SpringBoot系列 - 批处理
Spring Batch是一个轻量级的框架,完全面向Spring的批处理框架,用于企业级大量的数据读写处理系统。以POJO和Spring 框架为基础, 包括日志记录/跟踪,事务管理、 作业处理统计工作重新启动、跳过、资源管理等功能。
Spring Batch官网是这样介绍的自己:一款轻量的、全面的批处理框架,用于开发强大的日常运营的企业级批处理应用程序。
框架主要有以下功能:
- Transaction management(事务管理)
- Chunk based processing(基于块的处理)
- Declarative I/O(声明式的输入输出)
- Start/Stop/Restart(启动/停止/再启动)
- Retry/Skip(重试/跳过)
如果你的批处理程序需要使用上面的功能,那就大胆地使用它吧。
框架介绍
先用一个图让你有一个大概印象,这个东西是什么:
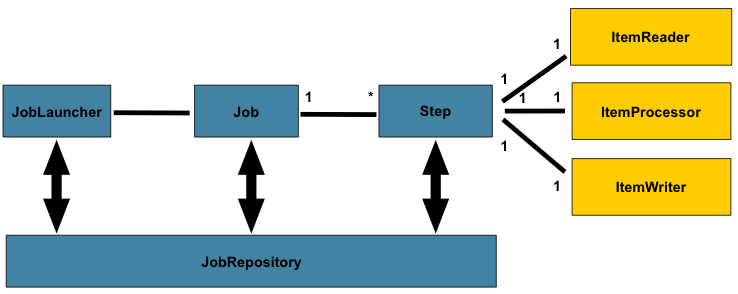
框架一共有5个主要角色:
- JobRepository是用户注册Job的容器,就是存储数据的地方,可以看做是一个数据库的接口,在任务执行的时候需要通过它来记录任务状态等等信息。
- JobLauncher是任务启动器,通过它来启动任务,可以看做是程序的入口。
- Job代表着一个具体的任务。
- Step代表着一个具体的步骤,一个Job可以包含多个Step(想象把大象放进冰箱这个任务需要多少个步骤你就明白了)。
- Item就是输出->处理->输出,一个完整Step流程。
下面简要的介绍一下这5个角色
JobRepository
JobRepository用于存储任务执行的状态信息,比如什么时间点执行了什么任务、任务执行结果如何等等。 框架提供了2种实现,一种是通过Map形式保存在内存中,当Java程序重启后任务信息也就丢失了, 并且在分布式下无法获取其他节点的任务执行情况;另一种是保存在数据库中,并且将数据保存在下面6张表里:
- BATCH_JOB_INSTANCE
- BATCH_JOB_EXECUTION_PARAMS
- BATCH_JOB_EXECUTION
- BATCH_STEP_EXECUTION
- BATCH_JOB_EXECUTION_CONTEXT
- BATCH_STEP_EXECUTION_CONTEXT
Spring Batch框架的JobRepository支持主流的数据库:DB2、Derby、H2、HSQLDB、MySQL、Oracle、PostgreSQL、SQLServer、Sybase。
JobLauncher
JobLauncher是任务启动器,该接口只有一个run方法:
public interface JobLauncher {
JobExecution run(Job job, JobParameters jobParameters);
}
除了传入Job对象之外,还需要传入JobParameters对象,后续讲到Job再解释为什么要多传一个JobParameters。 通过JobLauncher可以在Java程序中调用批处理任务,也可以通过命令行或者其他框架 (如定时调度框架Quartz、Web后台框架Spring MVC)中调用批处理任务。 Spring Batch框架提供了一个JobLauncher的实现类SimpleJobLauncher。
Job
Job代表着一个任务,一个Job与一个或者多个JobInstance相关联,而一个JobInstance又与一个或者多个JobExecution相关联:
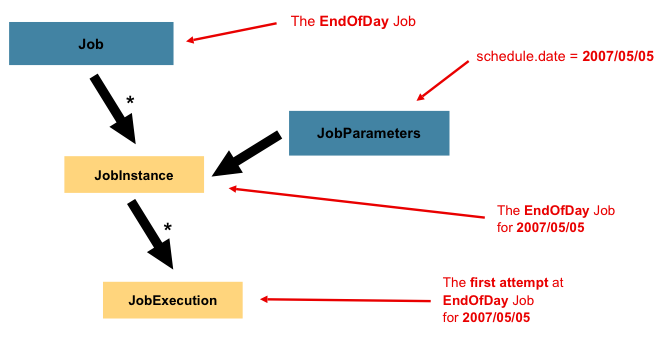
考虑到任务可能不是只执行一次就再也不执行了,更多的情况可能是定时任务,如每天执行一次,每个星期执行一次等等, 那么为了区分每次执行的任务,框架使用了JobInstance。如上图所示,Job是一个EndOfDay(每天最后时刻执行的任务), 那么其中一个JobInstance就代表着2007年5月5日那天执行的任务实例。 框架通过在执行JobLauncher.run(Job, JobParameters)方法时传入的JobParameters来区分是哪一天的任务。
由于2007年5月5日那天执行的任务可能不会一次就执行完成,比如中途被停止,或者出现异常导致中断, 需要多执行几次才能完成,所以框架使用了JobExecution来表示每次执行的任务。
Step
一个Job任务可以分为几个Step步骤,与JobExection相同,每次执行Step的时候使用StepExecution来表示执行的步骤。 每一个Step还包含着一个ItemReader、ItemProcessor、ItemWriter,下面分别介绍这三者。
ItemReader
ItemReader代表着读操作,其接口如下:
public interface ItemReader<T> {
T read();
}
框架已经提供了多种ItemReader接口的实现类,包括对文本文件、CSV文件、XML文件、数据库、JMS消息等读的处理,当然我们也可以自己实现该接口。
ItemProcessor
ItemReader代表着处理操作,其接口如下:
public interface ItemProcessor<I, O> {
O process(I item) throws Exception;
}
process方法的形参传入I类型的对象,通过处理后返回O型的对象。开发者可以实现自己的业务代码来对数据进行处理。
ItemWriter
ItemReader代表着写操作,其接口如下:
public interface ItemWriter<T> {
void write(List<? extends T> items) throws Exception;
}
框架已经提供了多种ItemWriter接口的实现类,包括对文本文件、CSV文件、XML文件、数据库、JMS消息等写的处理,当然我们也可以自己实现该接口。
Job监听器
还可以自定义任务监听器,在任务启动和完成之后进行相应的通知和响应。
/**
* 监听器实现JobExecutionListener接口,并重写其beforeJob,afterJob方法即可
*/
