容器化RDS—— 计算存储分离 or 本地存储
沃趣科技 熊中哲
随着交流机会的增多(集中在金融行业, 规模都在各自领域数一数二), 发现大家对 Docker + Kubernetes 的接受程度超乎想象, 并极有兴趣将这套架构应用到 RDS 领域. 数据库服务的需求可以简化为:
实现数据零丢失的前提下,提供可接受的服务能力
因此存储架构的选型至关重要. 到底是选择计算存储分离还是本地存储?
本文就这个问题, 从以下几点展开 :
● 回顾 : 计算存储分离, 本地存储优缺点
● MySQL 基于本地存储实现数据零丢失
● 性能对比
● 基于 Docker + Kubernetes 的实现
分享个人理解.
回顾 : 计算存储分离, 本地存储优缺点
还是从计算存储分离说起,
计算存储分离
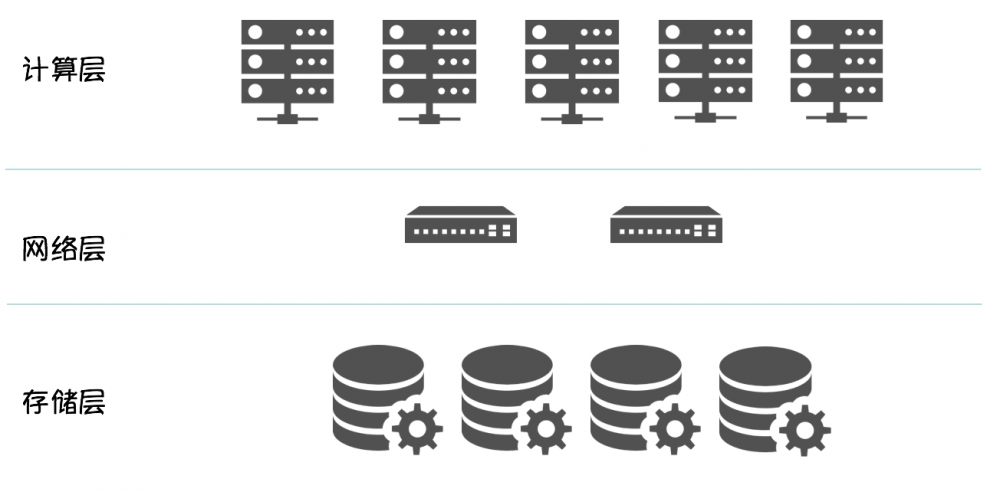
先说优点 :
● 架构清晰
● 计算资源 / 存储资源独立扩展
● 提升实例密度, 优化硬件利用率
● 简化实例切换流程 : 将有状态的数据下沉到存储层, Scheduler 调度时, 无需感知计算节点的存储介质, 只需调度到满足计算资源要求的 Node, 数据库实例启动时, 只需在分布式文件系统挂载 mapping volume 即可. 可以显著的提高数据库实例的部署密度和计算资源利用率.
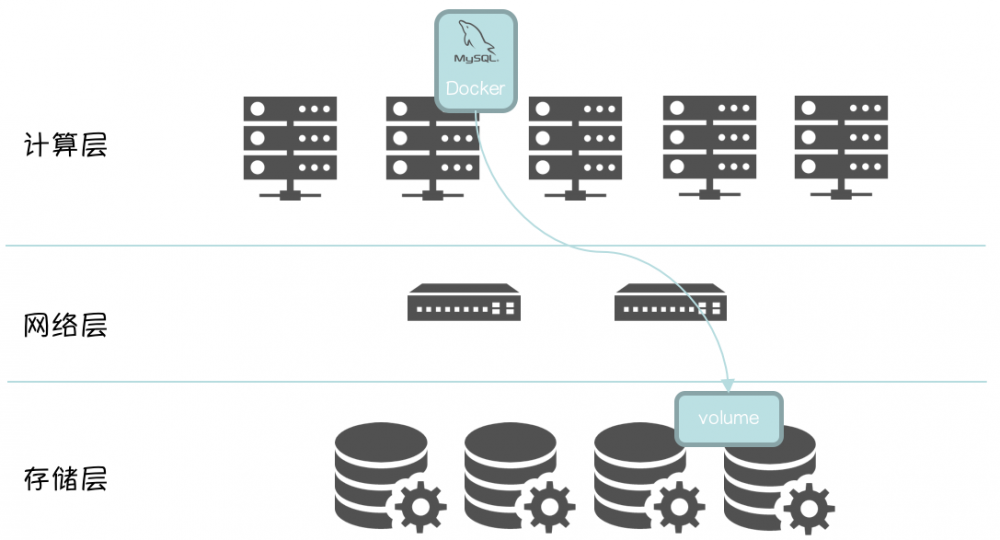
以 MySQL 为例
● 通用性更好, 同时适用于 Oracle , MySQL
详见 : <容器化RDS : 计算存储分离架构下的"Split-Brain">
从部分用户的上下文来看, 存在如下客观缺点 :
● 引入分布式存储, 架构复杂度加大. 一旦涉及到分布式存储的问题, DBA 无法闭环解决.
