Spring Cloud在云计算SaaS中的实战经验分享

摘要
云帐房CTO张英磊基于自己的个人经验,分享Spring Cloud在云计算SaaS中的实战经验,希望能为大家带来一些思路上的帮助。
内容来源: 2017年5月6日,云帐房CTO张英磊在“Spring Cloud中国社区技术沙龙-北京站”进行《Spring Cloud在云计算SaaS中的实战经验分享》演讲分享。IT 大咖说作为独家视频合作方,经主办方和讲者审阅授权发布。
阅读字数: 2084 | 5分钟阅读
嘉宾演讲视频及PPT回顾: t.cn/RETMgVo
SaaS漫谈
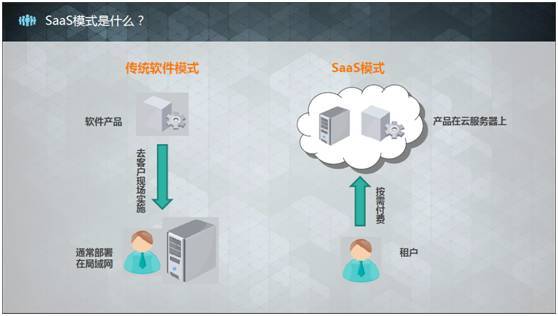
SaaS模式是什么?
传统的软件模式是在开发出软件产品后,需要去客户现场进行实施,通常部署在局域网,这样开发、部署及维护的成本都是比较高的。
现在随着云服务技术的蓬勃发展,就出现了SaaS模式。所谓SaaS模式即是把产品部署在云服务器上,从前的客户变成了“租户”,我们按照功能和租用时间对租户进行收费。这样的好处是,用户可以按自己的需求来购买功能和时间,同时自己不需要维护服务器,而我们作为SaaS提供商也免去了跑到客户现场实施的麻烦,运维的风险则主要由IaaS提供商来承担。
SaaS多租户数据库方案
目前主流的SaaS多租户数据库方案有以下三种:

完全隔离:独立数据库,它的好处就是隔离度很高,但是占用成本也相当高,而且资源共享度低。
共享+隔离:可以共享数据库,但是有独立的Schema。这样它的各项指标相对来说都是比较平均的。
完全共享:共享数据库和数据表。我个人不太推荐这种方式,因为虽然它的共享度很高,但是几乎没有隔离度,而且开发上的复杂度会随着业务发展越来越高。
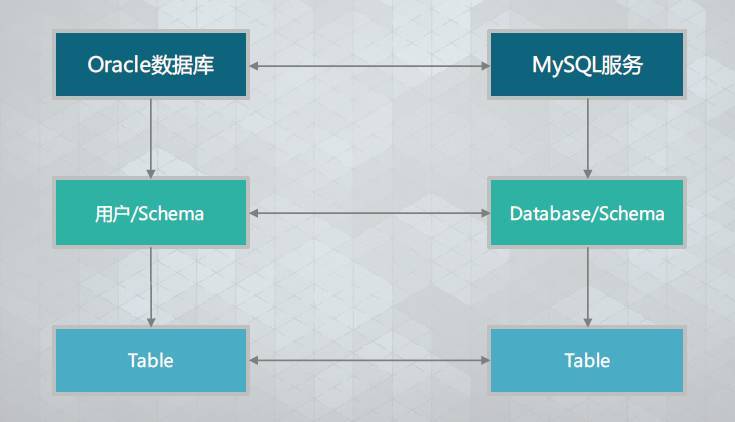
什么是Schema?
数据库中的Schema是数据库对象的集合。比如在Oracle中,一个用户一般对应一个Schema。
对MySQL来说,Schema并不是Database的下级,而是等同于Database。比如执行create schema test,和createdatabase test是一样的。
Oracle与MySQL的数据库层级对应关系如下:
独立Schema模式的优点和问题
独立Schema模式的优点:
高独立性: 每个租户都拥有自己的库,与其他租户是隔离的;
高可扩展性: 可以方便的进行横向扩展和数据迁移;
业务开发简单: 开发时只需要考虑单租户的业务逻辑即可,通过切换Schema来达到多租户的效果,联查的表更少;
定制化服务: 用户可以定制个性化服务,不影响其他租户;
独立Schema模式存在的问题:
1、数据库越来越多怎么办?如果有10万个租户,就有10万个库,单个服务器肯定无法承受。
2、如此多的数据库,如何进行表的更新与维护?