public class MyJobListener implements JobExecutionListener {
@Override
public void beforeJob(JobExecution jobExecution) {
}
@Override
public void afterJob(JobExecution jobExecution) {
}
}
数据校验
我们可以JSR-303(主要实现由hibernate-validator)的注解,来校验ItemReader读取到的数据是否满足要求。
首先让我们的ItemProcessor实现ValidatingItemProcessor接口:
public class MyItemProcessor extends ValidatingItemProcessor<User> {
@Override
public User process(User item) throws ValidationException {
super.process(item);
return item;
}
}
然后定义自己的校验器,实现的Validator接口来自于Spring,我们将使用JSR-303的Validator来校验:
public class MyBeanValidator<T> implements Validator<T>,InitializingBean {
private Validator validator;
@Override
public void afterPropertiesSet() throws Exception {
}
@Override
public void validate(T value)throws ValidationException{
}
}
在定义我们的MyItemProcessor时必须将MyBeanValidator设置进去,代码如下:
@Bean
public ItemProcessor<User,User> processor(){
//新建ItemProcessor接口的实现类返回
MyItemProcessor processor = new MyItemProcessor();
processor.setValidator(myBeanValidator());
return processor;
}
@Bean
public Validator<User> myBeanValidator(){
return new MyBeanValidator<User>();
}
SpringBoot集成实例
Spring Boot对Spring Batch支持的源码位于 org.springframework.boot.autoconfigure.batch 下。
Spring Boot为我们自动初始化了Spring Batch存储批处理记录的数据库,且当我们程序启动时, 会自动执行我们定义的Job的Bean,不过我们可以通过配置定时器或手动触发方式启动。
Spring Boot提供如下属性来定制Spring Batch:
#启动时要执行的job,默认执行全部job spring.batch.job.name=job1,job2 #是否自动执行定义的job,默认是 spring.batch.job.enabled=true #是否初始化Spring Batch的数据库,默认为是 spring.batch.initializer.enabled=true spring.batch.schema= #设置Spring Batch的数据库表的前缀 spring.batch.table-prefix=
下面通过一个真实的例子,需要将客户导过来的csv文件导入到我们的业务Oracle数据库中,来说明怎样在SpringBoot中使用批处理框架。
添加maven依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
<exclusions>
<exclusion>
<groupId>org.hsqldb</groupId>
<artifactId>hsqldb</artifactId>
</exclusion>
</exclusions>
</dependency>
<!--添加hibernate-validator依赖,作为数据校验使用-->
<dependency>
<groupId>org.hibernate.validator</groupId>
<artifactId>hibernate-validator</artifactId>
<version>6.0.7.Final</version>
</dependency>
<dependency>
<groupId>javax.validation</groupId>
<artifactId>validation-api</artifactId>
<version>2.0.1.Final</version>
</dependency>
<dependency>
<groupId>javax.el</groupId>
<artifactId>javax.el-api</artifactId>
<version>3.0.1-b04</version>
</dependency>
<dependency>
<groupId>org.glassfish.web</groupId>
<artifactId>javax.el</artifactId>
<version>2.2.6</version>
</dependency>
<!--添加hibernate-validator依赖 END-->
<!-- Oracle驱动包 -->
<dependency>
<groupId>com.oracle</groupId>
<artifactId>ojdbc6</artifactId>
<version>11.2.0.4.0-atlassian-hosted</version>
</dependency>
配置application.yml
################### spring配置 ###################
spring:
profiles:
active: dev
batch:
job:
enabled: false
