在AIX或Linux下,如何查看磁盘是否包含数据?
在AIX或Linux下,如何查看磁盘是否包含数据?
真题1、在AIX或Linux下,如何查看磁盘是否包含数据?
答案:在AIX下,可以使用lquerypv -h来查看磁盘是否包含数据,或磁盘头是否被dd过。这在安装RAC的过程中,是非常实用的一个命令。如果不包括数据的话,那么如下所示:
[ZFFR4CB2101:root]/]> lquerypv -h /dev/rhdisk10
00000000 00000000 00000000 00000000 00000000 |................|
00000010 00000000 00000000 00000000 00000000 |................|
00000020 00000000 00000000 00000000 00000000 |................|
00000030 00000000 00000000 00000000 00000000 |................|
00000040 00000000 00000000 00000000 00000000 |................|
00000050 00000000 00000000 00000000 00000000 |................|
00000060 00000000 00000000 00000000 00000000 |................|
00000070 00000000 00000000 00000000 00000000 |................|
00000080 00000000 00000000 00000000 00000000 |................|
00000090 00000000 00000000 00000000 00000000 |................|
000000A0 00000000 00000000 00000000 00000000 |................|
000000B0 00000000 00000000 00000000 00000000 |................|
000000C0 00000000 00000000 00000000 00000000 |................|
000000D0 00000000 00000000 00000000 00000000 |................|
000000E0 00000000 00000000 00000000 00000000 |................|
000000F0 00000000 00000000 00000000 00000000 |................|
如果包括数据的话,那么显示如下所示:
[ZFFR4CB2101:root]/]> lquerypv -h /dev/rhdisk10
00000000 00820101 00000000 80000000 B6FE0F29 |...............)|
00000010 00000000 00000000 00000000 00000000 |................|
00000020 4F52434C 4449534B 00000000 00000000 |ORCLDISK........|
00000030 00000000 00000000 00000000 00000000 |................|
00000040 0B200000 00000103 4F43525F 30303030 |. ......OCR_0000|
00000050 00000000 00000000 00000000 00000000 |................|
00000060 00000000 00000000 4F435200 00000000 |........OCR.....|
00000070 00000000 00000000 00000000 00000000 |................|
00000080 00000000 00000000 4F43525F 30303030 |........OCR_0000|
00000090 00000000 00000000 00000000 00000000 |................|
000000A0 00000000 00000000 00000000 00000000 |................|
000000B0 00000000 00000000 00000000 00000000 |................|
000000C0 00000000 00000000 01F80D69 66A0E000 |...........if...|
000000D0 01F80D69 70C48800 02001000 00100000 |...ip...........|
000000E0 0001BC80 0002001C 00000003 00000001 |................|
000000F0 00000002 00000002 00000000 00000000 |................|
在Linux中,可以使用hexdump命令来实现相同的效果,如下所示:
[root@OCPLHR ~]# hexdump -n 1024 -C /dev/sdb1
00000000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00000200 4c 41 42 45 4c 4f 4e 45 01 00 00 00 00 00 00 00 |LABELONE........|
00000210 50 ef ff c1 20 00 00 00 4c 56 4d 32 20 30 30 31 |P... ...LVM2 001|
00000220 53 68 78 53 57 33 43 33 48 64 44 48 33 56 65 79 |ShxSW3C3HdDH3Vey|
00000230 44 54 50 78 4a 6e 42 66 46 37 74 5a 4a 78 79 7a |DTPxJnBfF7tZJxyz|
00000240 00 84 a6 54 02 00 00 00 00 00 03 00 00 00 00 00 |...T............|
00000250 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000260 00 00 00 00 00 00 00 00 00 10 00 00 00 00 00 00 |................|
00000270 00 f0 02 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000280 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00000400
[root@OCPLHR ~]# hexdump -n 1024 -C /dev/sdb6
00000000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00000400
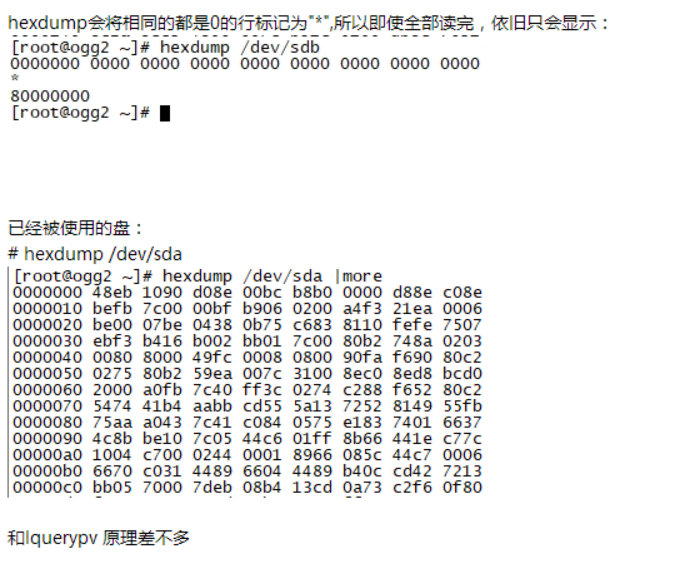
很明显,磁盘/dev/sdb1已经被使用了,而/dev/sdb6还没有被使用。其中,-n参数表示只格式前n个长度的字符,而-C参数表示每个字节显示为16进制和相应的ASCII字符。
& 说明:
有关lquerypv和hexdump的更多内容可以参考我的BLOG:http://blog.itpub.net/26736162/viewspace-2149976/
问: linux用类似aix 中lquerypv -h /dev 查看磁盘是否有内容的命令?
答: 查看磁盘有无数据的命令:aix是lquerypv 、linux是hexdump
Linux命令学习总结:hexdump
2015-12-26 10:44 by 潇湘隐者, 7741 阅读, 0 评论, 收藏, 编辑命令简介:
hexdump是Linux下的一个二进制文件查看工具,它可以将二进制文件转换为ASCII、八进制、十进制、十六进制格式进行查看。
指令所在路径:/usr/bin/hexdump
命令语法:
hexdump: [-bcCdovx] [-e fmt] [-f fmt_file] [-n length] [-s skip] [file ...]
命令参数:
此命令参数是Red Hat Enterprise Linux Server release 5.7下hexdump命令参数,不同版本Linux的hexdump命令参数有可能不同。
|
参数 |
长参数 |
描叙 |
|
-b |
|
每个字节显示为8进制。一行共16个字节,一行开始以十六进制显示偏移值 |
|
-c |
|
每个字节显示为ASCII字符 |
|
-C |
|
每个字节显示为16进制和相应的ASCII字符 |
|
-d |
|
两个字节显示为10进制 |
|
-e |
|
格式化输出 |
|
-f |
|
Specify a file that contains one or more newline separated format strings. Empty lines and lines whose first non-blank character is a hash mark (#) are ignored. |
|
-n |
|
只格式前n个长度的字符 |
|
-o |
|
两个字节显示为8进制 |
|
-s |
|
从偏移量开始输出 |
|
-v |
|
The -v option causes hexdump to display all input data. Without the -v option, any number of groups of output lines, which would be identical to the immediately preceding group of output lines |
|
-x |
|
双字节十六进制显示 |
使用示例:
1: 查看hexdmp命令的帮助信息
[root@DB-Server ~]# man hexdump
2: 以8进制显示文件里面的字符。
[root@DB-Server ~]# cat >test.txt
ABCDEF
GHIJKM
123456
[root@DB-Server ~]# hexdump -b test.txt
0000000 101 102 103 104 105 106 012 107 110 111 112 113 115 012 061 062
0000010 063 064 065 066 012
0000015
注意:一行共16个字节,一行开始以十六进制显示偏移值(如下所示,第一行字符串只显示到D,第十六个字节,后面的F12*DFDF换行显示)
[root@DB-Server ~]# cat >test.txt
ABCDEFGHIJKLMNODF12*DFDF
[2]+ Stopped cat > test.txt
You have new mail in /var/spool/mail/root
[root@DB-Server ~]# hexdump -b test.txt
0000000 101 102 103 104 105 106 107 110 111 112 113 114 115 116 117 104
0000010 106 061 062 052 104 106 104 106 012
0000019
[root@DB-Server ~]# hexdump -c test.txt
0000000 A B C D E F G H I J K L M N O D
0000010 F 1 2 * D F D F /n
0000019

3:以ASCII字符显示文件中字符
[root@DB-Server ~]# hexdump -c test.txt
0000000 A B C D E F G H I J K L M N O D
0000010 F 1 2 * D F D F /n
0000019
hexdump 以ASCII字符显示时,可以输出换行符,这个功能可以用来检查文件是Linux的换行符格式还是Widows格式换行符。如下所示

