Django ORM的简单总结
我们继续昨天的内容使用Oracle中的emp,dept来学习Django ORM,今天做一些总结和扩展,希望你能有所收获。
先来说下两张表emp,dept。
emp表的数据如下:
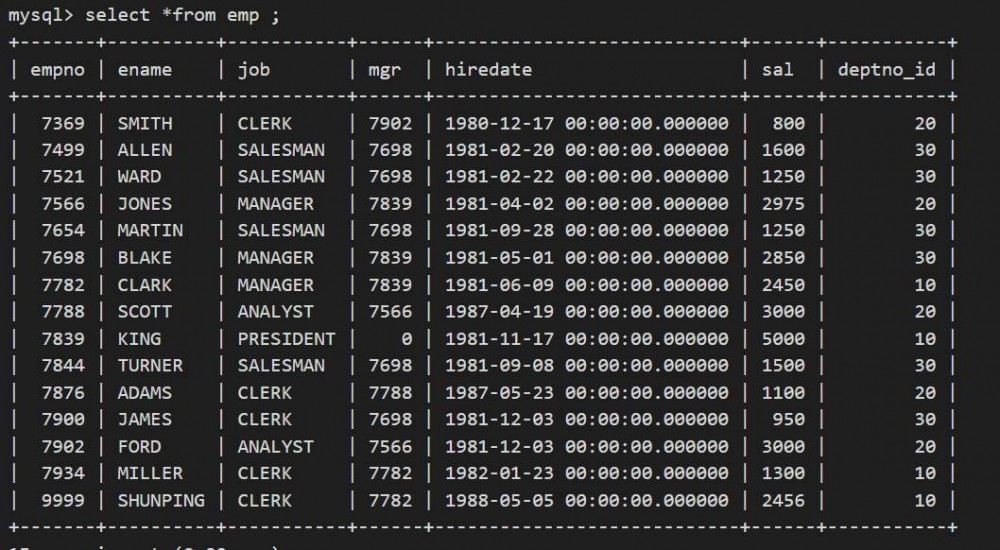
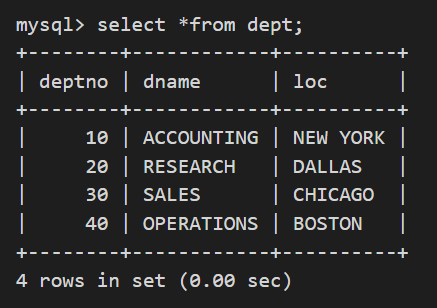
dept表的数据如下:
然后我们就开始吧,有的同学说我的数据还没有初始化,可以移步上一篇找到脚本。
对于QuerysetAPI的内容,如果看文档有非常多的解释和介绍,很难抓到重点,我就从我的认知来梳理一下。
1. QuerySet 创建对象的方法
>>> from scott.models import emp
>>> from scott.models import dept
先得到所有的数据。
>>> emp.objects.all()
[<emp: 7369 SMITH> , <emp: 7499 ALLEN> , <emp: 7521 WARD> , <emp: 7566 JONES> , <emp: 7654 MARTIN> , <emp: 7698 BLAKE> , <emp: 7782 CLARK> , <emp: 7788 SCOTT> , <emp: 7839 KING> , <emp: 7844 TURNER> , <emp: 7876 ADAMS> , <emp: 7900 JAMES> , <emp: 7902 FORD> , <emp: 7934 MILLER> , <emp: 9999 SHUNPING>]
>>> dept.objects.all()
[<dept: 10 ACCOUNTING> , <dept: 20 RESEARCH> , <dept: 30 SALES> , <dept: 40 OPERATIONS>]
第一种方法是使用create
>>> dept.objects.create( dname= 'DEV',loc= 'Beijing')
<dept: 41 DEV>
第二种是初始化另外一个对象,save完成
>>> newdept = dept( dname= 'TEST',loc= 'ShangHai')
>>> newdept.save()
第三种和第二种有些类似,可以对立面的属性根据需求改变。
>>> #method 3
>>> newdept.dname
'TEST'
>>> newdept=dept()
>>> newdept.dname
u''
>>> newdept.dname= 'OPS'
>>> newdept.loc= 'Guangzhou'
>>> newdept.save()
第四种会做一个判断,有点类似数据库立面的create or replace,注意此处的返回是一个布尔值。
>>> dept.objects.get_or_create( dname= 'DBA',loc= 'Shenzhen')
(<dept: 44 DBA> , True) 2.查询语句根据主键查询
>>> dept.objects.get( pk= 10)
<dept: 10 ACCOUNTING>
得到top n的数据
>>> dept.objects.all()[: 5]
[<dept: 10 ACCOUNTING> , <dept: 20 RESEARCH> , <dept: 30 SALES> , <dept: 40 OPERATIONS> , <dept: 41 DEV>]
使用get方法,返回的是一行
>>> dept.objects.get( dname= 'DBA')
<dept: 44 DBA>
使用filter的exact是精确匹配,和上面的方法是等价的。
>>> dept.objects.filter( dname__exact= 'DBA')
[<dept: 44 DBA>]
忽略大小写
>>> dept.objects.filter( dname__iexact= 'DBA')
[<dept: 44 DBA>]
查询内容排除包含ACC的部门
>>> dept.objects.exclude( dname__contains= 'ACC')
[<dept: 20 RESEARCH> , <dept: 30 SALES> , <dept: 40 OPERATIONS> , <dept: 41 DEV> , <dept: 42 TEST> , <dept: 43 OPS> , <dept: 44 DBA>]
>>>
可以过滤和排除操作都使用
>>> dept.objects.filter( dname__contains= 'DB').exclude( dname= 'MBA')
[<dept: 44 DBA>] 3.删除这种方法是查到指定的数据,然后直接删除,还是有一些风险点的。
>>> dept.objects.filter( dname__contains= 'DB').delete()
或者分批删除
>>> dept.objects.all()
[<dept: 10 ACCOUNTING> , <dept: 20 RESEARCH> , <dept: 30 SALES> , <dept: 40 OPERATIONS> , <dept: 41 DEV> , <dept: 42 TEST> , <dept: 43 OPS>]
>>> newdept=dept.objects.filter( dname__contains= 'DEV')
