使用Prometheus监控的Spring Boot程序
本文将会带领读者,在Spring Boot/Spring Cloud应用中添加对Prometheus监控的支持,以实现对应用性能以及业务相关监控指标的数据采集。同时也会介绍Prometheus中不同的Metrics类型的使用场景。
添加Prometheus Java Client依赖
这里使用0.0.24的版本,在之前的版本中Spring Boot暴露的监控地址,无法正确的处理Prometheus Server的请求,详情: https://github.com/prometheus/client_java/issues/265
# build.gradle
...
dependencies {
...
compile 'io.prometheus:simpleclient:0.0.24'
compile "io.prometheus:simpleclient_spring_boot:0.0.24"
compile "io.prometheus:simpleclient_hotspot:0.0.24"
}
...
启用Prometheus Metrics Endpoint
添加注解@EnablePrometheusEndpoint启用Prometheus Endpoint,这里同时使用了simpleclient_hotspot中提供的DefaultExporter该Exporter会在metrics endpoint中放回当前应用JVM的相关信息
@SpringBootApplication
@EnablePrometheusEndpoint
public class SpringApplication implements CommandLineRunner {
public static void main(String[] args) {
SpringApplication.run(GatewayApplication.class, args);
}
@Override
public void run(String... strings) throws Exception {
DefaultExports.initialize();
}
}
默认情况下Prometheus暴露的metrics endpoint为 /prometheus,可以通过endpoint配置进行修改
endpoints:
prometheus:
id: metrics
metrics:
id: springmetrics
sensitive: false
enabled: true
启动应用程序访问 http://localhost:8080/metrics 可以看到以下输出:
# HELP jvm_gc_collection_seconds Time spent in a given JVM garbage collector in seconds.
# TYPE jvm_gc_collection_seconds summary
jvm_gc_collection_seconds_count{gc="PS Scavenge",} 11.0
jvm_gc_collection_seconds_sum{gc="PS Scavenge",} 0.18
jvm_gc_collection_seconds_count{gc="PS MarkSweep",} 2.0
jvm_gc_collection_seconds_sum{gc="PS MarkSweep",} 0.121
# HELP jvm_classes_loaded The number of classes that are currently loaded in the JVM
# TYPE jvm_classes_loaded gauge
jvm_classes_loaded 8376.0
# HELP jvm_classes_loaded_total The total number of classes that have been loaded since the JVM has started execution
# TYPE jvm_classes_loaded_total counter
...
添加拦截器,为监控埋点做准备
除了获取应用JVM相关的状态以外,我们还可能需要添加一些自定义的监控Metrics实现对系统性能,以及业务状态进行采集,以提供日后优化的相关支撑数据。首先我们使用拦截器处理对应用的所有请求。
继承WebMvcConfigurerAdapter类,复写addInterceptors方法,对所有请求/**添加拦截器
@SpringBootApplication
@EnablePrometheusEndpoint
public class SpringApplication extends WebMvcConfigurerAdapter implements CommandLineRunner {
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new PrometheusMetricsInterceptor()).addPathPatterns("/**");
}
}
PrometheusMetricsInterceptor集成HandlerInterceptorAdapter,通过复写父方法,实现对请求处理前/处理完成的处理。
public class PrometheusMetricsInterceptor extends HandlerInterceptorAdapter {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
return super.preHandle(request, response, handler);
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
super.afterCompletion(request, response, handler, ex);
}
}
自定义Metrics
Prometheus提供了4中不同的Metrics类型:Counter,Gauge,Histogram,Summary
Counter:只增不减的计数器
计数器可以用于记录只会增加不会减少的指标类型,比如记录应用请求的总量(http_requests_total),cpu使用时间(process_cpu_seconds_total)等。
对于Counter类型的指标,只包含一个inc()方法,用于计数器+1
一般而言,Counter类型的metrics指标在命名中我们使用_total结束。
public class PrometheusMetricsInterceptor extends HandlerInterceptorAdapter {
static final Counter requestCounter = Counter.build()
.name("io_namespace_http_requests_total").labelNames("path", "method", "code")
.help("Total requests.").register();
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
String requestURI = request.getRequestURI();
String method = request.getMethod();
int status = response.getStatus();
requestCounter.labels(requestURI, method, String.valueOf(status)).inc();
super.afterCompletion(request, response, handler, ex);
}
}
使用Counter.build()创建Counter metrics,name()方法,用于指定该指标的名称 labelNames()方法,用于声明该metrics拥有的维度label。在preHandle方法中,我们获取当前请求的,RequesPath,Method以及状态码。并且调用inc()方法,在每次请求发生时计数+1。
