Eureka 源码解析 —— 任务批处理
摘要: 原创出处 http://www.iocoder.cn/Eureka/batch-tasks/ 「芋道源码」欢迎转载,保留摘要,谢谢!
本文主要基于 Eureka 1.8.X 版本
- 1. 概述
- 2. 整体流程
- 3. 任务处理器
- 4. 创建任务分发器
- 4.1 批量任务执行分发器
- 4.2 单任务执行分发器
- 5. 创建任务接收执行器
- 6. 创建任务执行器
- 6.1 创建批量任务执行器
- 6.2 创建单任务执行器
- 6.3 工作线程抽象类
- 7. 网络通信整形器
- 8. 任务接收执行器【处理任务】
- 9. 任务接收线程【调度任务】
- 10. 任务执行器【执行任务】
- 10.1 批量任务工作线程
- 10.2 单任务工作线程
- 666. 彩蛋
������关注**微信公众号:【芋道源码】**有福利:
- RocketMQ / MyCAT / Sharding-JDBC 所有 源码分析文章列表
- RocketMQ / MyCAT / Sharding-JDBC 中文注释源码 GitHub 地址
- 您对于源码的疑问每条留言 都 将得到 认真 回复。 甚至不知道如何读源码也可以请教噢 。
- 新的 源码解析文章 实时 收到通知。 每周更新一篇左右 。
- 认真的 源码交流微信群。
1. 概述
本文主要分享 任务批处理 。Eureka-Server 集群通过任务批处理同步应用实例注册实例,所以本文也是为 Eureka-Server 集群同步的分享做铺垫。
本文涉及类在 com.netflix.eureka.util.batcher 包下,涉及到主体类的类图如下(打开大图 ):
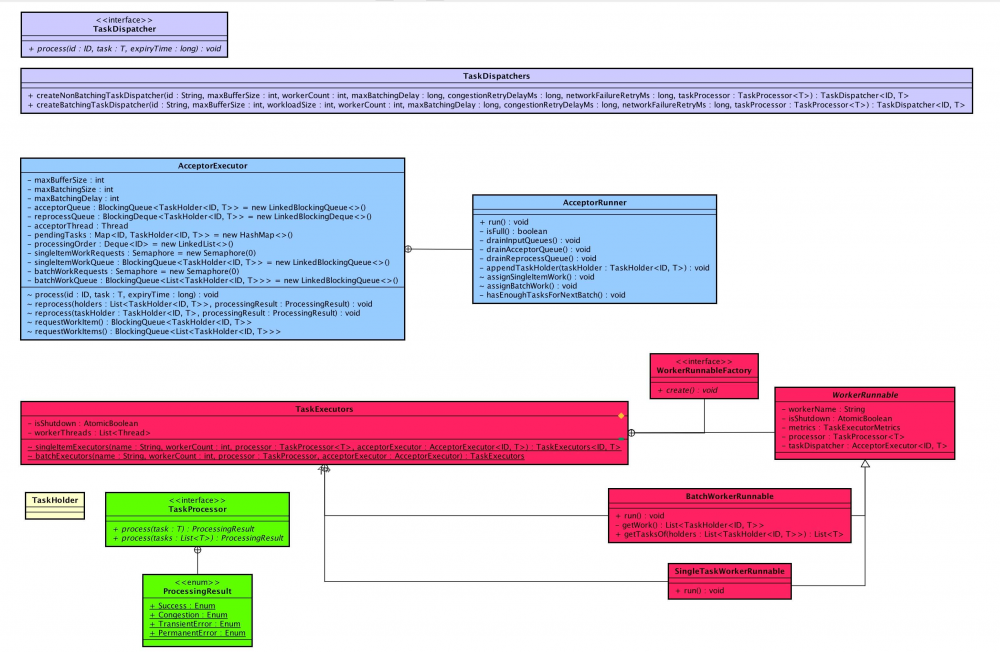
- 紫色部分 —— 任务分发器
- 蓝色部分 —— 任务接收器
- 红色部分 —— 任务执行器
- 绿色部分 —— 任务处理器
- 黄色部分 —— 任务持有者( 任务 )
推荐 Spring Cloud 书籍:
- 请支持正版。下载盗版, 等于主动编写低级 BUG 。
- 程序猿DD —— 《Spring Cloud微服务实战》
- 周立 —— 《Spring Cloud与Docker微服务架构实战》
- 两书齐买,京东包邮。
2. 整体流程
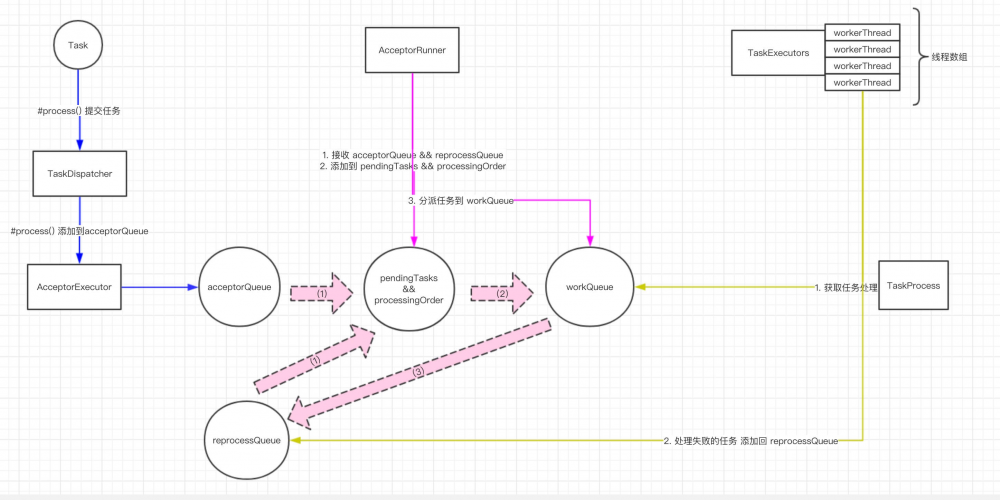
任务执行的整体流程如下(打开大图 ):
-
细箭头 —— 任务执行经历的操作
-
粗箭头 —— 任务队列流转的方向
-
不同于一般情况下,任务提交了 立即 同步或异步执行,任务的执行拆分了 三层队列 :
-
第一层,接收队列(
acceptorQueue),重新处理队列(reprocessQueue)。- 蓝线:分发器在收到任务执行请求后,提交到接收队列, 任务实际未执行 。
- 黄线:执行器的工作线程处理任务失败,将符合条件( 见)的失败任务提交到重新执行队列。
-
第二层,待执行队列(
processingOrder)- 粉线:接收线程( Runner )将重新执行队列,接收队列提交到待执行队列。
-
第三层,工作队列(
workQueue)- 粉线:接收线程( Runner )将待执行队列的任务根据参数(
maxBatchingSize)将任务合并成 批量任务 ,调度( 提交 )到工作队列。 - 黄线:执行器的工作线程 池 ,一个工作线程可以拉取一个 批量任务 进行执行。
- 粉线:接收线程( Runner )将待执行队列的任务根据参数(
-
-
三层队列的好处:
- 接收队列,避免处理任务的阻塞等待。
- 接收线程( Runner )合并任务,将相同任务编号( 是的,任务是带有编号的 )的任务合并,只执行一次。
- Eureka-Server 为集群同步提供批量操作 多个 应用实例的 接口 ,一个 批量任务 可以一次调度接口完成,避免多次调用的开销。当然,这样做的前提是合并任务,这也导致 Eureka-Server 集群之间对应用实例的注册和下线带来更大的延迟。 毕竟,Eureka 是在 CAP 之间,选择了 AP 。
3. 任务处理器
com.netflix.eureka.util.batcher.TaskProcessor ,任务处理器 接口 。接口代码如下:
public interface TaskProcessor<T>{
/**
* A processed task/task list ends up in one of the following states:
* <ul>
* <li>{@code Success} processing finished successfully</li>
* <li>{@code TransientError} processing failed, but shall be retried later</li>
* <li>{@code PermanentError} processing failed, and is non recoverable</li>
* </ul>
*/
enum ProcessingResult {
/**
* 成功
*/
Success,
/**
* 拥挤错误
*/
Congestion,
/**
* 瞬时错误
*/
TransientError,
/**
* 永久错误
*/
PermanentError
}
/**
* 处理单任务
* In non-batched mode a single task is processed at a time.
*/
ProcessingResult process(T task);
/**
* 处理批量任务
*
* For batched mode a collection of tasks is run at a time. The result is provided for the aggregated result,
* and all tasks are handled in the same way according to what is returned (for example are rescheduled, if the
* error is transient).
*/
ProcessingResult process(List<T> tasks);
}
- ProcessingResult ,处理任务结果。
-
Success,成功。 -
Congestion,拥挤错误, 任务将会被重试 。例如,请求被限流。 -
TransientError,瞬时错误, 任务将会被重试 。例如,网络请求超时。 -
PermanentError,永久错误, 任务将会被丢弃 。例如,执行时发生程序异常。
-
-
#process(task)方法,处理单任务。 -
#process(tasks)方法,处理批量任务。
4. 创建任务分发器
com.netflix.eureka.util.batcher.TaskDispatcher ,任务分发器 接口 。接口代码如下:
public interface TaskDispatcher<ID, T>{
void process(ID id, T task, long expiryTime);
void shutdown();
}
-
#process(...)方法,提交任务编号,任务,任务过期时间给任务分发器处理。
com.netflix.eureka.util.batcher.TaskDispatchers ,任务分发器 工厂类 ,用于创建任务分发器。其内部提供两种任务分发器的实现:
- 批量任务 执行的分发器,用于 Eureka-Server 集群注册信息的同步任务。