● 分布式存储选型,
○ 选择商用, 有 Storage Verdor Lock In 风险
○ 选择开源, 大多数用户(包括沃趣)都测试过 GlusterFS 和 Ceph ,针对数据库(Sensitive Lantency)场景, 性能完全无法接受.
本地存储
如果在意计算存储分离架构中提到的缺点, 本地存储可以有效的打消类似顾虑,
无需引入分布式存储, 避免Storage Verdor Lock In 风险, 所有问题都由DBA 闭环解决,.
但是, 需要依赖数据库自有方案实现数据零丢失
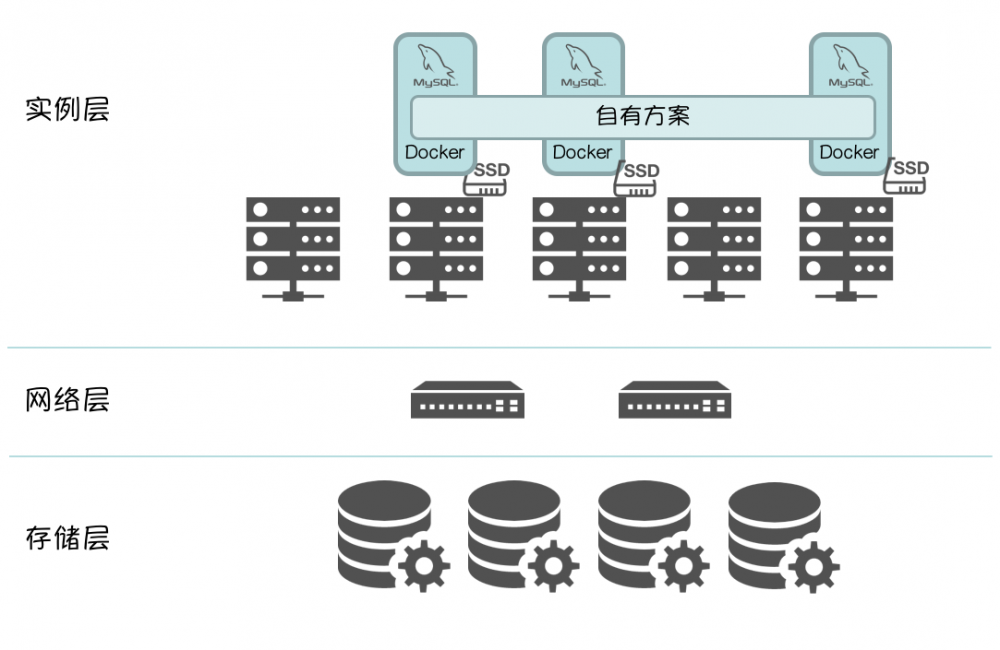
以 MySQL 为例
还会引入类似问题,
● 物理容量受限于单机容量;
● 调度更复杂, 选定数据库实例的存储类型(比如 SSD )后, 一旦该实例发生”failover”, 只能调度到拥有 SSD 的物理节点, 这导致调度器需要对物理节点”Physical Topology Aware”;
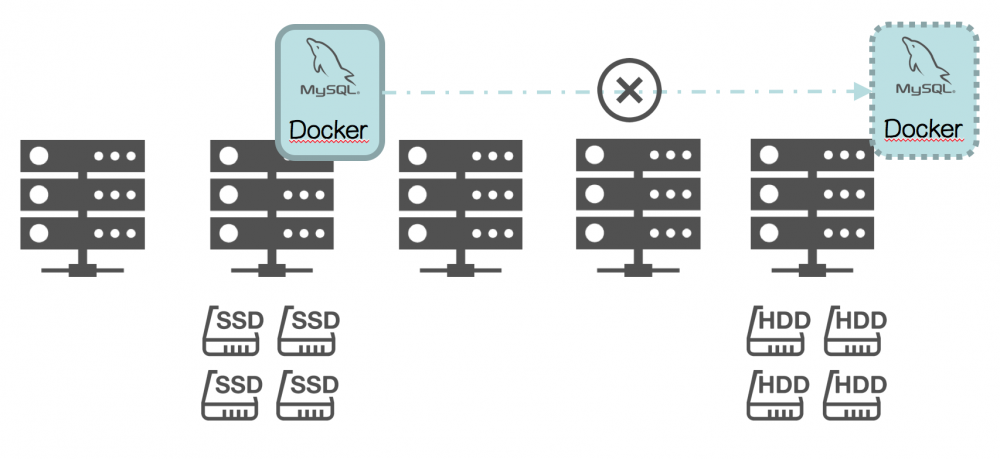
● 密度难提升, 这是”Physical Topology Aware”的副作用;
● 因数据库的不同方案差异性较大, 通用性无法保证.
接下来, 进入正题, 看一下 MySQL 基于本地存储如何实现数据库零丢失.