>>> newdept.delete()
全部删除 ,先不操作
dept.objects.all().delete() 4.更新使用filter来过滤得到数据,然后使用update来更新
>>> dept.objects.filter( dname__contains= 'TEST')
[<dept: 42 TEST>]
>>> dept.objects.filter( dname__contains= 'TEST').update( dname= 'Test')
1L
>>>
>>> dept.objects.filter( dname__contains= 'Te')
[<dept: 42 Test>]
或者把初始化一个对象,更新这个对象
>>> newdept=dept.objects.get( dname= 'Test')
>>>
>>> newdept.dname
u'Test'
>>> dname= 'Test2'
>>> loc= 'Lanzhou'
>>> newdept.save()
5.迭代Queryset>>> newdept=dept.objects.all()
>>> for new in newdept:
... print(new.dname)
...
ACCOUNTING
RESEARCH
SALES
OPERATIONS
Test
OPS 6.链式查询两个filter来过滤
>>> dept.objects.filter( dname__contains= 'Test').filter( deptno= 42)
[<dept: 42 Test>]
先使用fileter过滤,然后使用exclude排除
>>> dept.objects.filter( dname__contains= 'Test').exclude( deptno= 4)
[<dept: 42 Test>] 7.top n的写法得到前4行
>>> dept.objects.all()[: 4]
[<dept: 10 ACCOUNTING> , <dept: 20 RESEARCH> , <dept: 30 SALES> , <dept: 40 OPERATIONS>]
>>>
最后2行,有个技巧是用reverse()
>>> dept.objects.all().reverse()[: 2]
[<dept: 43 OPS> , <dept: 42 Test>]
最后1行,下标是从0开始
>>> dept.objects.all().reverse()[ 0]
<dept: 43 OPS>
>>> dept.objects.all().reverse()[ 1]
<dept: 42 Test>
或者使用order_by反向排序
>>> dept.objects.all().order_by( '-deptno')[: 2]
[<dept: 43 OPS> , <dept: 42 Test>]
有的同学可能疑惑order_by和reverse的性能差别。我们继续往下看。
8.得到调用的SQL语句方法1:
>>> print str(dept.objects.all().order_by( '-deptno').distinct().query)
SELECT DISTINCT `dept`.`deptno` , `dept`.`dname` , `dept`.`loc` FROM `dept` ORDER BY `dept`.`deptno` DESC
>>>
>>> print str(dept.objects.all().reverse().distinct().query)
SELECT DISTINCT `dept`.`deptno` , `dept`.`dname` , `dept`.`loc` FROM `dept` ORDER BY `dept`.`deptno` DESC
可见两者是等价的,所以我们就很容易理解reverse()和order_by的差别了,实现不同,但是结果相同。 方法2:使用query.__str__()来得到
>>> dept.objects.all().reverse().distinct().query. __str__()
u'SELECT DISTINCT `dept`.`deptno`, `dept`.`dname`, `dept`.`loc` FROM `dept` ORDER BY `dept`.`deptno` DESC'
方法3:在settings.py里面补充下面的内容,然后在python shell模式下,可以看到调用的SQL
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console': {
'class': 'logging.StreamHandler',
} ,
} ,
'loggers': {
'django.db.backends': {
'handlers': [ 'console'] ,
'level': 'DEBUG' if DEBUG else 'INFO',
} ,
} ,
} 8.得到返回结果 values_list
可以使用values_list来实现,比如返回dname和deptno列
>>> dept.objects.values_list( 'dname','deptno')
[( u'ACCOUNTING', 10L) , ( u'RESEARCH', 20L) , ( u'SALES', 30L) , ( u'OPERATIONS', 40L) , ( u'Test', 42L) , ( u'OPS', 43L)]