Counter.build()…register(),会像Collector中注册该指标,并且当访问/metrics地址时,返回该指标的状态。
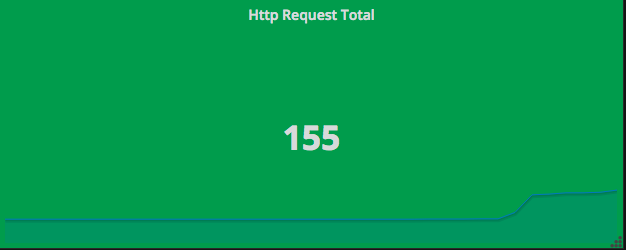
通过指标io_namespace_http_requests_total我们可以:
- 查询应用的请求总量
# PromQL sum(io_namespace_http_requests_total)
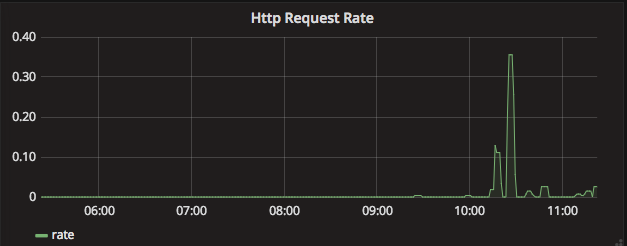
- 查询每秒Http请求量
# PromQL sum(rate(io_wise2c_gateway_requests_total[5m]))
- 查询当前应用请求量Top N的URI
# PromQL topk(10, sum(io_namespace_http_requests_total) by (path))
Gauge: 可增可减的仪表盘
对于这类可增可减的指标,可以用于反应应用的 当前状态 ,例如在监控主机时,主机当前空闲的内容大小(node_memory_MemFree),可用内存大小(node_memory_MemAvailable)。或者容器当前的cpu使用率,内存使用率。
对于Gauge指标的对象则包含两个主要的方法inc()以及dec(),用户添加或者减少计数。在这里我们使用Gauge记录当前正在处理的Http请求数量。
public class PrometheusMetricsInterceptor extends HandlerInterceptorAdapter {
...省略的代码
static final Gauge inprogressRequests = Gauge.build()
.name("io_namespace_http_inprogress_requests").labelNames("path", "method", "code")
.help("Inprogress requests.").register();
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
...省略的代码
// 计数器+1
inprogressRequests.labels(requestURI, method, String.valueOf(status)).inc();
return super.preHandle(request, response, handler);
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
...省略的代码
// 计数器-1
inprogressRequests.labels(requestURI, method, String.valueOf(status)).dec();
super.afterCompletion(request, response, handler, ex);
}
}
通过指标io_namespace_http_inprogress_requests我们可以直接查询应用当前正在处理中的Http请求数量:
# PromQL
io_namespace_http_inprogress_requests{}
Histogram:用于统计分布情况的柱状图
主要用于在指定分布范围内(Buckets)记录大小(如http request bytes)或者事件发生的次数。
以请求响应时间requests_latency_seconds为例,假如我们需要记录http请求响应时间符合在分布范围{.005, .01, .025, .05, .075, .1, .25, .5, .75, 1, 2.5, 5, 7.5, 10}中的次数时。
public class PrometheusMetricsInterceptor extends HandlerInterceptorAdapter {
static final Histogram requestLatencyHistogram = Histogram.build().labelNames("path", "method", "code")
.name("io_namespace_http_requests_latency_seconds_histogram").help("Request latency in seconds.")
.register();
private Histogram.Timer histogramRequestTimer;
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
...省略的代码
histogramRequestTimer = requestLatencyHistogram.labels(requestURI, method, String.valueOf(status)).startTimer();
...省略的代码
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
...省略的代码
histogramRequestTimer.observeDuration();
...省略的代码
}
}
使用Histogram构造器可以创建Histogram监控指标。默认的buckets范围为{.005, .01, .025, .05, .075, .1, .25, .5, .75, 1, 2.5, 5, 7.5, 10}。如何需要覆盖默认的buckets,可以使用.buckets(double… buckets)覆盖。
Histogram会自动创建3个指标,分别为:
- 事件发生总次数: basename_count
# 实际含义: 当前一共发生了2次http请求
io_namespace_http_requests_latency_seconds_histogram_count{path="/",method="GET",code="200",} 2.0
- 所有事件产生值的大小的总和: basename_sum
# 实际含义: 发生的2次http请求总的响应时间为13.107670803000001 秒
io_namespace_http_requests_latency_seconds_histogram_sum{path="/",method="GET",code="200",} 13.107670803000001
- 事件产生的值分布在bucket中的次数: basename_bucket{le=”上包含”}
# 在总共2次请求当中。http请求响应时间 <=0.005 秒 的请求次数为0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.005",} 0.0
# 在总共2次请求当中。http请求响应时间 <=0.01 秒 的请求次数为0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.01",} 0.0
# 在总共2次请求当中。http请求响应时间 <=0.025 秒 的请求次数为0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.025",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.05",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.075",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.1",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.25",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.5",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.75",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="1.0",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="2.5",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="5.0",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="7.5",} 2.0
# 在总共2次请求当中。http请求响应时间 <=10 秒 的请求次数为0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="10.0",} 2.0
# 在总共2次请求当中。http请求响应时间 10 秒 的请求次数为0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="+Inf",} 2.0
Summary
