【体系结构】有关Oracle SCN知识点的整理--补充内容
【体系结构】有关Oracle SCN知识点的整理--补充内容
DBA入门之认识Oracle SCN(System Change Number)
1. SCN的定义
SCN(System Change Number),也就是通常所说的系统改变号,是数据库中非常重要的一个数据结构。
SCN用以标识数据库在某个确切时刻提交的版本。在事务提交时,它被赋予一个唯一的标识事务的SCN。SCN同时被作为Oracle数据库的内部时钟机制,可被看做逻辑时钟,每个数据库都有一个全局的SCN生成器。
作为数据库内部的逻辑时钟,数据库事务依SCN而排序,Oracle也依据SCN来实现一致性读(Read Consistency)等重要数据库功能。另外对于分布式事务(Distributed Transactions),SCN也极为重要,这里不做更多介绍。
SCN在数据库中是唯一的,并随时间而增加,但是可能并不连贯。除非重建数据库,SCN的值永远不会被重置为0.
一直以来,对于SCN有很多争议,很多人认为SCN是指System Commit Number,而通常SCN在提交时才变化,所以很多时候,这两个名词经常在文档中反复出现。即使在Oracle的官方文档中,SCN也常以System Change/Commit Number两种形式出现。
到底是哪个词其实不是很重要,重要的是需要知道SCN是Oracle内部的时钟机制,Oracle通过SCN来维护数据库的一致性,并通过SCN实施Oracle至关重要的恢复机制。
SCN在数据库中是无处不在,常见的事务表、控制文件、数据文件头、日志文件、数据块头等都记录有SCN值。
冠以不同前缀,SCN也有了不同的名称,如检查点SCN(Checkpint SCN)、Resetlogs SCN等。
2.SCN的获取方式
可以通过如下几种方式获得数据库的当前或近似SCN。
(1) 从Oracle 9i开始。
可以使用dbms_flashback.get_system_change_number来获得:
SQL> select dbms_flashback.get_system_change_number from dual;
GET_SYSTEM_CHANGE_NUMBER
------------------------
888266
(2) Oracle 9i前。
可以通过查询x$ktuxe获得系统最接近当前值的SCN:
X$ktuxe的含义是[k]ernel [T]ransaction [U]ndo Transa[x]tion [E]ntry(table)
SQL>select max(ktuxecnw*power(2,32)+ktuxescnb) from x$ktuxe;
MAX(KTUXESCNW*POWER(2,32)+KTUXESCNB)
------------------------
28848232
3.SCN的进一步说明
系统当前SCN并不是在任何的数据库操作时都会改变,SCN通常在事务提交或回滚时改变。在控制文件、数据文件头、数据库、日志文件头、日志文件change vector中都有SCN,但其作用各不相同。
(1) 数据文件头中包含了该数据文件的Checkpoint SCN,表示该数据文件最近一次执行检查点操作时的SCN。
从控制文件的dump文件中,可以得到一下内容:
DATA FILE #1:
(name #7) /opt/ora10g/oradata/ORCL/system01.dbf
creation size=0 block size=8192 status=0xe head=7 tail=7 dup=1
tablespace 0, index=1 krfil=1 prev_file=0
unrecoverable scn: 0x0000.00000000 01/01/1988 00:00:00
Checkpoint cnt:106 scn: 0x0000.000d845f 11/14/2011 15:24:50
Stop scn: 0xffff.ffffffff 11/14/2011 14:31:00
Creation Checkpointed at scn: 0x0000.00000009 06/30/2005 19:10:11
……
对于每一个数据文件都包含一个这样的条目,记录该文件的检查点SCN的值以及检查点发生的时间,这里的Checkpint SCN、Stop SCN以及Checkpoint CNT都是非常重要的数据结构,我们将会在下面检查点部分详细介绍。
同样可以通过命令转储数据文件头,观察其具体信息及检查点记录等,从跟踪文件中摘取system表空间的记录作为参考:
***************************************************************************
DATA FILE RECORDS
***************************************************************************
(size = 428, compat size = 428, section max = 100, section in-use = 4,
last-recid= 53, old-recno = 0, last-recno = 0)
(extent = 1, blkno = 11, numrecs = 100)
DATA FILE #1:
(name #7) /opt/ora10g/oradata/ORCL/system01.dbf
creation size=0 block size=8192 status=0xe head=7 tail=7 dup=1
tablespace 0, index=1 krfil=1 prev_file=0
unrecoverable scn: 0x0000.00000000 01/01/1988 00:00:00
Checkpoint cnt:106 scn: 0x0000.000d845f 11/14/2011 15:24:50
Stop scn: 0xffff.ffffffff 11/14/2011 14:31:00
Creation Checkpointed at scn: 0x0000.00000009 06/30/2005 19:10:11
thread:0 rba:(0x0.0.0)
enabled threads: 00000000 00000000 00000000 00000000 00000000 00000000
00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
Offline scn: 0x0000.0006ce7a prev_range: 0
Online Checkpointed at scn: 0x0000.0006ce7b 11/10/2011 22:40:23
thread:1 rba:(0x1.2.0)
enabled threads: 01000000 00000000 00000000 00000000 00000000 00000000
Hot Backup end marker scn: 0x0000.00000000
aux_file is NOT DEFINED
(2) 日志文件头包含了Low SCN 和Next SCN。
Low SCN和 Next SCN这两个SCN表示该日志文件包含介于Low SCN到Next SCN的重做信息,对于Current的日志文件(当前正在被使用的Redo Logfile),其最终SCN不可知,所以Next SCN被置为无穷大,也就是ffffffff。
来看一下日志文件的情况:
SQL> select * from v$log;
GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARC STATUS FIRST_CHANGE# FIRST_TIM
---------- ---------- ---------- ---------- ---------- --- ----------------------------- ---------
1 1 35 52428800 1 NO CURRENT 881890 14-NOV-11
2 1 33 52428800 1 YES INACTIVE 836815 12-NOV-11
3 1 34 52428800 1 YES INACTIVE 858362 12-NOV-11
SQL> select dbms_flashback.get_system_change_number from dual;
GET_SYSTEM_CHANGE_NUMBER
------------------------
889346
SQL> alter system switch logfile;
System altered.
SQL> select * from v$log;
GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARC STATUS FIRST_CHANGE# FIRST_TIM
---------- ---------- ---------- ---------- ---------- --- ----------------------------- ---------
1 1 35 52428800 1 YES ACTIVE 881890 14-NOV-11
2 1 36 52428800 1 NO CURRENT 889353 14-NOV-11
3 1 34 52428800 1 YES INACTIVE 858362 12-NOV-11
可以看到,SCN 889346显然位于Log Group#为1的日志文件中,该日志文件包含了SCN自881890 至889353 的Redo信息。Oracle在进行恢复时,就需要根据低SCN和高SCN来确定需要的恢复信息位于哪一个日志或归档文件中。
如果通过控制文件转储,可以在控制文件中找到关于日志文件的信息:
SQL> alter session set events 'immediate trace name redohdr level 10';
Session altered.
LOG FILE #1:
(name #3) /opt/ora10g/oradata/ORCL/redo01.log
Thread 1 redo log links: forward: 2 backward: 0
siz: 0x19000 seq: 0x00000026 hws: 0x1 bsz: 512 nab: 0xffffffff flg: 0x8 dup: 1
Archive links: fwrd: 0 back: 0 Prev scn: 0x0000.000de15c
Low scn: 0x0000.000def9a 11/16/2011 16:06:06
Next scn: 0xffff.ffffffff 01/01/1988 00:00:00
LOG FILE #2:
(name #2) /opt/ora10g/oradata/ORCL/redo02.log
Thread 1 redo log links: forward: 3 backward: 1
siz: 0x19000 seq: 0x00000024 hws: 0x4 bsz: 512 nab: 0x5c6 flg: 0x1 dup: 1
Archive links: fwrd: 0 back: 0 Prev scn: 0x0000.000d74e2
Low scn: 0x0000.000d9209 11/14/2011 16:57:08
Next scn: 0x0000.000de15c 11/16/2011 15:01:07
LOG FILE #3:
(name #1) /opt/ora10g/oradata/ORCL/redo03.log
Thread 1 redo log links: forward: 0 backward: 2
siz: 0x19000 seq: 0x00000025 hws: 0x3 bsz: 512 nab: 0x37e3 flg: 0x1 dup: 1
Archive links: fwrd: 0 back: 0 Prev scn: 0x0000.000d9209
Low scn: 0x0000.000de15c 11/16/2011 15:01:07
Next scn: 0x0000.000def9a 11/16/2011 16:06:06
可以注意到,Log File 1是当前的日志文件,该文件拥有的Next SCN是无穷大。
同样,可以通过直接dump日志文件的方式来进行转储;
SQL> select * from v$logfile;
GROUP# STATUS TYPE MEMBER
---------- ------- ---------------------------------------------------------------------------
3 ONLINE /opt/ora10g/oradata/ORCL/redo03.log
2 ONLINE /opt/ora10g/oradata/ORCL/redo02.log
1 ONLINE /opt/ora10g/oradata/ORCL/redo01.log
SQL> alter system dump logfile '/opt/ora10g/oradata/ORCL/redo01.log';
System altered.
DUMP OF REDO FROM FILE '/opt/ora10g/oradata/ORCL/redo01.log'
Opcodes *.*
RBAs: 0x000000.00000000.0000 thru 0xffffffff.ffffffff.ffff
SCNs: scn: 0x0000.00000000 thru scn: 0xffff.ffffffff
Times: creation thru eternity
FILE HEADER:
Compatibility Vsn = 169869568=0xa200100
Db ID=1294662348=0x4d2afacc, Db Name='ORCL'
Activation ID=1294635980=0x4d2a93cc
Control Seq=953=0x3b9, File size=102400=0x19000
File Number=1, Blksiz=512, File Type=2 LOG
descrip:"Thread 0001, Seq# 0000000038, SCN 0x0000000def9a-0xffffffffffff"
thread: 1 nab: 0xffffffff seq: 0x00000026 hws: 0x1 eot: 1 dis: 0
resetlogs count: 0x2db5af57 scn: 0x0000.0006ce7b (446075)
resetlogs terminal rcv count: 0x0 scn: 0x0000.00000000
prev resetlogs count: 0x2184ef74 scn: 0x0000.00000001 (1)
prev resetlogs terminal rcv count: 0x0 scn: 0x0000.00000000
Low scn: 0x0000.000def9a (913306) 11/16/2011 16:06:06
Next scn: 0xffff.ffffffff 01/01/1988 00:00:00
Enabled scn: 0x0000.0006ce7b (446075) 11/10/2011 22:40:23
Thread closed scn: 0x0000.000def9a (913306) 11/16/2011 16:06:06
Disk cksum: 0x5987 Calc cksum: 0x5987
Terminal recovery stop scn: 0x0000.00000000
Terminal recovery 01/01/1988 00:00:00
Most recent redo scn: 0x0000.00000000
Largest LWN: 0 blocks
End-of-redo stream : No
Unprotected mode
Miscellaneous flags: 0x0
这里不打算详细介绍具体命令的用户及更进一步的内容,有兴趣的朋友可以由此开始进一步的探索。
使用Oradebug修改Oracle SCN
Oracle SCN对于数据库运行、维护而言是至关重要的因素。在启动从mount到open过程中,主要是各种文件的SCN进行比较的行为。通常情况下,我们是不需要介入到Oracle SCN的取值和设置,甚至错误的干预可能会引起严重运行事故。
在之前的文章中,笔者介绍过使用隐含参数和跟踪事件来推动Oracle SCN前进的方法。但是,在11.2.0.2之后的版本中,Oracle关闭了这个通道,这种方法不在有效。在高版本情况下,我们是可以通过oradebug工具对SCN进行修改。
注意:这种方法比较危险,请不要在投产环境下进行测试。
1、实验环境说明
笔者使用Oracle 11g进行测试,版本为11.2.0.4。对应操作系统是Linux 6.5 64bit版本。
SQL> select * from v$version;
BANNER
--------------------------------------------------------------------------------
Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production
PL/SQL Release 11.2.0.4.0 - Production
CORE 11.2.0.4.0 Production
TNS for Linux: Version 11.2.0.4.0 - Production
NLSRTL Version 11.2.0.4.0 – Production
我们先聊聊Oracle的SCN。在数据库内部,SCN是一个单向递增的数字编号,控制文件、数据文件、在线Redo日志、归档日志和备份集合中,都包括这个数字编号。在内部文件中,SCN是通过Base和Wrap两个部分进行保存。Base是SCN编号的基础位,是通过32位二进制位进行保存。一旦超过这32位长度,系统会自动在Wrap进位。也就是说,Wrap表示的超过4G个数的进位次数。
使用Oracle oradebug修改SCN,可以在两个场景下进行,就是Oracle启动Open状态和Mount状态。下面分别进行说明。
2、Open状态下SCN修改
在Open状态,系统的SCN是在不断的向前推动,即使对外没有事务操作,系统内部SCN编号也在不断的前进。我们先将数据库进入open状态。
SQL> alter database open;
Database altered.
SQL> select CHECKPOINT_CHANGE#, current_scn from v$database;
CHECKPOINT_CHANGE# CURRENT_SCN
------------------ -----------
1753982 1754355
SQL> select dbms_flashback.get_system_change_number from dual;
GET_SYSTEM_CHANGE_NUMBER
------------------------
1754364
此时,从系统中提取出的SCN编号约为1754364,显然没有超过wrap的进位4G,变化为16进制如下:
SQL> select to_char(1754364, 'XXXXXXXX') from dual;
TO_CHAR(1754364,'XXXXXXXX')
---------------------------
1AC4FC
使用oradebug查看内存中SCN对应的变量。
SQL> oradebug setmypid
Statement processed.
SQL> oradebug dumpvar sga kcsgscn_
kcslf kcsgscn_ [06001AE70, 06001AEA0) = 001AC52A 00000000 00000000 00000000 00000065 00000000 00000000 00000000 00000000 00000000 6001AB50 00000000
其中,0x001AC52A近似SCN的Base部分。注意:Linux系统是Little位的操作系统,Base在前,Wrap在后。
SQL> select to_number('1AC52A','xxxxxx') from dual;
TO_NUMBER('1AC52A','XXXXXX')
----------------------------
1754410
下面计划将Base修改为1800000,查看16进制取值。
SQL> select to_char(1800000, 'XXXXXXXX') from dual;
TO_CHAR(1800000,'XXXXXXXX')
---------------------------
1B7740
使用poke命令将计算好的值写入进去。
SQL> oradebug poke 0x06001AE70 4 0x001B7740
BEFORE: [06001AE70, 06001AE74) = 001AC66F
AFTER: [06001AE70, 06001AE74) = 001B7740
SQL> oradebug DUMPvar SGA kcsgscn_
kcslf kcsgscn_ [06001AE70, 06001AEA0) = 001B7745 00000000 00000000 00000000 00000164 00000000 00000000 00000000 00000000 00000000 6001AB50 00000000
SQL>
poke命令中,第一位参数是对应写入的内存位数,第二位参数是写入长度,第三位参数是写入取值。默认写入取值是10进制,我们在这里指定写入16进制。
每一个取值段,用8个16进制对应,对应到数字位数是4位。此时查看Oracle情况。
SQL> select CHECKPOINT_CHANGE#, current_scn from v$database;
CHECKPOINT_CHANGE# CURRENT_SCN
------------------ -----------
1753982 1800400
SQL> select dbms_flashback.get_system_change_number from dual;
GET_SYSTEM_CHANGE_NUMBER
------------------------
1800402
SQL> select file#, checkpoint_change# from v$datafile;
FILE# CHECKPOINT_CHANGE#
---------- ------------------
1 1753982
2 1753982
3 1753982
4 1753982
5 1753982
6 1753982
7 1753982
7 rows selected
SQL> select file#, checkpoint_change# from v$datafile_header;
FILE# CHECKPOINT_CHANGE#
---------- ------------------
1 1753982
2 1753982
3 1753982
4 1753982
5 1753982
6 1753982
7 1753982
7 rows selected
从上面看,内存和控制文件中新的取值已经写入进去了。但是各个文件的头块和检查点还没有反应过来。此时可以使用checkpoint强制写入。
SQL> alter system checkpoint;
System altered.
