使用Oracle中的emp,dept来学习Django ORM

学习Django的时候,总是觉得这部分内容和实际的应用有一定的差别或者距离。一方面Django自带的ORM对于底层数据库来说是一种适配性很强的组件,可以不强依赖于某一种数据库,sqlite,MySQL,Oracle,PG等等都可以,学习起来需要一定的周期。另外一方面是因为这种方式是通用的API,一下子没有了SQL语句,要理解并接受这种思想,需要一点时间,对很多DBA来说需要适应。第三点就是没有融会贯通,好像看明白了,但是实际写的时候发现还是摸黑,不知道从何入手。
所以我就换个思路,从数据库的角度来反向解析Django怎么实现我们常见的数据需求。先做减法,侧重于说查询的部分。常见的数据需求,这个需求有些大,怎么让他更通用呢,我想到了Oracle里面的emp,dept,自打学习数据库,很多的测试案例就和这两个表分不开,所以我们就从这个为切入点来逐步分析。
有的同学可能开始就打了退堂鼓,Oracle的还要转换语句,还有数据类型,而使用的数据库是MySQL,是不是有些麻烦啊,其实这些都不是事儿,不花一点功夫肯定难有收获。
我们配置下emp,dept的结构,是在Django的models.py的文件中配置即可。
from django.db import models
import django.utils.timezone as timezone
class dept(models.Model):
deptno = models.AutoField( primary_key= True)
dname = models.CharField( max_length= 30)
loc = models.CharField( max_length= 30, default= ' ')
class Meta:
db_table = 'dept'
verbose_name = 'DEPT'
verbose_name_plural = 'DEPT'
ordering = [ 'deptno']
def __unicode__( self):
return '%s %s' % ( self.deptno , self.dname)
class dept(models.Model):
deptno = models.AutoField( primary_key= True)
dname = models.CharField( max_length= 30)
loc = models.CharField( max_length= 30, default= ' ')
class Meta:
db_table = 'dept'
verbose_name = 'DEPT'
verbose_name_plural = 'DEPT'
ordering = [ 'deptno']
def __unicode__( self):
return '%s %s' % ( self.deptno , self.dname)
class emp(models.Model):
empno = models.AutoField( primary_key= True)
ename = models.CharField( max_length= 30)
job = models.CharField( max_length= 30)
mgr = models.IntegerField()
hiredate = models.DateTimeField( 'hire date', default=timezone.now)
sal = models.IntegerField()
comm = models.IntegerField
deptno = models.ForeignKey( 'dept')
class Meta:
db_table = 'emp'
verbose_name = 'EMP'
verbose_name_plural = 'EMP'
verbose_name_plural = 'EMP'
ordering = [ 'empno', 'ename']
def __unicode__( self):
return '%s %s' % ( self.empno , self.ename)
其实内容来看倒也不难,类型是通用的。
使用python manage.py makemigrations得到变化的结构和数据
Migrations for 'scott':
0001_initial.py:
- Create model dept
- Create model emp
得到的SQL如下:
>python manage.py sqlmigrate scott 0001
BEGIN;
CREATE TABLE "dept" ( "deptno" integer NOT NULL PRIMARY KEY AUTOINCREMENT , "dname" varchar( 30) NOT NULL , "loc" varchar( 30) NOT NULL);