- 单任务 执行的分发器,用于 Eureka-Server 向亚马逊 AWS 的 ASG ( Autoscaling Group ) 同步状态。虽然本系列暂时对 AWS 相关的不做解析,从工具类的角度来说,本文会对该分发器进行分享。
com.netflix.eureka.cluster.ReplicationTaskProcessor ,实现 TaskDispatcher ,Eureka-Server 集群任务处理器。感兴趣的同学,可以点击 链接 自己研究,我们将在TODO[0021]:集群同步 详细解析。
4.1 批量任务执行分发器
调用 TaskDispatchers#createBatchingTaskDispatcher(...) 方法,创建 批量任务 执行的分发器,实现代码如下:
// TaskDispatchers.java
1: /**
2: * 创建批量任务执行的分发器
3: *
4: * @param id 任务执行器编号
5: * @param maxBufferSize 待执行队列最大数量
6: * @param workloadSize 单个批量任务包含任务最大数量
7: * @param workerCount 任务执行器工作线程数
8: * @param maxBatchingDelay 批量任务等待最大延迟时长,单位:毫秒
9: * @param congestionRetryDelayMs 请求限流延迟重试时间,单位:毫秒
10: * @param networkFailureRetryMs 网络失败延迟重试时长,单位:毫秒
11: * @param taskProcessor 任务处理器
12: * @param <ID> 任务编号泛型
13: * @param <T> 任务泛型
14: * @return 批量任务执行的分发器
15: */
16: public static <ID, T> TaskDispatcher<ID, T> createBatchingTaskDispatcher(String id,
17: int maxBufferSize,
18: int workloadSize,
19: int workerCount,
20: long maxBatchingDelay,
21: long congestionRetryDelayMs,
22: long networkFailureRetryMs,
23: TaskProcessor<T> taskProcessor){
24: // 创建 任务接收执行器
25: final AcceptorExecutor<ID, T> acceptorExecutor = new AcceptorExecutor<>(
26: id, maxBufferSize, workloadSize, maxBatchingDelay, congestionRetryDelayMs, networkFailureRetryMs
27: );
28: // 创建 批量任务执行器
29: final TaskExecutors<ID, T> taskExecutor = TaskExecutors.batchExecutors(id, workerCount, taskProcessor, acceptorExecutor);
30: // 创建 批量任务分发器
31: return new TaskDispatcher<ID, T>() {
32: @Override
33: public void process(ID id, T task, long expiryTime){
34: acceptorExecutor.process(id, task, expiryTime);
35: }
36:
37: @Override
38: public void shutdown(){
39: acceptorExecutor.shutdown();
40: taskExecutor.shutdown();
41: }
42: };
43: }
- 第 1 至 23 行 :方法参数。比较多哈,请耐心理解。
-
workloadSize参数,单个批量任务包含任务最大数量。 -
taskProcessor参数, 自定义任务执行器实现 。
-
- 第 24 至 27 行 :创建任务 接收 执行器。在详细解析。
- 第 28 至 29 行 :创建 批量 任务执行器。在「6.1 创建批量任务执行器」详细解析。
- 第 30 至 42 行 :创建 批量 任务分发器。
- 第 32 至 35 行 :
#process()方法的实现,调用AcceptorExecutor#process(...)方法,提交 [ 任务编号 , 任务 , 任务过期时间 ] 给任务分发器处理。
- 第 32 至 35 行 :
4.2 单任务执行分发器
调用 TaskDispatchers#createNonBatchingTaskDispatcher(...) 方法,创建 单任务 执行的分发器,实现代码如下:
1: /**
2: * 创建单任务执行的分发器
3: *
4: * @param id 任务执行器编号
5: * @param maxBufferSize 待执行队列最大数量
6: * @param workerCount 任务执行器工作线程数
7: * @param maxBatchingDelay 批量任务等待最大延迟时长,单位:毫秒
8: * @param congestionRetryDelayMs 请求限流延迟重试时间,单位:毫秒
9: * @param networkFailureRetryMs 网络失败延迟重试时长,单位:毫秒
10: * @param taskProcessor 任务处理器
11: * @param <ID> 任务编号泛型
12: * @param <T> 任务泛型
13: * @return 单任务执行的分发器
14: */
15: public static <ID, T> TaskDispatcher<ID, T> createNonBatchingTaskDispatcher(String id,
16: int maxBufferSize,
17: int workerCount,
18: long maxBatchingDelay,
19: long congestionRetryDelayMs,
20: long networkFailureRetryMs,
21: TaskProcessor<T> taskProcessor){
22: // 创建 任务接收执行器
23: final AcceptorExecutor<ID, T> acceptorExecutor = new AcceptorExecutor<>(
24: id, maxBufferSize, /* workloadSize = 1 */1, maxBatchingDelay, congestionRetryDelayMs, networkFailureRetryMs
25: );
26: final TaskExecutors<ID, T> taskExecutor = TaskExecutors.singleItemExecutors(id, workerCount, taskProcessor, acceptorExecutor);
27: return new TaskDispatcher<ID, T>() {
28: @Override
29: public void process(ID id, T task, long expiryTime){
30: acceptorExecutor.process(id, task, expiryTime);