SQL> select file#, checkpoint_change# from v$datafile;
FILE# CHECKPOINT_CHANGE#
---------- ------------------
1 1800422
2 1800422
3 1800422
4 1800422
5 1800422
6 1800422
7 1800422
7 rows selected
SQL> select file#, checkpoint_change# from v$datafile_header;
FILE# CHECKPOINT_CHANGE#
---------- ------------------
1 1800422
2 1800422
3 1800422
4 1800422
5 1800422
6 1800422
7 1800422
7 rows selected
SQL> select CHECKPOINT_CHANGE#, current_scn from v$database;
CHECKPOINT_CHANGE# CURRENT_SCN
------------------ -----------
1800422 1800433
此时,关闭重启系统也不会有问题。篇幅原因,不进行具体展示。那么,很多时候SCN错误是会影响到开启数据库的,我们可能都不能进入open状态。从mount状态下我们怎么修改SCN编号。
3、Mount状态修改SCN编号
我们测试进入mount状态。
SQL> startup mount
ORACLE instance started.
Total System Global Area 3540881408 bytes
Fixed Size 2258320 bytes
Variable Size 855640688 bytes
Database Buffers 2667577344 bytes
Redo Buffers 15405056 bytes
Database mounted.
此时,oradebug命令导出内存取值。
SQL> oradebug setmypid
Statement processed.
SQL> oradebug DUMPvar SGA kcsgscn_
kcslf kcsgscn_ [06001AE70, 06001AEA0) = 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 6001AB50 00000000
注意:在mount状态下,内存中的SCN取值都是0,包括base和wrap两部分。我们这次修改wrap从0到1。这个过程中,我们需要写入base和wrap两个部分,如果我们只写入了wrap部分,base部分保持0,那么系统运行的时候,会从base为0开始。
此时,需要查看一下当前文件里面SCN是多少。
SQL> select file#, checkpoint_change# from v$datafile;
FILE# CHECKPOINT_CHANGE#
---------- ------------------
1 1800920
2 1800920
3 1800920
4 1800920
5 1800920
6 1800920
7 1800920
7 rows selected
SQL> select file#, checkpoint_change# from v$datafile_header;
FILE# CHECKPOINT_CHANGE#
---------- ------------------
1 1800920
2 1800920
3 1800920
4 1800920
5 1800920
6 1800920
7 1800920
7 rows selected
SQL> select CHECKPOINT_CHANGE#, current_scn from v$database;
CHECKPOINT_CHANGE# CURRENT_SCN
------------------ -----------
1800920 0
计算1800920对应到16进制取值为:0x001B7AD8。下面分别写入base和wrap取值。
SQL> oradebug DUMPvar SGA kcsgscn_
kcslf kcsgscn_ [06001AE70, 06001AEA0) = 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 6001AB50 00000000
SQL> oradebug poke 0x06001AE70 4 0x001B7AD8
BEFORE: [06001AE70, 06001AE74) = 00000000
AFTER: [06001AE70, 06001AE74) = 001B7AD8
SQL> oradebug poke 0x06001AE74 4 0x00000001
BEFORE: [06001AE74, 06001AE78) = 00000000
AFTER: [06001AE74, 06001AE78) = 00000001
SQL> oradebug DUMPvar SGA kcsgscn_
kcslf kcsgscn_ [06001AE70, 06001AEA0) = 001B7AD8 00000001 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 6001AB50 00000000
启动数据库。
SQL> alter database open;
Database altered.
SQL> select CHECKPOINT_CHANGE#, current_scn from v$database;
CHECKPOINT_CHANGE# CURRENT_SCN
------------------ -----------
4296768217 4296768485
SQL> select file#, checkpoint_change# from v$datafile_header;
FILE# CHECKPOINT_CHANGE#
---------- ------------------
1 4296768217
2 4296768217
3 4296768217
4 4296768217
5 4296768217
6 4296768217
7 4296768217
7 rows selected
SQL> select file#, checkpoint_change# from v$datafile;
FILE# CHECKPOINT_CHANGE#
---------- ------------------
1 4296768217
2 4296768217
3 4296768217
4 4296768217
5 4296768217
6 4296768217
7 4296768217
7 rows selected
显然在open的时候,写入的checkpoint在所有文件中。写入的wrap头也比较清晰。
SQL> select 4296768217/(4*1024*1024*1024) from dual;
4296768217/(4*1024*1024*1024)
-----------------------------
1.0004193095956
SQL> oradebug DUMPvar SGA kcsgscn_
kcslf kcsgscn_ [06001AE70, 06001AEA0) = 001B7C1D 00000001 00000000 00000000 00000047 00000000 00000000 00000000 00000000 00000000 6001AB50 00000000
4、结论
使用oradebug直接修改内存SCN,是我们在故障修复时候非常快捷的方法。不过,快捷建立在对内部机制清晰理解的前提之下。所以,无论何种场景进行修复,有备份、可恢复是我们工作的基本前提。
Oracle系统表 smon_scn_time 的说明
一.SMON_SCN_TIME 表结构说明
SMON_SCN_TIME表存放的是SCN和Time之前的映射关系。 该表由SMON 进程负责维护。
SQL> desc smon_scn_time
Name Null? Type
------------------------------------------------- ----------------------------
THREAD NUMBER
TIME_MP NUMBER
TIME_DP DATE
SCN_WRP NUMBER
SCN_BAS NUMBER
NUM_MAPPINGS NUMBER
TIM_SCN_MAP RAW(1200)
SCN NUMBER
ORIG_THREAD NUMBER
SQL> alter session set nls_date_format='yyyy-mm-ddhh24:mi:ss';
Session altered.
SQL> select time_dp,scn from smon_scn_time where rownum<5;
TIME_DP SCN
------------------- ----------
2013-03-15 10:31:04 2092348
2013-03-15 10:35:49 2092452
2013-03-15 10:41:00 2092581
2013-03-15 10:45:46 2092682
在Oracle 11g中,该表的创建SQL在$ORACLE_HOME/rdbms/admin/dtxnspc.bsq 文件中。
create table smon_scn_time (
thread number, /* thread, compatibility */
time_mp number, /* time this recent scn represents */
time_dp date, /* time as date, compatibility */
scn_wrpnumber, /*scn.wrp, compatibility */
scn_bas number, /* scn.bas, compatibility */
num_mappings number,
tim_scn_map raw(1200),
scnnumber default 0, /* scn*/
orig_thread number default 0 /* for downgrade */
) cluster smon_scn_to_time_aux (thread)
/
create unique index smon_scn_time_tim_idxon smon_scn_time(time_mp)
tablespace SYSAUX
/
create unique index smon_scn_time_scn_idxon smon_scn_time(scn)
tablespace SYSAUX
/
我们可以直接delete掉SMON_SCN_TIME表中的记录:
SQL> delete from smon_scn_time;
2120 rows deleted.
SQL> commit;
Commit complete.
SQL> select count(1) from smon_scn_time;
COUNT(1)
----------
0
二.SMON_SCN_TIME表记录保存策略说明
2.1 Oracle 9i
根据MOS文档的说明:
How To Map SCN To Timestamp Before 10g? [ID365536.1]
SYS.SMON_SCN_TIMEwill have a maximum of 1440 rows and each record will be for a 5 minute period.Oracle maintains this information for a maximum of 5 days after which therecords will be recycled.
This means thatdata is stored 12 times per hour * 24 hours * 5 days = 1440 rows.
在Oracle 9i版本中,SMON_SCN_TIME 表中最多存放1440条记录。 SMON 进程每隔5分钟生成一次SCN和TIME 之前的映射,并更新到SMON_SCN_TIME表。该表的维护周期是5天。
因此该表最多存放的记录是:12*24*5=1440条记录。
超过1440条的记录在下次循环中会被删除。
2.2 Oracle 10g以后的版本
在oracle 10g以后的版本,SMON_SCN_TIME表的维护策略发生了变化。
根据MOS文档的说明:
High Executions Of Statement "deletefrom smon_scn_time..." [ID 375401.1]
The deletestatement deletes the oldest rows from smon_scn_time to clear space for newrows. SMON wakes up every 5 minutes and checks how many on-disk mappingswe have--the max is 144000.
--SMON进程每个5分钟唤醒一次来更新SCN和TIME之间的映射关系,并且检查SMON_SCN_TIME表中的记录数,该表的记录数最大是144000条。
The new mappingsare then added for the last period (since SMON last updated), and if this isover 144000, SMON will then issue the delete statement:
delete fromsmon_scn_time where thread=0 and time_mp = (select min(time_mp) fromsmon_scn_time where thread=0)
--SMON进程会把最新的SCN_TIME映射关系写入SMON_SCN_TIME表,如果该表的记录数超过144000条,那么就会执行上面的delete操作,删除最早的记录。
There will be anexecution of this each time SMON wakes to update smon_scn_time, and if onedeletion does not free enough mappings, then there will be multiple executions.
--SMON进程每次被唤醒都会更新SMON_SCN_TIME表,如果一次delete操作不能释放足够的空间映射空间,就会执行多次delete操作。
三.禁用SMON 进程对SMON_SCN_TIME 表的更新
可以设置12500事件停止SMON进程对SMON_SCN_TIME。
具体操作如下:
SQL> select count(1) from smon_scn_time;
COUNT(1)
----------
2115
SQL> alter system set events '12500trace name context forever, level 10';
System altered.
SQL> select sysdate from dual;
SYSDATE
-------------------
2013-03-20 13:06:15
SQL> select count(1) from smon_scn_time;
COUNT(1)
----------
2115
SQL> alter system set events '12500 tracename context off';
System altered.
SQL> select sysdate from dual;
SYSDATE
-------------------
2013-03-20 13:19:58
SQL> select count(1) from smon_scn_time;
COUNT(1)
----------
2119
四.SMON_SCN_TIME 表相关的2个案例
4.1 Oracle 9i SMON_SCN_TIME 表被锁
LOCK ON SYS.SMON_SCN_TIME [ID 747745.1]
4.1.1 现象
Oracle 9i,SYS.SMON_SCN_TIME 被 SMON 进程已排它锁占用,并且锁不能释放,导致数据库出现性能问题,并且SMON_SCN_TIME表中有大量的记录。
SQL> selectcount(*) from sys.smon_scn_time;
COUNT(*)
----------
137545
1 row selected.
--正常情况下,9i最多只能保存1440条记录。
SQL> select object_id from dba_objectswhere object_name = 'SMON_SCN_TIME';
OBJECT_ID
----------
575
1 row selected.
SQL> select * fromv$locked_object where object_id = 575;
XIDUSNXIDSLOT XIDSQN OBJECT_ID SESSION_ID
---------- ---------- ---------- ---------- ----------
ORACLE_USERNAME OS_USER_NAME PROCESS
------------------------------ ------------------------------ ------------
LOCKED_MODE
-----------
5 5 1494 575 164
dbadmin 4444350
3 <=Locked in row exclusive mode
4.1.2 处理方法
设置12500事件,停止SMON 进程更新SMON_SCN_TIME表,然后手工删除表中的记录。
SQL> alter system set events '12500 tracename context forever, level 10';
SQL> delete from smon_scn_time;
SQL> commit;
SQL> alter system set events '12500 tracename context off';
Now restart the instance.
4.2 Oracle 10g SMON_SCN_TIME 表频繁的被delete
High Executions Of Statement "deletefrom smon_scn_time..." [ID 375401.1]
4.2.1 现象
AWR报告显示smon_scn_time的删除操作频繁的被执行。
delete fromsmon_scn_time where thread=0 and time_mp = (select min(time_mp) fromsmon_scn_time where thread=0);
导致这种现象的原因是SMON_SCN_TIME表和表上的索引不一致。需要重建SMON_SCN_TIME上的索引。
SQL> analyze table smon_scn_timevalidate structure cascade;
analyze table smon_scn_time validate structure cascade
*
ERROR at line 1 :
ORA-01499: table/Index Cross Reference Failure - see trace file
4.2.2 处理方法
connect / as sysdba
drop index smon_scn_time_scn_idx;
drop index smon_scn_time_tim_idx;
create unique index smon_scn_time_scn_idx on smon_scn_time(scn);
create unique index smon_scn_time_tim_idx on smon_scn_time(time_mp);
analyze table smon_scn_time validate structure cascade;
由oradebug poke推进scn理解scn base及scn wrap系列一
原文地址:由oradebug poke推进scn理解scn base及scn wrap系列一 作者:wisdomone1
背景
在v$transaction会看到scn,其中又分为scn base及scn wrap,这到底怎么回事呢?而且很多ORA报错与SCN有关,如果多了解一些SCN相关的知识,也便于我们分析解决问题。
结论
1,oradebug poke可以推进SCN,分为在数据库OPEN及MOUNT皆可以oradebug setmypid
oradebug DUMPvar SGA kcsgscn_
oradebug poke 0x060012658 4 1000
2,关于kcsgscn_变量我是在BAIDU上面查的,而关于SCN到底是对应内存是哪块区域,我是采用多次运行oradebug DUMPvar SGA kcsgscn_,看哪些内存的值在变化,基本就是哪块
3,oradebug poke 0x060012658 4 1000 就是推进SCN的命令,具体含义如下:
oradebug poke 内存地址 长度 要修改的内容 ,注意这个要修改的内容必须是十进制,如果是16进制会报上述的错(这里我采用了反向对比思维),且这里长度是前4个字节
4,如果是在OPEN状态下推进SCN,oradebug DUMPvar SGA kcsgscn_是有值的,而在MOUNT因为数据库没有打开,所在是空的,全是0,那么如何调整SCN,可以基于每个文件头的BLOCK 1的数据结构kscnbas及kscnwrp进行调整
这个数据结构对应select file#,name,checkpoint_change# from v$datafile;
BBED> map
File: /home/ora10g/asia/asia/users01.dbf (0)
Block: 1 Dba:0x00000000
------------------------------------------------------------
Data File Header
struct kcvfh, 676 bytes @0
ub4 tailchk @8188
BBED> p kcvfh
struct kcvfhckp, 36 bytes @484
struct kcvcpscn, 8 bytes @484
ub4 kscnbas @484 0x028f5c58 --scn base
ub2 kscnwrp @488 0x0000 --scn wrap
5,select current_scn from v$database,这个SCN是一直在变化,可以叫作内存SCN
6,scn是由scn base及scn wrap构成的,当scn base达到一定程度,scn wrap则会递增,一般情况下scn wrap是0,不会变化
7,scn base及scn wrap也是数据块中的数据结构,可见scn base是4个字节,而scn wrap是2个字节
也就是说scn base要用4个字节用完,scn wrap就会递增
依理推理,4个字节为 power(2,32),也就是达到这个数据时,scn base就会归0,scn wrap递增1
8,基于 select file#,name,checkpoint_change# from v$datafile;和数据结构的scn base及scn wrap可知scn计算公式为
scn=scn wrap * power(2,32)+scn base
9,进一步引申,也可以计算出为scn最大值,因为scn base及scn wrap是由4个字节及4个字节构成的,而这些字节表示的数据范围是有限的
10,如果过小调整scn远小于checkpoint_change#,会引发ora-600 2662,当然解决也很容易,基于checkpoint_change#调大scn即可
否则2662会引发数据库强制关闭
测试
SQL> select * from v$version where rownum=1;
BANNER
----------------------------------------------------------------
Oracle Database 10g Enterprise Edition Release 10.2.0.5.0 - 64bi
---可见事务也有scn base及scn wrap的概念
SQL> desc v$transaction;
Name Null? Type
----------------- -------- ------------
ADDR RAW(8)
XIDUSN NUMBER
XIDSLOT NUMBER
XIDSQN NUMBER
UBAFIL NUMBER
UBABLK NUMBER
UBASQN NUMBER
UBAREC NUMBER
STATUS VARCHAR2(16)
START_TIME VARCHAR2(20)
START_SCNB NUMBER --scn base
START_SCNW NUMBER --scn wrap
START_UEXT NUMBER
START_UBAFIL NUMBER
START_UBABLK NUMBER
START_UBASQN NUMBER
START_UBAREC NUMBER
SES_ADDR RAW(8)
FLAG NUMBER
SPACE VARCHAR2(3)
RECURSIVE VARCHAR2(3)
NOUNDO VARCHAR2(3)
PTX VARCHAR2(3)
NAME VARCHAR2(256
)
PRV_XIDUSN NUMBER
PRV_XIDSLT NUMBER
PRV_XIDSQN NUMBER
PTX_XIDUSN NUMBER
PTX_XIDSLT NUMBER
PTX_XIDSQN NUMBER
DSCN-B NUMBER --scn base
DSCN-W NUMBER --scn wrap
USED_UBLK NUMBER
USED_UREC NUMBER
LOG_IO NUMBER
PHY_IO NUMBER
CR_GET NUMBER
CR_CHANGE NUMBER
START_DATE DATE
DSCN_BASE NUMBER --scn base
DSCN_WRAP NUMBER --scn wrap
START_SCN NUMBER
DEPENDENT_SCN NUMBER
XID RAW(8)
PRV_XID RAW(8)
PTX_XID RAW(8)
---普通数据块也有scn base及scn wrap的概念,且scn base为4个字节,scn wrap为2个字节
BBED> map
File: /home/ora10g/asia/asia/users01.dbf (0)
Block: 12 Dba:0x00000000
------------------------------------------------------------
KTB Data Block (Table/Cluster)
struct kcbh, 20 bytes @0
struct ktbbh, 72 bytes @20
struct kdbh, 14 bytes @100
struct kdbt[1], 4 bytes @114
sb2 kdbr[32] @118
ub1 freespace[7814] @182
ub1 rowdata[192] @7996
ub4 tailchk @8188
BBED> p kcbh
struct kcbh, 20 bytes @0
ub1 type_kcbh @0 0x06
ub1 frmt_kcbh @1 0xa2
ub1 spare1_kcbh @2 0x00
ub1 spare2_kcbh @3 0x00
ub4 rdba_kcbh @4 0x0100000c
ub4 bas_kcbh @8 0x00048e91 --scn base
ub2 wrp_kcbh @12 0x0000 --scn wrap
ub1 seq_kcbh @14 0x02
ub1 flg_kcbh @15 0x06 (KCBHFDLC, KCBHFCKV)
ub2 chkval_kcbh @16 0x7e45
ub2 spare3_kcbh @18 0x0000
BBED>
---数据文件头也有scn base及scn wrap的概念
BBED> map
File: /home/ora10g/asia/asia/users01.dbf (0)
Block: 1 Dba:0x00000000
------------------------------------------------------------
Data File Header
struct kcvfh, 676 bytes @0
ub4 tailchk @8188
BBED> p kcvfh
struct kcvfh, 676 bytes @0
struct kcvfhbfh, 20 bytes @0
ub1 type_kcbh @0 0x0b
ub1 frmt_kcbh @1 0xa2
ub1 spare1_kcbh @2 0x00
ub1 spare2_kcbh @3 0x00
ub4 rdba_kcbh @4 0x01000001
ub4 bas_kcbh @8 0x00000000
ub2 wrp_kcbh @12 0x0000
从上述我们发现基本scn wrap全是0,那么何时scn会变成非0呢,我想到了推进SCN,然后对比DUMP数据块,可以了其原理了
SQL> select current_scn,checkpoint_change# from v$database;
CURRENT_SCN CHECKPOINT_CHANGE#
----------- ------------------
311981 296387
SQL> alter session set events 'immediate trace name adjust_scn level 1';
Session altered.