3、租户的数据都隔离开了,进行整体数据分析的时候怎么办?
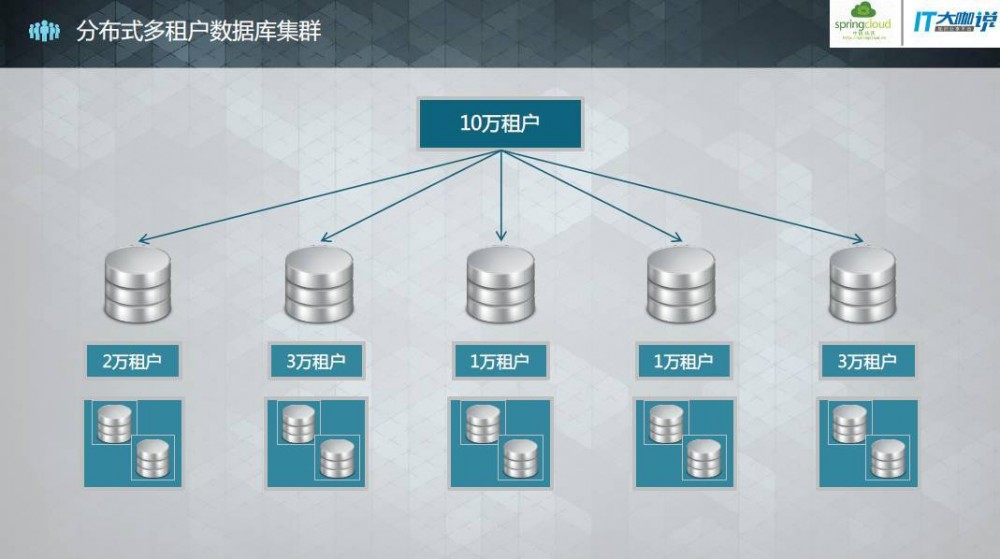
分布式多租户数据库集群
为了解决第一个问题,我们采用了分布式多租户数据库集群。假设有10万租户,它们可以分布在不同的服务器上,而且每台服务器上的数量都不是固定的,可以根据业务量进行分布,必要时还可以进行租户迁移。
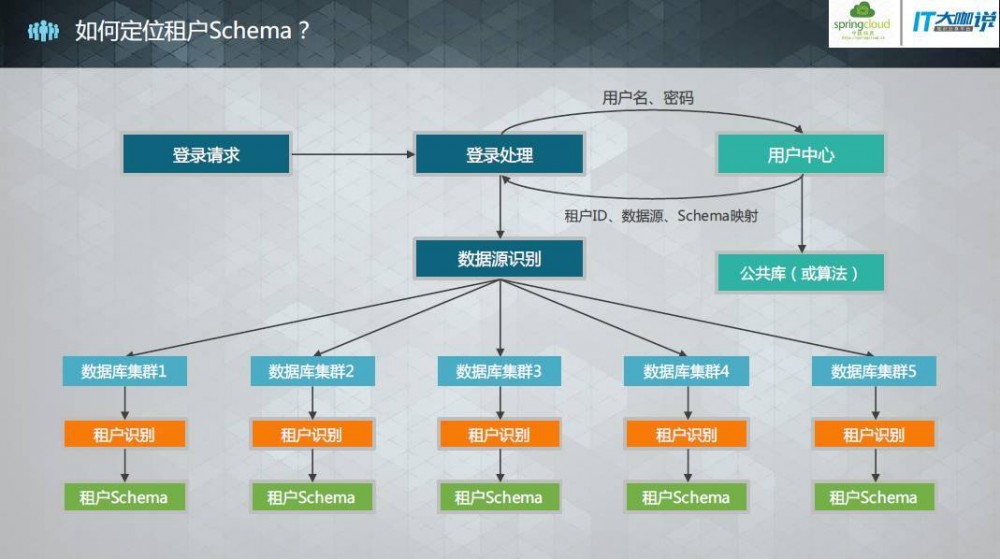
当租户分布开以后,可使用如下方式来定位租户:
数据微服务
第二和第三个问题,可以使用数据微服务来解决:
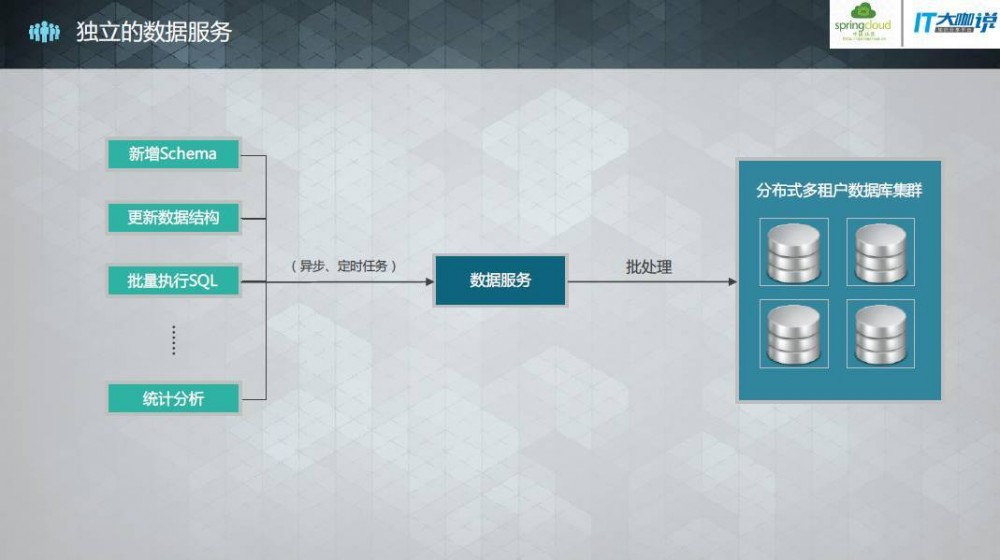
数据微服务可以专门用来处理新增Schema,更新数据结构、批量执行SQL以及统计分析等操作。
至于统计分析的时效性,租户通常只关注自身业务的统计分析,因此我们在面向租户时可以只对单个业务库进行实时统计分析,数据量一般不大。