在Exadata X5-2(HC)测试创建31g各类文件和10Tbigfile的效率
联系: QQ(5163721)
标题: 在Exadata X5-2(HC)测试创建31g各类文件和10Tbigfile的效率
作者:Lunar©版权所有[文章允许转载,但必须以链接方式注明源地址,否则追究法律责任.]
本周要使用SwingBench对Exadata X5-2(HC)进行压测,因此,我提前准备了需要的表空间和redo等等。
1,首先看一下创建31g的数据文件的速度:
新增一个31g的数据文件,普通类型的数据文件,大概12秒左右:
sys@DBM>create tablespace Lunar_500g datafile '+DATADG' size 31g autoextend on next 8g maxsize 31g 22:53:20 2 22:53:20 3 EXTENT MANAGEMENT LOCAL AUTOALLOCATE 22:53:20 4 SEGMENT SPACE MANAGEMENT AUTO ; Tablespace created. 22:53:32 sys@DBM>
对比一下EF550全闪存(可用空间也是20T,Exadata X5-2 QuarterRack也带了20T的闪存):

增加一个31g的临时表空间文件,大概不到20秒:
00:17:04 sys@DBM>alter tablespace temp add tempfile '+DATADG' SIZE 31g; Tablespace altered. 00:17:22 sys@DBM>
新增一个31g的undo表空间文件,大概不到30秒:
00:18:34 sys@DBM>alter tablespace UNDOTBS1 add datafile '+DATADG' SIZE 31g; Tablespace altered. 00:19:02 sys@DBM>
新增一个system的31g文件,时间比较长,大概不到80秒的样子:
00:19:02 sys@DBM>alter tablespace SYSTEM add datafile '+DATADG' SIZE 31g; Tablespace altered. 00:20:19 sys@DBM>
新增一个SYSAUX表空间的文件大概20秒左右:
00:20:19 sys@DBM>aalter tablespace SYSAUX add datafile '+DATADG' SIZE 31g; Tablespace altered. 00:20:40 sys@DBM>
顺便测试了一下Exadata上创建10T bigfile的效率,具体命令如下:
create bigfile tablespace soe datafile '+DATADG' size 10T autoextend on next 8g EXTENT MANAGEMENT LOCAL uniform size 1m SEGMENT SPACE MANAGEMENT AUTO ;
这个过程执行了大概1小时,也就是在此环境下,创建10T的bigfile需要1小时时间,这个速度我感觉已经超快了:
00:43:20 sys@DBM>create bigfile tablespace soe datafile '+DATADG' size 10T autoextend on next 8g EXTENT MANAGEMENT LOCAL uniform size 1m SEGMENT SPACE MANAGEMENT AUTO ; 00:43:21 2 00:43:21 3 00:43:21 4 Tablespace created. 01:45:24 sys@DBM>
.
首先了解一下,offload和Smart Scan的关系。Offload在很多时候我们可以跟SmartScan理解为一致的东西。
它是指讲处理能力从数据库服务器下移到存储服务器的操作。
这一操作不仅转移了CPU的使用,更主要的是大大减少了返回到数据库层的IO:
1,减少存储系统和数据库服务器之间的传输数据量
2,减少数据库服务器上的CPU使用率(解压缩的操作发生在cell上)
3,减少存储层磁盘读取的时间
.
但是在某些情况下,还有一些其他非SmartScan类型的卸载(offload)操作:
1,智能文件创建(数据块在存储节点上被格式化)
2,Rman增量备份
.
在创建大表空间的时候,我们看到了等待事件“cell smart file creation”
这个正是我们期待看到的,这类IO走智能文件创建(Offload是Exadata的独门武器,而智能文件创建是非Smart Scan类型的一种IO卸载功能)。
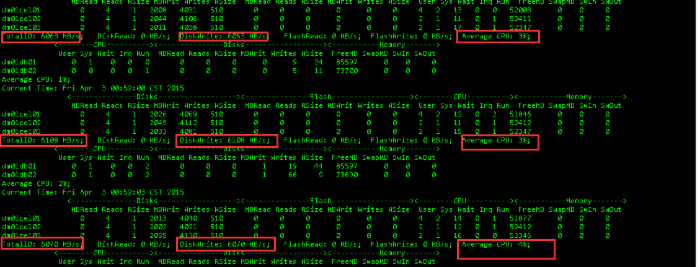
01:17:51 sys@DBM>select inst_id,event,count(1) from gv$session where wait_class#<> 6 group by inst_id,event order by 1,3; INST_ID EVENT COUNT(1) ---------- ---------------------------------------------------------------- ---------- 1 cell smart file creation 1 01:18:06 sys@DBM>/ INST_ID EVENT COUNT(1) ---------- ---------------------------------------------------------------- ---------- 1 cell smart file creation 1 01:18:21 sys@DBM>
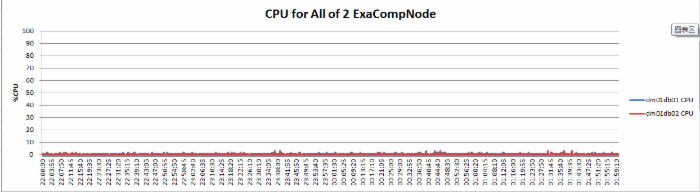
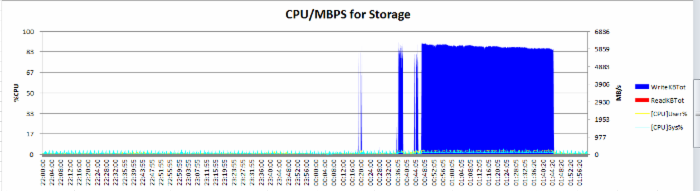
整个创建bigtable的时间测算,测试期间,db节点和cell节点的CPU占用都很低:
每秒 6G
每分钟 360G
每小时 20T(既然是每小时20T,那么我的这个10T表空间为什么使用了1小时,而不是30分钟?)
这个啊,我猜因为咱们是ASM NORMAL redundancy(Exadata上没有RAID,靠的就是ASM自身的冗余和IO rebalance)。
也就是IO要写两份,O(∩_∩)O哈哈~
具体看图:
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