SQL> select current_scn,checkpoint_change# from v$database;
CURRENT_SCN CHECKPOINT_CHANGE#
----------- ------------------
311996 296387
可见上述推进SCN太慢了
SQL> select 311996-311981 from dual;
311996-311981
-------------
15
---且ALERT会报权限不足的错误信息
Mon Nov 30 23:46:36 EST 2015
Errors in file /home/ora10g/admin/asia/udump/asia_ora_23849.trc:
ORA-01031: insufficient privileges
---上述推进SCN方法太慢,我们尝试另一种快速推进SCN的方法,不过要重启库到MOUNT状态
SQL> shutdown immediate
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> startup mount
ORACLE instance started.
Total System Global Area 901775360 bytes
Fixed Size 2100424 bytes
Variable Size 226493240 bytes
Database Buffers 666894336 bytes
Redo Buffers 6287360 bytes
Database mounted.
---可见MOUNT状态下CURRENT_SCN为0,其它SCN列皆有值
SQL> select current_scn,checkpoint_change# from v$database;
CURRENT_SCN CHECKPOINT_CHANGE#
----------- ------------------
0 312204
SQL> select file#,name,checkpoint_change# from v$datafile;
FILE# NAME CHECKPOINT_CHANGE#
---------- -------------------------------------------------- ------------------
1 /home/ora10g/asia/asia/system01.dbf 312204
2 /home/ora10g/asia/asia/undotbs01.dbf 312204
3 /home/ora10g/asia/asia/sysaux01.dbf 312204
4 /home/ora10g/asia/asia/users01.dbf 312204
SQL> select file#,checkpoint_change# from v$datafile_header;
FILE# CHECKPOINT_CHANGE#
---------- ------------------
1 312204
2 312204
3 312204
4 312204
SQL> select to_char('312204','xxxxxxx') from dual;
TO_CHAR(
--------
4c38c
---bbed查看数据文件的SCN,可知是4c38c
struct kcvfhckp, 36 bytes @484
struct kcvcpscn, 8 bytes @484
ub4 kscnbas @484 0x0004c38c
ub2 kscnwrp @488 0x0000
---用10015事件推进SCN发现没有变化,可见在MOUNT状态下不生效推进SCN
SQL> alter session set events '10015 trace name adjust_scn level 1';
Session altered.
SQL> select current_scn,checkpoint_change# from v$database;
CURRENT_SCN CHECKPOINT_CHANGE#
----------- ------------------
0 312204
打开数据库看看有无生效,也是没有效果
SQL> alter database open;
Database altered.
SQL> select current_scn,checkpoint_change# from v$database;
CURRENT_SCN CHECKPOINT_CHANGE#
----------- ------------------
312409 312207
SQL> select file#,name,checkpoint_change# from v$datafile;
FILE# NAME CHECKPOINT_CHANGE#
---------- -------------------------------------------------- ------------------
1 /home/ora10g/asia/asia/system01.dbf 312207
2 /home/ora10g/asia/asia/undotbs01.dbf 312207
3 /home/ora10g/asia/asia/sysaux01.dbf 312207
4 /home/ora10g/asia/asia/users01.dbf 312207
---换另一种方法,用ORADEBUG POKE推进SCN
SQL> shutdown immediate
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> startup mount
ORACLE instance started.
Total System Global Area 901775360 bytes
Fixed Size 2100424 bytes
Variable Size 226493240 bytes
Database Buffers 666894336 bytes
Redo Buffers 6287360 bytes
Database mounted.
SQL> oradebug setmypid
Statement processed.
SQL> oradebug DUMPvar SGA kcsgscn_
kcslf kcsgscn_ [060012658, 060012688) = 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 60012338 00000000
SQL>
SQL> select file#,name,checkpoint_change# from v$datafile;
FILE# NAME CHECKPOINT_CHANGE#
---------- -------------------------------------------------- ------------------
1 /home/ora10g/asia/asia/system01.dbf 312714
2 /home/ora10g/asia/asia/undotbs01.dbf 312714
3 /home/ora10g/asia/asia/sysaux01.dbf 312714
4 /home/ora10g/asia/asia/users01.dbf 312714
SQL> select to_char('312714','xxxxxx') from dual;
TO_CHAR
-------
4c58a
SQL> oradebug poke 0x060012658 8 0x0004c58a
BEFORE: [060012658, 060012660) = 00000000 00000000
AFTER: [060012658, 060012660) = 0004C58A 00000000
SQL> oradebug DUMPvar SGA kcsgscn
kcslf kcsgscn_ [060012658, 060012688) = 0004C58A 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 60012338 00000000
SQL>
SQL> alter database open;
Database altered.
SQL> select file#,name,checkpoint_change# from v$datafile;
FILE# NAME CHECKPOINT_CHANGE#
---------- -------------------------------------------------- ------------------
1 /home/ora10g/asia/asia/system01.dbf 312717
2 /home/ora10g/asia/asia/undotbs01.dbf 312717
3 /home/ora10g/asia/asia/sysaux01.dbf 312717
4 /home/ora10g/asia/asia/users01.dbf 312717
好像没起作用
SQL> select current_scn,checkpoint_change# from v$database;
CURRENT_SCN CHECKPOINT_CHANGE#
----------- ------------------
312891 312717
---换个思路,试试在数据库打开时推进SCN
SQL> select file#,name,checkpoint_change# from v$datafile;
FILE# NAME CHECKPOINT_CHANGE#
---------- -------------------------------------------------- ------------------
1 /home/ora10g/asia/asia/system01.dbf 313429
2 /home/ora10g/asia/asia/undotbs01.dbf 313429
3 /home/ora10g/asia/asia/sysaux01.dbf 313429
4 /home/ora10g/asia/asia/users01.dbf 313429
SQL> select current_scn,checkpoint_change# from v$database;
CURRENT_SCN CHECKPOINT_CHANGE#
----------- ------------------
313917 313429
SQL> select to_char('313917','xxxxxxxxxx') from dual;
TO_CHAR('31
-----------
4ca3d
---经间隔多次运行如下ORADEBUG命令,我分析CURRENT_SCN就是内存中的第1部分(因为就这部分信息在变化,其它信息是固定的)
SQL> oradebug setmypid
Statement processed.
SQL> oradebug DUMPvar SGA kcsgscn_
kcslf kcsgscn_ [060012658, 060012688) = 0004CAD4 00000000 00000000 00000000 00000113 00000000 00000000 00000000 00000000 00000000 60012338 00000000
SQL>
SQL>
SQL>
SQL> oradebug DUMPvar SGA kcsgscn_
kcslf kcsgscn_ [060012658, 060012688) = 0004CAD6 00000000 00000000 00000000 00000114 00000000 00000000 00000000 00000000 00000000 60012338 00000000
SQL>
SQL>
SQL> oradebug DUMPvar SGA kcsgscn_
kcslf kcsgscn_ [060012658, 060012688) = 0004CAD7 00000000 00000000 00000000 00000115 00000000 00000000 00000000 00000000 00000000 60012338 00000000
SQL>
---所以我们只要改第1部分信息的内容即可
SQL> oradebug poke 0x060012658 4 FFFFA3523
ORA-01858: a non-numeric character was found where a numeric was expected
SQL>
可见oradeug poke 的含义是oradebug poke 内存地址 长度 要修改的内容 ,注意这个要修改的内容必须是十进制,如果是16进制会报上述的错(这里我采用了反向对比思维),且这里长度是前4个字节
SQL> oradebug poke 0x060012658 4 1000
BEFORE: [060012658, 06001265C) = 0004CB41
AFTER: [060012658, 06001265C) = 000003E8
SQL> select to_number('3E8','xxxxxxxxx') from dual;
TO_NUMBER('3E8','XXXXXXXXX')
----------------------------
1000
---而且上述由于把SCN改得过小,小于数据文件及控制文件的SCN,会报ORA-600 的2662错误,处理很简单,快速基于checkpoint_change#把SCN变大即可,否则过会数据库就会DOWN机
SQL> select current_scn,checkpoint_change# from v$database;
select current_scn,checkpoint_change# from v$database
*
ERROR at line 1:
ORA-00600: internal error code, arguments: [2662], [0], [71], [0], [333548],
[0], [], []
---基于上述分析,因为原来SCN是313917,我们加到19999999999
SQL> oradebug setmypid
Statement processed.
SQL> select power(2,32) from dual;
POWER(2,32)
-----------
4294967296
如果把SCN调整为上述的值,马上ALAERT会报错
SQL> oradebug DUMPvar SGA kcsgscn_
kcslf kcsgscn_ [060012658, 060012688) = 000565AE 00000000 00000000 00000000 00000075 00000000 00000000 00000000 00000000 00000000 60012338 00000000
SQL> oradebug poke 0x060012658 4 4294967296
BEFORE: [060012658, 06001265C) = 000565B3
AFTER: [060012658, 06001265C) = 00000000
Tue Dec 01 01:27:33 EST 2015
Errors in file /home/ora10g/admin/asia/bdump/asia_cjq0_27711.trc:
ORA-00604: error occurred at recursive SQL level 1
ORA-08176: consistent read failure; rollback data not available
--所以可见SCN也不能随意去调太大,ORACLE内部肯定有个控制算法的,否则会把库搞DOWN掉
SQL> oradebug poke 0x060012658 4 42949670
BEFORE: [060012658, 06001265C) = 00000003
AFTER: [060012658, 06001265C) = 028F5C26
SQL> alter system checkpoint;
System altered.
SQL> alter system checkpoint;
System altered.
SQL> select file#,name,checkpoint_change# from v$datafile;
FILE# NAME CHECKPOINT_CHANGE#
---------- -------------------------------------------------- ------------------
1 /home/ora10g/asia/asia/system01.dbf 42949720
2 /home/ora10g/asia/asia/undotbs01.dbf 42949720
3 /home/ora10g/asia/asia/sysaux01.dbf 42949720
4 /home/ora10g/asia/asia/users01.dbf 42949720
---可见SCN已经调整为指定的SCN了
SQL> select current_scn,checkpoint_change# from v$database;
CURRENT_SCN CHECKPOINT_CHANGE#
----------- ------------------
42949724 42949720
---换个思路继糿研究SCN BASE及SCN WRAP,如果我一直增加SCN BASE,SCN WRAP会有变化呢,我理解肯定是SCN BASE大到一定程度,SCN WRAP就会有变化
BBED> map
File: /home/ora10g/asia/asia/users01.dbf (0)
Block: 1 Dba:0x00000000
------------------------------------------------------------
Data File Header
struct kcvfh, 676 bytes @0
ub4 tailchk @8188
BBED> p kcvfh
struct kcvfhckp, 36 bytes @484
struct kcvcpscn, 8 bytes @484
ub4 kscnbas @484 0x028f5c58 --scn base
ub2 kscnwrp @488 0x0000
SQL> select to_number('&x','xxxxxxxx') from dual;
Enter value for x: 28f5c58
old 1: select to_number('&x','xxxxxxxx') from dual
new 1: select to_number('28f5c58','xxxxxxxx') from dual
TO_NUMBER('28F5C58','XXXXXXXX')
-------------------------------
42949720
BBED> set offset 484
OFFSET 484
BBED> dump count 5
File: /home/ora10g/asia/asia/users01.dbf (0)
Block: 1 Offsets: 484 to 488 Dba:0x00000000
------------------------------------------------------------------------
585c8f02 00
<32 bytes="" per="" line="">
SQL> select power(2,31) from dual;
POWER(2,31)
-----------
2147483648
SQL> select to_char('2147483648','xxxxxxxxx') from dual;
TO_CHAR('2
----------
80000000
BBED> modify /x 00000080
Warning: contents of previous BIFILE will be lost. Proceed? (Y/N) Y
File: /home/ora10g/asia/asia/users01.dbf (0)
Block: 1 Offsets: 484 to 488 Dba:0x00000000
------------------------------------------------------------------------
00000080 00
<32 bytes="" per="" line="">
--还要调整tailchk
可以看到tailchk校验由ub4 bas_kcbh的低4位+ub1 type_kcbh+ub1 seq_kcbh
BBED> p tailchk
ub4 tailchk @8188 0x00000b01
ub4 bas_kcbh @8 0x00000000
ub1 type_kcbh @0 0x0b
ub1 seq_kcbh @14 0x01
BBED> sum apply
Check value for File 0, Block 1:
current = 0x2dac, required = 0x2dac
---调整后
struct kcvfhckp, 36 bytes @484
struct kcvcpscn, 8 bytes @484
ub4 kscnbas @484 0x80000000
ub2 kscnwrp @488 0x0000
BBED> p tailchk
ub4 tailchk @8188 0x00000b01
SQL> conn scott/system
Connected.