而我们后台对全局数据的统计分析通常时效性要求不高,就可以使用异步或定时任务处理,此时建议使用多个数据微服务来分区处理数据再汇总。当总体数据量大到一定程度,还可以引入Hadoop等大数据处理框架。
架构设计
微服务的拆分原则
微服务大体上有两种情况的拆分。第一种是根据业务功能进行拆分,微服务本身应该是高内聚的,微服务之间低耦合,微服务业务应该是单一的。
另一种情况就是从架构设计来拆分,是从基础组件、性能均衡和资源分配这三个角度考虑的。
业务架构设计
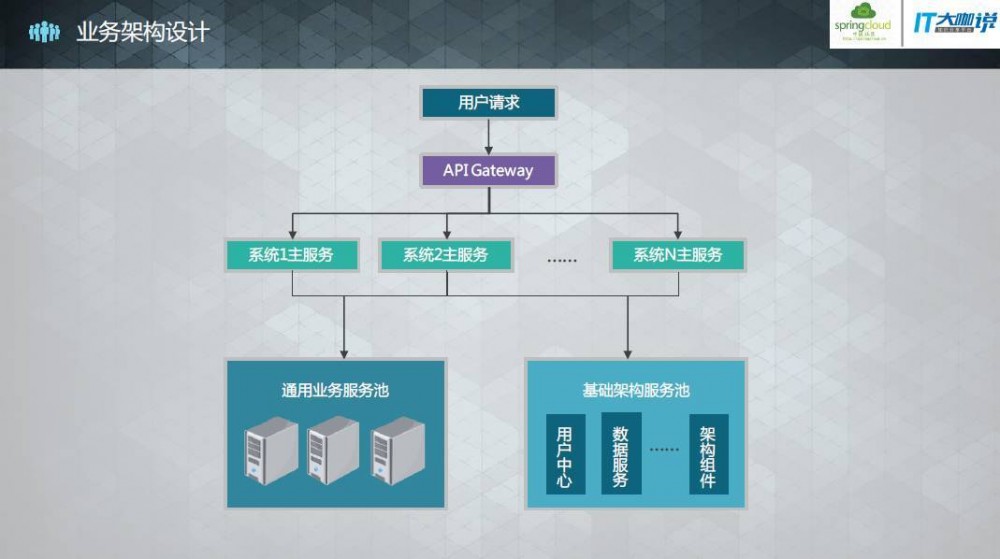
通常情况下,我们都可以拆分出许多通用业务微服务和基础架构微服务,现在假设我们有这样的通用业务服务池和基础架构服务池。首先我们可能有很多不同的系统,它们一些通用的业务就放在通用业务池里,但是它们本身也会有一些独立的特殊业务。那么我们既可以直接调用通用业务服务池里的API,也可以在处理特殊业务时调用其他业务微服务的API,而这些业务微服务也同样可以调用通用业务池里的微服务。