Summary和Histogram非常类型相似,都可以统计事件发生的次数或者发小,以及其分布情况。
public class PrometheusMetricsInterceptor extends HandlerInterceptorAdapter {
static final Summary requestLatency = Summary.build()
.name("io_namespace_http_requests_latency_seconds_summary")
.quantile(0.5, 0.05)
.quantile(0.9, 0.01)
.labelNames("path", "method", "code")
.help("Request latency in seconds.").register();
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
...省略的代码
requestTimer = requestLatency.labels(requestURI, method, String.valueOf(status)).startTimer();
...省略的代码
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
...省略的代码
requestTimer.observeDuration();
...省略的代码
}
}
使用Summary指标,会自动创建多个时间序列:
- 事件发生总的次数
# 含义:当前http请求发生总次数为12次
io_namespace_http_requests_latency_seconds_summary_count{path="/",method="GET",code="200",} 12.0
- 事件产生的值的总和
# 含义:这12次http请求的总响应时间为 51.029495508s
io_namespace_http_requests_latency_seconds_summary_sum{path="/",method="GET",code="200",} 51.029495508
- 事件产生的值的分布情况
# 含义:这12次http请求响应时间的中位数是3.052404983s
io_namespace_http_requests_latency_seconds_summary{path="/",method="GET",code="200",quantile="0.5",} 3.052404983
# 含义:这12次http请求响应时间的9分位数是8.003261666s
io_namespace_http_requests_latency_seconds_summary{path="/",method="GET",code="200",quantile="0.9",} 8.003261666
Summary VS Histogram
Summary和Histogram都提供了对于事件的计数_count以及值的汇总_sum。 因此使用_count,和_sum时间序列可以计算出相同的内容,例如http每秒的平均响应时间:rate(basename_sum[5m]) / rate(basename_count[5m])。
同时Summary和Histogram都可以计算和统计样本的分布情况,比如中位数,9分位数等等。其中 0.0<= 分位数Quantiles <= 1.0。
不同在于Histogram可以通过histogram_quantile函数在服务器端计算分位数。 而Sumamry的分位数则是直接在客户端进行定义。因此对于分位数的计算。 Summary在通过PromQL进行查询时有更好的性能表现,而Histogram则会消耗更多的资源。相对的对于客户端而言Histogram消耗的资源更少。
使用Collector暴露业务指标
除了在拦截器中使用Prometheus提供的Counter,Summary,Gauage等构造监控指标以外,我们还可以通过自定义的Collector实现对相关业务指标的暴露
@SpringBootApplication
@EnablePrometheusEndpoint
public class SpringApplication extends WebMvcConfigurerAdapter implements CommandLineRunner {
@Autowired
private CustomExporter customExporter;
...省略的代码
@Override
public void run(String... args) throws Exception {
...省略的代码
customExporter.register();
}
}
CustomExporter集成自io.prometheus.client.Collector,在调用Collector的register()方法后,当访问/metrics时,则会自动从Collector的collection()方法中获取采集到的监控指标。
由于这里CustomExporter存在于Spring的IOC容器当中,这里可以直接访问业务代码,返回需要的业务相关的指标。
import io.prometheus.client.Collector;
import io.prometheus.client.GaugeMetricFamily;
import org.springframework.stereotype.Component;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
@Component
public class CustomExporter extends Collector {
@Override
public List<MetricFamilySamples> collect() {
List<MetricFamilySamples> mfs = new ArrayList<>();
# 创建metrics指标
GaugeMetricFamily labeledGauge =
new GaugeMetricFamily("io_namespace_custom_metrics", "custom metrics", Collections.singletonList("labelname"));
# 设置指标的label以及value
labeledGauge.addMetric(Collections.singletonList("labelvalue"), 1);
mfs.add(labeledGauge);
return mfs;
}
}
当然这里也可以使用CounterMetricFamily,SummaryMetricFamily声明其它的指标类型。
小结
好了。 目前为止,我们通过Spring的拦截器,以及通过自定义Collector两种方式实现对应用自定义指标的暴露,启动应用程序,并且访问 http://localhost:8080/metrics。我们可以看到如下结果。
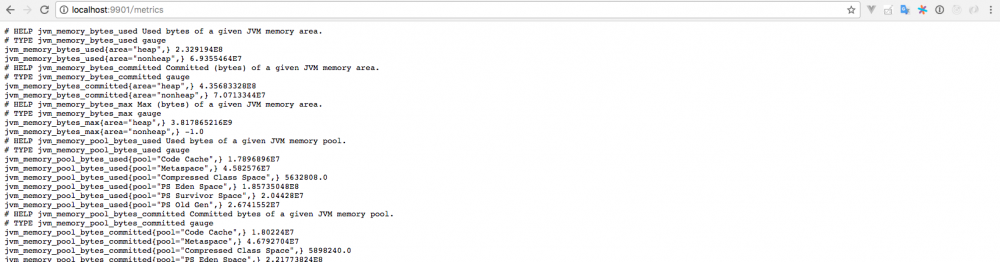
恭喜,接下来在后面的文章中我们会尝试将应用程序部署到Kubernetes当中,并且通过Prometheus采集其数据,通过PromQL聚合数据,并且在Grafana中进行监控可视化。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