SQL> create table t_modafter(a int);
Table created.
SQL> insert into t_modafter values(1);
1 row created.
SQL> commit;
Commit complete.
SQL> conn /as sysdba
Connected.
SQL> alter system checkpoint;
System altered.
SQL> alter system flush buffer_cache;
System altered.
---调整scn base到最大值-1
SQL> select power(2,32)-1 from dual;
POWER(2,32)-1
-------------
4294967295
SQL> select to_char('4294967295','xxxxxxxxxx') from dual;
TO_CHAR('42
-----------
ffffffff
---报错可以分2步进行,即先2个字节进行,然后再把余下的2个字节修改完
BBED> modify /x ffffffff
BBED-00209: invalid number (ffffffff)
BBED> modify /x ffff
Warning: contents of previous BIFILE will be lost. Proceed? (Y/N) Y
File: /home/ora10g/asia/asia/users01.dbf (0)
Block: 1 Offsets: 484 to 488 Dba:0x00000000
------------------------------------------------------------------------
ffff0080 00
<32 bytes="" per="" line="">
BBED> set offset 486
OFFSET 486
BBED> dump
File: /home/ora10g/asia/asia/users01.dbf (0)
Block: 1 Offsets: 486 to 488 Dba:0x00000000
------------------------------------------------------------------------
008000
<32 bytes="" per="" line="">
BBED> modify /x ffff
File: /home/ora10g/asia/asia/users01.dbf (0)
Block: 1 Offsets: 486 to 488 Dba:0x00000000
------------------------------------------------------------------------
ffff00
<32 bytes="" per="" line="">
BBED> dump
File: /home/ora10g/asia/asia/users01.dbf (0)
Block: 1 Offsets: 484 to 486 Dba:0x00000000
------------------------------------------------------------------------
ffffff
<32 bytes="" per="" line="">
BBED> p kcvfh
struct kcvfhckp, 36 bytes @484
struct kcvcpscn, 8 bytes @484
ub4 kscnbas @484 0xffffffff scn_base已经调整为 power(2,32)-1 ,其中32代表4个字节,每个字节byte即8bit,所以就是32个bit,可以表示的数据即power(2,32)
ub2 kscnwrp @488 0x0000
SQL> alter system flush buffer_cache;
System altered.
SQL> alter system checkpoint;
System altered.
BBED> p kcvfh
struct kcvfhckp, 36 bytes @484
struct kcvcpscn, 8 bytes @484
ub4 kscnbas @484 0x00000002
ub2 kscnwrp @488 0x0001 ---看到没,SCN WRAP有值了,哈哈说明,SCN BASE大到一定程度,它就有值了
SQL> select file#,name,checkpoint_change# from v$datafile;
FILE# NAME CHECKPOINT_CHANGE#
---------- -------------------------------------------------- ------------------
1 /home/ora10g/asia/asia/system01.dbf 4294967298
2 /home/ora10g/asia/asia/undotbs01.dbf 4294967298
3 /home/ora10g/asia/asia/sysaux01.dbf 4294967298
4 /home/ora10g/asia/asia/users01.dbf 4294967298
可见scn=scn wrap * power(2,32)+scn base
SQL> select 1*4294967296+2 from dual;
1*4294967296+2
--------------
4294967298
也就是说scn wrap有值时,scn又开始从0开始计数,由此可见ORACLE设计的精妙所在,再深入一些,也可以知道SCN最大值是什么,哈哈
了解你所不知道的SMON功能(十):维护SMON_SCN_TIME字典基表
SMON后台进程的作用还包括维护SMON_SCN_TIME基表。
SMON_SCN_TIME基表用于记录过去时间段中SCN(system change number)与具体的时间戳(timestamp)之间的映射关系,因为是采样记录这种映射关系,所以SMON_SCN_TIME可以较为较为粗糙地(不精确地)定位某个SCN的时间信息。实际的SMON_SCN_TIME是一张cluster table簇表。

SMON_SCN_TIME时间映射表最大的用途是为闪回类型的查询(flashback type queries)提供一种将时间映射为SCN的途径(The SMON time mapping is mainly for flashback type queries to map a time to an SCN)。
Metalink文档介绍了SMON更新SMON_SCN_TIME的规律:
- 在版本10g中SMON_SCN_TIME每6秒钟被更新一次(In Oracle Database 10g, smon_scn_time is updated every 6 seconds hence that is the minimum time that the flashback query time needs to be behind the timestamp of the first change to the table.)
- 在版本9.2中SMON_SCN_TIME每5分钟被更新一次(In Oracle Database 9.2, smon_scn_time is updated every 5 minutes hence the required delay between the flashback time and table properties change is at least 5 minutes.)
另外从10g开始SMON也会清理SMON_SCN_TIME中的记录了,SMON后台进程会每5分钟被唤醒一次,检查SMON_SCN_TIME在磁盘上的映射记录总数,若总数超过144000条,则会使用以下语句删除最老的一条记录(time_mp最小):
delete from smon_scn_time where thread = 0 and time_mp = (select min(time_mp) from smon_scn_time where thread = 0)
若仅仅删除一条记录不足以获得足够的空间,那么SMON会反复多次执行以上DELETE语句。
触发场景
虽然Metalink文档指出了在10g中SMON会以每6秒一次的频率更新SMON_SCN_TIME基表,但是实际观测可以发现更新频率与SCN的增长速率相关,在较为繁忙的实例中SCN的上升极快时SMON可能会以6秒一次的最短间隔频率更新 , 但是在空闲的实例中SCN增长较慢,则仍会以每5或10分钟一次频率更新,例如:
[oracle@vrh8 ~]$ ps -ef|grep smon|grep -v grep oracle 3484 1 0 Nov12 ? 00:00:02 ora_smon_G10R21 SQL> select * from v$version; BANNER ---------------------------------------------------------------- Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - 64bi PL/SQL Release 10.2.0.1.0 - Production CORE 10.2.0.1.0 Production TNS for Linux: Version 10.2.0.1.0 - Production NLSRTL Version 10.2.0.1.0 - Production SQL> select * from global_name; GLOBAL_NAME -------------------------------------------------------------------------------- www.askmaclean.com & www.askmaclean.com SQL> oradebug setospid 3484; Oracle pid: 8, Unix process pid: 3484, image: oracle@vrh8.oracle.com (SMON) SQL> oradebug event 10500 trace name context forever,level 10 : 10046 trace name context forever,level 12; Statement processed. SQL> SQL> oradebug tracefile_name; /s01/admin/G10R21/bdump/g10r21_smon_3484.trc /* 等待一定时间 */
找出SMON trace文件中insert数据到SMON_SCN_TIME的记录:
grep -A20 "insert into smon_scn_time" /s01/admin/G10R21/bdump/g10r21_smon_3484.trc insert into smon_scn_time (thread, time_mp, time_dp, scn, scn_wrp, scn_bas, num_mappings, tim_scn_map) values (0, :1, :2, :3, :4, :5, :6, :7) END OF STMT PARSE #4:c=0,e=43,p=0,cr=0,cu=0,mis=0,r=0,dep=1,og=4,tim=1290280848899596 BINDS #4: kkscoacd Bind#0 oacdty=02 mxl=22(22) mxlc=00 mal=00 scl=00 pre=00 oacflg=00 fl2=0001 frm=00 csi=00 siz=24 off=0 kxsbbbfp=7fb29844edb8 bln=22 avl=06 flg=05 value=767145793 Bind#1 oacdty=12 mxl=07(07) mxlc=00 mal=00 scl=00 pre=00 oacflg=10 fl2=0001 frm=00 csi=00 siz=8 off=0 kxsbbbfp=7fff023ae780 bln=07 avl=07 flg=09 value="11/14/2011 0:3:13" Bind#2 oacdty=02 mxl=22(04) mxlc=00 mal=00 scl=00 pre=00 oacflg=10 fl2=0001 frm=00 csi=00 siz=24 off=0 kxsbbbfp=7fff023ae70c bln=22 avl=04 flg=09 value=954389 Bind#3 -- insert into smon_scn_time (thread, time_mp, time_dp, scn, scn_wrp, scn_bas, num_mappings, tim_scn_map) values (0, :1, :2, :3, :4, :5, :6, :7) END OF STMT PARSE #1:c=0,e=21,p=0,cr=0,cu=0,mis=0,r=0,dep=1,og=4,tim=1290281434933390 BINDS #1: kkscoacd Bind#0 oacdty=02 mxl=22(22) mxlc=00 mal=00 scl=00 pre=00 oacflg=00 fl2=0001 frm=00 csi=00 siz=24 off=0 kxsbbbfp=7fb29844edb8 bln=22 avl=06 flg=05 value=767146393 Bind#1 oacdty=12 mxl=07(07) mxlc=00 mal=00 scl=00 pre=00 oacflg=10 fl2=0001 frm=00 csi=00 siz=8 off=0 kxsbbbfp=7fff023ae780 bln=07 avl=07 flg=09 value="11/14/2011 0:13:13" Bind#2 oacdty=02 mxl=22(04) mxlc=00 mal=00 scl=00 pre=00 oacflg=10 fl2=0001 frm=00 csi=00 siz=24 off=0 kxsbbbfp=7fff023ae70c bln=22 avl=04 flg=09 value=954720 Bind#3 -- insert into smon_scn_time (thread, time_mp, time_dp, scn, scn_wrp, scn_bas, num_mappings, tim_scn_map) values (0, :1, :2, :3, :4, :5, :6, :7) END OF STMT PARSE #3:c=0,e=20,p=0,cr=0,cu=0,mis=0,r=0,dep=1,og=4,tim=1290281727955249 BINDS #3: kkscoacd Bind#0 oacdty=02 mxl=22(22) mxlc=00 mal=00 scl=00 pre=00 oacflg=00 fl2=0001 frm=00 csi=00 siz=24 off=0 kxsbbbfp=7fb29844e960 bln=22 avl=06 flg=05 value=767146993 Bind#1 oacdty=12 mxl=07(07) mxlc=00 mal=00 scl=00 pre=00 oacflg=10 fl2=0001 frm=00 csi=00 siz=8 off=0 kxsbbbfp=7fff023ae780 bln=07 avl=07 flg=09 value="11/14/2011 0:23:13" Bind#2 oacdty=02 mxl=22(04) mxlc=00 mal=00 scl=00 pre=00 oacflg=10 fl2=0001 frm=00 csi=00 siz=24 off=0 kxsbbbfp=7fff023ae70c bln=22 avl=04 flg=09 value=954926 Bind#3 insert into smon_scn_time (thread, time_mp, time_dp, scn, scn_wrp, scn_bas, num_mappings, tim_scn_map) values (0, :1, :2, :3, :4, :5, :6, :7) END OF STMT PARSE #4:c=0,e=30,p=0,cr=0,cu=0,mis=0,r=0,dep=1,og=4,tim=1290282313990553 BINDS #4: kkscoacd Bind#0 oacdty=02 mxl=22(22) mxlc=00 mal=00 scl=00 pre=00 oacflg=00 fl2=0001 frm=00 csi=00 siz=24 off=0 kxsbbbfp=7fb29844edb8 bln=22 avl=06 flg=05 value=767147294 Bind#1 oacdty=12 mxl=07(07) mxlc=00 mal=00 scl=00 pre=00 oacflg=10 fl2=0001 frm=00 csi=00 siz=8 off=0 kxsbbbfp=7fff023ae780 bln=07 avl=07 flg=09 value="11/14/2011 0:28:14" Bind#2 oacdty=02 mxl=22(04) mxlc=00 mal=00 scl=00 pre=00 oacflg=10 fl2=0001 frm=00 csi=00 siz=24 off=0 kxsbbbfp=7fff023ae70c bln=22 avl=04 flg=09 value=955036 Bind#3
可以通过以上INSERT语句的TIME_DP绑定变量值中发现其更新SMON_SCN_TIME的时间规律,一般为5或10分钟一次。这说明SMON_SCN_TIME的更细频率与数据库实例的负载有关,其最短的间隔是每6秒一次,最长的间隔为10分钟一次。
由于SMON_SCN_TIME的更新频率问题可能引起ORA-01466错误,详见:
Error ORA-01466 while executing a flashback query. [ID 281510.1]
由于SMON_SCN_TIME的数据不一致可能引起ORA-00600[6711]或频繁地执行”delete from smon_scn_time”删除语句,详见:
ORA-00600[6711]错误一例
High Executions Of Statement “delete from smon_scn_time…” [ID 375401.1]
SMON维护SMON_SCN_TIME时相关的Stack CALL,ktf_scn_time是更新SMON_SCN_TIME的主要函数:
ksedst ksedmp ssexhd kghlkremf kghalo kghgex kghalf kksLoadChild kxsGetRuntimeLock kksfbc
kkspsc0 kksParseCursor opiosq0 opiall0 opikpr opiodr rpidrus skgmstack rpidru rpiswu2 kprball ktf_scn_time ktmmon ktmSmonMain ksbrdp opirip opidrv sou2o opimai_real main main_opd_entry
SMON 还可能使用以下SQL语句维护SMON_SCN_TIME字典基表:
select smontabv.cnt,
smontab.time_mp,
smontab.scn,
smontab.num_mappings,
smontab.tim_scn_map,
smontab.orig_thread
from smon_scn_time smontab,
(select max(scn) scnmax,
count(*) + sum(NVL2(TIM_SCN_MAP, NUM_MAPPINGS, 0)) cnt
from smon_scn_time
where thread = 0) smontabv
where smontab.scn = smontabv.scnmax
and thread = 0
insert into smon_scn_time
(thread,
time_mp,
time_dp,
scn,
scn_wrp,
scn_bas,
num_mappings,
tim_scn_map)
values
(0, :1, :2, :3, :4, :5, :6, :7)
update smon_scn_time
set orig_thread = 0,
time_mp = :1,
time_dp = :2,
scn = :3,
scn_wrp = :4,
scn_bas = :5,
num_mappings = :6,
tim_scn_map = :7
where thread = 0
and scn = (select min(scn) from smon_scn_time where thread = 0)
delete from smon_scn_time
where thread = 0
and scn = (select min(scn) from smon_scn_time where thread = 0)
如何禁止SMON更新SMON_SCN_TIME基表
可以通过设置诊断事件event=’12500 trace name context forever, level 10’来禁止SMON更新SMON_SCN_TIME基表(Setting the 12500 event at system level should stop SMON from updating the SMON_SCN_TIME table.):
SQL> alter system set events '12500 trace name context forever, level 10'; System altered.