datasource:
driver-class-name: oracle.jdbc.driver.OracleDriver
url: jdbc:oracle:thin:@xxx.xxx.xxx.xxx:1521:orcl11g
username: adm_real
password: adm_real
真实csv数据,位于 src/main/resources/NT_BSC_BUDGETVTOLL.csv 中
表定义如下:
CREATE TABLE "ADM_REAL"."NT_BSC_BUDGETVTOLL" (
"F_ID" VARCHAR2(100 BYTE) NOT NULL ,
"F_YEAR" VARCHAR2(4 BYTE) NULL ,
"F_TOLLID" VARCHAR2(50 BYTE) NULL ,
"F_BUDGETID" VARCHAR2(50 BYTE) NULL ,
"F_CBUDGETID" VARCHAR2(50 BYTE) NULL ,
"F_VERSION" VARCHAR2(1 BYTE) DEFAULT '1' NULL ,
"F_AUDITMSG" VARCHAR2(100 BYTE) NULL ,
"F_TRIALSTATUS" VARCHAR2(1 BYTE) DEFAULT '0' NULL ,
"F_FIRAUDITER" VARCHAR2(50 BYTE) NULL ,
"F_FIRAUDITTIME" VARCHAR2(20 BYTE) NULL ,
"F_FINAUDITER" VARCHAR2(50 BYTE) NULL ,
"F_FINAUDITTIME" VARCHAR2(64 BYTE) NULL ,
"F_EDITTIME" VARCHAR2(64 BYTE) NULL ,
"F_STARTDATE" VARCHAR2(8 BYTE) NULL ,
"F_ENDDATE" VARCHAR2(8 BYTE) NULL ,
)
领域模型类
public class BudgetVtoll {
private String id;
private String year;
private String tollid;
private String budgetid;
private String cbudgetid;
private String version;
/**
* 使用JSR-303注解来校验数据
*/
@Size(max = 100)
private String auditmsg;
private String trialstatus;
private String firauditer;
private String firaudittime;
private String finauditer;
private String finaudittime;
private String edittime;
private String startdate;
private String enddate;
// 下面省略get/set方法
}
数据处理及校验
定义处理器
public class CsvItemProcessor extends ValidatingItemProcessor<BudgetVtoll> {
@Override
public BudgetVtoll process(BudgetVtoll item) throws ValidationException {
/*
* 需要执行super.process(item)才会调用自定义校验器
*/
super.process(item);
/*
* 对数据进行简单的处理和转换 todo
*/
return item;
}
}
校验器定义:
public class CsvBeanValidator<T> implements Validator<T>, InitializingBean {
private javax.validation.Validator validator;
@Override
public void validate(T value) throws ValidationException {
/*
* 使用Validator的validate方法校验数据
*/
Set<ConstraintViolation<T>> constraintViolations = validator.validate(value);
if (constraintViolations.size() > 0) {
StringBuilder message = new StringBuilder();
for (ConstraintViolation<T> constraintViolation : constraintViolations) {
message.append(constraintViolation.getMessage()).append("/n");
}
throw new ValidationException(message.toString());
}
}
/**
* 使用JSR-303的Validator来校验我们的数据,在此进行JSR-303的Validator的初始化
*/
@Override
public void afterPropertiesSet() {
ValidatorFactory validatorFactory = Validation.buildDefaultValidatorFactory();
validator = validatorFactory.usingContext().getValidator();
}
}
任务监听器
public class CsvJobListener implements JobExecutionListener {
private Logger logger = LoggerFactory.getLogger(this.getClass());
private long startTime;
private long endTime;
@Override
public void beforeJob(JobExecution jobExecution) {