31: }
32:
33: @Override
34: public void shutdown(){
35: acceptorExecutor.shutdown();
36: taskExecutor.shutdown();
37: }
38: };
39: }
- 第 1 至 21 行 :方法参数。比较多哈,请耐心理解。
-
workloadSize参数#createBatchingTaskDispatcher(...)少这个参数。 在第 24 行,你会发现该参数传递给 AcceptorExecutor 使用 1 噢 。 -
taskProcessor参数, 自定义任务执行器实现 。
-
- 第 21 至 25 行 :创建任务 接收 执行器。和
#createBatchingTaskDispatcher(...)只差workloadSize = 1参数。在详细解析。 - 第 28 至 29 行 :创建 单 任务执行器。 和
#createBatchingTaskDispatcher(...)差别很大 。「6.2 创建单任务执行器」详细解析。 - 第 30 至 42 行 :创建 单 任务分发器。和
#createBatchingTaskDispatcher(...)一样。
5. 创建任务接收执行器
com.netflix.eureka.util.batcher.AcceptorExecutor ,任务接收执行器。创建构造方法代码如下:
1: class AcceptorExecutor<ID, T>{
2:
3: private static final Logger logger = LoggerFactory.getLogger(AcceptorExecutor.class);
4:
5: /**
6: * 待执行队列最大数量
7: * {@link #processingOrder}
8: */
9: private final int maxBufferSize;
10: /**
11: * 单个批量任务包含任务最大数量
12: */
13: private final int maxBatchingSize;
14: /**
15: * 批量任务等待最大延迟时长,单位:毫秒
16: */
17: private final long maxBatchingDelay;
18:
19: /**
20: * 是否关闭
21: */
22: private final AtomicBoolean isShutdown = new AtomicBoolean(false);
23: /**
24: * 接收任务队列
25: */
26: private final BlockingQueue<TaskHolder<ID, T>> acceptorQueue = new LinkedBlockingQueue<>();
27: /**
28: * 重新执行任务队列
29: */
30: private final BlockingDeque<TaskHolder<ID, T>> reprocessQueue = new LinkedBlockingDeque<>();
31: /**
32: * 接收任务线程
33: */
34: private final Thread acceptorThread;
35:
36: /**
37: * 待执行任务映射
38: */
39: private final Map<ID, TaskHolder<ID, T>> pendingTasks = new HashMap<>();
40: /**
41: * 待执行队列
42: */
43: private final Deque<ID> processingOrder = new LinkedList<>();
44:
45: /**
46: * 单任务工作请求信号量
47: */
48: private final Semaphore singleItemWorkRequests = new Semaphore(0);
49: /**
50: * 单任务工作队列
51: */
52: private final BlockingQueue<TaskHolder<ID, T>> singleItemWorkQueue = new LinkedBlockingQueue<>();
53:
54: /**
55: * 批量任务工作请求信号量
56: */
57: private final Semaphore batchWorkRequests = new Semaphore(0);
58: /**
59: * 批量任务工作队列
60: */
61: private final BlockingQueue<List<TaskHolder<ID, T>>> batchWorkQueue = new LinkedBlockingQueue<>();
62:
63: /**
64: * 网络通信整形器
65: */
66: private final TrafficShaper trafficShaper;
67:
68: AcceptorExecutor(String id,
69: int maxBufferSize,
70: int maxBatchingSize,
71: long maxBatchingDelay,
72: long congestionRetryDelayMs,
73: long networkFailureRetryMs) {
74: this.maxBufferSize = maxBufferSize;
75: this.maxBatchingSize = maxBatchingSize;
76: this.maxBatchingDelay = maxBatchingDelay;
77:
78: // 创建 网络通信整形器
79: this.trafficShaper = new TrafficShaper(congestionRetryDelayMs, networkFailureRetryMs);
80:
81: // 创建 接收任务线程
82: ThreadGroup threadGroup = new ThreadGroup("eurekaTaskExecutors");
83: this.acceptorThread = new Thread(threadGroup, new AcceptorRunner(), "TaskAcceptor-" + id);
84: this.acceptorThread.setDaemon(true);
85: this.acceptorThread.start();
86:
87: // TODO (省略代码)芋艿:监控相关,暂时无视
88: }
89: }
- 第 5 至 61 行 :属性。比较多哈,请耐心理解。
- 眼尖如你,会发现 AcceptorExecutor 即存在单任务工作队列(
singleItemWorkQueue),又存在批量任务工作队列(batchWorkQueue) ,在「9. 任务接收线程【调度任务】」会解答这个疑惑。
- 眼尖如你,会发现 AcceptorExecutor 即存在单任务工作队列(
- 第 81 至 85 行 : 创建接收任务线程 。
6. 创建任务执行器
com.netflix.eureka.util.batcher.TaskExecutors ,任务执行器。 其内部提供创建单任务和批量任务执行器的两种方法 。TaskExecutors 构造方法如下:
class TaskExecutors<ID, T>{
private static final Logger logger = LoggerFactory.getLogger(TaskExecutors.class);