一般我们不推荐禁止SMON更新SMON_SCN_TIME基表,因为这样会影响flashback Query闪回查询的正常使用,但是在某些异常恢复的场景中SMON_SCN_TIME数据讹误可能导致实例的Crash,那么可以利用以上12500事件做到不触发SMON_SCN_TIME被更新。
如何手动清除SMON_SCN_TIME的数据
因为SMON_SCN_TIME不是bootstrap自举核心对象,所以我们可以手动更新该表上的数据、及重建其索引。
如我在中介绍了因为SMON_SCN_TIME与其索引的数据不一致时,可以通过重建索引来解决问题:
connect / as sysdba drop index smon_scn_time_scn_idx; drop index smon_scn_time_tim_idx; create unique index smon_scn_time_scn_idx on smon_scn_time(scn); create unique index smon_scn_time_tim_idx on smon_scn_time(time_mp); analyze table smon_scn_time validate structure cascade;
可以在设置了12500事件后手动删除SMON_SCN_TIME上的记录,重启实例后SMON会继续正常更新SMON_SCN_TIME。除非是因为SMON_SCN_TIME表上的记录与索引smon_scn_time_tim_idx或smon_scn_time_scn_idx上的不一致造成DELETE语句无法有效删除该表上的记录:文档说明了该问题,否则我们没有必要手动去清除SMON_SCN_TIME上的数据。
具体方法如下:
SQL> conn / as sysdba /* Set the event at system level */ SQL> alter system set events '12500 trace name context forever, level 10'; /* Delete the records from SMON_SCN_TIME */ SQL> delete from smon_scn_time; SQL> commit; SQL> alter system set events '12500 trace name context off'; 完成以上步骤后重启实例restart instance shutdown immediate; startup;
深入剖析 - Oracle SCN机制详细解读
原创 2017-11-23 周玉其
SCN可以说是Oracle中一个很基础的部分,但同时它也是一个很重要的。它是系统中维持数据的一致性和顺序恢复的重要标志,是数据库非常重要的一种数据结构。
SCN介绍
请点击此处输入图片描述
SCN即系统改变号(System Change Number),是在某个时间点定义数据库已提交版本的时间戳标记。 Oracle为每个已提交的事务分配一个唯一的SCN。 SCN的值是对数据库进行更改的逻辑时间点。 Oracle使用此编号记录对数据库所做的更改。在数据库中,SCN也可以说是无处不在,数据文件头,控制文件,数据块头,日志文件等等都标记着SCN。也正是这样,数据库的一致性维护和SCN密切相关。不管是数据的备份,恢复都是离不开SCN的。
SCN是一个6字节(48bit)的数字,其值为281,474,976,710,656(2^48),分为2个部分:
SCN_BASE是一个4字节(32bit)的数字
SCN_WRAP是一个2字节(16bit)的数字
每当SCN_BASE达到其最大值(2^32 = 4294967296)时,SCN_WRAP增加1,SCN_BASE将被重置为0,一直持续到SCN_WRAP达到其最大值,即2^16 = 65536。
SCN =(SCN_WRAP * 4294967296)+ SCN_BASE
SCN随着每个事务的完成而增加。提交不会写入数据文件,也不更新控制文件。当发生checkpoint时,控制文件更新,SCN被写入到控制文件。
当前的SCN可以通过以下查询获得:
select dbms_flashback.get_system_change_number scn from dual;
select current_scn from v$database;
四种重要的SCN
请点击此处输入图片描述
在理解这几种SCN之前,我们先看下oracle事务中的数据变化是如何写入数据文件的:
第一步:事务开始;
第二步:在buffer cache中找到需要的数据块,如果没找到,从数据文件中载入buffer cache中;
第三步:事务修改buffer cache的数据块,该数据被标识为“脏数据”,并被写入log buffer中;
第四步:事务提交,LGWR进程将log buffer中的“脏数据”的日志条目写入redo log file中;
第五步:当发生checkpoint,CKPT进程更新所有数据文件的文件头中的信息,DBWn进程则负责将Buffer Cache中的脏数据写入到数据文件中。
经过上述5个步骤,事务中的数据变化最终被写入到数据文件中。但是,一旦在上述中间环节数据库意外宕机了,在重新启动时如何知道哪些数据已经写入数据文件、哪些没有写呢?(同样,在DG、streams中也存在类似疑问:redolog中哪些是上一次同步已经复制过的数据、哪些没有)
SCN机制就能比较完善的解决上述问题。 SCN是一个数字,确切的说是一个只会增加、不会减少的数字。正是它这种只会增加的特性确保了 Oracle知道哪些应该被恢复、哪些应该被复制。
总共有4种SCN:
系统检查点(System Checkpoint)SCN
数据文件检查点(Datafile Checkpoint)SCN
结束SCN(Stop SCN)
开始SCN(Start SCN)
(1)System Checkpoint SCN
当checkpoint完成后,ORACLE将System Checkpoint SCN号存放在控制文件中。我们可以通过下面SQL语句查询:
select checkpoint_change# from v$database;
(2)Datafile Checkpoint SCN
当checkpoint完成后,Oracle将Datafile Checkpoint SCN存放在控制文件中。我们可以通过下面SQL语句查询所有数据文件的Datafile Checkpoinnt SCN。
select name,checkpoint_change# from v$datafile;
(3)Start SCN
Oracle将StartSCN存放在数据文件头中。这个SCN用于检查数据库启动过程是否需要做media recovery。我们可以通过以下SQL语句查询:
select name,checkpoint_change# from v$datafile_header;
(4)Stop SCN
ORACLE将StopSCN存放在控制文件中。这个SCN号用于检查数据库启动过程是否需要做instance recovery。我们可以通过以下SQL语句查询:
select name,last_change# from v$datafile;
在数据库正常运行的情况下,对可读写的online数据文件,该SCN号为NULL。
SCN与数据库启动:
在数据库启动过程中,当System Checkpoint SCN、Datafile Checkpoint SCN和Start SCN都相同时,数据库可以正常启动,不需要做media recovery。三者当中有一个不同时,则需要做media recovery.如果在启动的过程中,End SCN为NULL,则需要做instance recovery。Oracle在启动过程中首先检查是否需要media recovery,然后再检查是否需要instance recovery。
SCN与数据库关闭:
如果数据库的正常关闭的话,将会触发一个checkpoint,同时将数据文件的END SCN设置为相应数据文件的Start SCN。当数据库启动时,发现它们是一致的,则不需要做instance recovery。在数据库正常启动后,ORACLE会将END SCN设置为NULL.如果数据库异常关闭的话,则END SCN将为NULL。
Q&A
Q
为什么ORACLE在控制文件中记录System checkpoint SCN 号的同时,还需要为每个数据文件记录DatafileCheckpoint SCN?
A
如果有表空间read only,那么该表空间的所有datafile的start SCN和stop SCN将被冻结,这个时候就跟System Checkpoint SCN不一致,但在库open的时候是不需要做media recovery的,如果没有DatafileCheckpoint SCN就无法判断这些datafile是否是最新的。
可能遇到的SCN问题
请点击此处输入图片描述
首选我们看几个跟SCN有关的概念:
Reasonable SCNLimit(RSL)
RSL = (当前时间 - 1988年1月1日)*24*3600*SCN每秒最大可能增长速率
也就是从1988年1月1日开始,假如SCN按最大速率增长,当天理论上的最大值。
最大增长速率:在11.2.0.2之前是16384,在11.2.0.2及之后版本是32768
在11.2.0.2版本之后由_max_reasonable_scn_rate参数控制
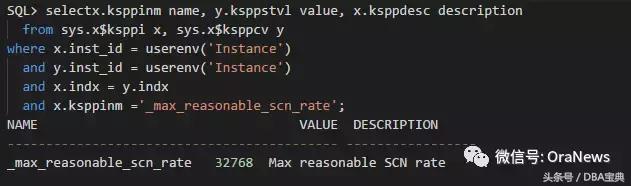
请点击此处输入图片描述
该参数不建议修改。
SCN Headroom
Headroom(天) = (Reasonable SCN Limit -CurrentSCN)/ SCN每秒最大可能增长速率/3600/24
也就是如果SCN按最大速率增长,达到当前理论最大值需要的天数。这个值可以用来判断SCN增长速率是否过快。
那么,SCN Headroom如果获取呢?
参考MOS: Bug 13498243 -"scnhealthcheck.sql" script (文档 ID 13498243.8),打上该BUG的patch之后,将在$ORACLE_HOME/rdbms/admin中增加scnhealthcheck.sql文件,该文件就是用来检查SCN是否正常。
另外还有一篇MOS文档,专门对该脚本的输出做了解释。即Installing, Executing and Interpreting output from the"scnhealthcheck.sql" script (文档 ID 1393363.1)。
执行该脚本,结果如下:
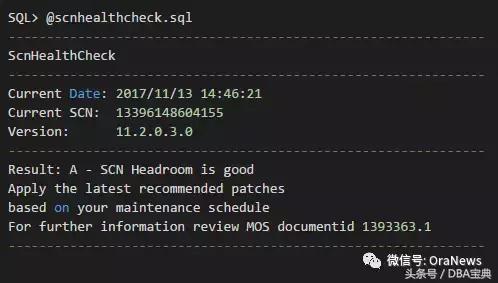
请点击此处输入图片描述
这个结果我们仍然无法得到该数据库的具体SCN Headroom,下面这个SQL是从scnhealthcheck.sql中找到的,可以直接查到SCN Headroom的值(indicator字段)。
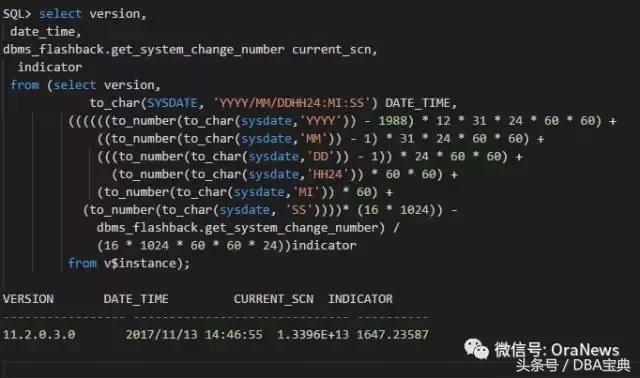
请点击此处输入图片描述
Q&A
Q
针对上面的查询结果,是不是意味着过1647天之后,SCN就将达到最大值?
A
不会,因为1647天之后,Current SCN会变大,Reasonable SCN Limit同样也会变大,正常情况下,SCNHeadroon只会变大不会变小。
SCN headroom过小的问题
如果SCN正常增长,达到最大值大约可以用500年,SCN headroom的值也会随着时间的推移慢慢变大,但是可能由于BUG、用特殊手段人为调整、dblink传播导致SCN增长出现异常。但如果出现SCN headroom过小,alert log会出现警告:Warning: The SCN headroom for this database is only NN days!
原因定位:
1. 通过下面这篇文档里提供的脚本,该脚本类似于创建AWR,可以按snap_id对dba_hist_sysstat里的某个stat_name做统计,我们这里的Stat_name选择calls to kcmgas。
How to Extract the Historical Values of aStatistic from the AWR Repository (文档 ID 948272.1)
2. 通过查询V$ARCHIVED_LOG单位时间内scn变化
3. 通过上面两个方式得出的结果分析,如果是非持续突发增长,认为很可能是通过dblink引起;
4. 同时比较awr报告中“callsto kcmgas” 和“user commits”,如果user commits也是高速增长,很可能是自身引起;
kcmgas是Oracle分配scn的函数,在一个空库上做测试,可以看出每分配一次scn,calls to kcmgas的统计增加1,所以calls to kcmgas的量可以作为scn的增长量来分析。
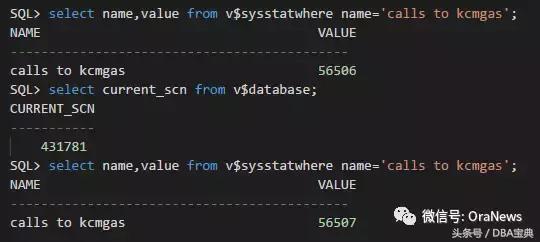
请点击此处输入图片描述
ORA-19706: Invalid SCN错误
[1376995.1]里的介绍,在2012年1月CPU或PSU里增加_external_scn_rejection_threshold_hours参数,11.2.0.2及以后的版本,默认为1天即24小时,其他版本默认为31天即744小时,相当于把拒绝外部SCN连接的阈值调大了,因而更加容易引发ORA-19706错误。该参数对数据库自身产生的SCN递增没有影响。Bug 13554409 - Fix for bug13554409 [ID 13554409.8]的里对该问题也有介绍。
ORA-19706错误:最常见的就是拒绝dblink连接的时候,如A库跟B库通过dblink连接,A的SCN有通过人为调整增大许多,连接B库的时候,Oracle会判断该SCN传播过来之后,如果会导致SCN headroom小于_external_scn_rejection_threshold_hours设置的阈值,则拒绝连接
相关参考:SCN、ORA-19706错误和_external_scn_rejection_threshold_hours参数
如果打完2012年1月CPU或PSU后遇到ORA-19706错误,对于以下这些版本的数据库:
Oracle 10.2.0.5
Oracle 11.1.0.7
Oracle 11.2.0.2
Oracle 11.2.0.3
oracle建议给数据库安装2012年4月发布的PSU,并在安装该PSU的基础上,安装补丁13916709。如果是集群架构,同时给集群软件最新安装PSU。参数_external_scn_rejection_threshold_hours在2012年4月(包含2012年4月)以后发布的PSU/CPU中,11.2.0.2及以后的版本,是1天即24小时,其他版本是31天即744小时。其他版本:先升级到高版本,再按照上面的方法处理。
总结
如果发现SCN有异常,需要及时通过上述方法来打上最新的PSU,同时尽量少用DBLINK,从系统设计角度来讲也是不推荐这种系统间强耦合的设计。
SCN、ORA-19706错误和_external_scn_rejection_threshold_hours参数
2016-10-28 熊军
Oracle数据库在安装了2012年1月发布的CPU或PSU补丁之后,经常出现下面一些现象:
1、应用出现ORA-19706: invalid SCN错误。
2、在alert日志中出现类似如下警告:

请点击此处输入图片描述
3、在alert日志中出现类似如下错误:

请点击此处输入图片描述
4、在alert日志中出现类似如下信息:

请点击此处输入图片描述
5、在MOS文档《ORA-19706 and Related Alert Log Messages [ID 1393360.1]》中还提到其他会出现在alert中的一些警告信息:

请点击此处输入图片描述
如果说以上的现象只是警告或应用级报错,影响范围有限,那么不幸的是如果遇到RECO进程在恢复分布式事务时遇到SCN问题,则可能使数据库宕掉,例如:
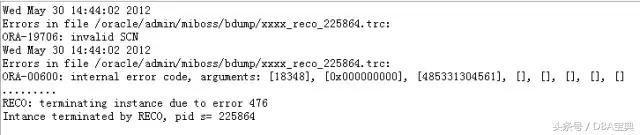
请点击此处输入图片描述
那么2012年1月发布的CPU或PSU补丁到底使数据库在SCN处理方面产生了什么样的变化?这种变化对数据库有什么危害吗?甚至于说,以上提示的信息是由于这个补丁的BUG引起的吗?