4:以16进制和相应的ASCII字符显示文件里的字符
[root@DB-Server ~]# hexdump -C test.txt
00000000 41 42 43 44 45 46 47 48 49 4a 4b 4c 4d 4e 4f 44 |ABCDEFGHIJKLMNOD|
00000010 46 31 32 2a 44 46 44 46 0a |F12*DFDF.|
00000019
5:只格式文件中前n个字符
[root@DB-Server ~]# hexdump -C -n 5 test.txt
00000000 41 42 43 44 45 |ABCDE|
00000005
6:以偏移量开始格式输出。如下所示指定参数-s 5 ,前面的ABCDE字符没有了。
[root@DB-Server ~]# hexdump -C test.txt
00000000 41 42 43 44 45 46 47 48 49 4a 4b 4c 4d 4e 4f 44 |ABCDEFGHIJKLMNOD|
00000010 46 31 32 2a 44 46 44 46 0a |F12*DFDF.|
00000019
[root@DB-Server ~]# hexdump -C -s 5 test.txt
00000005 46 47 48 49 4a 4b 4c 4d 4e 4f 44 46 31 32 2a 44 |FGHIJKLMNODF12*D|
00000015 46 44 46 0a |FDF.|
00000019
作者:潇湘隐者
我使用过的Linux命令之hexdump - ”十六“进制查看器
本文链接:http://codingstandards.iteye.com/blog/805778 (转载请注明出处)
用途说明
hexdump命令一般用来查看”二进制“文件的十六进制编码,但实际上它的用途不止如此,手册页上的说法是“ascii, decimal, hexadecimal, octal dump“,这也就是本文标题为什么要将”十六“给引起来的原因,而且它能查看任何文件,而不只限于二进制文件了。另外还有xxd和od也可以做类似的事情,但是我从未用过。在程序输出二进制格式的文件时,常用hexdump来检查输出是否正确。当然也可以使用Windows上的UltraEdit32之类的工具查看文件的十六进制编码,但Linux上有现成的工具,何不拿来用呢。
常用参数
如果要看到较理想的结果,使用-C参数,显示结果分为三列(文件偏移量、字节的十六进制、ASCII字符)。
格式:hexdump -C binfile
一般文件都不是太小,最好用less来配合一下。
格式:hexdump -C binfile | less
使用示例
示例一 比较各种参数的输出结果
[root@new55 ~]# echo /etc/passwd | hexdump
0000000 652f 6374 702f 7361 7773 0a64
000000c
[root@new55 ~]# echo /etc/passwd | od -x
0000000 652f 6374 702f 7361 7773 0a64
0000014
[root@new55 ~]# echo /etc/passwd | xxd
0000000: 2f65 7463 2f70 6173 7377 640a /etc/passwd.
[root@new55 ~]# echo /etc/passwd | hexdump -C <== 规范的十六进制和ASCII码显示(Canonical hex+ASCII display )
00000000 2f 65 74 63 2f 70 61 73 73 77 64 0a |/etc/passwd.|
0000000c
[root@new55 ~]# echo /etc/passwd | hexdump -b <== 单字节八进制显示(One-byte octal display)
0000000 057 145 164 143 057 160 141 163 163 167 144 012
000000c
[root@new55 ~]# echo /etc/passwd | hexdump -c <== 单字节字符显示(One-byte character display)
0000000 / e t c / p a s s w d /n
000000c
[root@new55 ~]# echo /etc/passwd | hexdump -d <== 双字节十进制显示(Two-byte decimal display)
0000000 25903 25460 28719 29537 30579 02660
000000c
[root@new55 ~]# echo /etc/passwd | hexdump -o <== 双字节八进制显示(Two-byte octal display)
0000000 062457 061564 070057 071541 073563 005144
000000c
[root@new55 ~]# echo /etc/passwd | hexdump -x <== 双字节十六进制显示(Two-byte hexadecimal display)
0000000 652f 6374 702f 7361 7773 0a64
000000c
[root@new55 ~]# echo /etc/passwd | hexdump -v
0000000 652f 6374 702f 7361 7773 0a64
000000c
比较来比较去,还是hexdump -C的显示效果更好些。
示例二 确认文本文件的格式
文本文件在不同操作系统上的行结束标志是不一样的,经常会碰到由此带来的问题。比如Linux的许多命令不能很好的处理DOS格式的文本文件。Windows/DOS下的文本文件是以/r/n作为行结束的,而Linux/Unix下的文本文件是以/n作为行结束的。
[root@new55 ~]# cat test.bc
123*321
123/321
scale=4;123/321
[root@new55 ~]# hexdump -C test.bc
00000000 31 32 33 2a 33 32 31 0a 31 32 33 2f 33 32 31 0a |123*321.123/321.|
00000010 73 63 61 6c 65 3d 34 3b 31 32 33 2f 33 32 31 0a |scale=4;123/321.|
00000020 0a |.|
00000021
[root@new55 ~]#
注:常见的ASCII字符的十六进制表示
/r 0D
/n 0A
/t 09
DOS/Windows的换行符 /r/n 即十六进制表示 0D 0A
Linux/Unix的换行符 /n 即十六进制表示 0A
示例三 查看wav文件
有些IVR系统需要8K赫兹8比特的语音文件,可以使用hexdump看一下具体字节编码。
[root@web186 root]# ls -l tmp.wav
-rw-r--r-- 1 root root 32381 2010-04-19 tmp.wav
[root@web186 root]# file tmp.wav
tmp.wav: RIFF (little-endian) data, WAVE audio, ITU G.711 a-law, mono 8000 Hz
[root@web186 root]# hexdump -C tmp.wav | less
00000000 52 49 46 46 75 7e 00 00 57 41 56 45 66 6d 74 20 |RIFFu~..WAVEfmt |
00000000 52 49 46 46 75 7e 00 00 57 41 56 45 66 6d 74 20 |RIFFu~..WAVEfmt |
00000010 12 00 00 00 06 00 01 00 40 1f 00 00 40 1f 00 00 |........@...@...|
00000020 01 00 08 00 00 00 66 61 63 74 04 00 00 00 43 7e |......fact....C~|
00000030 00 00 64 61 74 61 43 7e 00 00 d5 d5 d5 d5 d5 d5 |..dataC~........|
00000040 d5 d5 d5 d5 d5 d5 d5 d5 d5 d5 d5 d5 d5 d5 d5 d5 |................|
*
000000a0 d5 d5 d5 d5 d5 d5 d5 d5 d5 55 d5 55 d5 d5 55 d5 |.........U.U..U.|
000000b0 55 d5 d5 55 d5 55 d5 d5 55 d5 55 55 55 55 55 55 |U..U.U..U.UUUUUU|
000000c0 55 55 55 55 55 55 55 d5 d5 d5 d5 d5 d5 d5 d5 d5 |UUUUUUU.........|
000000d0 d5 55 55 55 55 55 55 55 55 55 55 55 55 55 55 55 |.UUUUUUUUUUUUUUU|
000000e0 55 55 55 55 55 55 55 55 55 d5 d5 d5 d5 d5 d5 d5 |UUUUUUUUU.......|
000000f0 d5 d5 d5 d5 55 55 55 55 55 55 55 55 55 55 55 55 |....UUUUUUUUUUUU|
00000100 55 55 55 55 55 55 55 55 55 55 55 55 d5 d5 d5 d5 |UUUUUUUUUUUU....|
00000110 d5 d5 d5 d5 d5 d5 55 55 55 55 55 55 55 55 55 55 |......UUUUUUUUUU|
00000120 55 55 55 55 55 55 55 55 55 55 55 55 55 55 d5 d5 |UUUUUUUUUUUUUU..|
00000130 d5 d5 d5 d5 d5 d5 d5 d5 d5 55 55 55 55 55 55 55 |.........UUUUUUU|
00000140 55 55 d5 55 55 55 55 55 55 55 55 55 55 55 55 55 |UU.UUUUUUUUUUUUU|
00000150 55 d5 d5 d5 d5 d5 d5 d5 d5 d5 d5 55 55 55 55 55 |U..........UUUUU|
00000160 55 55 55 55 55 55 55 55 55 55 55 55 55 55 55 55 |UUUUUUUUUUUUUUUU|
00000170 55 55 55 55 d5 d5 d5 d5 d5 d5 d5 d5 d5 55 d5 55 |UUUU.........U.U|
00000180 55 55 55 55 55 55 55 55 55 55 55 55 55 55 55 55 |UUUUUUUUUUUUUUUU|
00000190 55 55 55 55 55 55 55 d5 d5 d5 d5 d5 d5 d5 d5 55 |UUUUUUU........U|
000001a0 55 55 55 55 55 55 55 d5 d5 55 55 55 55 55 55 55 |UUUUUUU..UUUUUUU|
000001b0 55 55 55 55 55 55 55 d5 55 55 d5 55 55 55 55 55 |UUUUUUU.UU.UUUUU|
000001c0 55 55 d5 55 d5 d5 55 d5 55 55 55 55 55 55 55 55 |UU.U..U.UUUUUUUU|
000001d0 55 55 55 55 55 55 55 55 55 55 55 55 55 55 55 d5 |UUUUUUUUUUUUUUU.|
000001e0 55 d5 d5 d5 d5 55 55 55 55 55 55 55 55 55 55 55 |U....UUUUUUUUUUU|
000001f0 55 55 55 55 55 55 55 55 55 55 55 55 d5 55 55 d5 |UUUUUUUUUUUU.UU.|
00000200 55 55 55 55 55 55 55 55 55 d5 d5 d5 d5 d5 55 55 |UUUUUUUUU.....UU|
00000210 55 55 55 55 55 55 55 55 55 55 55 55 55 55 55 d5 |UUUUUUUUUUUUUUU.|
00000220 55 55 d5 55 d5 55 55 d5 55 d5 55 55 d5 55 d5 d5 |UU.U.UU.U.UU.U..|
00000230 d5 d5 d5 d5 d5 d5 d5 d5 d5 d5 d5 d5 d5 d5 d5 d5 |................|
*
00000ba0 d5 d5 d5 d5 d5 d5 d5 d5 d5 d5 d5 55 55 d5 55 d5 |...........UU.U.|
00000bb0 55 55 d5 55 d5 55 d5 d5 55 d5 55 55 55 55 55 55 |UU.U.U..U.UUUUUU|
00000bc0 55 55 55 55 55 55 55 55 55 d5 d5 55 55 55 55 55 |UUUUUUUUU..UUUUU|
00000bd0 55 55 55 55 55 55 55 d5 55 55 55 55 55 55 d5 55 |UUUUUUU.UUUUUU.U|
00000be0 55 55 55 55 55 55 55 55 55 55 55 d5 55 55 55 55 |UUUUUUUUUUU.UUUU|
00000bf0 55 55 55 55 55 55 55 55 d5 d5 55 55 55 55 55 d5 |UUUUUUUU..UUUUU.|
00000c00 d5 55 55 55 55 d5 d5 d5 55 55 55 55 55 d5 d5 55 |.UUUU...UUUUU..U|
:q
[root@web186 root]#
问题思考
相关资料
【1】kindle's blog hexdump,od,xxd
【2】杭州美创科技技术资源中心 使用hexdump 查看二进制文件
返回 我使用过的Linux命令系列总目录
使用hexdump工具追踪EXT4文件系统中的一个文件
昨天追踪EXT4文件系统的过程中出了点问题,就是找不到文件,于是试了一下追踪FAT32文件系统的,成功之后有了点信心,今天继续嗑EXT4文件系统,终于找到啦,记录一下。
- 操作系统:linux(centos 6.5)
- 文件系统:EXT4
- 工具:hexdump,windows自带计算器
- 参考资源:《数据重现-文件系统原理精解与数据恢复最佳实践》(马林 著)
《基于EXT4文件系统的数据恢复方法研究》(徐国天)
题为《Ext4文件系统架构分析》的系列博客
题为《 深入理解ext4(一)----extent区段》的博客
题为《ext4的Extent解析》的博客
题为《ext4_ext_find_extent解析》的博客
EXT4文件系统架构(非原创):
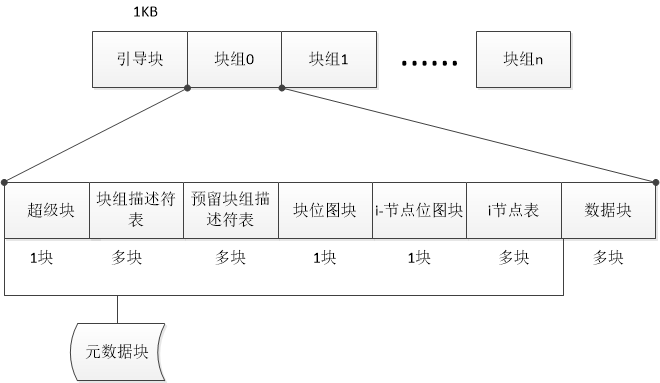
补充说明:EXT4文件系统中只有0号块组的超级块和块组描述符表的位置是固定的,其他都不固定。其中,超级块总是开始于偏移位置1024(字节),占据1024个字节,块组描述符表紧随超级块后面,占用的大小是不定。
步骤:
1、查看文件系统基本情况,新建子目录和文件