/**
* 是否关闭
*/
private final AtomicBoolean isShutdown;
/**
* 工作线程池
*/
private final List<Thread> workerThreads;
TaskExecutors(WorkerRunnableFactory<ID, T> workerRunnableFactory, int workerCount, AtomicBoolean isShutdown) {
this.isShutdown = isShutdown;
this.workerThreads = new ArrayList<>();
// 创建 工作线程池
ThreadGroup threadGroup = new ThreadGroup("eurekaTaskExecutors");
for (int i = 0; i < workerCount; i++) {
WorkerRunnable<ID, T> runnable = workerRunnableFactory.create(i);
Thread workerThread = new Thread(threadGroup, runnable, runnable.getWorkerName());
workerThreads.add(workerThread);
workerThread.setDaemon(true);
workerThread.start();
}
}
/**
* 创建工作线程工厂
*
* @param <ID> 任务编号泛型
* @param <T> 批量任务执行器
*/
interface WorkerRunnableFactory<ID, T>{
WorkerRunnable<ID, T> create(int idx);
}
}
-
workerThreads属性,工作线程 池 。 工作任务队列会被工作线程池并发拉取,并发执行 。 -
com.netflix.eureka.util.batcher.TaskExecutors.WorkerRunnableFactory,创建工作线程工厂 接口 。单任务和批量任务执行器的工作线程实现不同,通过自定义工厂实现类创建。
6.1 创建批量任务执行器
调用 TaskExecutors#batchExecutors(...) 方法,创建批量任务执行器。实现代码如下:
/**
* 创建批量任务执行器
*
* @param name 任务执行器名
* @param workerCount 任务执行器工作线程数
* @param processor 任务处理器
* @param acceptorExecutor 接收任务执行器
* @param <ID> 任务编号泛型
* @param <T> 任务泛型
* @return 批量任务执行器
*/
static <ID, T> TaskExecutors<ID, T> batchExecutors(final String name,
int workerCount,
final TaskProcessor<T> processor,
final AcceptorExecutor<ID, T> acceptorExecutor){
final AtomicBoolean isShutdown = new AtomicBoolean();
final TaskExecutorMetrics metrics = new TaskExecutorMetrics(name);
// 创建批量任务执行器
return new TaskExecutors<>(new WorkerRunnableFactory<ID, T>() { // 批量任务工作线程工厂
@Override
public WorkerRunnable<ID, T> create(int idx){
return new BatchWorkerRunnable<>("TaskBatchingWorker-" + name + '-' + idx /* 线程名 */, isShutdown, metrics, processor, acceptorExecutor);
}
}, workerCount, isShutdown);
}
-
com.netflix.eureka.util.batcher.TaskExecutors.WorkerRunnable.BatchWorkerRunnable,批量任务工作线程。
6.2 创建单任务执行器
调用 TaskExecutors#singleItemExecutors(...) 方法,创建批量任务执行器。实现代码如下:
/**
* 创建单任务执行器
*
* @param name 任务执行器名
* @param workerCount 任务执行器工作线程数
* @param processor 任务处理器
* @param acceptorExecutor 接收任务执行器
* @param <ID> 任务编号泛型
* @param <T> 任务泛型
* @return 单任务执行器
*/
static <ID, T> TaskExecutors<ID, T> singleItemExecutors(final String name,
int workerCount,
final TaskProcessor<T> processor,
final AcceptorExecutor<ID, T> acceptorExecutor){
final AtomicBoolean isShutdown = new AtomicBoolean();
final TaskExecutorMetrics metrics = new TaskExecutorMetrics(name);
// 创建单任务执行器
return new TaskExecutors<>(new WorkerRunnableFactory<ID, T>() { // 单任务工作线程工厂
@Override
public WorkerRunnable<ID, T> create(int idx){
return new SingleTaskWorkerRunnable<>("TaskNonBatchingWorker-" + name + '-' + idx /* 线程名 */, isShutdown, metrics, processor, acceptorExecutor);
}
}, workerCount, isShutdown);
}
-
com.netflix.eureka.util.batcher.TaskExecutors.WorkerRunnable.SingleTaskWorkerRunnable,单任务工作线程。
6.3 工作线程抽象类
com.netflix.eureka.util.batcher.TaskExecutors.WorkerRunnable ,任务工作线程抽象类。BatchWorkerRunnable 和 SingleTaskWorkerRunnable 都实现该类,差异在 #run() 的自定义实现。WorkerRunnable 实现代码如下:
abstract static class WorkerRunnable<ID, T> implements Runnable{
/**
* 线程名
*/
final String workerName;
/**
* 是否关闭
*/
final AtomicBoolean isShutdown;
final TaskExecutorMetrics metrics;
/**
* 任务处理器
*/