MySQL 基于本地存储数据零丢失
最常用的是基于 Replication 模型将数据复制到 MySQL Cluster 中所有成员.
MySQL Master-Slave Replication (类似 Oracle DataGuard) 提供了基于 binlog 的数据库层的复制模型, 在高并发压力下节点间同步数据速率最快, 单位时间内的交易量受其他节点的影响极小, 该架构可通过 vip 漂移的方式实现 “failover”
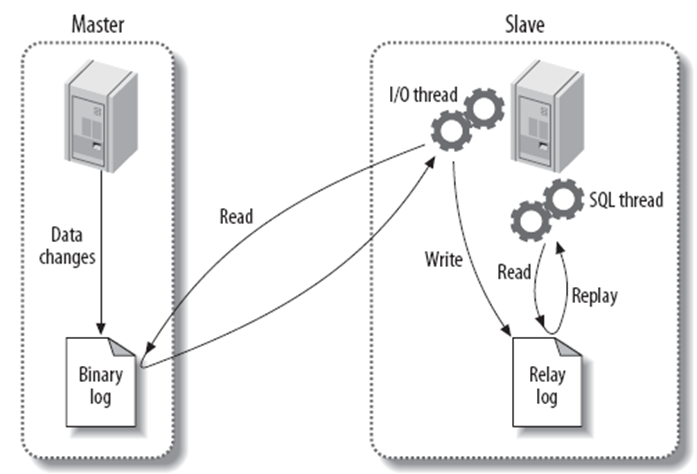
MySQL Master-Slave Replication
但严格意义上来说, 这是基于 binlog 的 Asynchronous Replication 模型, 因此集群中所有成员存在数据不一致的可能,在”failover”时无法保证数据零丢失.
可见如果基于 Replication 模型, Synchronous Replication 是实现数据零丢失的前提.
传统的 Synchronous Replication 一般会采用两阶段提交或分布式锁, 这会带来如下几个问题 :
● 单位时间内事务能力(TPS) 会跟集群成员数量成反比
● 增加集群成员会显著且无法预期的增加事务响应时间
● 增加了集群成员数据复制的冲突和死锁的可能性
针对以上问题 Galera Cluster 提出 Certification-based Replication 来解决传统 Synchronous Replication 中遇到的问题, 实现如下 :
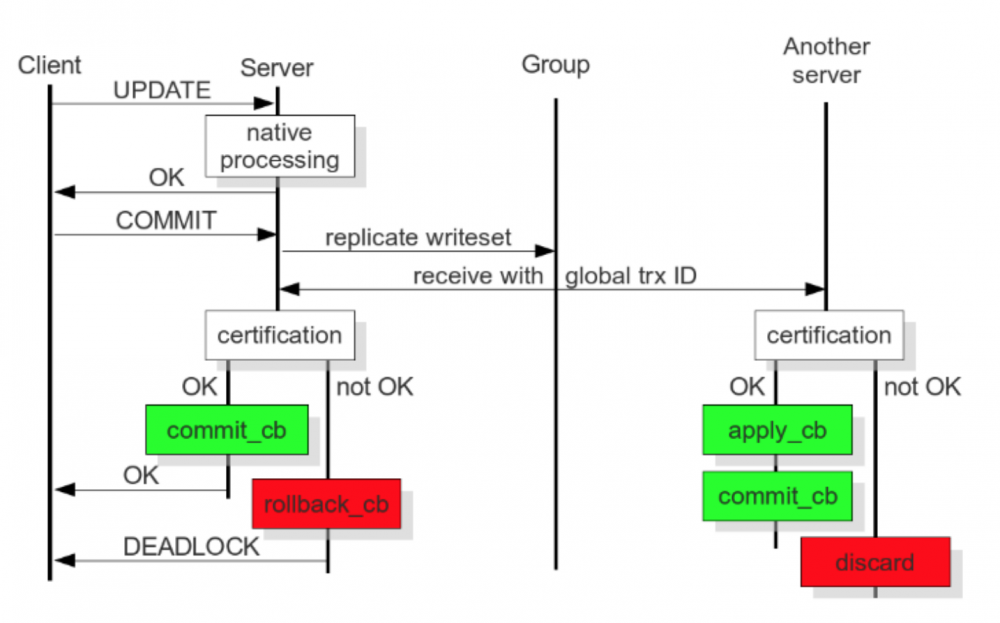
Deferred Update Replication 延迟更新复制
这个流程图中, 有几个细节需要分享,
● 将基于 binlog 改为基于 write-set. write-set 中包含修改的数据, Global Transaction ID (后面简称 GTID)和 Primary Key.
○ GTID 类似 45eec521-2f34-11e0-0800-2a36050b826b:94530586304
○ 94530586304 为64-bit 有符号整型, 用来表示事务在序列中的位置
● 将传统的 Synchronous Replication 改为 Deferred Update Replication, 并将整个过程大致分解成四个阶段, 本地阶段, 发送阶段, 验证阶段和应用阶段, 其中 :
○ 本地阶段 : 乐观执行, 在事务 Commit 前, 假设该 Transcation 在集群中复制时不会产生冲突
○ 发送阶段 : 优化同步时间窗口, 除去全局排序并获取 GTID 为同步操作, 冲突验证和事务应用都为异步, 极大的优化了复制效率.