>>>
初始化一个对象,打印出结果
>>> newdept=dept.objects.values_list( 'dname','deptno')
>>> newdept
[( u'ACCOUNTING', 10L) , ( u'RESEARCH', 20L) , ( u'SALES', 30L) , ( u'OPERATIONS', 40L) , ( u'Test', 42L) , ( u'OPS', 43L)]
可以使用list方法
>>> list(newdept)
[( u'ACCOUNTING', 10L) , ( u'RESEARCH', 20L) , ( u'SALES', 30L) , ( u'OPERATIONS', 40L) , ( u'Test', 42L) , ( u'OPS', 43L)]
>>>
使用values_list的结果,格式和上面还是有一些差别的。
>>> dept.objects.values_list( 'dname',flat= True)
[ u'ACCOUNTING', u'RESEARCH', u'SALES', u'OPERATIONS', u'Test', u'OPS']
可以加入flat选项,只输出指定的列
>>> print str(dept.objects.values_list( 'dname',flat= True).query)
SELECT `dept`.`dname` FROM `dept` ORDER BY `dept`.`deptno` ASC
9.得到返回结果 values
>>> dept.objects.values( 'dname')
[{ 'dname': u'ACCOUNTING'} , { 'dname': u'RESEARCH'} , { 'dname': u'SALES'} , { 'dname': u'OPERATIONS'} , { 'dname': u'Test'} , { 'dname': u'OPS'}]
>>>
>>> dept.objects.values_list( 'dname')
[( u'ACCOUNTING',) , ( u'RESEARCH',) , ( u'SALES',) , ( u'OPERATIONS',) , ( u'Test',) , ( u'OPS',)]
>>>
两者返回的并不是真正的列表或字典,也是queryset 10.列的别名
可以使用extra来指定别名
>>> dept.objects.all().extra( select={ 'dname': 'Dname'})
[<dept: 10 ACCOUNTING> , <dept: 20 RESEARCH> , <dept: 30 SALES> , <dept: 40 OPERATIONS> , <dept: 42 Test> , <dept: 43 OPS>]
>>>
如果不确定里面的参数代表的含义,可以得到解析的SQL来对比一下,就很清楚了。
>>> print str(dept.objects.all().extra( select={ 'dname': 'Dname'}).query)
SELECT (Dname) AS `dname` , `dept`.`deptno` , `dept`.dname , `dept`.`loc` FROM `dept` ORDER BY `dept`.`deptno` ASC
>>>
>>> print str(dept.objects.all().extra( select={ 'Dname': "dname"}).query)
SELECT (dname) AS `Dname` , `dept`.`deptno` , `dept`.`dname` , `dept`.`loc` FROM `dept` ORDER BY `dept`.`deptno` ASC
>>>
>>> print str(dept.objects.all().extra( select={ 'dname': 'Dname'}).defer( 'dname').query)
SELECT (Dname) AS `dname` , `dept`.`deptno` , `dept`.`loc` FROM `dept` ORDER BY `dept`.`deptno` ASC
11.聚合运算
我们常见的是这种:
##计算个数
>>> print str(dept.objects.all().extra( select={ 'dname': 'Dname'}).defer( 'dname').count())
6
如果是做聚合运算,就需要用到Count,Avg,Sum了。
##做聚合结算,需要导入Count,使用annotate
>>> from django.db.models import Count
>>> dept.objects.all().values( 'dname').annotate( count=Count( 'dname')).values( 'dname','count')
[{ 'dname': u'ACCOUNTING', 'count': 1} , { 'dname': u'RESEARCH', 'count': 1} , { 'dname': u'SALES', 'count': 1} , { 'dname': u'OPERATIONS', 'count': 1} , { 'dname': u'Test', 'count': 1} , { 'dname': u'OPS', 'count': 1}]