CREATE TABLE "emp" ( "empno" integer NOT NULL PRIMARY KEY AUTOINCREMENT , "ename" varchar( 30) NOT NULL , "job" varchar( 30) NOT NULL , "mgr" integer NOT NULL
, "hiredate" datetime NOT NULL , "sal" integer NOT NULL , "deptno_id" integer NOT NULL REFERENCES "dept" ( "deptno"));
CREATE INDEX "emp_d6b13549" ON "emp" ( "deptno_id");
COMMIT;
简单确认下,我们就可以生成创建出来这两个表了,使用python manage.py migrate即可。
emp的表结构如下:
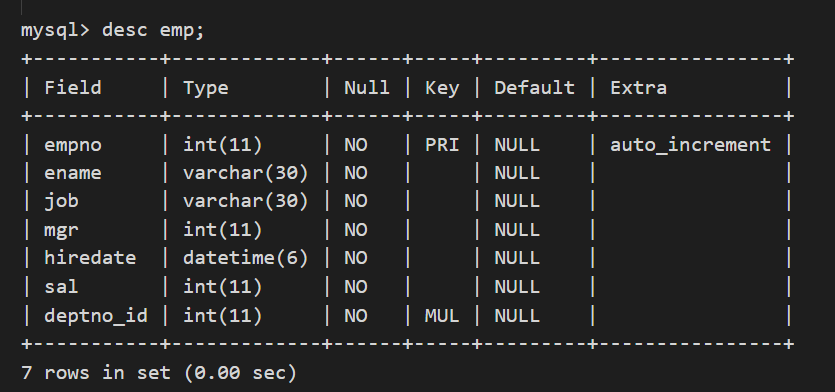
dept的表结构如下:
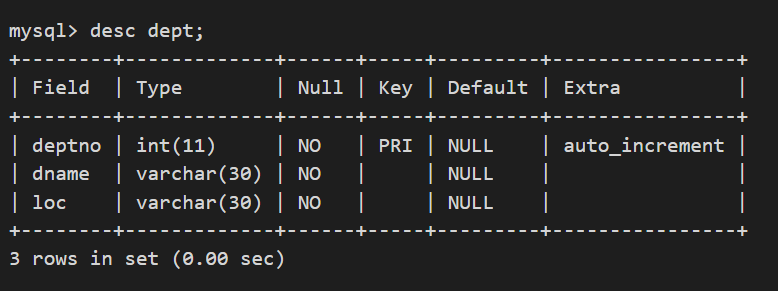
我们初始化一下数据,这个时候直接使用SQL也可以.
dept表的初始化语句如下:
insert into dept values( 10,'ACCOUNTING','NEW YORK');
insert into dept values( 20,'RESEARCH','DALLAS');
insert into dept values( 30,'SALES','CHICAGO');
insert into dept values( 40,'OPERATIONS','BOSTON');
emp表的初始化语句如下,特别需要注意的就是字段不是deptno,而是deptno_id
insert into emp(EMPNO ,ENAME ,JOB ,MGR ,HIREDATE ,SAL ,DEPTNO_ID) values( 7369,'SMITH','CLERK',7902,'1980-12-17',800.00,20);
insert into emp(EMPNO ,ENAME ,JOB ,MGR ,HIREDATE ,SAL ,DEPTNO_ID) values( 7499,'ALLEN','SALESMAN',7698,'1981-2-20',1600.00,30);
insert into emp(EMPNO ,ENAME ,JOB ,MGR ,HIREDATE ,SAL ,DEPTNO_ID) values( 7521,'WARD','SALESMAN',7698,'1981-2-22',1250.00,30);
insert into emp(EMPNO ,ENAME ,JOB ,MGR ,HIREDATE ,SAL ,DEPTNO_ID) values( 7566,'JONES','MANAGER',7839,'1981-4-2',2975.00,20);
insert into emp(EMPNO ,ENAME ,JOB ,MGR ,HIREDATE ,SAL ,DEPTNO_ID) values( 7654,'MARTIN','SALESMAN',7698,'1981-9-28',1250.00,30);
insert into emp(EMPNO ,ENAME ,JOB ,MGR ,HIREDATE ,SAL ,DEPTNO_ID) values( 7698,'BLAKE','MANAGER',7839,'1981-5-1',2850.00,30);
insert into emp(EMPNO ,ENAME ,JOB ,MGR ,HIREDATE ,SAL ,DEPTNO_ID) values( 7782,'CLARK','MANAGER',7839,'1981-6-9',2450.00,10);
insert into emp(EMPNO ,ENAME ,JOB ,MGR ,HIREDATE ,SAL ,DEPTNO_ID) values( 7788,'SCOTT','ANALYST',7566,'1987--4-19',3000.00,20);
insert into emp(EMPNO ,ENAME ,JOB ,MGR ,HIREDATE ,SAL ,DEPTNO_ID) values( 7839,'KING','PRESIDENT',0,'1981-11-17',5000.00,10);
insert into emp(EMPNO ,ENAME ,JOB ,MGR ,HIREDATE ,SAL ,DEPTNO_ID) values( 7844,'TURNER','SALESMAN',7698,'1981-9-8',1500.00,30);
insert into emp(EMPNO ,ENAME ,JOB ,MGR ,HIREDATE ,SAL ,DEPTNO_ID) values( 7876,'ADAMS','CLERK',7788,'1987-5-23',1100.00,20);