○ 验证阶段 : 只有收到该事务的所有前置事务后(不能有 “hole”), 该事务和所有未执行的前置事务才能并发验证, 不然不能保证 Global Ordering, 因此这里需要牺牲效率, 引入一定的串行化.

需要等待事务3
于是就有了 Galera Cluster 在 MySQL 分支中的实现 MariaDB Galera Cluster (简称 MGC) 和 Percona Xtradb Cluster (简称 PXC)
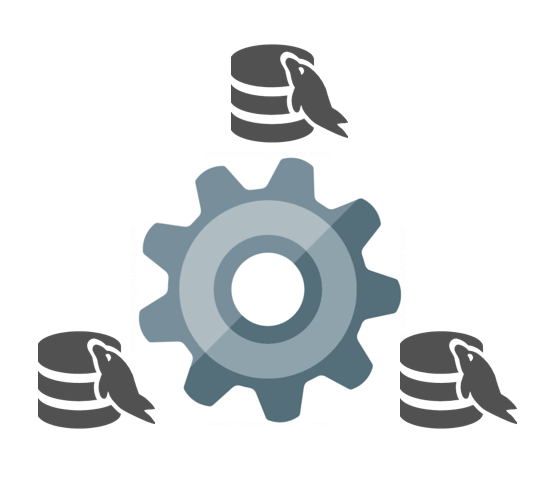
为避免”split-brain”问题, 需要至少三节点组成集群, 对计算资源和存储资源的容量要求至少增加2倍, 会进一步降低资源的部署密度
越来越多的用户也期望通过该方案实现 跨 IDC 多活, 那么需要在规划阶段想清楚 :
IDC 和 数据库节点的拓扑架构, 以保证在1个 IDC 出问题的情况, 集群可以持续提供服务
首先IDC (物理或逻辑) 最少需要3个, 再看看数据库节点数量分别为3, 4, 5, 6, 7的拓扑关系 :
● 3 数据库节点 :
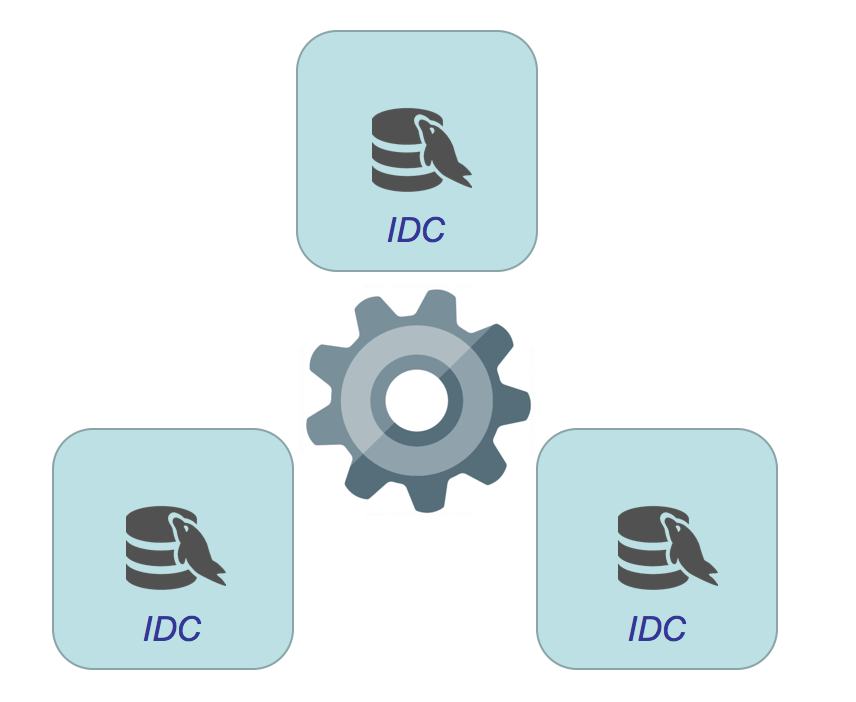
● 4 数据库节点 :设置权重避免”split-brain” (? + ? ) + ? + ?