产品不是由服务组成的,而是由API组成的。服务就是服务,我们不一定要让它必须属于哪个产品,而是要把不同服务的API组合成一个产品。
下面是一个使用Spring Cloud的服务拓扑举例:
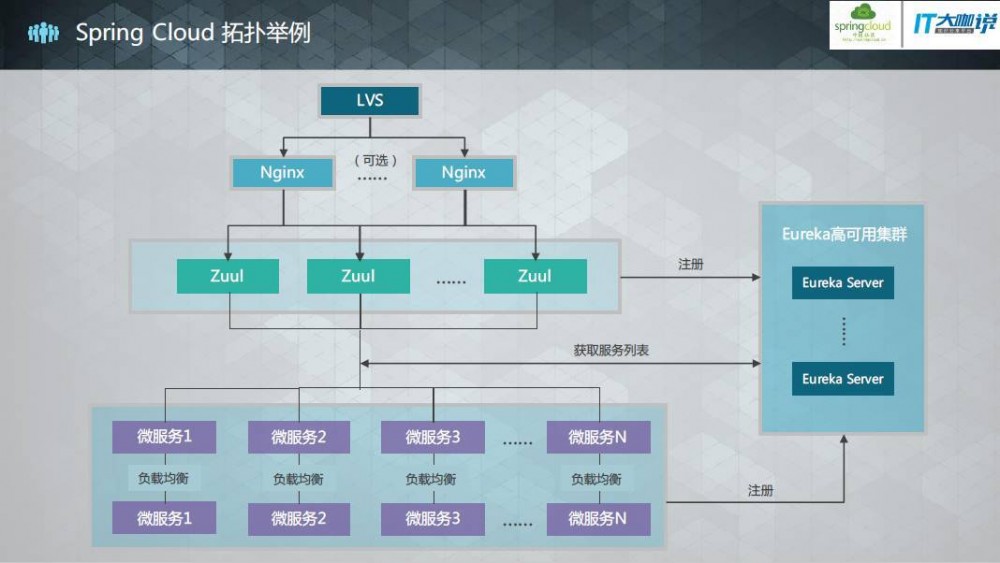
实战经验分享
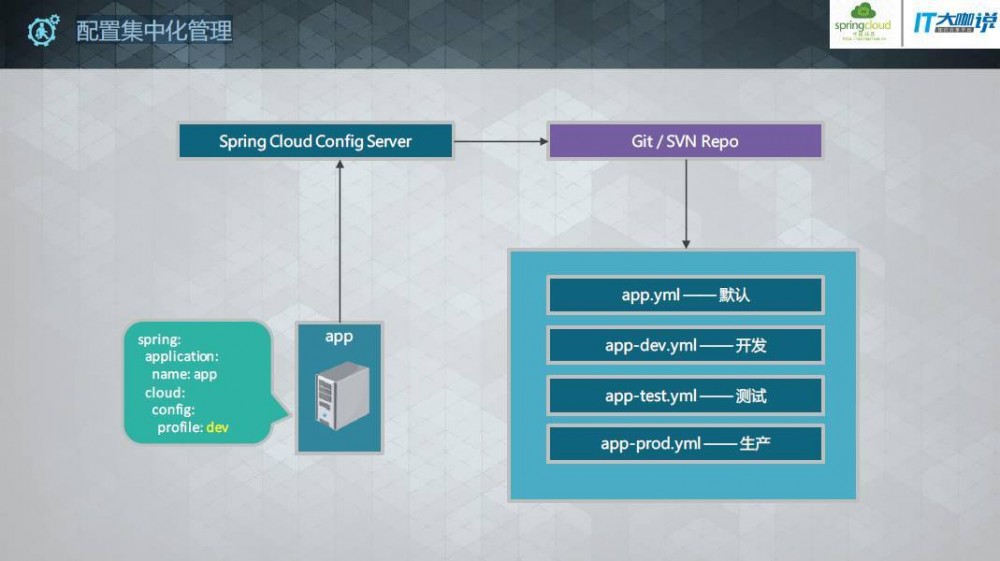
配置集中化管理
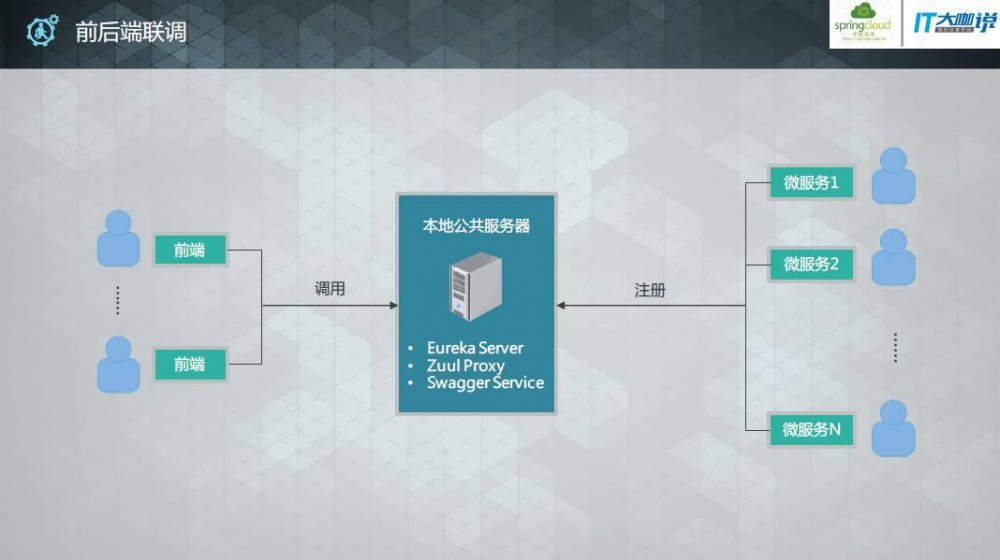
前后端协作

通常使用swagger方式中存在的问题:
各类与业务无关的注解大量污染Controller代码,造成维护困难;
灵活性差,想要给特定人暴露特定接口(比如第三方)比较麻烦;
发布生产时需要特殊处理来关闭swagger;
Swagger有时会与其他jar包冲突(比如springfox-swagger2.6.0会导致注册Eureka异常)。
Spring Cloud + Swagger
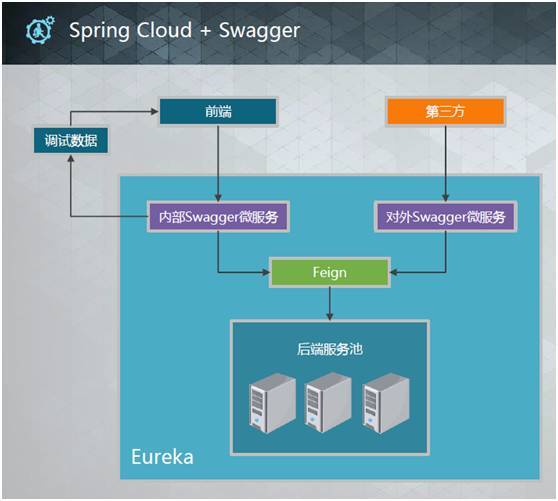
开发未动,文档先行。正式开发前优先编写独立的Swagger微服务供开发人员参考,让Swagger回归文档本质;
项目初期,由Swagger微服务直接返回格式化的假数据供前端调试,方便前后端并行开发;
前后端联调时,前端可继续由Swagger通过Feign来调用后端服务查看数据,或直接连后端服务调试真实业务逻辑;
可针对不同第三方的需求,提供不同的对外Swagger微服务让对方调试,灵活暴露接口。
后端服务完全不引入任何Swagger代码,保持代码纯净,也避免了Swagger冲突,发布生产时直接关掉Swagger服务即可;
注意事项:
Swagger的接口路径、参数等必须与真正的业务接口保持一致,严格遵守规范,方便前端直连后端时统一修改;
Swagger微服务中需要有相应的VO,这类东西可以编写一次,到处复制。因此并不会增加工作量。
总结
技术并不是全部

我今天的分享就到这里,谢谢大家!
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