要回答这些问题,得先从SCN讲起。SCN可以说是Oracle中的很基础,但同时也是很重要的东西,它是一个单向增长的“时钟”,广泛应用于数据库的恢复、事务ACID、一致性读还有分布式事务中。那么除了这些,SCN还有以下一些知识点:
-
SCN的内部存储方式:在Oracle内部,SCN分为两部分存储,分别称之为scn wrap和scn base。实际上SCN长度为48位,即它其实就是一个48位的整数。只不过可能是由于在早些年通常只能处理32位甚至是16位的数据,所以人为地分成了低32位(scn base)和高16位(scn wrap)。为什么不设计成64位,这个或许是觉得48位已经足够长了并且为了节省两个字节的空间:)。那么SCN这个48位长的整数,最大就是2^48(2的48次方, 281万亿,281474976710656),很大的一个数字了。
-
Maximum Reasonable SCN:在当前时间点,SCN最大允许达到(或者说最大可能)的SCN值。也称为Reasonable SCN Limit,简称RSL。这个值是一个限制,避免数据库的SCN无限制地增大,甚至达到了SCN的最大值。这个值大约是这样一个公式计算出来的:(当前时间-1988年1月1日)*24*3600*SCN每秒最大可能增长速率。当前时间减1988年1月1日的结果是天数,24表示1天24小时,3600表示1小时3600秒。不过这个公式里面“当前时间-1988年1月”部分并不是两个时间直接相减,而是按每月31天进行计算的(或许是为了计算简单,因此在Oracle内部可能要频繁地计算,这个计算方法可以在安装了13498243这个补丁后得到的scnhealthcheck.sql文件中看到,《Installing, Executing and Interpreting output from the "scnhealthcheck.sql" script [ID 1393363.1]》这篇MOS文档解释了这个脚本的使用及对结果的解释,实际上直接看脚本代码更为清楚)。那么SCN最秒最大可能增长速率是多少呢,这个跟Oracle版本有一定的关系,在11.2.0.2之前是16384(即16K),在11.2.0.2及之后版本是32768(即32K)。在11.2.0.2的版本中有一个隐含参数,_max_reasonable_scn_rate,其默认值就是32768(不建议调整这个值)。如果按16K的最大值,SCN要增长到最大,要超过500年。
-
SCN Headroom:这个是指Maximum Reasonable SCN与当前数据库SCN的差值。在alert中通常是以“天”为单位,这个只是为了容易让人读而已。天数=(Maximum Reasonable SCN-Current SCN)/16384/3600/24。这个值就的意思就是,如果按SCN的每大增长速率,多少天会到达Maximum Reasonable SCN。但实际上即使如此,也不会到达Maximum Reasonable SCN,因为到那时Maximum Reasonable SCN也增大了(越时间增大),要到达Maximum Reasonable SCN,得必须以SCN最大可能速率的2倍才行。
-
SCN的异常增长:通常来说,每秒最大允许的16K/32K增长速率已经足够了,但是不排除由于BUG,或者人为调整导致SCN异常增长过大。特别是后者,比如数据库通过特殊手段强制打开,手工把SCN递增得很大。同时Oracle的SCN会通过db link进行传播。如果A库通过db link连接到B库,如果A库的SCN高于B库的SCN,那么B库就会递增SCN到跟A库一样,反之如果A库的SCN低于B库的SCN,那么A库的SCN会递增到跟B库的SCN一样。也就是说,涉及到db link进行操作的多个库,它们会将SCN同步到这些库中的最大的SCN。
-
那么,如果是数据库本身操作而不是通过db link同步使得SCN的增长,其增长速率如何判断呢,这个可以通过系统的统计量“calls to kcmgas”和"DEBUG calls to kcmgas"来得到。kcmgas的意思是get and advance SCN,即获取并递增SCN。
-
在两个库通过dblink进行分布式事务时,假设B库的SCN值要高于A库的SCN,因此要将B库的SCN增同步到A库,但是如果B库的SCN过高,这样同步到A库之后,使得A库面临Headroom过小的风险,那么A库会拒绝同步SCN,这个时候就会报ORA-19706: Invalid SCN错误。分布式事务,或者说是通过db link的操作就会失败,即使是通过db link的查询操作。这里显然有一个阈值,如果递增SCN使得Headroom过小到什么值时,就会拒绝递增(同步)SCN?目前来看是这样:如果打了2012年1月CPU或PSU补丁,11.2.0.2及以后的版本,是1天即24小时,其他版本是31天即744小时,打了补丁之后可以由隐含参数_external_scn_rejection_threshold_hours来调整。而没有打补丁的情况下,视同此参数设为0,实际最小为1小时。由于Oracle 9.2.0.8没有了最新的补丁集,显示也不会有这个参数,保持默认为1小时。注意这是一个静态参数。所以打了2012年1月CPU或PSU补丁的一个重要变化是增加了_external_scn_rejection_threshold_hours参数,同时使11.2.0.2以下版本的数据库其Headroom的阈值增得较大。这带来的影响就是ORA-19706的错误出现的概率更高。解决的办法将_external_scn_rejection_threshold_hours这个隐含参数设置为较小的值,推荐的值是24,即1天。从_external_scn_rejection_threshold_hours这个参数名的字面意思结合它的作用,可以说这个参数就是”拒绝外部SCN“的阈值。对于数据库自身产生的SCN递增是没有影响的。
-
虽然11.2.0.2及之后的版本,其默认的每秒最大可能SCN增长速率为32K,这使得Maximum Reasonable SCN更大,也就是说其SCN可以增长到更大的值。那也就是可能会使11.2.0.2的库与低版本的数据库之间不能进行dblink连接。或者是11.2.0.2的库不能与16K速率的(比如调整了_max_reasonable_scn_rate参数值)的11.2.0.2的库进行dblink连接。
现在是时候来回答以下几个问题了:
-
2012年1月后发布的CPU或PSU补丁到底使数据库在SCN处理方面产生了什么样的变化?
增加了_external_scn_rejection_threshold_hours参数,11.2.0.2及以上版本的这个参数默认值是24,其他版本默认值是744。这样使11.2.0.2以下版本的数据库其Headroom的阈值增得较大。
-
这种变化对数据库有什么危害吗?
在一个具有很多系统的大型企业环境里面,db link使用很多,甚至有一些不容易管控到的数据库也在跟关键系统通过 db link进行连接,在这样的环境中,过高的SCN扩散到关键系统,而系统如果打了这个补丁,其Headroom阈值变大,那么就更容易出现ORA-19706错误,对db link依赖很严重的系统可能会导致业务系统问题,严重情况下甚至会宕库。不过通过设置隐含参数_external_scn_rejection_threshold_hours可解决这样的问题。所以,如果你安装了2012年1月的CPU或PSU补丁,请尽快设置此参数为建议的值24,极端情况下你可以设置为1。。
-
alert中的那些提示或警告信息是BUG引起的吗?
这些提示或警告不是BUG引起的。它只是提醒你注意SCN过高增长,或者是你的Headroom较小(在Headroom小于62天时可能会提醒),引起你的重视。实际上根据MOS文档《System Change Number (SCN), Headroom, Security and Patch Information[ID 1376995.1]》的说法,这个补丁修复了SCN相关的一些BUG。如果非要说BUG,可以勉强认为补丁安装后新增的参数_external_scn_rejection_threshold_hours其默认值过大。Bug13554409 - Fix for bug 13554409 [ID 13554409.8]就是说的这个问题。不过这个问题已经在2012年4月的CPU或PSU补丁中得到修复。
在最后我们来解读一下alert日志中的一些信息:
-
信息

请点击此处输入图片描述
这里是说,SCN向前(跳跃)递增了68098分钟,其递增后的SCN是0x0ba9.4111a520。注意这里的分钟的计算就是根据SCN每秒最大可能增长速率为16K来的。我们计算一下:
0x0ba94111a520转换成10进制12821569053984。
在alert日志中,这个信息是刚打开数据库的时候,所以 crash recovery完成时的scn可以做为近似的当前SCN,其值为12754630269552:
(12821569053984-12754630269552)/16384/60=68093.65278320313
这里16384值的是SCN每秒最大可能增长速率,可以看到计算结果极为接近。
我们再来计算一下这个SCN的headroom是多少:
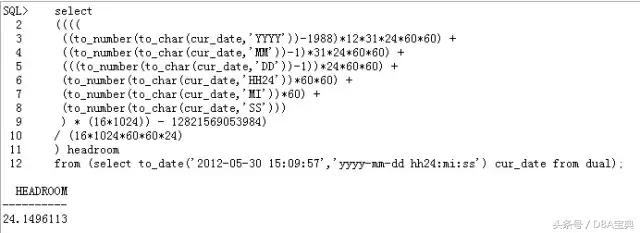
请点击此处输入图片描述
可以看到结果为24天,由于这个时候_external_scn_rejection_threshold_hours参数值为24,即1天,所以虽然有这么大的跳跃,但SCN仍然增长成功。
-
信息

请点击此处输入图片描述
在这个信息中,拒绝了db link引起的SCN增加。计算一下这个SCN的headroom:
0x0ba93caec689转换成10进制是12821495465609
当前时间是2012-05-30 12:02:00,
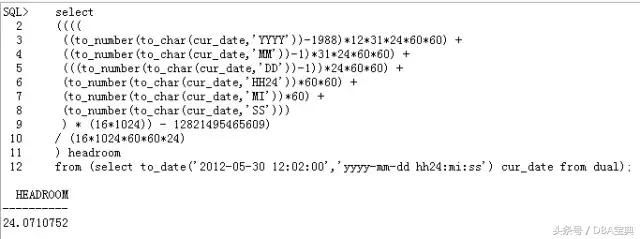
请点击此处输入图片描述
由于这个时候_external_scn_rejection_threshold_hours参数值为744,即31天,计算出的headroom在这个阈值之内,因此拒绝增加SCN。
(31-24.0710752)*24=166.2941952,正好是166小时。
-update on 2012/6/2--
实际上2012年1月的CPU或PSU补丁之后还会有下面的变化:
1、_minimum_giga_scn这个隐含没有了,可惜了这个手工增加SCN的利器。
2、11.2.0.2及之后的版本,从原来的32K SCN最大速率调整回了16K速率。可以用下面的SQL来得到结果:
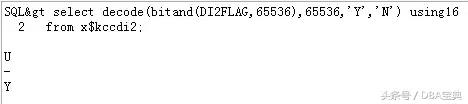
请点击此处输入图片描述
上面的SQL的结果只有在11.2.0.2及以上版本才有意义,结果为Y,表示使用的是16K的速率,否则是使用32K速率。
本文涉及的一些参数,和SCN的一些算法,可能会随着版本或补丁的变化而产生较大的变化。
important update: 实际上在Jan 2012的PSU/CPU补丁中存在较大的SCN BUG,目前已经不建议打这个补丁集,而是打到更高的PSU补丁集上。
About Me
.............................................................................................................................................
● 本文内容整理自网络,若有侵权请联系小麦苗删除
● 本文在itpub(http://blog.itpub.net/26736162/abstract/1/)、博客园(http://www.cnblogs.com/lhrbest)和个人微信公众号(xiaomaimiaolhr)上有同步更新
● 本文itpub地址:http://blog.itpub.net/26736162/abstract/1/
● 本文博客园地址:http://www.cnblogs.com/lhrbest
● 本文pdf版、个人简介及小麦苗云盘地址:http://blog.itpub.net/26736162/viewspace-1624453/
● 数据库笔试面试题库及解答:http://blog.itpub.net/26736162/viewspace-2134706/
● DBA宝典今日头条号地址:http://www.toutiao.com/c/user/6401772890/#mid=1564638659405826
.............................................................................................................................................
● QQ群号:230161599(满)、618766405
● 微信群:可加我微信,我拉大家进群,非诚勿扰
● 联系我请加QQ好友(646634621),注明添加缘由
● 于 2017-11-01 09:00 ~ 2017-11-30 22:00 在魔都完成
● 文章内容来源于小麦苗的学习笔记,部分整理自网络,若有侵权或不当之处还请谅解
● 版权所有,欢迎分享本文,转载请保留出处
.............................................................................................................................................
● 小麦苗的微店:https://weidian.com/s/793741433?wfr=c&ifr=shopdetail
● 小麦苗出版的数据库类丛书:http://blog.itpub.net/26736162/viewspace-2142121/
.............................................................................................................................................
使用微信客户端扫描下面的二维码来关注小麦苗的微信公众号(xiaomaimiaolhr)及QQ群(DBA宝典),学习最实用的数据库技术。

小麦苗的微信公众号 小麦苗的DBA宝典QQ群2 《DBA笔试面宝典》读者群 小麦苗的微店
.............................................................................................................................................





背景
在v$transaction会看到scn,其中又分为scn base及scn wrap,这到底怎么回事呢?而且很多ORA报错与SCN有关,如果多了解一些SCN相关的知识,也便于我们分析解决问题。
结论
1,oradebug poke可以推进SCN,分为在数据库OPEN及MOUNT皆可以oradebug setmypid
oradebug DUMPvar SGA kcsgscn_
oradebug poke 0x060012658 4 1000
2,关于kcsgscn_变量我是在BAIDU上面查的,而关于SCN到底是对应内存是哪块区域,我是采用多次运行oradebug DUMPvar SGA kcsgscn_,看哪些内存的值在变化,基本就是哪块
3,oradebug poke 0x060012658 4 1000 就是推进SCN的命令,具体含义如下:
oradebug poke 内存地址 长度 要修改的内容 ,注意这个要修改的内容必须是十进制,如果是16进制会报上述的错(这里我采用了反向对比思维),且这里长度是前4个字节
4,如果是在OPEN状态下推进SCN,oradebug DUMPvar SGA kcsgscn_是有值的,而在MOUNT因为数据库没有打开,所在是空的,全是0,那么如何调整SCN,可以基于每个文件头的BLOCK 1的数据结构kscnbas及kscnwrp进行调整
这个数据结构对应select file#,name,checkpoint_change# from v$datafile;
BBED> map
File: /home/ora10g/asia/asia/users01.dbf (0)
Block: 1 Dba:0x00000000
------------------------------------------------------------
Data File Header
struct kcvfh, 676 bytes @0
ub4 tailchk @8188
BBED> p kcvfh
struct kcvfhckp, 36 bytes @484
struct kcvcpscn, 8 bytes @484
ub4 kscnbas @484 0x028f5c58 --scn base
ub2 kscnwrp @488 0x0000 --scn wrap
5,select current_scn from v$database,这个SCN是一直在变化,可以叫作内存SCN
6,scn是由scn base及scn wrap构成的,当scn base达到一定程度,scn wrap则会递增,一般情况下scn wrap是0,不会变化
7,scn base及scn wrap也是数据块中的数据结构,可见scn base是4个字节,而scn wrap是2个字节
也就是说scn base要用4个字节用完,scn wrap就会递增
依理推理,4个字节为 power(2,32),也就是达到这个数据时,scn base就会归0,scn wrap递增1
8,基于 select file#,name,checkpoint_change# from v$datafile;和数据结构的scn base及scn wrap可知scn计算公式为
scn=scn wrap * power(2,32)+scn base
9,进一步引申,也可以计算出为scn最大值,因为scn base及scn wrap是由4个字节及4个字节构成的,而这些字节表示的数据范围是有限的
10,如果过小调整scn远小于checkpoint_change#,会引发ora-600 2662,当然解决也很容易,基于checkpoint_change#调大scn即可
否则2662会引发数据库强制关闭
测试
SQL> select * from v$version where rownum=1;
BANNER
----------------------------------------------------------------
Oracle Database 10g Enterprise Edition Release 10.2.0.5.0 - 64bi
---可见事务也有scn base及scn wrap的概念
SQL> desc v$transaction;
Name Null? Type
----------------- -------- ------------
ADDR RAW(8)
XIDUSN NUMBER
XIDSLOT NUMBER
XIDSQN NUMBER
UBAFIL NUMBER
UBABLK NUMBER
UBASQN NUMBER
UBAREC NUMBER
STATUS VARCHAR2(16)
START_TIME VARCHAR2(20)
START_SCNB NUMBER --scn base
START_SCNW NUMBER --scn wrap
START_UEXT NUMBER
START_UBAFIL NUMBER
START_UBABLK NUMBER
START_UBASQN NUMBER
START_UBAREC NUMBER
SES_ADDR RAW(8)
FLAG NUMBER
SPACE VARCHAR2(3)
RECURSIVE VARCHAR2(3)
NOUNDO VARCHAR2(3)
PTX VARCHAR2(3)
NAME VARCHAR2(256
)
PRV_XIDUSN NUMBER
PRV_XIDSLT NUMBER
PRV_XIDSQN NUMBER
PTX_XIDUSN NUMBER
PTX_XIDSLT NUMBER
PTX_XIDSQN NUMBER
DSCN-B NUMBER --scn base
DSCN-W NUMBER --scn wrap
USED_UBLK NUMBER
USED_UREC NUMBER
LOG_IO NUMBER
PHY_IO NUMBER
CR_GET NUMBER
CR_CHANGE NUMBER
START_DATE DATE
DSCN_BASE NUMBER --scn base
DSCN_WRAP NUMBER --scn wrap
START_SCN NUMBER
DEPENDENT_SCN NUMBER
XID RAW(8)
PRV_XID RAW(8)
PTX_XID RAW(8)
---普通数据块也有scn base及scn wrap的概念,且scn base为4个字节,scn wrap为2个字节
BBED> map
File: /home/ora10g/asia/asia/users01.dbf (0)
Block: 12 Dba:0x00000000
------------------------------------------------------------
KTB Data Block (Table/Cluster)
struct kcbh, 20 bytes @0
struct ktbbh, 72 bytes @20
struct kdbh, 14 bytes @100
struct kdbt[1], 4 bytes @114
sb2 kdbr[32] @118
ub1 freespace[7814] @182
ub1 rowdata[192] @7996
ub4 tailchk @8188
BBED> p kcbh
struct kcbh, 20 bytes @0
ub1 type_kcbh @0 0x06
ub1 frmt_kcbh @1 0xa2
ub1 spare1_kcbh @2 0x00
ub1 spare2_kcbh @3 0x00
ub4 rdba_kcbh @4 0x0100000c
ub4 bas_kcbh @8 0x00048e91 --scn base
ub2 wrp_kcbh @12 0x0000 --scn wrap
ub1 seq_kcbh @14 0x02
ub1 flg_kcbh @15 0x06 (KCBHFDLC, KCBHFCKV)
ub2 chkval_kcbh @16 0x7e45
ub2 spare3_kcbh @18 0x0000
BBED>
---数据文件头也有scn base及scn wrap的概念
BBED> map
File: /home/ora10g/asia/asia/users01.dbf (0)
Block: 1 Dba:0x00000000
------------------------------------------------------------
Data File Header
struct kcvfh, 676 bytes @0
ub4 tailchk @8188
BBED> p kcvfh
struct kcvfh, 676 bytes @0
struct kcvfhbfh, 20 bytes @0
ub1 type_kcbh @0 0x0b
ub1 frmt_kcbh @1 0xa2
ub1 spare1_kcbh @2 0x00
ub1 spare2_kcbh @3 0x00
ub4 rdba_kcbh @4 0x01000001
ub4 bas_kcbh @8 0x00000000
ub2 wrp_kcbh @12 0x0000
从上述我们发现基本scn wrap全是0,那么何时scn会变成非0呢,我想到了推进SCN,然后对比DUMP数据块,可以了其原理了
SQL> select current_scn,checkpoint_change# from v$database;
CURRENT_SCN CHECKPOINT_CHANGE#
----------- ------------------
311981 296387
SQL> alter session set events 'immediate trace name adjust_scn level 1';
Session altered.