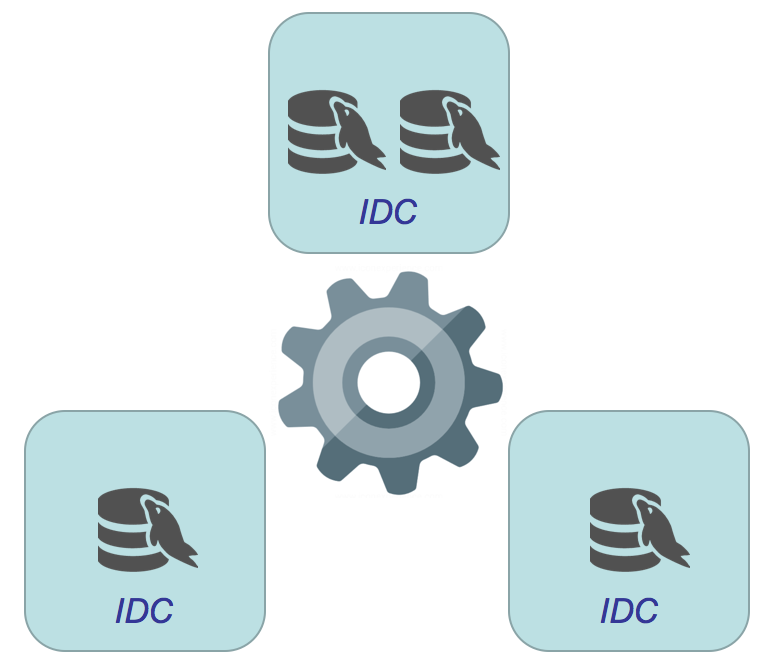
● 5 数据库节点
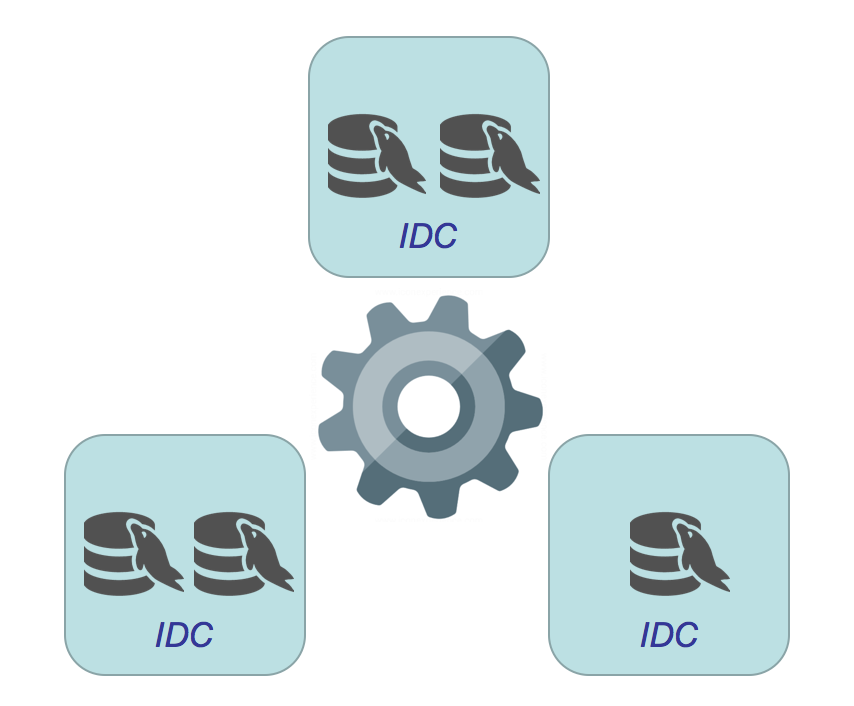
● 6 数据库节点
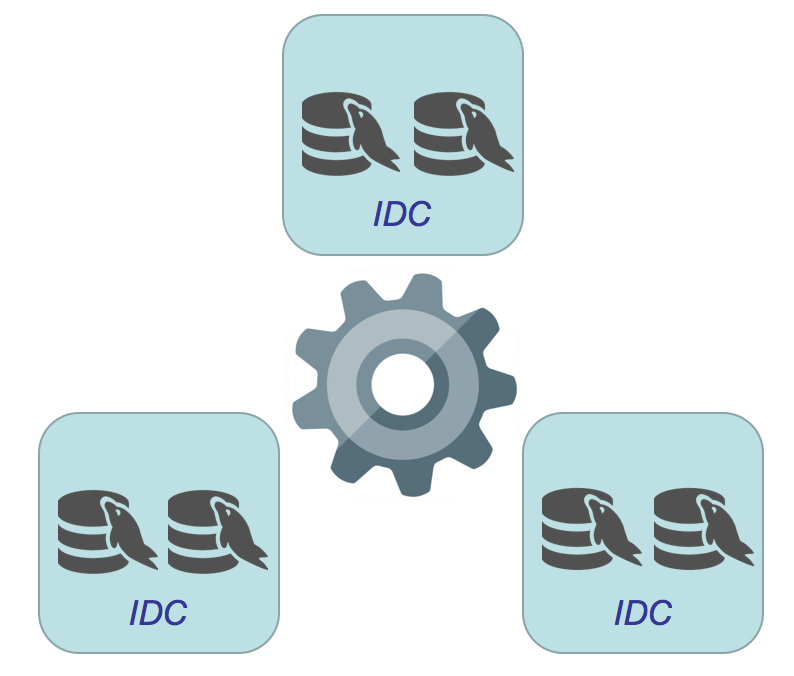
● 7 数据库节点 : 可支持两种拓扑关系
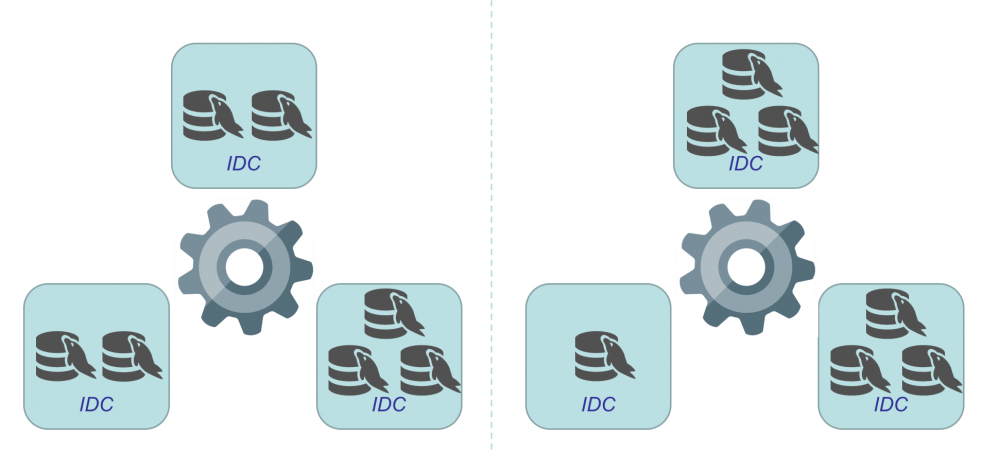
同时, 还有 MySQL Group Replication[1] (简称 MGR), 类似 Galera Cluster :
● 基于Corosync实现(Totem协议), 插件式安装, MySQL 官方原生插件.
● 集群架构, 支持多写(建议单写)
● 允许少数节点故障, 同步延迟较小, 保证强一致, 数据零丢失
● 单位时间的交易量受 flow control 影响.
这里还需要提一下 Vitess[2]
● 该项目由 youtube 开源, 从文档看功能极为强大, 高度产品化.
● 作为第二个存储类项目(第一个是 Rook, 有意思是存储类而不是数据库类)加入 CNCF, 目前还处于孵化阶段(incubation-level).
● 笔者没有使用经验, 也不知道国内有哪些用户, 不做评论.