不过值得一提的是,里面的group by的部分是个硬骨头,因为group by会默认带有主键列,对于一些特殊的场景,就会有些乏力了,比如这种SQL,在目前的实现中是不能直接支持的。
select deptno_id ,count(*) from emp group by deptno_id;
都会间接转换为如下的方式,就有些尴尬了。
select deptno_id ,count(*) from emp group by empno;
如果手工强转,就会抛错了。
>>> a=emp.objects.raw( 'select deptno_id,count(*) count from emp group by deptno_id')
>>> a[ 0]
( 0.000) select deptno_id ,count(*) count from emp group by deptno_id; args=()
Traceback (most recent call last):
File "<console>", line 1, in <module>
File "/usr/local/lib/python2.7/site-packages/django/db/models/query.py", line 1323, in __getitem__
return list(self)[k]
File "/usr/local/lib/python2.7/site-packages/django/db/models/query.py", line 1296, in __iter__
raise InvalidQuery( 'Raw query must include the primary key')
InvalidQuery: Raw query must include the primary key
12.Inner Join和聚合运算
inner join,注意下面的deptno__dname的部分。
>>> emp.objects.values( 'deptno__dname').annotate( sum=Sum( 'deptno')).values( 'deptno','sum').query. __str__()
u'SELECT `emp`.`deptno_id`, SUM(`emp`.`deptno_id`) AS `sum` FROM `emp` INNER JOIN `dept` ON ( `emp`.`deptno_id` = `dept`.`deptno` ) GROUP BY `emp`.`empno` ORDER BY `emp`.`empno` ASC, `emp`.`ename` ASC'
12.select_related查询
这种方式的一大好处就是会自动关联查询,调用一次会自动获取相关的数据。
我们可以对比下它和通常方式的差别。
使用传统的方式,如果需要关联查询,会在后台反复调用关联查询。
>>> emp.objects.all()[: 10]
( 0.001) SELECT `emp`.`empno` , `emp`.`ename` , `emp`.`job` , `emp`.`mgr` , `emp`.`hiredate` , `emp`.`sal` , `emp`.`deptno_id` FROM `emp` ORDER BY `emp`.`empno` ASC , `emp`.`ename` ASC LIMIT 10; args=()
[<emp: 7369 SMITH> , <emp: 7499 ALLEN> , <emp: 7521 WARD> , <emp: 7566 JONES> , <emp: 7654 MARTIN> , <emp: 7698 BLAKE> , <emp: 7782 CLARK> , <emp: 7788 SCOTT> , <emp: 7839 KING> , <emp: 7844 TURNER>]
初始化对象,得到关联数据的情况
>>> a=emp.objects.all()[: 10][ 0]
( 0.000) SELECT `emp`.`empno` , `emp`.`ename` , `emp`.`job` , `emp`.`mgr` , `emp`.`hiredate` , `emp`.`sal` , `emp`.`deptno_id` FROM `emp` ORDER BY `emp`.`empno` ASC , `emp`.`ename` ASC LIMIT 1; args=()
>>> a.ename
u'SMITH'
>>> a.deptno --可以看到又做了一次查询
( 0.002) SELECT `dept`.`deptno` , `dept`.`dname` , `dept`.`loc` FROM `dept` WHERE `dept`.`deptno` = 20; args=( 20,)
<dept: 20 RESEARCH>
而使用select_related就可以解决这个问题。
只查一次数据库 select_related
>>> a=emp.objects.all().select_related( 'deptno')[: 4][ 0]