可以看到挂载在/boot目录下的文件系统类型是EXT4,因此在改目录下新建子目录及文件:

文件内容为:“This test is belong to Boot folder!”文件基本信息如下:

2、查看超级块,找到0号块组起始块号、块大小、每块组所含块数、每块组i节点数、第一个非保留i节点、每个i节点大小。
命令:hexdump -s 1024 -n 1024 -C /dev/sda1
查看结果:

首先可以看到0x38-0x39是EXT系列文件系统的签名标志:“53 ef”
0x14-0x17是0号块组起始块号:0x01,说明超级块前面有一个块为保留块,用来存储引导程序。
0x18-0x1b是块大小:0x00,这里的值指的是将1024字节左移的位数,移动0位也就是1024字节,移动一位相当于乘以2,就是2048字节。
0x20-0x23是每块组所含块数:0x2000(十进制8192)
0x28-0x2b是每块组所含i节点数:0x07f0(十进制2032)
0x54-0x57是第一个非保留i节点号:0x0b(11),一般为lost+found目录
0x58-0x59是每个i节点结构的大小:0x80(十进制128),也就是每个i节点表项占用128个字节。
3、查看块组描述符表,找到块位图块、i节点位图块、i节点表起始块号、块组目录数。
命令:hexdump -s 2048 -n 1024 -C /dev/sda1
查看结果:
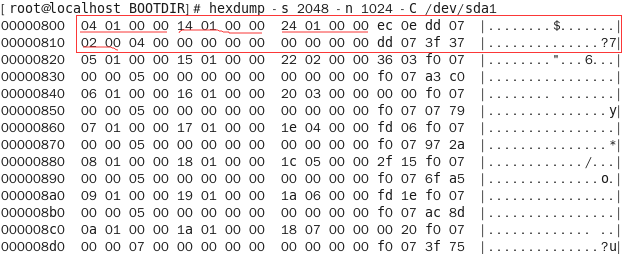
块组描述符表中每个块组使用32个字节来描述,因此第一个32字节描述的就是0号块组。
0x00-0x04是块位图块起始块号:0x0104
0x05-0x07是i节点位图块起始块号:0x0114
0x08-0x0b是i节点表起始块号:0x0124
0x10-0x11是该块组的目录数:0x02
这里获取的起始块号是逻辑块号(将文件系统所有的块从0开始递增编号),因此在计算偏移量时可以直接乘以每块字节数(0x400,也就是十进制的1024)
这里补充说明一下:EXT3文件系统的块位图块号、i节点位图块和i节点表起始块号是递增的,而这里他们三个之间却是相差一个常量:16。
因为这里使用了一个EXT4新引进的结构:Flexible 块组(flex_bg)
|
Flexible 块组 Flexible 块组的设计目的是组成更大的逻辑块组,尽量让大文件连续,将元数据聚集加快元数据载入。因此它的做法是将几个块组的块位图块,i节点位图块,i节点表块放在这个逻辑块组的第一个块组中,这样剩下的块组中就只存储了该块组的超级块和块组描述表。 上面的块组描述表中可以看出这个Flexible 块组是将16个块组合成了一个逻辑块组。 说起Flexible 块组就要提起元块组(Media Block Group),因为他和Flexible 块组是“有你没我”的关系。Flexible 块组是移动了块位图块、i节点位图块、i节点表块,元块组是减少了块组描述符表的备份,原本块组描述符表和超级块一起备份在块组号为0或者3、5、7的幂的块组,元块组是只在一个元块组的第一、二个块组和最后一个块组中备份块组描述符表,增加元块组存储数据的空间。 |
3、从根目录中找到子目录
第一步我们提到了第一个非保留i节点号为11,那么前面的10个保留i节点的作用是什么呢(i节点号从1开始编号),这里只说明2号节点是存储的是根目录i节点号,因此我们读取i节点表的2号表项值就可以找到根目录所在块号了。
计算i节点表项的偏移量涉及到了块组描述符表中的i节点表起始块号:0x0124。
某i节点表项起始字节=i节点起始块号*每块所占字节数+(该i节点号-1)*每个i节点表项所占字节数
0x0124*0x400+(0x02-0x01)*0x80=0x49080
下面就可以读取根目录i节点表项值了。
命令:hexdump -s 0x49080 -n 128 -C /dev/sda1
查看结果:

0xa8-0xd7是12个直接块指针,其中四个字节为一个单位,表示一个块号。
(这里要解释的是:EXt4文件系统将12个直接块指针、1个一级间接块指针、1个二级间接块指针、1个三级间接块指针,一共60个字节用extent结构来替换,但前提是偏移0xa0-0xa3处的标志位置为“00 00 08 00”,而这里全为0,则证明没有使用extent结构,因此依旧按照块指针形式查找根目录)
图中可以看出根目录只占用了一个块,块号为:0x1104
根目录的起始偏移字节为=根目录所在块号*每块所占字节数
则根目录的起始偏移字节:0x1104*0x400=0x441000
使用命令:hexdump -s 0x441000 -n 1024 -C /dev/sda1 查看根目录内容:
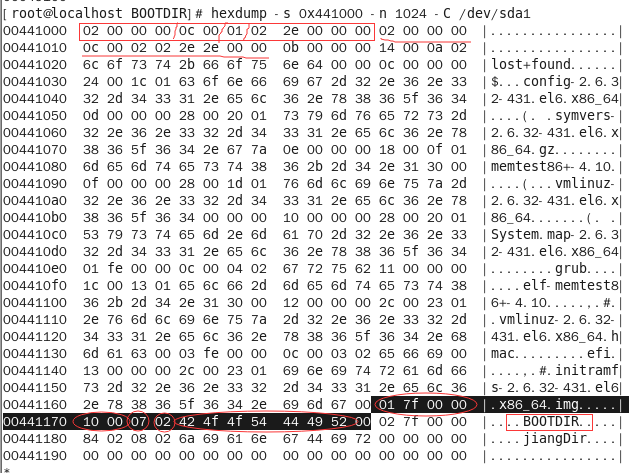
查看/boot目录下的文件:

可以看到两者的内容是相符的,说明我们找的没有错。根目录中BOOTDIR的目录项用黑色底纹标注。
0x6c-0x6f是该文件内容所在i节点号:0x7f01
0x70-0x71是本目录项长度:0x10(16字节)
0x72是本目录项名字长度0x07(7个字节)
0x73是本文件类型:0x02(表示目录)
0x74开始是文件名的ASCCI码:“42 4f 4f 54 44 49 52 00”
在这一步中与FAT32文件系统的区别有两个:
一是怎么寻找根目录。FAT32中根目录在数据区的开头,因此我们可以直接去数据区读取;而EXT4文件系统中,我们需要通过2号i节点表找到根目录所在的块号,才能看到根目录内容,这里就可以看出EXT4文件系统将目录也看作文件了,因为他的读取方式和普通文件是一样的,只不过普通文件需要从目录中得到i节点号,而根目录是一开始就定好了i节点号。
二是目录的大小。FAT32中目录的大小是固定的(短文件名目录占32字节,长文件名目录占多个32字节),所以当文件名过长时,使用了长文件名机制来解决,而EXT4文件系统的目录项大小是在目录项中灵活定的。比如这一步中我们查看到的根目录结果中,开始的12个字节是本目录项,紧接着12个字节是根目录项,而我们要找的目标目录项的长度是16个字节,其中说明部分(i节点号,本目录项长度字节数,名字长度,文件类型)占用都是一样的,差就差在文件名部分。但我们也看到文件名后面总有“00”补齐,这是因为目录项的长度总要是4的倍数,因此不够时会用0补齐。
4、从i节点表中找到子目录所在块号
第三步中我们找到指向子目录的i节点号为0x7f01,也是逻辑i节点号,因此我们要先找到0x7f01在哪个块组中:
某i节点所在块组=该i节点号/每块组i节点个数
0x7f01/0x7f0=0x10(十进制16)
某i节点所在i节点表号=该i节点号%每块组i节点个数
0x7f01%0x7f0=0x01
因此0x7f01在16号块组的i节点表中,在改i节点表的1号表项中。
接下来我们要从块组描述符表中找到16号块组的i节点表起始块号,以便找到子目录所在块号。
某块组在块组描述符表中偏移字节=块组描述符表起始字节+块组号*每块组描述符表项字节数
2048+16*32=2560字节
我们读取2560偏移字节开始的32字节:

可以看到:0x08-0x0b为i节点表起始块号:0x020021
读取16号块组i节点表的1号i节点表项值:

这里需要重点注意:0x20-0x23处的标志内容为“00 00 08 00”也就是0x080000,表示使用了extent结构,因此这里文件子目录的搜索就需要按照extent结构来读取0x28-0x63这60个字节的内容。
有个疑问:EXT4文件系统什么时候使用extent结构,查看0号块组的10个保留i节点时,看到只有8号也就是日志节点启用了extent结构,其他都没有使用,而其他块组中似乎是都默认启用extent结构,但也发现了例外,因此不能确定EXT4关于启用extent结构的规定,后续需要注意!
|
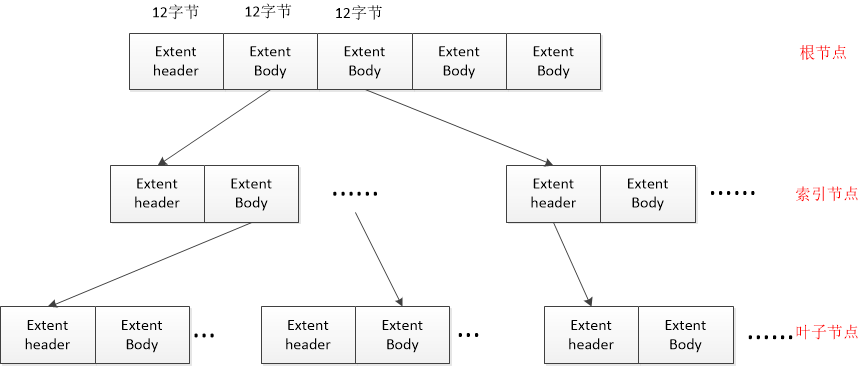
下面介绍一下extent的结构,内容有参考。 每个extent结构占用12个字节,所以每个i节点表项中可以有60/12=5个extent结构,这其中第一个extent作为extent头(extent header是一个B+树的描述头),剩下的4个是extent体(extent body,由于extent树中的节点有两种:索引节点和叶子节点,因此当节点为索引节点时(可以从extent header中区分索引节点和叶子节点)extent body存储的是下一级extent树节点信息,当节点为叶子节点时extent body 中存储的是数据块块号信息) extent树结构
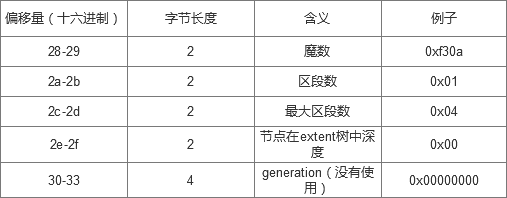
extent数据结构 extent header
这里要说明的是:魔数是一个校验值,只有当校验结果是0xf30a时B+树的块才正确 节点在extent树中的深度是从叶子节点算起,因此根节点的深度是最深的(看到有人说根节点的最大深度不超过5),当深度为0时表明是叶子节点,那么这个节点就是数据节点,他后面的extent body就是指向的数据块,存储数据块号;当深度大于0,后面的extent body表示索引节点。 extent body 当为索引节点时
当为叶子节点时
补充说明:当extent body表示索引节点时最后最后两个节点冗余是为了迁就叶子节点。 |
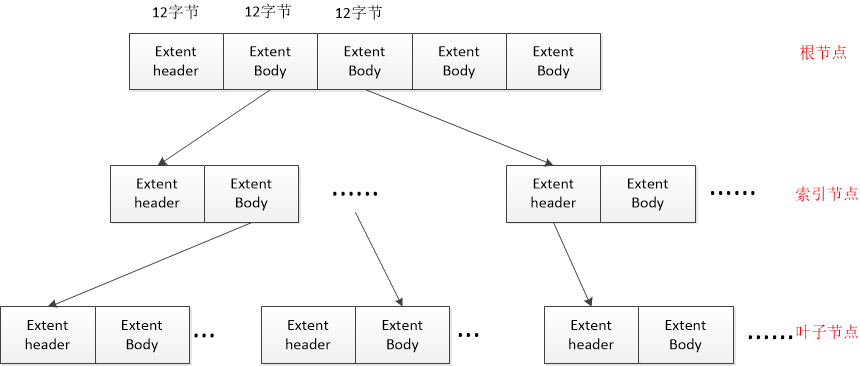
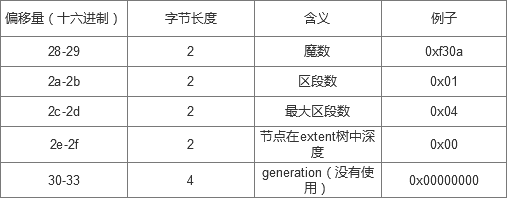
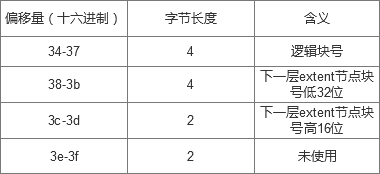
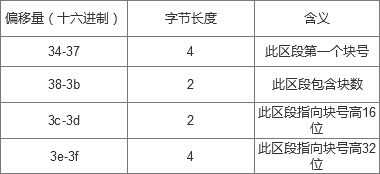
从0x28-0x63是extent结构。
extent头中说明的信息有:本区段有一个extent body,最大区段个数为4,本段在extent树中深度为0,是叶子节点。
后面紧着的12个字节是extent body说明的信息有:本区段的第一个块号是0,本区段含有一个块,本区段指向的数据块块号为0x021002。
该块的偏移字节:0x8400800
5、从子目录对应的i节点号得到目标文件块号
查看结果第4步中子目录块内容:

加黑色底纹的是本目录(“.”)和根目录(“..”)接下来就是目标文件:BOOTTEXT.txt,他的i节点号为:0x7f04
查看i节点表,找到目标文件的块号:
该i节点表项的偏移字节为:0x020021*0x400+(0x7f04%0x7f0-1)*0x80=0x8008580
读取该偏移字节处开始的128字节内容:

同样目标文件的i节点表项也启用了extent结构,按照与第4步同样的方法分析,得带目标文件所在块号0x024005(偏移字节为0x9001400)。
接下来读取该块内容:

找到啦!和第一步中使用cat命令查看的文件内容一致。
hexdump是Linux下的一个二进制文件查看工具,可以将二进制文件转换为ASCII、10进制、16进制或8进制进行查看。
首先我们准备一个测试用的文件test,十六进制如下:
00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F10 11 12 13 14 15 16 17 18 19 1A 1B 1C 1D 1E 1F20 21 22 23 24 25 26 27 28 29 2A 2B 2C 2D 2E 2F
选项:
-n length
只格式化输入文件的前length个字节
-C
输出十六进制和对应字符
输入:
hexdump -n 13 -C test
输出:
00000000 00 01 02 03 04 05 06 07 08 09 0a 0b 0c |.............|0000000d
-s 从偏移量开始输出
输入:
hexdump -n 13 -C -s 30 test
输出:
0000001e 1e 1f 20 21 22 23 24 25 26 27 28 29 2a |.. !"#$%&'()*|0000002b
hexdump高级用法:
-e 指定格式字符串,格式字符串包含在一对单引号中,格式字符串形如:'a/b "format1" "format2"'
每个格式字符串由三部分组成,每个由空格分隔,
第一个形如a/b,b表示对每b个输入字节应用format1格式,a表示对每a个输入字节应用format2格式,一般a>b,且b只能为1,2,4,另外a可以省略,省略则a=1。
format1和format2中可以使用类似printf的格式字符串,
如:%02d:两位十进制
%03x:三位十六进制
%02o:两位八进制
%c:单个字符等
还有一些特殊的用法:
%_ad:标记下一个输出字节的序号,用十进制表示%_ax:标记下一个输出字节的序号,用十六进制表示
%_ao:标记下一个输出字节的序号,用八进制表示
%_p:对不能以常规字符显示的用.代替同一行如果要显示多个格式字符串,则可以跟多个-e选项
About Me
.............................................................................................................................................
● 本文作者:小麦苗,部分内容整理自网络,若有侵权请联系小麦苗删除
● 本文在itpub(http://blog.itpub.net/26736162/abstract/1/)、博客园(http://www.cnblogs.com/lhrbest)和个人微信公众号(xiaomaimiaolhr)上有同步更新
● 本文itpub地址:http://blog.itpub.net/26736162/abstract/1/
● 本文博客园地址:http://www.cnblogs.com/lhrbest
● 本文pdf版、个人简介及小麦苗云盘地址:http://blog.itpub.net/26736162/viewspace-1624453/
● 数据库笔试面试题库及解答:http://blog.itpub.net/26736162/viewspace-2134706/
● DBA宝典今日头条号地址:http://www.toutiao.com/c/user/6401772890/#mid=1564638659405826
.............................................................................................................................................
● QQ群号:230161599(满)、618766405
● 微信群:可加我微信,我拉大家进群,非诚勿扰
● 联系我请加QQ好友(646634621),注明添加缘由
● 于 2018-01-01 06:00 ~ 2018-01-31 24:00 在魔都完成
● 文章内容来源于小麦苗的学习笔记,部分整理自网络,若有侵权或不当之处还请谅解
● 版权所有,欢迎分享本文,转载请保留出处
.............................................................................................................................................
● 小麦苗的微店:https://weidian.com/s/793741433?wfr=c&ifr=shopdetail
● 小麦苗出版的数据库类丛书:http://blog.itpub.net/26736162/viewspace-2142121/
● 好消息:小麦苗OCP、OCM开班啦,详情请点击:http://blog.itpub.net/26736162/viewspace-2148098/
.............................................................................................................................................
使用微信客户端扫描下面的二维码来关注小麦苗的微信公众号(xiaomaimiaolhr)及QQ群(DBA宝典),学习最实用的数据库技术。

小麦苗的微信公众号 小麦苗的DBA宝典QQ群2 《DBA笔试面试宝典》读者群 小麦苗的微店
.............................................................................................................................................






Linux命令学习总结:hexdump
2015-12-26 10:44 by 潇湘隐者, 7741 阅读, 0 评论, 收藏, 编辑命令简介:
hexdump是Linux下的一个二进制文件查看工具,它可以将二进制文件转换为ASCII、八进制、十进制、十六进制格式进行查看。
指令所在路径:/usr/bin/hexdump
命令语法:
hexdump: [-bcCdovx] [-e fmt] [-f fmt_file] [-n length] [-s skip] [file ...]
命令参数:
此命令参数是Red Hat Enterprise Linux Server release 5.7下hexdump命令参数,不同版本Linux的hexdump命令参数有可能不同。
|
参数 |
长参数 |
描叙 |
|
-b |
|
每个字节显示为8进制。一行共16个字节,一行开始以十六进制显示偏移值 |
|
-c |
|
每个字节显示为ASCII字符 |
|
-C |
|
每个字节显示为16进制和相应的ASCII字符 |
|
-d |
|
两个字节显示为10进制 |
|
-e |
|
格式化输出 |
|
-f |
|
Specify a file that contains one or more newline separated format strings. Empty lines and lines whose first non-blank character is a hash mark (#) are ignored. |
|
-n |
|
只格式前n个长度的字符 |
|
-o |
|
两个字节显示为8进制 |
|
-s |
|
从偏移量开始输出 |
|
-v |
|
The -v option causes hexdump to display all input data. Without the -v option, any number of groups of output lines, which would be identical to the immediately preceding group of output lines |
|
-x |
|
双字节十六进制显示 |
使用示例:
1: 查看hexdmp命令的帮助信息
[root@DB-Server ~]# man hexdump
2: 以8进制显示文件里面的字符。
[root@DB-Server ~]# cat >test.txt
ABCDEF
GHIJKM
123456
[root@DB-Server ~]# hexdump -b test.txt
0000000 101 102 103 104 105 106 012 107 110 111 112 113 115 012 061 062
0000010 063 064 065 066 012
0000015
注意:一行共16个字节,一行开始以十六进制显示偏移值(如下所示,第一行字符串只显示到D,第十六个字节,后面的F12*DFDF换行显示)
[root@DB-Server ~]# cat >test.txt
ABCDEFGHIJKLMNODF12*DFDF
[2]+ Stopped cat > test.txt
You have new mail in /var/spool/mail/root
[root@DB-Server ~]# hexdump -b test.txt
0000000 101 102 103 104 105 106 107 110 111 112 113 114 115 116 117 104
0000010 106 061 062 052 104 106 104 106 012
0000019
[root@DB-Server ~]# hexdump -c test.txt
0000000 A B C D E F G H I J K L M N O D
0000010 F 1 2 * D F D F /n
0000019

3:以ASCII字符显示文件中字符
[root@DB-Server ~]# hexdump -c test.txt
0000000 A B C D E F G H I J K L M N O D
0000010 F 1 2 * D F D F /n
0000019
hexdump 以ASCII字符显示时,可以输出换行符,这个功能可以用来检查文件是Linux的换行符格式还是Widows格式换行符。如下所示