关于 MGR 和 Vitess 网上已有大量介绍, 这里不再赘述.
性能对比
在数据零丢失的前提下, 看看这几种架构在性能上的对比:
● MGR 5.7.17 / PXC 5.7.14-26.17
● MGR 5.7.17 / PXC 5.7.17-29.20 / MariaDB 10.2.5 RC
● 本地存储 / 计算存储分离
性能对比1 : MGR 5.7.17 / PXC 5.7.14-26.17
测试背景描述:
● MGR 5.7.17 对比 PXC 5.7.14-26.17 (基于 Galera 3实现)
● 负载模型 : OLTP Read/Write (RW)
● durability : sync_binlog=1, innodb_flush_log_at_trx_commit=1
● non-durability : sync_binlog=0, innodb_flush_log_at_trx_commit=2
测试数据 :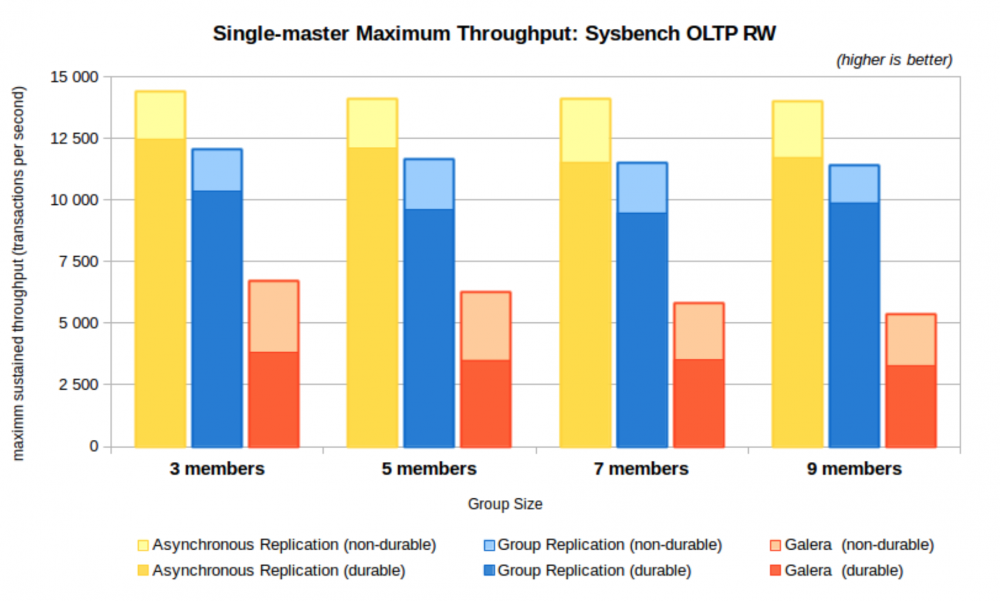
来自于 MySQL 官方[3]
测试结果:
在设置 durability 的情况下, MGR 最大吞吐约是PXC 5.7.14-26.17 (基于 Galera 3 实现) 的3倍, 优势明显.