SQL> select current_scn,checkpoint_change# from v$database;
CURRENT_SCN CHECKPOINT_CHANGE#
----------- ------------------
311996 296387
可见上述推进SCN太慢了
SQL> select 311996-311981 from dual;
311996-311981
-------------
15
---且ALERT会报权限不足的错误信息
Mon Nov 30 23:46:36 EST 2015
Errors in file /home/ora10g/admin/asia/udump/asia_ora_23849.trc:
ORA-01031: insufficient privileges
---上述推进SCN方法太慢,我们尝试另一种快速推进SCN的方法,不过要重启库到MOUNT状态
SQL> shutdown immediate
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> startup mount
ORACLE instance started.
Total System Global Area 901775360 bytes
Fixed Size 2100424 bytes
Variable Size 226493240 bytes
Database Buffers 666894336 bytes
Redo Buffers 6287360 bytes
Database mounted.
---可见MOUNT状态下CURRENT_SCN为0,其它SCN列皆有值
SQL> select current_scn,checkpoint_change# from v$database;
CURRENT_SCN CHECKPOINT_CHANGE#
----------- ------------------
0 312204
SQL> select file#,name,checkpoint_change# from v$datafile;
FILE# NAME CHECKPOINT_CHANGE#
---------- -------------------------------------------------- ------------------
1 /home/ora10g/asia/asia/system01.dbf 312204
2 /home/ora10g/asia/asia/undotbs01.dbf 312204
3 /home/ora10g/asia/asia/sysaux01.dbf 312204
4 /home/ora10g/asia/asia/users01.dbf 312204
SQL> select file#,checkpoint_change# from v$datafile_header;
FILE# CHECKPOINT_CHANGE#
---------- ------------------
1 312204
2 312204
3 312204
4 312204
SQL> select to_char('312204','xxxxxxx') from dual;
TO_CHAR(
--------
4c38c
---bbed查看数据文件的SCN,可知是4c38c
struct kcvfhckp, 36 bytes @484
struct kcvcpscn, 8 bytes @484
ub4 kscnbas @484 0x0004c38c
ub2 kscnwrp @488 0x0000
---用10015事件推进SCN发现没有变化,可见在MOUNT状态下不生效推进SCN
SQL> alter session set events '10015 trace name adjust_scn level 1';
Session altered.
SQL> select current_scn,checkpoint_change# from v$database;
CURRENT_SCN CHECKPOINT_CHANGE#
----------- ------------------
0 312204
打开数据库看看有无生效,也是没有效果
SQL> alter database open;
Database altered.
SQL> select current_scn,checkpoint_change# from v$database;
CURRENT_SCN CHECKPOINT_CHANGE#
----------- ------------------
312409 312207
SQL> select file#,name,checkpoint_change# from v$datafile;
FILE# NAME CHECKPOINT_CHANGE#
---------- -------------------------------------------------- ------------------
1 /home/ora10g/asia/asia/system01.dbf 312207
2 /home/ora10g/asia/asia/undotbs01.dbf 312207
3 /home/ora10g/asia/asia/sysaux01.dbf 312207
4 /home/ora10g/asia/asia/users01.dbf 312207
---换另一种方法,用ORADEBUG POKE推进SCN
SQL> shutdown immediate
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> startup mount
ORACLE instance started.
Total System Global Area 901775360 bytes
Fixed Size 2100424 bytes
Variable Size 226493240 bytes
Database Buffers 666894336 bytes
Redo Buffers 6287360 bytes
Database mounted.
SQL> oradebug setmypid
Statement processed.
SQL> oradebug DUMPvar SGA kcsgscn_
kcslf kcsgscn_ [060012658, 060012688) = 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 60012338 00000000
SQL>
SQL> select file#,name,checkpoint_change# from v$datafile;
FILE# NAME CHECKPOINT_CHANGE#
---------- -------------------------------------------------- ------------------
1 /home/ora10g/asia/asia/system01.dbf 312714
2 /home/ora10g/asia/asia/undotbs01.dbf 312714
3 /home/ora10g/asia/asia/sysaux01.dbf 312714
4 /home/ora10g/asia/asia/users01.dbf 312714
SQL> select to_char('312714','xxxxxx') from dual;
TO_CHAR
-------
4c58a
SQL> oradebug poke 0x060012658 8 0x0004c58a
BEFORE: [060012658, 060012660) = 00000000 00000000
AFTER: [060012658, 060012660) = 0004C58A 00000000
SQL> oradebug DUMPvar SGA kcsgscn
kcslf kcsgscn_ [060012658, 060012688) = 0004C58A 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 60012338 00000000
SQL>
SQL> alter database open;
Database altered.
SQL> select file#,name,checkpoint_change# from v$datafile;
FILE# NAME CHECKPOINT_CHANGE#
---------- -------------------------------------------------- ------------------
1 /home/ora10g/asia/asia/system01.dbf 312717
2 /home/ora10g/asia/asia/undotbs01.dbf 312717
3 /home/ora10g/asia/asia/sysaux01.dbf 312717
4 /home/ora10g/asia/asia/users01.dbf 312717
好像没起作用
SQL> select current_scn,checkpoint_change# from v$database;
CURRENT_SCN CHECKPOINT_CHANGE#
----------- ------------------
312891 312717
---换个思路,试试在数据库打开时推进SCN
SQL> select file#,name,checkpoint_change# from v$datafile;
FILE# NAME CHECKPOINT_CHANGE#
---------- -------------------------------------------------- ------------------
1 /home/ora10g/asia/asia/system01.dbf 313429
2 /home/ora10g/asia/asia/undotbs01.dbf 313429
3 /home/ora10g/asia/asia/sysaux01.dbf 313429
4 /home/ora10g/asia/asia/users01.dbf 313429
SQL> select current_scn,checkpoint_change# from v$database;
CURRENT_SCN CHECKPOINT_CHANGE#
----------- ------------------
313917 313429
SQL> select to_char('313917','xxxxxxxxxx') from dual;
TO_CHAR('31
-----------
4ca3d
---经间隔多次运行如下ORADEBUG命令,我分析CURRENT_SCN就是内存中的第1部分(因为就这部分信息在变化,其它信息是固定的)
SQL> oradebug setmypid
Statement processed.
SQL> oradebug DUMPvar SGA kcsgscn_
kcslf kcsgscn_ [060012658, 060012688) = 0004CAD4 00000000 00000000 00000000 00000113 00000000 00000000 00000000 00000000 00000000 60012338 00000000
SQL>
SQL>
SQL>
SQL> oradebug DUMPvar SGA kcsgscn_
kcslf kcsgscn_ [060012658, 060012688) = 0004CAD6 00000000 00000000 00000000 00000114 00000000 00000000 00000000 00000000 00000000 60012338 00000000
SQL>
SQL>
SQL> oradebug DUMPvar SGA kcsgscn_
kcslf kcsgscn_ [060012658, 060012688) = 0004CAD7 00000000 00000000 00000000 00000115 00000000 00000000 00000000 00000000 00000000 60012338 00000000
SQL>
---所以我们只要改第1部分信息的内容即可
SQL> oradebug poke 0x060012658 4 FFFFA3523
ORA-01858: a non-numeric character was found where a numeric was expected
SQL>
可见oradeug poke 的含义是oradebug poke 内存地址 长度 要修改的内容 ,注意这个要修改的内容必须是十进制,如果是16进制会报上述的错(这里我采用了反向对比思维),且这里长度是前4个字节
SQL> oradebug poke 0x060012658 4 1000
BEFORE: [060012658, 06001265C) = 0004CB41
AFTER: [060012658, 06001265C) = 000003E8
SQL> select to_number('3E8','xxxxxxxxx') from dual;
TO_NUMBER('3E8','XXXXXXXXX')
----------------------------
1000
---而且上述由于把SCN改得过小,小于数据文件及控制文件的SCN,会报ORA-600 的2662错误,处理很简单,快速基于checkpoint_change#把SCN变大即可,否则过会数据库就会DOWN机
SQL> select current_scn,checkpoint_change# from v$database;
select current_scn,checkpoint_change# from v$database
*
ERROR at line 1:
ORA-00600: internal error code, arguments: [2662], [0], [71], [0], [333548],
[0], [], []
---基于上述分析,因为原来SCN是313917,我们加到19999999999
SQL> oradebug setmypid
Statement processed.
SQL> select power(2,32) from dual;
POWER(2,32)
-----------
4294967296
如果把SCN调整为上述的值,马上ALAERT会报错
SQL> oradebug DUMPvar SGA kcsgscn_
kcslf kcsgscn_ [060012658, 060012688) = 000565AE 00000000 00000000 00000000 00000075 00000000 00000000 00000000 00000000 00000000 60012338 00000000
SQL> oradebug poke 0x060012658 4 4294967296
BEFORE: [060012658, 06001265C) = 000565B3
AFTER: [060012658, 06001265C) = 00000000
Tue Dec 01 01:27:33 EST 2015
Errors in file /home/ora10g/admin/asia/bdump/asia_cjq0_27711.trc:
ORA-00604: error occurred at recursive SQL level 1
ORA-08176: consistent read failure; rollback data not available
--所以可见SCN也不能随意去调太大,ORACLE内部肯定有个控制算法的,否则会把库搞DOWN掉
SQL> oradebug poke 0x060012658 4 42949670
BEFORE: [060012658, 06001265C) = 00000003
AFTER: [060012658, 06001265C) = 028F5C26
SQL> alter system checkpoint;
System altered.
SQL> alter system checkpoint;
System altered.
SQL> select file#,name,checkpoint_change# from v$datafile;
FILE# NAME CHECKPOINT_CHANGE#
---------- -------------------------------------------------- ------------------
1 /home/ora10g/asia/asia/system01.dbf 42949720
2 /home/ora10g/asia/asia/undotbs01.dbf 42949720
3 /home/ora10g/asia/asia/sysaux01.dbf 42949720
4 /home/ora10g/asia/asia/users01.dbf 42949720
---可见SCN已经调整为指定的SCN了
SQL> select current_scn,checkpoint_change# from v$database;
CURRENT_SCN CHECKPOINT_CHANGE#
----------- ------------------
42949724 42949720
---换个思路继糿研究SCN BASE及SCN WRAP,如果我一直增加SCN BASE,SCN WRAP会有变化呢,我理解肯定是SCN BASE大到一定程度,SCN WRAP就会有变化
BBED> map
File: /home/ora10g/asia/asia/users01.dbf (0)
Block: 1 Dba:0x00000000
------------------------------------------------------------
Data File Header
struct kcvfh, 676 bytes @0
ub4 tailchk @8188
BBED> p kcvfh
struct kcvfhckp, 36 bytes @484
struct kcvcpscn, 8 bytes @484
ub4 kscnbas @484 0x028f5c58 --scn base
ub2 kscnwrp @488 0x0000
SQL> select to_number('&x','xxxxxxxx') from dual;
Enter value for x: 28f5c58
old 1: select to_number('&x','xxxxxxxx') from dual
new 1: select to_number('28f5c58','xxxxxxxx') from dual
TO_NUMBER('28F5C58','XXXXXXXX')
-------------------------------
42949720
BBED> set offset 484
OFFSET 484
BBED> dump count 5
File: /home/ora10g/asia/asia/users01.dbf (0)
Block: 1 Offsets: 484 to 488 Dba:0x00000000
------------------------------------------------------------------------
585c8f02 00
<32 bytes="" per="" line="">
SQL> select power(2,31) from dual;
POWER(2,31)
-----------
2147483648
SQL> select to_char('2147483648','xxxxxxxxx') from dual;
TO_CHAR('2
----------
80000000
BBED> modify /x 00000080
Warning: contents of previous BIFILE will be lost. Proceed? (Y/N) Y
File: /home/ora10g/asia/asia/users01.dbf (0)
Block: 1 Offsets: 484 to 488 Dba:0x00000000
------------------------------------------------------------------------
00000080 00
<32 bytes="" per="" line="">
--还要调整tailchk
可以看到tailchk校验由ub4 bas_kcbh的低4位+ub1 type_kcbh+ub1 seq_kcbh
BBED> p tailchk
ub4 tailchk @8188 0x00000b01
ub4 bas_kcbh @8 0x00000000
ub1 type_kcbh @0 0x0b
ub1 seq_kcbh @14 0x01
BBED> sum apply
Check value for File 0, Block 1:
current = 0x2dac, required = 0x2dac
---调整后
struct kcvfhckp, 36 bytes @484
struct kcvcpscn, 8 bytes @484
ub4 kscnbas @484 0x80000000
ub2 kscnwrp @488 0x0000
BBED> p tailchk
ub4 tailchk @8188 0x00000b01
SQL> conn scott/system
Connected.
SQL> create table t_modafter(a int);
Table created.
SQL> insert into t_modafter values(1);
1 row created.
SQL> commit;
Commit complete.
SQL> conn /as sysdba
Connected.
SQL> alter system checkpoint;
System altered.
SQL> alter system flush buffer_cache;
System altered.