4:以16进制和相应的ASCII字符显示文件里的字符
[root@DB-Server ~]# hexdump -C test.txt
00000000 41 42 43 44 45 46 47 48 49 4a 4b 4c 4d 4e 4f 44 |ABCDEFGHIJKLMNOD|
00000010 46 31 32 2a 44 46 44 46 0a |F12*DFDF.|
00000019
5:只格式文件中前n个字符
[root@DB-Server ~]# hexdump -C -n 5 test.txt
00000000 41 42 43 44 45 |ABCDE|
00000005
6:以偏移量开始格式输出。如下所示指定参数-s 5 ,前面的ABCDE字符没有了。
[root@DB-Server ~]# hexdump -C test.txt
00000000 41 42 43 44 45 46 47 48 49 4a 4b 4c 4d 4e 4f 44 |ABCDEFGHIJKLMNOD|
00000010 46 31 32 2a 44 46 44 46 0a |F12*DFDF.|
00000019
[root@DB-Server ~]# hexdump -C -s 5 test.txt
00000005 46 47 48 49 4a 4b 4c 4d 4e 4f 44 46 31 32 2a 44 |FGHIJKLMNODF12*D|
00000015 46 44 46 0a |FDF.|
00000019
作者:潇湘隐者
我使用过的Linux命令之hexdump - ”十六“进制查看器
本文链接:http://codingstandards.iteye.com/blog/805778 (转载请注明出处)
用途说明
hexdump命令一般用来查看”二进制“文件的十六进制编码,但实际上它的用途不止如此,手册页上的说法是“ascii, decimal, hexadecimal, octal dump“,这也就是本文标题为什么要将”十六“给引起来的原因,而且它能查看任何文件,而不只限于二进制文件了。另外还有xxd和od也可以做类似的事情,但是我从未用过。在程序输出二进制格式的文件时,常用hexdump来检查输出是否正确。当然也可以使用Windows上的UltraEdit32之类的工具查看文件的十六进制编码,但Linux上有现成的工具,何不拿来用呢。
常用参数
如果要看到较理想的结果,使用-C参数,显示结果分为三列(文件偏移量、字节的十六进制、ASCII字符)。
格式:hexdump -C binfile
一般文件都不是太小,最好用less来配合一下。
格式:hexdump -C binfile | less
使用示例
示例一 比较各种参数的输出结果
[root@new55 ~]# echo /etc/passwd | hexdump
0000000 652f 6374 702f 7361 7773 0a64
000000c
[root@new55 ~]# echo /etc/passwd | od -x
0000000 652f 6374 702f 7361 7773 0a64
0000014
[root@new55 ~]# echo /etc/passwd | xxd
0000000: 2f65 7463 2f70 6173 7377 640a /etc/passwd.
[root@new55 ~]# echo /etc/passwd | hexdump -C <== 规范的十六进制和ASCII码显示(Canonical hex+ASCII display )
00000000 2f 65 74 63 2f 70 61 73 73 77 64 0a |/etc/passwd.|
0000000c
[root@new55 ~]# echo /etc/passwd | hexdump -b <== 单字节八进制显示(One-byte octal display)
0000000 057 145 164 143 057 160 141 163 163 167 144 012
000000c
[root@new55 ~]# echo /etc/passwd | hexdump -c <== 单字节字符显示(One-byte character display)
0000000 / e t c / p a s s w d /n
000000c
[root@new55 ~]# echo /etc/passwd | hexdump -d <== 双字节十进制显示(Two-byte decimal display)
0000000 25903 25460 28719 29537 30579 02660
000000c
[root@new55 ~]# echo /etc/passwd | hexdump -o <== 双字节八进制显示(Two-byte octal display)
0000000 062457 061564 070057 071541 073563 005144
000000c
[root@new55 ~]# echo /etc/passwd | hexdump -x <== 双字节十六进制显示(Two-byte hexadecimal display)
0000000 652f 6374 702f 7361 7773 0a64
000000c
[root@new55 ~]# echo /etc/passwd | hexdump -v
0000000 652f 6374 702f 7361 7773 0a64
000000c
比较来比较去,还是hexdump -C的显示效果更好些。
示例二 确认文本文件的格式
文本文件在不同操作系统上的行结束标志是不一样的,经常会碰到由此带来的问题。比如Linux的许多命令不能很好的处理DOS格式的文本文件。Windows/DOS下的文本文件是以/r/n作为行结束的,而Linux/Unix下的文本文件是以/n作为行结束的。
[root@new55 ~]# cat test.bc
123*321
123/321
scale=4;123/321
[root@new55 ~]# hexdump -C test.bc
00000000 31 32 33 2a 33 32 31 0a 31 32 33 2f 33 32 31 0a |123*321.123/321.|
00000010 73 63 61 6c 65 3d 34 3b 31 32 33 2f 33 32 31 0a |scale=4;123/321.|
00000020 0a |.|
00000021
[root@new55 ~]#
注:常见的ASCII字符的十六进制表示
/r 0D
/n 0A
/t 09
DOS/Windows的换行符 /r/n 即十六进制表示 0D 0A
Linux/Unix的换行符 /n 即十六进制表示 0A
示例三 查看wav文件
有些IVR系统需要8K赫兹8比特的语音文件,可以使用hexdump看一下具体字节编码。
[root@web186 root]# ls -l tmp.wav
-rw-r--r-- 1 root root 32381 2010-04-19 tmp.wav
[root@web186 root]# file tmp.wav
tmp.wav: RIFF (little-endian) data, WAVE audio, ITU G.711 a-law, mono 8000 Hz
[root@web186 root]# hexdump -C tmp.wav | less
00000000 52 49 46 46 75 7e 00 00 57 41 56 45 66 6d 74 20 |RIFFu~..WAVEfmt |
00000000 52 49 46 46 75 7e 00 00 57 41 56 45 66 6d 74 20 |RIFFu~..WAVEfmt |
00000010 12 00 00 00 06 00 01 00 40 1f 00 00 40 1f 00 00 |........@...@...|
00000020 01 00 08 00 00 00 66 61 63 74 04 00 00 00 43 7e |......fact....C~|
00000030 00 00 64 61 74 61 43 7e 00 00 d5 d5 d5 d5 d5 d5 |..dataC~........|
00000040 d5 d5 d5 d5 d5 d5 d5 d5 d5 d5 d5 d5 d5 d5 d5 d5 |................|
*
000000a0 d5 d5 d5 d5 d5 d5 d5 d5 d5 55 d5 55 d5 d5 55 d5 |.........U.U..U.|
000000b0 55 d5 d5 55 d5 55 d5 d5 55 d5 55 55 55 55 55 55 |U..U.U..U.UUUUUU|
000000c0 55 55 55 55 55 55 55 d5 d5 d5 d5 d5 d5 d5 d5 d5 |UUUUUUU.........|
000000d0 d5 55 55 55 55 55 55 55 55 55 55 55 55 55 55 55 |.UUUUUUUUUUUUUUU|
000000e0 55 55 55 55 55 55 55 55 55 d5 d5 d5 d5 d5 d5 d5 |UUUUUUUUU.......|
000000f0 d5 d5 d5 d5 55 55 55 55 55 55 55 55 55 55 55 55 |....UUUUUUUUUUUU|
00000100 55 55 55 55 55 55 55 55 55 55 55 55 d5 d5 d5 d5 |UUUUUUUUUUUU....|
00000110 d5 d5 d5 d5 d5 d5 55 55 55 55 55 55 55 55 55 55 |......UUUUUUUUUU|
00000120 55 55 55 55 55 55 55 55 55 55 55 55 55 55 d5 d5 |UUUUUUUUUUUUUU..|
00000130 d5 d5 d5 d5 d5 d5 d5 d5 d5 55 55 55 55 55 55 55 |.........UUUUUUU|
00000140 55 55 d5 55 55 55 55 55 55 55 55 55 55 55 55 55 |UU.UUUUUUUUUUUUU|
00000150 55 d5 d5 d5 d5 d5 d5 d5 d5 d5 d5 55 55 55 55 55 |U..........UUUUU|
00000160 55 55 55 55 55 55 55 55 55 55 55 55 55 55 55 55 |UUUUUUUUUUUUUUUU|
00000170 55 55 55 55 d5 d5 d5 d5 d5 d5 d5 d5 d5 55 d5 55 |UUUU.........U.U|
00000180 55 55 55 55 55 55 55 55 55 55 55 55 55 55 55 55 |UUUUUUUUUUUUUUUU|
00000190 55 55 55 55 55 55 55 d5 d5 d5 d5 d5 d5 d5 d5 55 |UUUUUUU........U|
000001a0 55 55 55 55 55 55 55 d5 d5 55 55 55 55 55 55 55 |UUUUUUU..UUUUUUU|
000001b0 55 55 55 55 55 55 55 d5 55 55 d5 55 55 55 55 55 |UUUUUUU.UU.UUUUU|
000001c0 55 55 d5 55 d5 d5 55 d5 55 55 55 55 55 55 55 55 |UU.U..U.UUUUUUUU|
000001d0 55 55 55 55 55 55 55 55 55 55 55 55 55 55 55 d5 |UUUUUUUUUUUUUUU.|
000001e0 55 d5 d5 d5 d5 55 55 55 55 55 55 55 55 55 55 55 |U....UUUUUUUUUUU|
000001f0 55 55 55 55 55 55 55 55 55 55 55 55 d5 55 55 d5 |UUUUUUUUUUUU.UU.|
00000200 55 55 55 55 55 55 55 55 55 d5 d5 d5 d5 d5 55 55 |UUUUUUUUU.....UU|
00000210 55 55 55 55 55 55 55 55 55 55 55 55 55 55 55 d5 |UUUUUUUUUUUUUUU.|
00000220 55 55 d5 55 d5 55 55 d5 55 d5 55 55 d5 55 d5 d5 |UU.U.UU.U.UU.U..|
00000230 d5 d5 d5 d5 d5 d5 d5 d5 d5 d5 d5 d5 d5 d5 d5 d5 |................|
*
00000ba0 d5 d5 d5 d5 d5 d5 d5 d5 d5 d5 d5 55 55 d5 55 d5 |...........UU.U.|
00000bb0 55 55 d5 55 d5 55 d5 d5 55 d5 55 55 55 55 55 55 |UU.U.U..U.UUUUUU|
00000bc0 55 55 55 55 55 55 55 55 55 d5 d5 55 55 55 55 55 |UUUUUUUUU..UUUUU|
00000bd0 55 55 55 55 55 55 55 d5 55 55 55 55 55 55 d5 55 |UUUUUUU.UUUUUU.U|
00000be0 55 55 55 55 55 55 55 55 55 55 55 d5 55 55 55 55 |UUUUUUUUUUU.UUUU|
00000bf0 55 55 55 55 55 55 55 55 d5 d5 55 55 55 55 55 d5 |UUUUUUUU..UUUUU.|
00000c00 d5 55 55 55 55 d5 d5 d5 55 55 55 55 55 d5 d5 55 |.UUUU...UUUUU..U|
:q
[root@web186 root]#
问题思考
相关资料
【1】kindle's blog hexdump,od,xxd
【2】杭州美创科技技术资源中心 使用hexdump 查看二进制文件
返回 我使用过的Linux命令系列总目录
使用hexdump工具追踪EXT4文件系统中的一个文件
昨天追踪EXT4文件系统的过程中出了点问题,就是找不到文件,于是试了一下追踪FAT32文件系统的,成功之后有了点信心,今天继续嗑EXT4文件系统,终于找到啦,记录一下。
- 操作系统:linux(centos 6.5)
- 文件系统:EXT4
- 工具:hexdump,windows自带计算器
- 参考资源:《数据重现-文件系统原理精解与数据恢复最佳实践》(马林 著)
《基于EXT4文件系统的数据恢复方法研究》(徐国天)
题为《Ext4文件系统架构分析》的系列博客
题为《 深入理解ext4(一)----extent区段》的博客
题为《ext4的Extent解析》的博客
题为《ext4_ext_find_extent解析》的博客
EXT4文件系统架构(非原创):