startTime = System.currentTimeMillis();
logger.info("任务处理开始");
}
@Override
public void afterJob(JobExecution jobExecution) {
endTime = System.currentTimeMillis();
logger.info("任务处理结束,总耗时=" + (endTime - startTime) + "ms");
}
}
配置类
@Configuration
@EnableBatchProcessing
public class CsvBatchConfig {
/**
* ItemReader定义,用来读取数据
* 1,使用FlatFileItemReader读取文件
* 2,使用FlatFileItemReader的setResource方法设置csv文件的路径
* 3,对此对cvs文件的数据和领域模型类做对应映射
*
* @return FlatFileItemReader
*/
@Bean
@StepScope
public FlatFileItemReader<BudgetVtoll> reader(@Value("#{jobParameters['input.file.name']}") String pathToFile) {
FlatFileItemReader<BudgetVtoll> reader = new FlatFileItemReader<>();
// reader.setResource(new ClassPathResource(pathToFile));
reader.setResource(new FileSystemResource(pathToFile));
reader.setLineMapper(new DefaultLineMapper<BudgetVtoll>() {
{
setLineTokenizer(new DelimitedLineTokenizer(",") {
{
setNames(new String[]{
"id","year","tollid","budgetid", "cbudgetid", "version", "auditmsg", "trialstatus",
"firauditer", "firaudittime", "finauditer", "finaudittime", "edittime", "startdate", "enddate"
});
}
});
setFieldSetMapper(new BeanWrapperFieldSetMapper<BudgetVtoll>() {{
setTargetType(BudgetVtoll.class);
}});
}
});
return reader;
}
/**
* ItemProcessor定义,用来处理数据
*
* @return
*/
@Bean
public ItemProcessor<BudgetVtoll, BudgetVtoll> processor() {
//使用我们自定义的ItemProcessor的实现CsvItemProcessor
CsvItemProcessor processor = new CsvItemProcessor();
//为processor指定校验器为CsvBeanValidator()
processor.setValidator(csvBeanValidator());
return processor;
}
/**
* ItemWriter定义,用来输出数据
* spring能让容器中已有的Bean以参数的形式注入,Spring Boot已经为我们定义了dataSource
*
* @param dataSource
* @return
*/
@Bean
public ItemWriter<BudgetVtoll> writer(DruidDataSource dataSource) {
JdbcBatchItemWriter<BudgetVtoll> writer = new JdbcBatchItemWriter<>();
//我们使用JDBC批处理的JdbcBatchItemWriter来写数据到数据库
writer.setItemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>());
String sql = "insert into BudgetVtoll " + " (f_id,f_year,f_tollid,f_budgetid,f_cbudgetid,f_version,f_auditmsg,f_trialstatus,f_firauditer,f_firaudittime,f_finauditer,f_finaudittime,f_edittime,f_startdate,f_enddate) "
+ " values(:id,:year,:tollid,:budgetid,:cbudgetid,:version,:auditmsg,:trialstatus,:firauditer,:firaudittime,:finauditer,:finaudittime,:edittime,:startdate,:enddate)";
//在此设置要执行批处理的SQL语句
writer.setSql(sql);
writer.setDataSource(dataSource);
return writer;
}
/**
* JobRepository,用来注册Job的容器
* jobRepositor的定义需要dataSource和transactionManager,Spring Boot已为我们自动配置了
* 这两个类,Spring可通过方法注入已有的Bean
*
* @param dataSource
* @param transactionManager
* @return
* @throws Exception
*/
@Bean
public JobRepository jobRepository(DruidDataSource dataSource, PlatformTransactionManager transactionManager) throws Exception {