final TaskProcessor<T> processor;
/**
* 任务接收执行器
*/
final AcceptorExecutor<ID, T> taskDispatcher;
// ... 省略构造方法和 getting 方法。
}
7. 网络通信整形器
com.netflix.eureka.util.batcher.TrafficShaper ,网络通信整形器。当任务执行发生请求限流,或是请求网络失败的情况,则延时 AcceptorRunner 将任务提交到工作任务队列,从而避免任务很快去执行,再次发生上述情况。TrafficShaper 实现代码如下:
class TrafficShaper{
/**
* Upper bound on delay provided by configuration.
*/
private static final long MAX_DELAY = 30 * 1000;
/**
* 请求限流延迟重试时间,单位:毫秒
*/
private final long congestionRetryDelayMs;
/**
* 网络失败延迟重试时长,单位:毫秒
*/
private final long networkFailureRetryMs;
/**
* 最后请求限流时间戳,单位:毫秒
*/
private volatile long lastCongestionError;
/**
* 最后网络失败时间戳,单位:毫秒
*/
private volatile long lastNetworkFailure;
TrafficShaper(long congestionRetryDelayMs, long networkFailureRetryMs) {
this.congestionRetryDelayMs = Math.min(MAX_DELAY, congestionRetryDelayMs);
this.networkFailureRetryMs = Math.min(MAX_DELAY, networkFailureRetryMs);
}
void registerFailure(ProcessingResult processingResult){
if (processingResult == ProcessingResult.Congestion) {
lastCongestionError = System.currentTimeMillis();
} else if (processingResult == ProcessingResult.TransientError) {
lastNetworkFailure = System.currentTimeMillis();
}
}
/**
* 计算提交延迟,单位:毫秒
*
* @return 延迟
*/
long transmissionDelay(){
// 无延迟
if (lastCongestionError == -1 && lastNetworkFailure == -1) {
return 0;
}
long now = System.currentTimeMillis();
// 计算最后请求限流带来的延迟
if (lastCongestionError != -1) {
long congestionDelay = now - lastCongestionError;
if (congestionDelay >= 0 && congestionDelay < congestionRetryDelayMs) { // 范围内
return congestionRetryDelayMs - congestionDelay; // 补充延迟
}
lastCongestionError = -1; // 重置时间戳
}
// 计算最后网络失败带来的延迟
if (lastNetworkFailure != -1) {
long failureDelay = now - lastNetworkFailure;
if (failureDelay >= 0 && failureDelay < networkFailureRetryMs) { // 范围内
return networkFailureRetryMs - failureDelay; // 补充延迟
}
lastNetworkFailure = -1; // 重置时间戳
}
// 无延迟
return 0;
}
}
-
#registerFailure(...),在任务执行失败时,提交任务结果给 TrafficShaper ,记录发生时间。在「10. 任务执行器【执行任务】」会看到调用该方法。 -
#transmissionDelay(...),计算提交延迟,单位:毫秒。「9. 任务接收线程【调度任务】」会看到调用该方法。
8. 任务接收执行器【处理任务】
调用 AcceptorExecutor#process(...) 方法,添加任务到接收任务队列。实现代码如下:
// AcceptorExecutor.java
void process(ID id, T task, long expiryTime){
acceptorQueue.add(new TaskHolder<ID, T>(id, task, expiryTime));
acceptedTasks++;
}
-
com.netflix.eureka.util.batcher.TaskHolder,任务持有者,实现代码如下:class TaskHolder<ID, T>{ /** * 任务编号 */ private final ID id; /** * 任务 */ private final T task; /** * 任务过期时间戳 */ private final long expiryTime; /** * 任务提交时间戳 */ private final long submitTimestamp; }
9. 任务接收线程【调度任务】
后台线程执行 AcceptorRunner#run(...) 方法,调度任务。实现代码如下:
1: @Override
2: public void run(){
3: long scheduleTime = 0;
4: while (!isShutdown.get()) {
5: try {
6: // 处理完输入队列( 接收队列 + 重新执行队列 )
7: drainInputQueues();
8:
9: // 待执行任务数量
10: int totalItems = processingOrder.size();
11:
12: // 计算调度时间
13: long now = System.currentTimeMillis();
14: if (scheduleTime < now) {
15: scheduleTime = now + trafficShaper.transmissionDelay();
16: }
17:
18: // 调度
19: if (scheduleTime <= now) {
20: // 调度批量任务
21: assignBatchWork();
22: // 调度单任务
23: assignSingleItemWork();
24: }
25:
26: // 1)任务执行器无任务请求,正在忙碌处理之前的任务;或者 2)任务延迟调度。睡眠 10 秒,避免资源浪费。
27: // If no worker is requesting data or there is a delay injected by the traffic shaper,
28: // sleep for some time to avoid tight loop.