---调整scn base到最大值-1
SQL> select power(2,32)-1 from dual;
POWER(2,32)-1
-------------
4294967295
SQL> select to_char('4294967295','xxxxxxxxxx') from dual;
TO_CHAR('42
-----------
ffffffff
---报错可以分2步进行,即先2个字节进行,然后再把余下的2个字节修改完
BBED> modify /x ffffffff
BBED-00209: invalid number (ffffffff)
BBED> modify /x ffff
Warning: contents of previous BIFILE will be lost. Proceed? (Y/N) Y
File: /home/ora10g/asia/asia/users01.dbf (0)
Block: 1 Offsets: 484 to 488 Dba:0x00000000
------------------------------------------------------------------------
ffff0080 00
<32 bytes="" per="" line="">
BBED> set offset 486
OFFSET 486
BBED> dump
File: /home/ora10g/asia/asia/users01.dbf (0)
Block: 1 Offsets: 486 to 488 Dba:0x00000000
------------------------------------------------------------------------
008000
<32 bytes="" per="" line="">
BBED> modify /x ffff
File: /home/ora10g/asia/asia/users01.dbf (0)
Block: 1 Offsets: 486 to 488 Dba:0x00000000
------------------------------------------------------------------------
ffff00
<32 bytes="" per="" line="">
BBED> dump
File: /home/ora10g/asia/asia/users01.dbf (0)
Block: 1 Offsets: 484 to 486 Dba:0x00000000
------------------------------------------------------------------------
ffffff
<32 bytes="" per="" line="">
BBED> p kcvfh
struct kcvfhckp, 36 bytes @484
struct kcvcpscn, 8 bytes @484
ub4 kscnbas @484 0xffffffff scn_base已经调整为 power(2,32)-1 ,其中32代表4个字节,每个字节byte即8bit,所以就是32个bit,可以表示的数据即power(2,32)
ub2 kscnwrp @488 0x0000
SQL> alter system flush buffer_cache;
System altered.
SQL> alter system checkpoint;
System altered.
BBED> p kcvfh
struct kcvfhckp, 36 bytes @484
struct kcvcpscn, 8 bytes @484
ub4 kscnbas @484 0x00000002
ub2 kscnwrp @488 0x0001 ---看到没,SCN WRAP有值了,哈哈说明,SCN BASE大到一定程度,它就有值了
SQL> select file#,name,checkpoint_change# from v$datafile;
FILE# NAME CHECKPOINT_CHANGE#
---------- -------------------------------------------------- ------------------
1 /home/ora10g/asia/asia/system01.dbf 4294967298
2 /home/ora10g/asia/asia/undotbs01.dbf 4294967298
3 /home/ora10g/asia/asia/sysaux01.dbf 4294967298
4 /home/ora10g/asia/asia/users01.dbf 4294967298
可见scn=scn wrap * power(2,32)+scn base
SQL> select 1*4294967296+2 from dual;
1*4294967296+2
--------------
4294967298
也就是说scn wrap有值时,scn又开始从0开始计数,由此可见ORACLE设计的精妙所在,再深入一些,也可以知道SCN最大值是什么,哈哈
了解你所不知道的SMON功能(十):维护SMON_SCN_TIME字典基表
SMON后台进程的作用还包括维护SMON_SCN_TIME基表。
SMON_SCN_TIME基表用于记录过去时间段中SCN(system change number)与具体的时间戳(timestamp)之间的映射关系,因为是采样记录这种映射关系,所以SMON_SCN_TIME可以较为较为粗糙地(不精确地)定位某个SCN的时间信息。实际的SMON_SCN_TIME是一张cluster table簇表。

SMON_SCN_TIME时间映射表最大的用途是为闪回类型的查询(flashback type queries)提供一种将时间映射为SCN的途径(The SMON time mapping is mainly for flashback type queries to map a time to an SCN)。
Metalink文档介绍了SMON更新SMON_SCN_TIME的规律:
- 在版本10g中SMON_SCN_TIME每6秒钟被更新一次(In Oracle Database 10g, smon_scn_time is updated every 6 seconds hence that is the minimum time that the flashback query time needs to be behind the timestamp of the first change to the table.)
- 在版本9.2中SMON_SCN_TIME每5分钟被更新一次(In Oracle Database 9.2, smon_scn_time is updated every 5 minutes hence the required delay between the flashback time and table properties change is at least 5 minutes.)
另外从10g开始SMON也会清理SMON_SCN_TIME中的记录了,SMON后台进程会每5分钟被唤醒一次,检查SMON_SCN_TIME在磁盘上的映射记录总数,若总数超过144000条,则会使用以下语句删除最老的一条记录(time_mp最小):
delete from smon_scn_time where thread = 0 and time_mp = (select min(time_mp) from smon_scn_time where thread = 0)
若仅仅删除一条记录不足以获得足够的空间,那么SMON会反复多次执行以上DELETE语句。
触发场景
虽然Metalink文档指出了在10g中SMON会以每6秒一次的频率更新SMON_SCN_TIME基表,但是实际观测可以发现更新频率与SCN的增长速率相关,在较为繁忙的实例中SCN的上升极快时SMON可能会以6秒一次的最短间隔频率更新 , 但是在空闲的实例中SCN增长较慢,则仍会以每5或10分钟一次频率更新,例如:
[oracle@vrh8 ~]$ ps -ef|grep smon|grep -v grep oracle 3484 1 0 Nov12 ? 00:00:02 ora_smon_G10R21 SQL> select * from v$version; BANNER ---------------------------------------------------------------- Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - 64bi PL/SQL Release 10.2.0.1.0 - Production CORE 10.2.0.1.0 Production TNS for Linux: Version 10.2.0.1.0 - Production NLSRTL Version 10.2.0.1.0 - Production SQL> select * from global_name; GLOBAL_NAME -------------------------------------------------------------------------------- www.askmaclean.com & www.askmaclean.com SQL> oradebug setospid 3484; Oracle pid: 8, Unix process pid: 3484, image: oracle@vrh8.oracle.com (SMON) SQL> oradebug event 10500 trace name context forever,level 10 : 10046 trace name context forever,level 12; Statement processed. SQL> SQL> oradebug tracefile_name; /s01/admin/G10R21/bdump/g10r21_smon_3484.trc /* 等待一定时间 */
找出SMON trace文件中insert数据到SMON_SCN_TIME的记录:
grep -A20 "insert into smon_scn_time" /s01/admin/G10R21/bdump/g10r21_smon_3484.trc insert into smon_scn_time (thread, time_mp, time_dp, scn, scn_wrp, scn_bas, num_mappings, tim_scn_map) values (0, :1, :2, :3, :4, :5, :6, :7) END OF STMT PARSE #4:c=0,e=43,p=0,cr=0,cu=0,mis=0,r=0,dep=1,og=4,tim=1290280848899596 BINDS #4: kkscoacd Bind#0 oacdty=02 mxl=22(22) mxlc=00 mal=00 scl=00 pre=00 oacflg=00 fl2=0001 frm=00 csi=00 siz=24 off=0 kxsbbbfp=7fb29844edb8 bln=22 avl=06 flg=05 value=767145793 Bind#1 oacdty=12 mxl=07(07) mxlc=00 mal=00 scl=00 pre=00 oacflg=10 fl2=0001 frm=00 csi=00 siz=8 off=0 kxsbbbfp=7fff023ae780 bln=07 avl=07 flg=09 value="11/14/2011 0:3:13" Bind#2 oacdty=02 mxl=22(04) mxlc=00 mal=00 scl=00 pre=00 oacflg=10 fl2=0001 frm=00 csi=00 siz=24 off=0 kxsbbbfp=7fff023ae70c bln=22 avl=04 flg=09 value=954389 Bind#3 -- insert into smon_scn_time (thread, time_mp, time_dp, scn, scn_wrp, scn_bas, num_mappings, tim_scn_map) values (0, :1, :2, :3, :4, :5, :6, :7) END OF STMT PARSE #1:c=0,e=21,p=0,cr=0,cu=0,mis=0,r=0,dep=1,og=4,tim=1290281434933390 BINDS #1: kkscoacd Bind#0 oacdty=02 mxl=22(22) mxlc=00 mal=00 scl=00 pre=00 oacflg=00 fl2=0001 frm=00 csi=00 siz=24 off=0 kxsbbbfp=7fb29844edb8 bln=22 avl=06 flg=05 value=767146393 Bind#1 oacdty=12 mxl=07(07) mxlc=00 mal=00 scl=00 pre=00 oacflg=10 fl2=0001 frm=00 csi=00 siz=8 off=0 kxsbbbfp=7fff023ae780 bln=07 avl=07 flg=09 value="11/14/2011 0:13:13" Bind#2 oacdty=02 mxl=22(04) mxlc=00 mal=00 scl=00 pre=00 oacflg=10 fl2=0001 frm=00 csi=00 siz=24 off=0 kxsbbbfp=7fff023ae70c bln=22 avl=04 flg=09 value=954720 Bind#3 -- insert into smon_scn_time (thread, time_mp, time_dp, scn, scn_wrp, scn_bas, num_mappings, tim_scn_map) values (0, :1, :2, :3, :4, :5, :6, :7) END OF STMT PARSE #3:c=0,e=20,p=0,cr=0,cu=0,mis=0,r=0,dep=1,og=4,tim=1290281727955249 BINDS #3: kkscoacd Bind#0 oacdty=02 mxl=22(22) mxlc=00 mal=00 scl=00 pre=00 oacflg=00 fl2=0001 frm=00 csi=00 siz=24 off=0 kxsbbbfp=7fb29844e960 bln=22 avl=06 flg=05 value=767146993 Bind#1 oacdty=12 mxl=07(07) mxlc=00 mal=00 scl=00 pre=00 oacflg=10 fl2=0001 frm=00 csi=00 siz=8 off=0 kxsbbbfp=7fff023ae780 bln=07 avl=07 flg=09 value="11/14/2011 0:23:13" Bind#2 oacdty=02 mxl=22(04) mxlc=00 mal=00 scl=00 pre=00 oacflg=10 fl2=0001 frm=00 csi=00 siz=24 off=0 kxsbbbfp=7fff023ae70c bln=22 avl=04 flg=09 value=954926 Bind#3 insert into smon_scn_time (thread, time_mp, time_dp, scn, scn_wrp, scn_bas, num_mappings, tim_scn_map) values (0, :1, :2, :3, :4, :5, :6, :7) END OF STMT PARSE #4:c=0,e=30,p=0,cr=0,cu=0,mis=0,r=0,dep=1,og=4,tim=1290282313990553 BINDS #4: kkscoacd Bind#0 oacdty=02 mxl=22(22) mxlc=00 mal=00 scl=00 pre=00 oacflg=00 fl2=0001 frm=00 csi=00 siz=24 off=0 kxsbbbfp=7fb29844edb8 bln=22 avl=06 flg=05 value=767147294 Bind#1 oacdty=12 mxl=07(07) mxlc=00 mal=00 scl=00 pre=00 oacflg=10 fl2=0001 frm=00 csi=00 siz=8 off=0 kxsbbbfp=7fff023ae780 bln=07 avl=07 flg=09 value="11/14/2011 0:28:14" Bind#2 oacdty=02 mxl=22(04) mxlc=00 mal=00 scl=00 pre=00 oacflg=10 fl2=0001 frm=00 csi=00 siz=24 off=0 kxsbbbfp=7fff023ae70c bln=22 avl=04 flg=09 value=955036 Bind#3
可以通过以上INSERT语句的TIME_DP绑定变量值中发现其更新SMON_SCN_TIME的时间规律,一般为5或10分钟一次。这说明SMON_SCN_TIME的更细频率与数据库实例的负载有关,其最短的间隔是每6秒一次,最长的间隔为10分钟一次。
由于SMON_SCN_TIME的更新频率问题可能引起ORA-01466错误,详见:
Error ORA-01466 while executing a flashback query. [ID 281510.1]
由于SMON_SCN_TIME的数据不一致可能引起ORA-00600[6711]或频繁地执行”delete from smon_scn_time”删除语句,详见:
ORA-00600[6711]错误一例
High Executions Of Statement “delete from smon_scn_time…” [ID 375401.1]
SMON维护SMON_SCN_TIME时相关的Stack CALL,ktf_scn_time是更新SMON_SCN_TIME的主要函数:
ksedst ksedmp ssexhd kghlkremf kghalo kghgex kghalf kksLoadChild kxsGetRuntimeLock kksfbc
kkspsc0 kksParseCursor opiosq0 opiall0 opikpr opiodr rpidrus skgmstack rpidru rpiswu2 kprball ktf_scn_time ktmmon ktmSmonMain ksbrdp opirip opidrv sou2o opimai_real main main_opd_entry
SMON 还可能使用以下SQL语句维护SMON_SCN_TIME字典基表:
select smontabv.cnt,
smontab.time_mp,
smontab.scn,
smontab.num_mappings,
smontab.tim_scn_map,
smontab.orig_thread
from smon_scn_time smontab,
(select max(scn) scnmax,
count(*) + sum(NVL2(TIM_SCN_MAP, NUM_MAPPINGS, 0)) cnt
from smon_scn_time
where thread = 0) smontabv
where smontab.scn = smontabv.scnmax
and thread = 0
insert into smon_scn_time
(thread,
time_mp,
time_dp,
scn,
scn_wrp,
scn_bas,
num_mappings,
tim_scn_map)
values
(0, :1, :2, :3, :4, :5, :6, :7)
update smon_scn_time
set orig_thread = 0,
time_mp = :1,
time_dp = :2,
scn = :3,
scn_wrp = :4,
scn_bas = :5,
num_mappings = :6,
tim_scn_map = :7
where thread = 0
and scn = (select min(scn) from smon_scn_time where thread = 0)
delete from smon_scn_time
where thread = 0
and scn = (select min(scn) from smon_scn_time where thread = 0)
如何禁止SMON更新SMON_SCN_TIME基表
可以通过设置诊断事件event=’12500 trace name context forever, level 10’来禁止SMON更新SMON_SCN_TIME基表(Setting the 12500 event at system level should stop SMON from updating the SMON_SCN_TIME table.):
SQL> alter system set events '12500 trace name context forever, level 10'; System altered.
一般我们不推荐禁止SMON更新SMON_SCN_TIME基表,因为这样会影响flashback Query闪回查询的正常使用,但是在某些异常恢复的场景中SMON_SCN_TIME数据讹误可能导致实例的Crash,那么可以利用以上12500事件做到不触发SMON_SCN_TIME被更新。
如何手动清除SMON_SCN_TIME的数据
因为SMON_SCN_TIME不是bootstrap自举核心对象,所以我们可以手动更新该表上的数据、及重建其索引。
如我在中介绍了因为SMON_SCN_TIME与其索引的数据不一致时,可以通过重建索引来解决问题:
connect / as sysdba drop index smon_scn_time_scn_idx; drop index smon_scn_time_tim_idx; create unique index smon_scn_time_scn_idx on smon_scn_time(scn); create unique index smon_scn_time_tim_idx on smon_scn_time(time_mp); analyze table smon_scn_time validate structure cascade;
可以在设置了12500事件后手动删除SMON_SCN_TIME上的记录,重启实例后SMON会继续正常更新SMON_SCN_TIME。除非是因为SMON_SCN_TIME表上的记录与索引smon_scn_time_tim_idx或smon_scn_time_scn_idx上的不一致造成DELETE语句无法有效删除该表上的记录:文档说明了该问题,否则我们没有必要手动去清除SMON_SCN_TIME上的数据。
具体方法如下:
SQL> conn / as sysdba /* Set the event at system level */ SQL> alter system set events '12500 trace name context forever, level 10'; /* Delete the records from SMON_SCN_TIME */ SQL> delete from smon_scn_time; SQL> commit; SQL> alter system set events '12500 trace name context off'; 完成以上步骤后重启实例restart instance shutdown immediate; startup;
正文到此结束
- 本文标签: ip Oracle UI 空间 分布式事务 操作系统 src 博客 微信公众号 IO 备份 mail grep 安装 时间 实例 参数 dist 删除 IOS 图片 update 事故 map 代码 Select REST QQ群 http kk cache rmi mina tar sql NSA DOM 软件 企业 ECS 2015 ORM 云 db 集群 Menu parse 二维码 同步 ask 文章 Action bug linux tab CDN cat Bootstrap HTML list 性能问题 DDL Enterprise PL/SQL 一致性 unix https 进程 IDE App value 总结 统计 ACE Security 分布式 启动过程 struct 数据库 数据 CTO key 锁 core Word message id 测试
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