JobRepositoryFactoryBean jobRepositoryFactoryBean = new JobRepositoryFactoryBean();
jobRepositoryFactoryBean.setDataSource(dataSource);
jobRepositoryFactoryBean.setTransactionManager(transactionManager);
jobRepositoryFactoryBean.setDatabaseType(String.valueOf(DatabaseType.ORACLE));
// 下面事务隔离级别的配置是针对Oracle的
jobRepositoryFactoryBean.setIsolationLevelForCreate("ISOLATION_READ_COMMITTED");
jobRepositoryFactoryBean.afterPropertiesSet();
return jobRepositoryFactoryBean.getObject();
}
/**
* JobLauncher定义,用来启动Job的接口
*
* @param dataSource
* @param transactionManager
* @return
* @throws Exception
*/
@Bean
public SimpleJobLauncher jobLauncher(DruidDataSource dataSource, PlatformTransactionManager transactionManager) throws Exception {
SimpleJobLauncher jobLauncher = new SimpleJobLauncher();
jobLauncher.setJobRepository(jobRepository(dataSource, transactionManager));
return jobLauncher;
}
/**
* Job定义,我们要实际执行的任务,包含一个或多个Step
*
* @param jobBuilderFactory
* @param s1
* @return
*/
@Bean
public Job importJob(JobBuilderFactory jobBuilderFactory, Step s1) {
return jobBuilderFactory.get("importJob")
.incrementer(new RunIdIncrementer())
.flow(s1)//为Job指定Step
.end()
.listener(csvJobListener())//绑定监听器csvJobListener
.build();
}
/**
* step步骤,包含ItemReader,ItemProcessor和ItemWriter
*
* @param stepBuilderFactory
* @param reader
* @param writer
* @param processor
* @return
*/
@Bean
public Step step1(StepBuilderFactory stepBuilderFactory, ItemReader<BudgetVtoll> reader, ItemWriter<BudgetVtoll> writer,
ItemProcessor<BudgetVtoll, BudgetVtoll> processor) {
return stepBuilderFactory
.get("step1")
.<BudgetVtoll, BudgetVtoll>chunk(65000)//批处理每次提交65000条数据
.reader(reader)//给step绑定reader
.processor(processor)//给step绑定processor
.writer(writer)//给step绑定writer
.build();
}
@Bean
public CsvJobListener csvJobListener() {
return new CsvJobListener();
}
@Bean
public Validator<BudgetVtoll> csvBeanValidator() {
return new MyBeanValidator<>();
}
}
注意,在定义Job的时候,我通过 @StepScope 注解,可以通过传递参数的方式将csv文件路径传进去。
测试类
最后再让我们写个测试类看看能不能成功:
@RunWith(SpringRunner.class)
@SpringBootTest(classes = Application.class)
public class BatchServiceTest {
private Logger logger = LoggerFactory.getLogger(this.getClass());
@Autowired
private JobLauncher jobLauncher;
@Autowired
private Job importJob;
@Test
public void testBatch1() throws Exception {
JobParameters jobParameters = new JobParametersBuilder()
.addLong("time", System.currentTimeMillis())
.addString("input.file.name", "E://NT_BSC_BUDGETVTOLL.csv")
.toJobParameters();
jobLauncher.run(importJob, jobParameters);
logger.info("testBatch1执行完成");
}
}
把csv文件放入resources/目录下面,然后执行测试。看看输出结果:
: Job: [FlowJob: [name=importJob]] launched with the following parameters: [{time=1517654976174, input.file.name=E:/NT_BSC_BUDGETVTOLL.csv}]