insert into emp(EMPNO ,ENAME ,JOB ,MGR ,HIREDATE ,SAL ,DEPTNO_ID) values( 7900,'JAMES','CLERK',7698,'1981-12-3',950,30);
insert into emp(EMPNO ,ENAME ,JOB ,MGR ,HIREDATE ,SAL ,DEPTNO_ID) values( 7902,'FORD','ANALYST',7566,'1981-12-3',3000,20);
insert into emp(EMPNO ,ENAME ,JOB ,MGR ,HIREDATE ,SAL ,DEPTNO_ID) values( 7934,'MILLER','CLERK',7782,'1982-1-23',1300,10);
insert into emp(EMPNO ,ENAME ,JOB ,MGR ,HIREDATE ,SAL ,DEPTNO_ID) values( 9999,'SHUNPING','CLERK',7782,'1988-5-5',2456.34,10);
剩下的事情就是实践了。我们就选择emp,dept常见的一些SQL来看看ORM能否完成这个任务。
1、显示所有的姓名、工种、工资和奖金,按工种降序排列,若工种相同则按工资升序排列。
如果使用MySQL,语句和数据结果如下:
mysql> select ename ,job ,sal from emp order by job desc ,sal asc;
+----------+-----------+------+
| ename | job | sal |
+----------+-----------+------+
| WARD | SALESMAN | 1250 |
| MARTIN | SALESMAN | 1250 |
使用order_by的方式来处理,可以看到有了一点头绪,但是还是没有实现需求。
>>> emp.objects.all().order_by( 'job')
[<emp: 7788 SCOTT> , <emp: 7902 FORD> , <emp: 7369 SMITH> , ....
所以我们的重点就是排序了,ORM本身有order_by函数,还可以调整DESC,ASC,所以一个基本符合要求的方式如下:
>>> emp.objects.all().order_by(( '-job') ,( 'sal'))
[<emp: 7521 WARD> , <emp: 7654 MARTIN> , <emp: 7844 TURNER>
第二个题目也是类似的。
2、查询员工的姓名和入职日期,并按入职日期从先到后进行排列。
SQL语句如下:
select ename,hiredate from emp order by hiredate asc;
现在的语句如下:
emp.objects.all().order_by(( 'hiredate'))
3. 计算工资最高的员工
这个需求充分考虑到聚合函数的部分,我们可以使用aggregate来完成这个工作。
>>> emp.objects.all().aggregate(Max( 'sal'))
{ 'sal__max': 5000}
4.查询至少有一个员工的部门信息。
这个部分会涉及到表关联关系,如果是通过SQL的方式,语句如下:
select * from dept where deptno in (select distinct deptno from emp where mgr is not null);
执行的结果如下,可以看到第一种方式能出结果,但是还是存在重复值,需要用distinct过啦一下。
>>> dept.objects.filter( emp__mgr__isnull= False)
[<dept: 10 ACCOUNTING> , <dept: 10 ACCOUNTING> , <dept: 10 ACCOUNTING> , <dept: 10 ACCOUNTING> , <dept: 20 RESEARCH> , <dept: 20 RESEARCH> , <dept: 20 RESEARCH> , <dept: 20 RESEARCH> , <dept: 20 RESEARCH> , <dept: 30 SALES> , <dept: 30 SALES> , <dept: 30 SALES> , <dept: 30 SALES> , <dept: 30 SALES> , <dept: 30 SALES>]
>>> dept.objects.filter( emp__mgr__isnull= False).distinct()
[<dept: 10 ACCOUNTING> , <dept: 20 RESEARCH> , <dept: 30 SALES>]
>>>
后续继续补充ORM的内容。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