29: if (totalItems == processingOrder.size()) {
30: Thread.sleep(10);
31: }
32: } catch (InterruptedException ex) {
33: // Ignore
34: } catch (Throwable e) {
35: // Safe-guard, so we never exit this loop in an uncontrolled way.
36: logger.warn("Discovery AcceptorThread error", e);
37: }
38: }
39: }
-
第 4 行 :无限循环执行调度,直到关闭。
-
第 6 至 7 行 :调用
#drainInputQueues()方法, 循环 处理完输入队列( 接收队列 + 重新执行队列 ), 直到 有待执行的任务。实现代码如下:1: private void drainInputQueues() throws InterruptedException{ 2: do { 3: // 处理完重新执行队列 4: drainReprocessQueue(); 5: // 处理完接收队列 6: drainAcceptorQueue(); 7: 8: // 所有队列为空,等待 10 ms,看接收队列是否有新任务 9: if (!isShutdown.get()) { 10: // If all queues are empty, block for a while on the acceptor queue 11: if (reprocessQueue.isEmpty() && acceptorQueue.isEmpty() && pendingTasks.isEmpty()) { 12: TaskHolder<ID, T> taskHolder = acceptorQueue.poll(10, TimeUnit.MILLISECONDS); 13: if (taskHolder != null) { 14: appendTaskHolder(taskHolder); 15: } 16: } 17: } 18: } while (!reprocessQueue.isEmpty() || !acceptorQueue.isEmpty() || pendingTasks.isEmpty()); // 处理完输入队列( 接收队列 + 重新执行队列 ) 19: }-
第 2 行 && 第 18 行 : 循环 ,直到 同时 满足如下全部条件:
- 重新执行队列(
reprocessQueue) 和接收队列(acceptorQueue)为空 - 待执行任务映射(
pendingTasks) 不为空
- 重新执行队列(
-
第 3 至 4 行 :处理完重新执行队列(
reprocessQueue)。实现代码如下:1: private void drainReprocessQueue(){ 2: long now = System.currentTimeMillis(); 3: while (!reprocessQueue.isEmpty() && !isFull()) { 4: TaskHolder<ID, T> taskHolder = reprocessQueue.pollLast(); // 优先拿较新的任务 5: ID id = taskHolder.getId(); 6: if (taskHolder.getExpiryTime() <= now) { // 过期 7: expiredTasks++; 8: } else if (pendingTasks.containsKey(id)) { // 已存在 9: overriddenTasks++; 10: } else { 11: pendingTasks.put(id, taskHolder); 12: processingOrder.addFirst(id); // 提交到队头 13: } 14: } 15: // 如果待执行队列已满,清空重新执行队列,放弃较早的任务 16: if (isFull()) { 17: queueOverflows += reprocessQueue.size(); 18: reprocessQueue.clear(); 19: } 20: }- 第 4 行 :优先从重新执行任务的队尾拿较新的任务,从而实现保留更新的任务在待执行任务映射(
pendingTasks) 里。 - 第 12 行 :添加任务编号到待执行队列(
processingOrder) 的头部。效果如下图: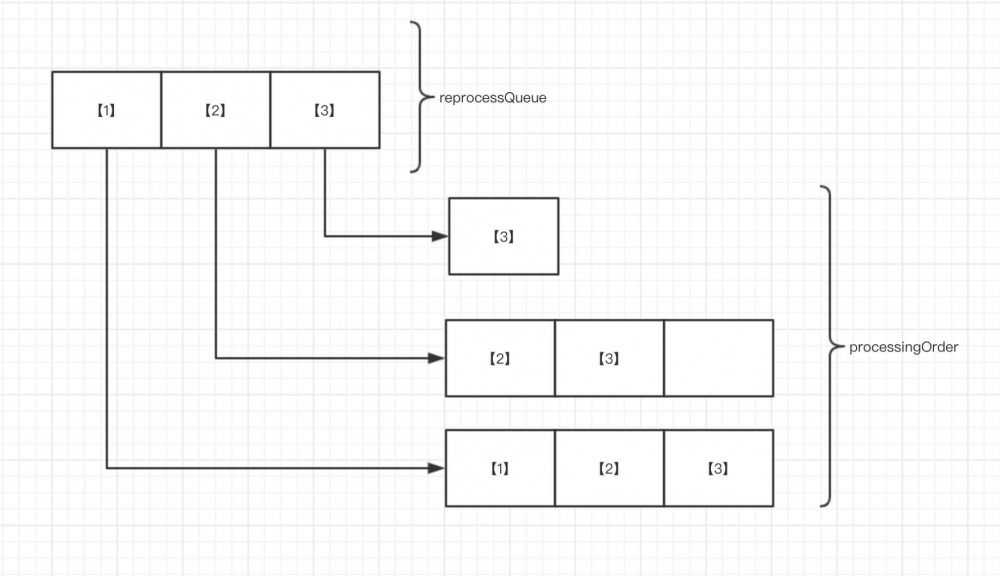
- 第 15 至 18 行 :如果待执行队列(
pendingTasks)已满,清空重新执行队列(processingOrder),放弃较早的任务。
- 第 4 行 :优先从重新执行任务的队尾拿较新的任务,从而实现保留更新的任务在待执行任务映射(
-
第 5 至 6 行 :处理完接收队列(
acceptorQueue),实现代码如下:private void drainAcceptorQueue(){ while (!acceptorQueue.isEmpty()) { // 循环,直到接收队列为空 appendTaskHolder(acceptorQueue.poll()); } } private void appendTaskHolder(TaskHolder<ID, T> taskHolder){ // 如果待执行队列已满,移除待处理队列,放弃较早的任务 if (isFull()) { pendingTasks.remove(processingOrder.poll()); queueOverflows++; } // 添加到待执行队列 TaskHolder<ID, T> previousTask = pendingTasks.put(taskHolder.getId(), taskHolder); if (previousTask == null) { processingOrder.add(taskHolder.getId()); } else { overriddenTasks++; } } -
第 8 至 17 行 :当所有队列为空,阻塞从接收队列(
acceptorQueue) 拉取任务 10 ms。若拉取到,添加到待执行队列(processingOrder)。
-
-
第 12 至 16 行 :计算可调度任务的最小时间(
scheduleTime)。- 当
scheduleTime小于当前时间,不重新计算,即此时需要延迟等待调度。 - 当
scheduleTime大于等于当前时间,配合TrafficShaper#transmissionDelay(...)重新计算。
- 当
-
第 19 行 :当
scheduleTime小于当前时间,执行任务的调度。 -
第 21 行 :调用