以上数据来自于MySQL 官方, 公平起见, 再来看看 Percona 在相同负载模型下的测试数据.
性能对比2 : MGR 5.7.17 / PXC 5.7.17-29.20 / MariaDB 10.2.5 RC
测试背景描述:
● 增加了 MariaDB 参与对比
● PXC 升级到 5.7.17-29.20, 该版本改进了MySQL write-set 复制层性能[4].
● 负载模型 : 依然使用 OLTP Read/Write (RW)
● durability : sync_binlog=1
● non-durability : sync_binlog=0
测试数据 :
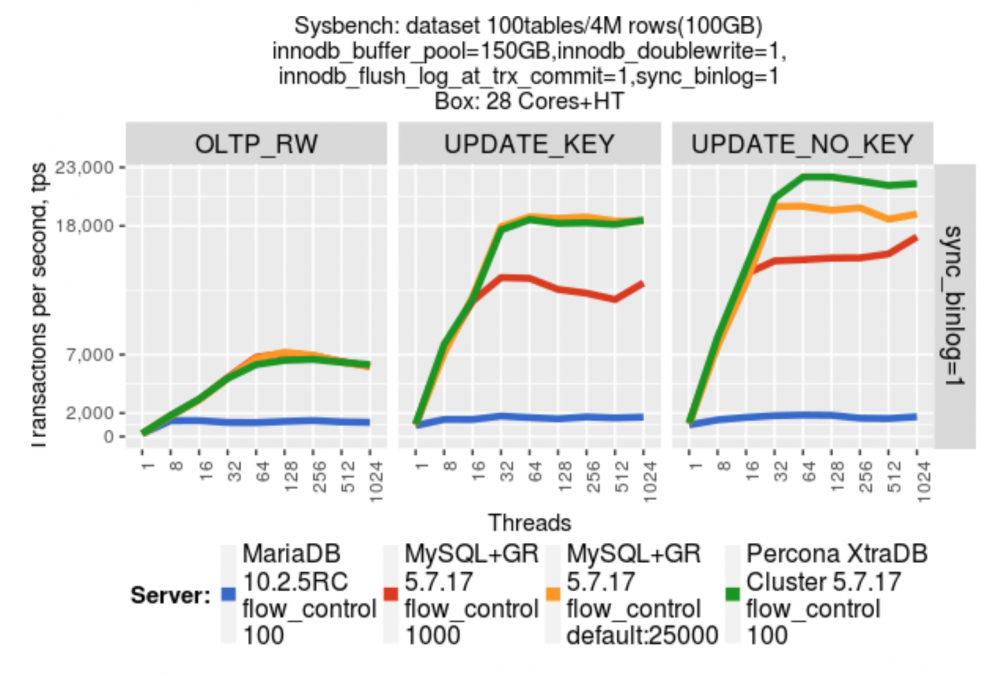
设置 durability , 数据来自于 Percona[5]

设置 non-durability , 数据来自于 Percona[6]
测试结果:
在负载模型相同的情况下(durability 和 non-durability) PXC 5.7.17-29.20 性能与 MGR 5.7.17 不分伯仲[7]. 如果使用 PXC, 推荐使用 5.7.17-29.20 或以上版本.
性能对比3 : 本地存储 / 计算存储分离
为了对比本地存储和计算存储分离, 专门使用 MGR + 本地存储架构 和 基于分布式存储的计算存储分离架构做性能对比.
测试结果:
在负载模型相同的情况下, 前者比后者 OLTP 下降32.12%, Select下降5.44%, Update下降24.18%, Insert 下降58.18%, Delete下降11.44%;
详细内容可留意 @波多野 同学 和 @韩杰 同学的测试报告, 这里不再赘述.
基于 Docker + Kubernetes 的实现
Docker + Kubernetes + MGR / Galera Cluster
在 github 上,可以看到基于 Docker + Kuberetes + PXC 的 demo[8]. 需要说明的是, 这仅仅是个玩具, 离部署到生产环境还有极大差距.
