每日一博 | 从零开始写简易读写分离并不复杂
最近在学习Spring boot,写了个读写分离。并未照搬网文,而是独立思考后的成果,写完以后发现从零开始写读写分离并不难!
我最初的想法是: 读方法走读库,写方法走写库(一般是主库),保证在Spring提交事务之前确定数据源.
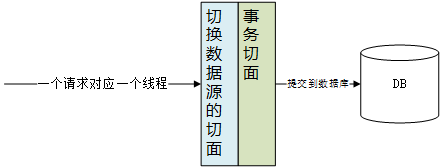
保证在Spring提交事务之前确定数据源,这个简单,利用AOP写个切换数据源的切面,让他的优先级高于Spring事务切面的优先级。至于读,写方法的区分可以用2个注解。
但是如何切换数据库呢? 我完全不知道!多年经验告诉我
当完全不了解一个技术时,先搜索学习必要知识,之后再动手尝试。
--温安适 20180309
我搜索了一些网文,发现都提到了一个AbstractRoutingDataSource类。查看源码注释如下
/**
Abstract {@link javax.sql.DataSource} implementation that routes {@link #getConnection()}
* calls to one of various target DataSources based on a lookup key. The latter is usually
* (but not necessarily) determined through some thread-bound transaction context.
*
*@author Juergen Hoeller
*@since 2.0.1
*@see #setTargetDataSources
* @see #setDefaultTargetDataSource
* @see #determineCurrentLookupKey()
*/
AbstractRoutingDataSource就是DataSource的抽象,基于lookup key的方式在多个数据库中进行切换。重点关注setTargetDataSources,setDefaultTargetDataSource,determineCurrentLookupKey三个方法。那么 AbstractRoutingDataSource就是Spring读写分离的关键了。
仔细阅读了三个方法,基本上跟方法名的意思一致。setTargetDataSources设置备选的数据源集合。 setDefaultTargetDataSource设置默认数据源,determineCurrentLookupKey决定当前数据源的对应的key。
但是我很好奇 这3个方法都没有包含切换数据库的逻辑啊 !我仔细阅读源码发现一个方法, determineTargetDataSource方法,其实它才是获取数据源的实现。 源码如下:
//切换数据库的核心逻辑
protected DataSource determineTargetDataSource() {
Assert.notNull(this.resolvedDataSources, "DataSource router not initialized");
Object lookupKey = determineCurrentLookupKey();
DataSource dataSource = this.resolvedDataSources.get(lookupKey);
if (dataSource == null && (this.lenientFallback || lookupKey == null)) {
dataSource = this.resolvedDefaultDataSource;
}
if (dataSource == null) {
throw new IllegalStateException
("Cannot determine target DataSource for lookup key [" + lookupKey + "]");
}
return dataSource;
}
//之前的2个核心方法
public void setTargetDataSources(Map<Object, Object> targetDataSources) {
this.targetDataSources = targetDataSources;
}
public void setDefaultTargetDataSource(Object defaultTargetDataSource) {
this.defaultTargetDataSource = defaultTargetDataSource;
}
简单说就是,根据determineCurrentLookupKey获取的key,在resolvedDataSources这个Map中查找对应的datasource!, 注意determineTargetDataSource方法竟然不使用的targetDataSources!