#assignBatchWork()方法,调度批量任务。实现代码如下:1: void assignBatchWork(){ 2: if (hasEnoughTasksForNextBatch()) { 3: // 获取 批量任务工作请求信号量 4: if (batchWorkRequests.tryAcquire(1)) { 5: // 获取批量任务 6: long now = System.currentTimeMillis(); 7: int len = Math.min(maxBatchingSize, processingOrder.size()); 8: List<TaskHolder<ID, T>> holders = new ArrayList<>(len); 9: while (holders.size() < len && !processingOrder.isEmpty()) { 10: ID id = processingOrder.poll(); 11: TaskHolder<ID, T> holder = pendingTasks.remove(id); 12: if (holder.getExpiryTime() > now) { // 过期 13: holders.add(holder); 14: } else { 15: expiredTasks++; 16: } 17: } 18: // 19: if (holders.isEmpty()) { // 未调度到批量任务,释放请求信号量 20: batchWorkRequests.release(); 21: } else { // 添加批量任务到批量任务工作队列 22: batchSizeMetric.record(holders.size(), TimeUnit.MILLISECONDS); 23: batchWorkQueue.add(holders); 24: } 25: } 26: } 27: }-
第 2 行 :调用
#hasEnoughTasksForNextBatch()方法,判断是否有足够任务进行下一次批量任务调度:1)待执行任务(processingOrder)映射已满;或者 2)到达批量任务处理最大等待延迟。实现代码如下:private boolean hasEnoughTasksForNextBatch(){ // 待执行队列为空 if (processingOrder.isEmpty()) { return false; } // 待执行任务映射已满 if (pendingTasks.size() >= maxBufferSize) { return true; } // 到达批量任务处理最大等待延迟( 通过待处理队列的头部任务判断 ) TaskHolder<ID, T> nextHolder = pendingTasks.get(processingOrder.peek()); long delay = System.currentTimeMillis() - nextHolder.getSubmitTimestamp(); return delay >= maxBatchingDelay; } -
第 5 至 17 行 :获取批量任务(
holders)。 你会发现,本文说了半天的批量任务,实际是 List<TaskHolder<ID, T>> 哈 。 -
第 4 行 :获取批量任务工作请求信号量(
batchWorkRequests) 。在任务执行器的批量任务执行器,每次执行时,发出batchWorkRequests。 每一个信号量需要保证获取到一个批量任务 。 -
第 19 至 20 行 :未调度到批量任务,释放请求信号量, 代表请求实际未完成,每一个信号量需要保证获取到一个批量任务 。
-
第 21 至 24 行 :添加批量任务到批量任务工作队列。
-
第 23 行 :调用
#assignSingleItemWork()方法,调度单任务。
-
-
第 23 行 :调用
#assignSingleItemWork()方法,调度单任务,和#assignBatchWork()方法 类似 。实现代码如下:void assignSingleItemWork(){ if (!processingOrder.isEmpty()) { // 待执行任队列不为空 // 获取 单任务工作请求信号量 if (singleItemWorkRequests.tryAcquire(1)) { // 【循环】获取单任务 long now = System.currentTimeMillis(); while (!processingOrder.isEmpty()) { ID id = processingOrder.poll(); // 一定不为空 TaskHolder<ID, T> holder = pendingTasks.remove(id); if (holder.getExpiryTime() > now) { singleItemWorkQueue.add(holder); return; } expiredTasks++; } // 获取不到单任务,释放请求信号量 singleItemWorkRequests.release(); } } } -
第 26 至 31 行 :当调度任务前的待执行任务数(
totalItems)等于当前待执行队列(processingOrder)的任务数,意味着:1)任务执行器无任务请求,正在忙碌处理之前的任务;或者 2)任务延迟调度。睡眠 10 秒,避免资源浪费。
10. 任务执行器【执行任务】
10.1 批量任务工作线程
批量任务工作后台线程( BatchWorkerRunnable )执行 #run(...) 方法,调度任务。实现代码如下:
//
1: @Override
2: public void run(){
3: try {
4: while (!isShutdown.get()) {
5: // 获取批量任务
6: List<TaskHolder<ID, T>> holders = getWork();
7:
8: // TODO 芋艿:监控相关,暂时无视
9: metrics.registerExpiryTimes(holders);
10:
11: // 获得实际批量任务
12: List<T> tasks = getTasksOf(holders);
13: // 调用处理器执行任务
14: ProcessingResult result = processor.process(tasks);
15: switch (result) {
16: case Success:
17: break;
18: case Congestion:
19: case TransientError:
20: taskDispatcher.reprocess(holders, result); // 提交重新处理
21: break;
22: case PermanentError:
23: logger.warn("Discarding {} tasks of {} due to permanent error", holders.size(), workerName);
24: }
25:
26: // TODO 芋艿:监控相关,暂时无视
27: metrics.registerTaskResult(result, tasks.size());
28: }
29: } catch (InterruptedException e) {
30: // Ignore
31: } catch (Throwable e) {
32: // Safe-guard, so we never exit this loop in an uncontrolled way.