( 0.001) SELECT `emp`.`empno` , `emp`.`ename` , `emp`.`job` , `emp`.`mgr` , `emp`.`hiredate` , `emp`.`sal` , `emp`.`deptno_id` , `dept`.`deptno` , `dept`.`dname` , `dept`.`loc` FROM `emp` INNER JOIN `dept` ON ( `emp`.`deptno_id` = `dept`.`deptno` ) ORDER BY `emp`.`empno` ASC , `emp`.`ename` ASC LIMIT 1; args=()
>>> a.ename
u'SMITH'
反复查看,都不会多次调用新的SQL
>>> a.deptno
<dept: 20 RESEARCH>
>>> a.ename
u'SMITH'
>>> a.mgr
7902L
>>>
>>> a.deptno.dname --级联查询
u'RESEARCH'13.prefetched_related查询对比prefetched related的好处
>>> a=emp.objects.all().filter( empno__in=( 7369,7521,7566))
>>> a
( 0.001) SELECT `emp`.`empno` , `emp`.`ename` , `emp`.`job` , `emp`.`mgr` , `emp`.`hiredate` , `emp`.`sal` , `emp`.`deptno_id` FROM `emp` WHERE `emp`.`empno` IN ( 7369, 7521, 7566) ORDER BY `emp`.`empno` ASC , `emp`.`ename` ASC LIMIT 21; args=( 7369, 7521, 7566)
[<emp: 7369 SMITH> , <emp: 7521 WARD> , <emp: 7566 JONES>]
迭代
>>> for t in a:
... print t.ename ,t.deptno
...
SMITH 20 RESEARCH
( 0.000) SELECT `dept`.`deptno` , `dept`.`dname` , `dept`.`loc` FROM `dept` WHERE `dept`.`deptno` = 30; args=( 30,)
WARD 30 SALES
( 0.000) SELECT `dept`.`deptno` , `dept`.`dname` , `dept`.`loc` FROM `dept` WHERE `dept`.`deptno` = 20; args=( 20,)
JONES 20 RESEARCH
初始化对象,使用in的方式来过滤数据
>>> a=emp.objects.all().filter( empno__in=( 7369,7521,7566)).prefetch_related( 'deptno')
>>> a
( 0.001) SELECT `emp`.`empno` , `emp`.`ename` , `emp`.`job` , `emp`.`mgr` , `emp`.`hiredate` , `emp`.`sal` , `emp`.`deptno_id` FROM `emp` WHERE `emp`.`empno` IN ( 7369, 7521, 7566) ORDER BY `emp`.`empno` ASC , `emp`.`ename` ASC LIMIT 21; args=( 7369, 7521, 7566)
( 0.000) SELECT `dept`.`deptno` , `dept`.`dname` , `dept`.`loc` FROM `dept` WHERE `dept`.`deptno` IN ( 20, 30) ORDER BY `dept`.`deptno` ASC; args=( 20, 30)
[<emp: 7369 SMITH> , <emp: 7521 WARD> , <emp: 7566 JONES>]
可以看到自始至终,都只有一次交互
>>> for t in a:
... print t.ename ,t.deptno
...
( 0.000) SELECT `emp`.`empno` , `emp`.`ename` , `emp`.`job` , `emp`.`mgr` , `emp`.`hiredate` , `emp`.`sal` , `emp`.`deptno_id` FROM `emp` WHERE `emp`.`empno` IN ( 7369, 7521, 7566) ORDER BY `emp`.`empno` ASC , `emp`.`ename` ASC; args=( 7369, 7521, 7566)
( 0.000) SELECT `dept`.`deptno` , `dept`.`dname` , `dept`.`loc` FROM `dept` WHERE `dept`.`deptno` IN ( 20, 30) ORDER BY `dept`.`deptno` ASC; args=( 20, 30)
SMITH 20 RESEARCH
WARD 30 SALES
JONES 20 RESEARCH正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