那一定存在resolvedDataSources与targetDataSources的对应关系。我接着翻阅代码,发现一个afterPropertiesSet方法(Spring源码中InitializingBean接口中的方法),这个方法将targetDataSources的值赋予了resolvedDataSources。源码如下:
@Override
public void afterPropertiesSet() {
if (this.targetDataSources == null) {
throw new IllegalArgumentException("Property 'targetDataSources' is required");
}
this.resolvedDataSources = new HashMap<Object, DataSource>(this.targetDataSources.size());
for (Map.Entry<Object, Object> entry : this.targetDataSources.entrySet()) {
Object lookupKey = resolveSpecifiedLookupKey(entry.getKey());
DataSource dataSource = resolveSpecifiedDataSource(entry.getValue());
this.resolvedDataSources.put(lookupKey, dataSource);
}
if (this.defaultTargetDataSource != null) {
this.resolvedDefaultDataSource = resolveSpecifiedDataSource(this.defaultTargetDataSource);
}
}
afterPropertiesSet 方法,熟悉Spring的都知道,它在bean实例已经创建好,且属性值和依赖的其他bean实例都已经注入以后执行。
也就是说调用,targetDataSources,defaultTargetDataSource的赋值一定要在afterPropertiesSet前边执行。
AbstractRoutingDataSource简单总结:
- AbstractRoutingDataSource,内部有一个Map<Object,DataSource>的域resolvedDataSources
- determineTargetDataSource方法通过determineCurrentLookupKey方法获得key,进而从map中取得对应的DataSource。
- setTargetDataSources 设置 targetDataSources
- setDefaultTargetDataSource 设置 defaultTargetDataSource,
- targetDataSources和defaultTargetDataSource 在afterPropertiesSet分别转换为resolvedDataSources和resolvedDefaultDataSource。
- targetDataSources,defaultTargetDataSource的赋值一定要在afterPropertiesSet前边执行。
进一步了解理论后,读写分离的方式则基本上出现在眼前了。(“下列方法不唯一”)
先写一个类继承AbstractRoutingDataSource,实现determineCurrentLookupKey方法,和afterPropertiesSet方法。afterPropertiesSet方法中调用setDefaultTargetDataSource和setTargetDataSources方法之后调用super.afterPropertiesSet。
之后定义一个切面在事务切面之前执行,确定真实数据源对应的key。但是这又出现了一个问题, 如何线程安全的情况下传递每个线程独立的key呢 ?没错 使用ThreadLocal传递真实数据源对应的key 。
ThreadLocal,Thread的局部变量,确保每一个线程都维护变量的一个副本
到这里基本逻辑就想通了,之后就是写了。
DataSourceContextHolder 使用ThreadLocal存储真实数据源对应的key
public class DataSourceContextHolder {
private static Logger log = LoggerFactory.getLogger(DataSourceContextHolder.class);
//线程本地环境
private static final ThreadLocal<String> local = new ThreadLocal<String>();
public static void setRead() {
local.set(DataSourceType.read.name());
log.info("数据库切换到读库...");
}
public static void setWrite() {
local.set(DataSourceType.write.name());
log.info("数据库切换到写库...");
}
public static String getReadOrWrite() {
return local.get();
}
}
DataSourceAopAspect 切面切换真实数据源对应的key,并设置优先级保证高于事务切面
@Aspect
@EnableAspectJAutoProxy(exposeProxy=true,proxyTargetClass=true)
@Component
public class DataSourceAopAspect implements PriorityOrdered{
@Before("execution(* com.springboot.demo.mybatis.service.readorwrite..*.*(..)) "
+ " and @annotation(com.springboot.demo.mybatis.readorwrite.annatation.ReadDataSource) ")
public void setReadDataSourceType() {
//如果已经开启写事务了,那之后的所有读都从写库读
DataSourceContextHolder.setRead();
}
@Before("execution(* com.springboot.demo.mybatis.service.readorwrite..*.*(..)) "
+ " and @annotation(com.springboot.demo.mybatis.readorwrite.annatation.WriteDataSource) ")
public void setWriteDataSourceType() {
DataSourceContextHolder.setWrite();
}
@Override
public int getOrder() {
/**
* 值越小,越优先执行 要优于事务的执行
* 在启动类中加上了@EnableTransactionManagement(order = 10)
*/
return 1;
}
}
RoutingDataSouceImpl实现AbstractRoutingDataSource的逻辑
@Component
public class RoutingDataSouceImpl extends AbstractRoutingDataSource {
@Override