33: logger.warn("Discovery WorkerThread error", e);
34: }
35: }
-
第 4 行 :无限循环执行调度,直到关闭。
-
第 6 行 :调用
getWork()方法,获取 一个 批量任务直到成功。实现代码如下:1: private List<TaskHolder<ID, T>> getWork() throws InterruptedException { 2: // 发起请求信号量,并获得批量任务的工作队列 3: BlockingQueue<List<TaskHolder<ID, T>>> workQueue = taskDispatcher.requestWorkItems(); 4: // 【循环】获取批量任务,直到成功 5: List<TaskHolder<ID, T>> result; 6: do { 7: result = workQueue.poll(1, TimeUnit.SECONDS); 8: } while (!isShutdown.get() && result == null); 9: return result; 10: }-
第 3 行 :调用
TaskDispatcher#requestWorkItems()方法,发起请求信号量,并获得批量任务的工作队列。实现代码如下:// TaskDispatcher.java /** * 批量任务工作请求信号量 */ private final Semaphore batchWorkRequests = new Semaphore(0); /** * 批量任务工作队列 */ private final BlockingQueue<List<TaskHolder<ID, T>>> batchWorkQueue = new LinkedBlockingQueue<>(); BlockingQueue<List<TaskHolder<ID, T>>> requestWorkItems() { batchWorkRequests.release(); return batchWorkQueue; }- 注意 ,批量任务工作队列(
batchWorkQueue) 和单任务工作队列(singleItemWorkQueue) 是 不同的队列 。
- 注意 ,批量任务工作队列(
-
第 5 至 8 行 : 循环 获取 一个 批量任务,直到成功。
-
-
第 12 行 :调用
#getTasksOf(...)方法,获得 实际 批量任务。实现代码如下:private List<T> getTasksOf(List<TaskHolder<ID, T>> holders){ List<T> tasks = new ArrayList<>(holders.size()); for (TaskHolder<ID, T> holder : holders) { tasks.add(holder.getTask()); } return tasks; } -
第 14 至 24 行 :调用处理器( TaskProcessor ) 执行任务。当任务执行结果为
Congestion或TransientError,调用AcceptorExecutor#reprocess(...)提交 整个批量任务 重新处理,实现代码如下:// AcceptorExecutor.java void reprocess(List<TaskHolder<ID, T>> holders, ProcessingResult processingResult){ // 添加到 重新执行队列 reprocessQueue.addAll(holders); // TODO 芋艿:监控相关,暂时无视 replayedTasks += holders.size(); // 提交任务结果给 TrafficShaper trafficShaper.registerFailure(processingResult); }
10.2 单任务工作线程
单任务工作后台线程( SingleTaskWorkerRunnable )执行 #run(...) 方法,调度任务,和 BatchWorkerRunnable#run(...) 基本类似,就不啰嗦了。实现代码如下:
@Override
// SingleTaskWorkerRunnable.java
public void run(){
try {
while (!isShutdown.get()) {
// 发起请求信号量,并获得单任务的工作队列
BlockingQueue<TaskHolder<ID, T>> workQueue = taskDispatcher.requestWorkItem();
TaskHolder<ID, T> taskHolder;
// 【循环】获取单任务,直到成功
while ((taskHolder = workQueue.poll(1, TimeUnit.SECONDS)) == null) {
if (isShutdown.get()) {
return;
}
}
// TODO 芋艿:监控相关,暂时无视
metrics.registerExpiryTime(taskHolder);
if (taskHolder != null) {
// 调用处理器执行任务
ProcessingResult result = processor.process(taskHolder.getTask());
switch (result) {
case Success:
break;
case Congestion:
case TransientError:
taskDispatcher.reprocess(taskHolder, result); // 提交重新处理
break;
case PermanentError:
logger.warn("Discarding a task of {} due to permanent error", workerName);
}
// TODO 芋艿:监控相关,暂时无视
metrics.registerTaskResult(result, 1);
}
}
} catch (InterruptedException e) {
// Ignore
} catch (Throwable e) {
// Safe-guard, so we never exit this loop in an uncontrolled way.
logger.warn("Discovery WorkerThread error", e);
}
}
666. 彩蛋
:smiling_imp: 又是一篇长文。建议边看代码,边对照着整体流程图,理解实际不难。
当然,欢迎你有任何疑问,在我的公众号( 芋道源码 ) 留言。
胖友,分享我的公众号( 芋道源码 ) 给你的胖友可好?
正文到此结束
- 本文标签: volatile 文章 ioc bug spring IDE 解析 参数 ACE 处理器 RocketMQ https UI App http Atom id git map CTO 程序猿 ask queue MQ 京东 注释 Eureka src 微信公众号 Collection db 集群 时间 list example 线程池 IO 源码 cat 代码 key 同步 任务调度 executor ssh 线程 GitHub Docker final 下载 ORM java tar 亚马逊 实例
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