我们已有计划实现满足生产环境的
● Docker + Kubernetes + PXC
● Docker + Kubernetes + MGC
● Docker + Kubernetes + MGR
并集成到 QFusion 来支持计算存储分离架构和本地存储架构混合部署, 架构示意图如下 :
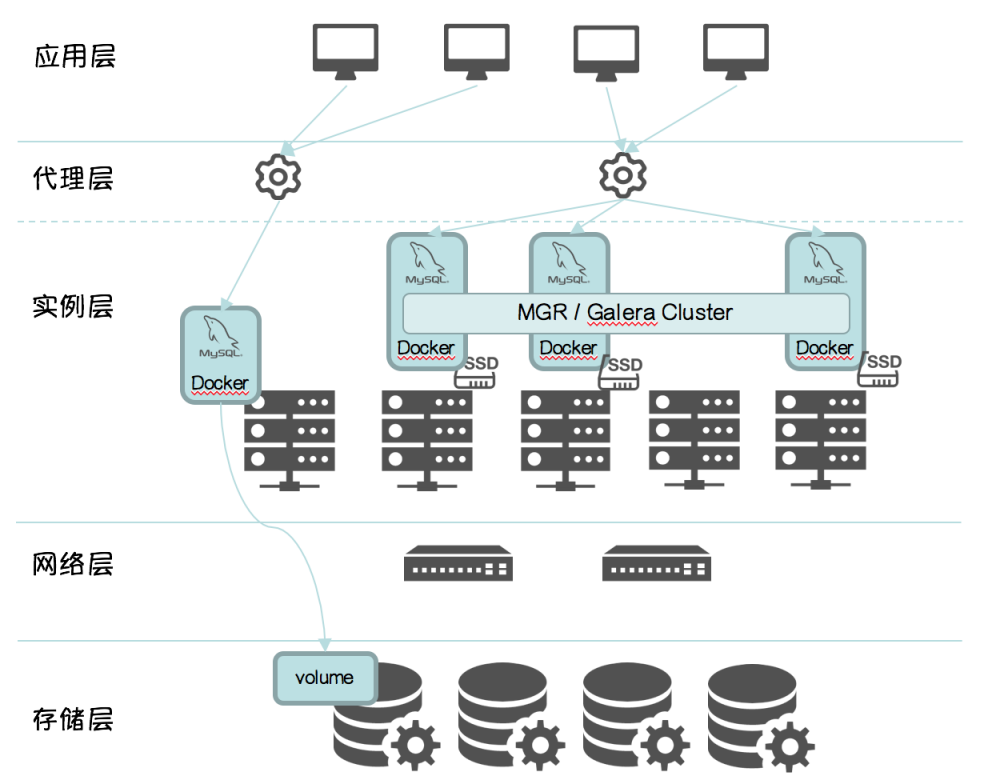
目前原型验证阶段已通过, 预计2018年Q2发布.
Docker + Kubernetes + Vitess
在 github 上,同样可以看到基于 Docker + Kubernetes 的 demo[9]. 有兴趣的同学可以玩一下.
性能只是选型需要考量的一部分, 要使用到生产环境或者产品化, 实际要考量的因素更多 :
● 运维 : 部署, 备份
● 弹性 : 计算存储扩容, 集群扩容
● 高可用 : 比如 “failover” 的细微差别对业务的影响
● 容错 : 比如网络对集群的影响, 尤其是在网络抖动或有明显延时的情况下
● 社区活跃度
● …...
以现有软硬件的开放程度, 各种架构或者产品狭义上的”黑科技”并不多, 常常看到的
xxx 比 xxx 快 xxx 倍
严格来说应该是
xxx 比 xxx 在特定场景 xxx 下快 xxx 倍.
并不存在”一枪毙命”的”Silver Bullet”, 只是 Docker + Kubernetes 为混合部署带来可能. 哪种更受青睐, 拭目以待, 用户会是最好的老师.
|
<人月神话>中提到”No Silver Bullet.”, 原意是用来论述软件工程领域的生产力问题
由于软件的复杂性本质, 使得真正的银弹并不存在, 没有任何一项技术或方法可使软件工程的生产力在十年内提高十倍. |
[1] https://dev.mysql.com/doc/refman/5.7/en/group-replication-background.html
[2] http://vitess.io/
[3] http://mysqlhighavailability.com/performance-evaluation-mysql-5-7-group-replication/?spm=5176.100239.blogcont66550.17.T4N8cZ
[4] https://www.percona.com/blog/2017/04/19/performance-improvements-percona-xtradb-cluster-5-7-17/
[5] https://www.percona.com/blog/2017/04/19/performance-improvements-percona-xtradb-cluster-5-7-17/
[6] https://www.percona.com/blog/2017/04/19/performance-improvements-percona-xtradb-cluster-5-7-17/
[7] 因为没有看到 MariaDB 的官方数据, 公平起见, 不做评论.
[8] https://github.com/kubernetes/kubernetes/tree/master/examples/storage/mysql-galera
[9] https://github.com/kubernetes/kubernetes/tree/master/examples/storage/vitess
正文到此结束
- 本文标签: HTML 锁 Action 高并发 tab Oracle 安装 App 软件 调度器 分布式 测试 科技 map 时间 插件 http id 协议 sql key src Master Lua 备份 https 集群 需求 Docker example 十年 分布式锁 update git cat GitHub 实例 Uber 文件系统 本质 mysql ip 产品 NSA Select 同步 IO 模型 db 压力 数据 Kubernetes 开源 ORM 高可用 node 数据库 金融
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