public void afterPropertiesSet() {
//初始化bean的时候执行,可以针对某个具体的bean进行配置
//afterPropertiesSet 早于init-method
//将datasource注入到targetDataSources中,可以为后续路由用到的key
this.setDefaultTargetDataSource(writeDataSource);
Map<Object,Object>targetDataSources=new HashMap<Object,Object>();
targetDataSources.put( DataSourceType.write.name(), writeDataSource);
targetDataSources.put( DataSourceType.read.name(), readDataSource);
this.setTargetDataSources(targetDataSources);
//执行原有afterPropertiesSet逻辑,
//即将targetDataSources中的DataSource加载到resolvedDataSources
super.afterPropertiesSet();
}
@Override
protected Object determineCurrentLookupKey() {
//这里边就是读写分离逻辑,最后返回的是setTargetDataSources保存的Map对应的key
String typeKey = DataSourceContextHolder.getReadOrWrite();
Assert.notNull(typeKey, "数据库路由发现typeKey is null,无法抉择使用哪个库");
log.info("使用"+typeKey+"数据库.............");
return typeKey;
}
private static Logger log = LoggerFactory.getLogger(RoutingDataSouceImpl.class);
@Autowired
@Qualifier("writeDataSource")
private DataSource writeDataSource;
@Autowired
@Qualifier("readDataSource")
private DataSource readDataSource;
}
基本逻辑实现完毕了就进行,通用设置,设置数据源,事务,SqlSessionFactory等
@Primary
@Bean(name = "writeDataSource", destroyMethod = "close")
@ConfigurationProperties(prefix = "test_write")
public DataSource writeDataSource() {
return new DruidDataSource();
}
@Bean(name = "readDataSource", destroyMethod = "close")
@ConfigurationProperties(prefix = "test_read")
public DataSource readDataSource() {
return new DruidDataSource();
}
@Bean(name = "writeOrReadsqlSessionFactory")
public SqlSessionFactory
sqlSessionFactorys(RoutingDataSouceImpl roundRobinDataSouceProxy)
throws Exception {
try {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setDataSource(roundRobinDataSouceProxy);
ResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
// 实体类对应的位置
bean.setTypeAliasesPackage("com.springboot.demo.mybatis.model");
// mybatis的XML的配置
bean.setMapperLocations(resolver.getResources("classpath:mapper/*.xml"));
return bean.getObject();
} catch (IOException e) {
log.error("" + e);
return null;
} catch (Exception e) {
log.error("" + e);
return null;
}
}
@Bean(name = "writeOrReadTransactionManager")
public DataSourceTransactionManager transactionManager(RoutingDataSouceImpl
roundRobinDataSouceProxy) {
//Spring 的jdbc事务管理器
DataSourceTransactionManager transactionManager = new
DataSourceTransactionManager(roundRobinDataSouceProxy);
return transactionManager;
}
其他代码,就不在这里赘述了,有兴趣可以移步 完整代码 。
使用Spring写读写分离,其核心就是AbstractRoutingDataSource,源码不难,读懂之后,写个读写分离就简单了!。
AbstractRoutingDataSource重点回顾:
- AbstractRoutingDataSource,内部有一个Map<Object,DataSource>的域resolvedDataSources
- determineTargetDataSource方法通过determineCurrentLookupKey方法获得key,进而从map中取得对应的DataSource。
- setTargetDataSources 设置 targetDataSources
- setDefaultTargetDataSource 设置 defaultTargetDataSource,
- targetDataSources和defaultTargetDataSource 在afterPropertiesSet分别转换为resolvedDataSources和resolvedDefaultDataSource。
- targetDataSources,defaultTargetDataSource的赋值一定要在afterPropertiesSet前边执行。
这周确实有点忙,周五花费了些时间不过总算实现了自己的诺言。
完成承诺不容易,喜欢您就点个赞!
正文到此结束
- 本文标签: rmi final tar bean 数据 实例 源码 src 安全 IO 代码 mybatis Service UI springboot App classpath Connection cat sqlsession 管理 value https Action 配置 Spring Boot CTO java dataSource 线程 mapper NSA key Property map id 注释 spring 总结 数据库 SqlSessionFactory IDE XML db http sql AOP 时间
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