补充说明:EXT4文件系统中只有0号块组的超级块和块组描述符表的位置是固定的,其他都不固定。其中,超级块总是开始于偏移位置1024(字节),占据1024个字节,块组描述符表紧随超级块后面,占用的大小是不定。
步骤:
1、查看文件系统基本情况,新建子目录和文件

可以看到挂载在/boot目录下的文件系统类型是EXT4,因此在改目录下新建子目录及文件:

文件内容为:“This test is belong to Boot folder!”文件基本信息如下:

2、查看超级块,找到0号块组起始块号、块大小、每块组所含块数、每块组i节点数、第一个非保留i节点、每个i节点大小。
命令:hexdump -s 1024 -n 1024 -C /dev/sda1
查看结果:

首先可以看到0x38-0x39是EXT系列文件系统的签名标志:“53 ef”
0x14-0x17是0号块组起始块号:0x01,说明超级块前面有一个块为保留块,用来存储引导程序。
0x18-0x1b是块大小:0x00,这里的值指的是将1024字节左移的位数,移动0位也就是1024字节,移动一位相当于乘以2,就是2048字节。
0x20-0x23是每块组所含块数:0x2000(十进制8192)
0x28-0x2b是每块组所含i节点数:0x07f0(十进制2032)
0x54-0x57是第一个非保留i节点号:0x0b(11),一般为lost+found目录
0x58-0x59是每个i节点结构的大小:0x80(十进制128),也就是每个i节点表项占用128个字节。
3、查看块组描述符表,找到块位图块、i节点位图块、i节点表起始块号、块组目录数。
命令:hexdump -s 2048 -n 1024 -C /dev/sda1
查看结果:
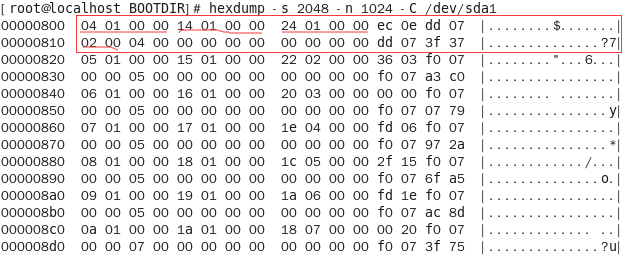
块组描述符表中每个块组使用32个字节来描述,因此第一个32字节描述的就是0号块组。
0x00-0x04是块位图块起始块号:0x0104
0x05-0x07是i节点位图块起始块号:0x0114
0x08-0x0b是i节点表起始块号:0x0124
0x10-0x11是该块组的目录数:0x02
这里获取的起始块号是逻辑块号(将文件系统所有的块从0开始递增编号),因此在计算偏移量时可以直接乘以每块字节数(0x400,也就是十进制的1024)
这里补充说明一下:EXT3文件系统的块位图块号、i节点位图块和i节点表起始块号是递增的,而这里他们三个之间却是相差一个常量:16。
因为这里使用了一个EXT4新引进的结构:Flexible 块组(flex_bg)
|
Flexible 块组 Flexible 块组的设计目的是组成更大的逻辑块组,尽量让大文件连续,将元数据聚集加快元数据载入。因此它的做法是将几个块组的块位图块,i节点位图块,i节点表块放在这个逻辑块组的第一个块组中,这样剩下的块组中就只存储了该块组的超级块和块组描述表。 上面的块组描述表中可以看出这个Flexible 块组是将16个块组合成了一个逻辑块组。 说起Flexible 块组就要提起元块组(Media Block Group),因为他和Flexible 块组是“有你没我”的关系。Flexible 块组是移动了块位图块、i节点位图块、i节点表块,元块组是减少了块组描述符表的备份,原本块组描述符表和超级块一起备份在块组号为0或者3、5、7的幂的块组,元块组是只在一个元块组的第一、二个块组和最后一个块组中备份块组描述符表,增加元块组存储数据的空间。 |
3、从根目录中找到子目录
第一步我们提到了第一个非保留i节点号为11,那么前面的10个保留i节点的作用是什么呢(i节点号从1开始编号),这里只说明2号节点是存储的是根目录i节点号,因此我们读取i节点表的2号表项值就可以找到根目录所在块号了。
计算i节点表项的偏移量涉及到了块组描述符表中的i节点表起始块号:0x0124。
某i节点表项起始字节=i节点起始块号*每块所占字节数+(该i节点号-1)*每个i节点表项所占字节数
0x0124*0x400+(0x02-0x01)*0x80=0x49080
下面就可以读取根目录i节点表项值了。
命令:hexdump -s 0x49080 -n 128 -C /dev/sda1
查看结果:

0xa8-0xd7是12个直接块指针,其中四个字节为一个单位,表示一个块号。
(这里要解释的是:EXt4文件系统将12个直接块指针、1个一级间接块指针、1个二级间接块指针、1个三级间接块指针,一共60个字节用extent结构来替换,但前提是偏移0xa0-0xa3处的标志位置为“00 00 08 00”,而这里全为0,则证明没有使用extent结构,因此依旧按照块指针形式查找根目录)
图中可以看出根目录只占用了一个块,块号为:0x1104
根目录的起始偏移字节为=根目录所在块号*每块所占字节数
则根目录的起始偏移字节:0x1104*0x400=0x441000
使用命令:hexdump -s 0x441000 -n 1024 -C /dev/sda1 查看根目录内容:
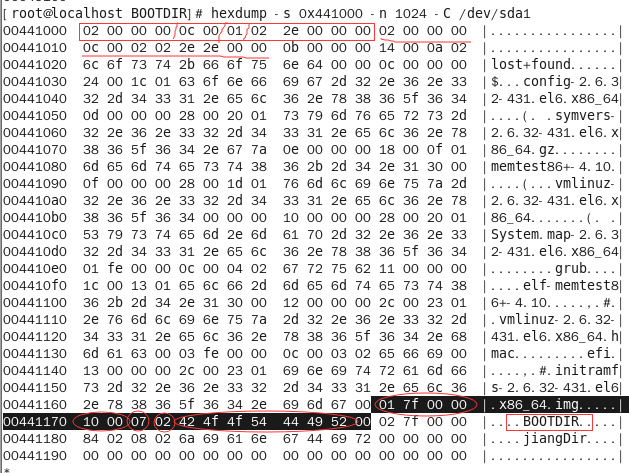
查看/boot目录下的文件:

可以看到两者的内容是相符的,说明我们找的没有错。根目录中BOOTDIR的目录项用黑色底纹标注。
0x6c-0x6f是该文件内容所在i节点号:0x7f01
0x70-0x71是本目录项长度:0x10(16字节)
0x72是本目录项名字长度0x07(7个字节)
0x73是本文件类型:0x02(表示目录)
0x74开始是文件名的ASCCI码:“42 4f 4f 54 44 49 52 00”
在这一步中与FAT32文件系统的区别有两个:
一是怎么寻找根目录。FAT32中根目录在数据区的开头,因此我们可以直接去数据区读取;而EXT4文件系统中,我们需要通过2号i节点表找到根目录所在的块号,才能看到根目录内容,这里就可以看出EXT4文件系统将目录也看作文件了,因为他的读取方式和普通文件是一样的,只不过普通文件需要从目录中得到i节点号,而根目录是一开始就定好了i节点号。
二是目录的大小。FAT32中目录的大小是固定的(短文件名目录占32字节,长文件名目录占多个32字节),所以当文件名过长时,使用了长文件名机制来解决,而EXT4文件系统的目录项大小是在目录项中灵活定的。比如这一步中我们查看到的根目录结果中,开始的12个字节是本目录项,紧接着12个字节是根目录项,而我们要找的目标目录项的长度是16个字节,其中说明部分(i节点号,本目录项长度字节数,名字长度,文件类型)占用都是一样的,差就差在文件名部分。但我们也看到文件名后面总有“00”补齐,这是因为目录项的长度总要是4的倍数,因此不够时会用0补齐。
4、从i节点表中找到子目录所在块号
第三步中我们找到指向子目录的i节点号为0x7f01,也是逻辑i节点号,因此我们要先找到0x7f01在哪个块组中:
某i节点所在块组=该i节点号/每块组i节点个数
0x7f01/0x7f0=0x10(十进制16)
某i节点所在i节点表号=该i节点号%每块组i节点个数
0x7f01%0x7f0=0x01
因此0x7f01在16号块组的i节点表中,在改i节点表的1号表项中。
接下来我们要从块组描述符表中找到16号块组的i节点表起始块号,以便找到子目录所在块号。
某块组在块组描述符表中偏移字节=块组描述符表起始字节+块组号*每块组描述符表项字节数
2048+16*32=2560字节
我们读取2560偏移字节开始的32字节:

可以看到:0x08-0x0b为i节点表起始块号:0x020021
读取16号块组i节点表的1号i节点表项值:

这里需要重点注意:0x20-0x23处的标志内容为“00 00 08 00”也就是0x080000,表示使用了extent结构,因此这里文件子目录的搜索就需要按照extent结构来读取0x28-0x63这60个字节的内容。
有个疑问:EXT4文件系统什么时候使用extent结构,查看0号块组的10个保留i节点时,看到只有8号也就是日志节点启用了extent结构,其他都没有使用,而其他块组中似乎是都默认启用extent结构,但也发现了例外,因此不能确定EXT4关于启用extent结构的规定,后续需要注意!
|
下面介绍一下extent的结构,内容有参考。 每个extent结构占用12个字节,所以每个i节点表项中可以有60/12=5个extent结构,这其中第一个extent作为extent头(extent header是一个B+树的描述头),剩下的4个是extent体(extent body,由于extent树中的节点有两种:索引节点和叶子节点,因此当节点为索引节点时(可以从extent header中区分索引节点和叶子节点)extent body存储的是下一级extent树节点信息,当节点为叶子节点时extent body 中存储的是数据块块号信息) extent树结构
extent数据结构 extent header
这里要说明的是:魔数是一个校验值,只有当校验结果是0xf30a时B+树的块才正确 节点在extent树中的深度是从叶子节点算起,因此根节点的深度是最深的(看到有人说根节点的最大深度不超过5),当深度为0时表明是叶子节点,那么这个节点就是数据节点,他后面的extent body就是指向的数据块,存储数据块号;当深度大于0,后面的extent body表示索引节点。 extent body 当为索引节点时
当为叶子节点时
补充说明:当extent body表示索引节点时最后最后两个节点冗余是为了迁就叶子节点。 |
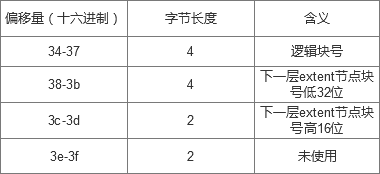
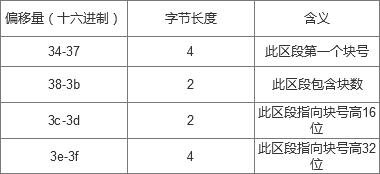
从0x28-0x63是extent结构。
extent头中说明的信息有:本区段有一个extent body,最大区段个数为4,本段在extent树中深度为0,是叶子节点。
后面紧着的12个字节是extent body说明的信息有:本区段的第一个块号是0,本区段含有一个块,本区段指向的数据块块号为0x021002。
该块的偏移字节:0x8400800
5、从子目录对应的i节点号得到目标文件块号
查看结果第4步中子目录块内容:

加黑色底纹的是本目录(“.”)和根目录(“..”)接下来就是目标文件:BOOTTEXT.txt,他的i节点号为:0x7f04
查看i节点表,找到目标文件的块号:
该i节点表项的偏移字节为:0x020021*0x400+(0x7f04%0x7f0-1)*0x80=0x8008580
读取该偏移字节处开始的128字节内容:

同样目标文件的i节点表项也启用了extent结构,按照与第4步同样的方法分析,得带目标文件所在块号0x024005(偏移字节为0x9001400)。
接下来读取该块内容:

找到啦!和第一步中使用cat命令查看的文件内容一致。
hexdump是Linux下的一个二进制文件查看工具,可以将二进制文件转换为ASCII、10进制、16进制或8进制进行查看。
首先我们准备一个测试用的文件test,十六进制如下:
00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F10 11 12 13 14 15 16 17 18 19 1A 1B 1C 1D 1E 1F20 21 22 23 24 25 26 27 28 29 2A 2B 2C 2D 2E 2F
选项:
-n length
只格式化输入文件的前length个字节
-C
输出十六进制和对应字符
输入:
hexdump -n 13 -C test
输出:
00000000 00 01 02 03 04 05 06 07 08 09 0a 0b 0c |.............|0000000d
-s 从偏移量开始输出
输入:
hexdump -n 13 -C -s 30 test
输出:
0000001e 1e 1f 20 21 22 23 24 25 26 27 28 29 2a |.. !"#$%&'()*|0000002b
hexdump高级用法:
-e 指定格式字符串,格式字符串包含在一对单引号中,格式字符串形如:'a/b "format1" "format2"'
每个格式字符串由三部分组成,每个由空格分隔,
第一个形如a/b,b表示对每b个输入字节应用format1格式,a表示对每a个输入字节应用format2格式,一般a>b,且b只能为1,2,4,另外a可以省略,省略则a=1。
format1和format2中可以使用类似printf的格式字符串,
如:%02d:两位十进制
%03x:三位十六进制
%02o:两位八进制
%c:单个字符等
还有一些特殊的用法:
%_ad:标记下一个输出字节的序号,用十进制表示%_ax:标记下一个输出字节的序号,用十六进制表示
%_ao:标记下一个输出字节的序号,用八进制表示
%_p:对不能以常规字符显示的用.代替同一行如果要显示多个格式字符串,则可以跟多个-e选项
正文到此结束
- 本文标签: DDL windows 2015 find IDE 操作系统 备份 博客 https centos 文件系统 解析 linux src tab 文章 科技 数据 参数 root 删除 ip IO 标题 HTML QQ群 aix Enterprise tar UI 二维码 web http mail ORM cat 空间 同步 unix ACE 系统架构 list 目录 W3C db 微信公众号 数据库 Menu 总结 测试 Word CDN 安装 id key 云
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
出现OpenClaw "device signature expired"。the Gateway rejects if Math.abs(Date.now() - signedAt) > 10 * 60 * 1000 (10 minutes)
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