: 任务处理开始
: Executing step: [step1]
: 任务处理结束,总耗时=810ms
: Job: [FlowJob: [name=importJob]] completed with the following parameters: [{time=1517654976174, input.file.name=E:/NT_BSC_BUDGETVTOLL.csv}] and the following status: [COMPLETED]
: testBatch1执行完成
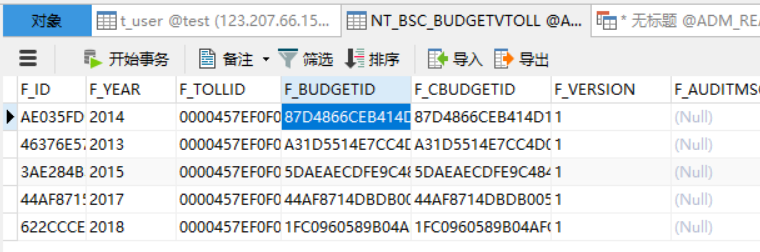
再去查看数据库里面的数据,已经正常写入了。
并发执行多个Job
SpringBatch批处理框架默认使用单线程完成所有任务的执行,官方推荐配置任务执行器来并发执行, 提高批处理的效率。
Spring Core 为我们提供了多种执行器实现(包括多种异步执行器),我们可以根据实际情况灵活选择使用。
| 类名 | 描述 | 是否异步 |
|---|---|---|
| SyncTaskExecutor | 简单同步执行器 | 否 |
| SimpleAsyncTaskExecutor | 简单异步执行器,提供最基本的异步实现 | 是 |
| WorkManagerTaskExecutor | 该类作为通过 JCA 规范进行任务执行的实现 | 是 |
| ThreadPoolTaskExecutor | 线程池任务执行器 | 是 |
配置线程池执行Job:
@Bean
public ThreadPoolTaskExecutor taskExecutor() {
ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor();
taskExecutor.setCorePoolSize(5);
taskExecutor.setMaxPoolSize(10);
taskExecutor.setQueueCapacity(200);
return taskExecutor;
}
@Bean
public SimpleJobLauncher jobLauncher(ThreadPoolTaskExecutor taskExecutor, DruidDataSource dataSource,
PlatformTransactionManager transactionManager) throws Exception {
SimpleJobLauncher jobLauncher = new SimpleJobLauncher();
jobLauncher.setTaskExecutor(taskExecutor);
jobLauncher.setJobRepository(jobRepository(dataSource, transactionManager));
return jobLauncher;
}
重点是上面的那句 jobLauncher.setTaskExecutor(taskExecutor);
这里的并发表示的是执行不同的Job使用线程池,每个Job实例会分配一个线程去执行。这个是最推荐的做法。
如果你还想对单个Job执行逻辑采用多线程,可以再Step配置中加入线程池支持,不过需要保证你所有的Step都是线程安全的:
return stepBuilderFactory
.get("logStep1")
//设置每个Job通过并发方式执行,一般来讲一个Job就让它串行完成的好
.taskExecutor(new SimpleAsyncTaskExecutor())
//并发任务数为 10,默认为4
.throttleLimit(10)
.build();
这里我通过一个实际例子展示如何编写多个Job并发执行。
还是跟上面例子一样,将csv文件导入到表中,但是这个时候有两个csv文件,我要导入到两张表。
CREATE TABLE Z_TEST_APP (
appid INT,
zname VARCHAR2 (20),
flag VARCHAR2 (2),
CONSTRAINT app_pk PRIMARY KEY (appid)
);
CREATE TABLE Z_TEST_LOG (
logid INT,
msg VARCHAR2 (20),
logtime VARCHAR2 (8),
CONSTRAINT log_pk PRIMARY KEY (logid)
);
每个类型任务单独创建一个package,然后里面放两个类。以APP为例:
创建一个App类:
public class App {
private int appid;
private String zname;
private String flag;
}
然后创建一个AppConfig类配置任务:
@Configuration
public class AppConfig {
/**
* ItemReader定义,用来读取数据
* 1,使用FlatFileItemReader读取文件
* 2,使用FlatFileItemReader的setResource方法设置csv文件的路径
* 3,对此对cvs文件的数据和领域模型类做对应映射
*
* @return FlatFileItemReader
*/
@Bean(name = "appReader")
@StepScope
public FlatFileItemReader<App> reader(@Value("#{jobParameters['input.file.name']}") String pathToFile) {
FlatFileItemReader<App> reader = new FlatFileItemReader<>();
reader.setResource(new FileSystemResource(pathToFile));
reader.setLineMapper(new DefaultLineMapper<App>() {
{
setLineTokenizer(new DelimitedLineTokenizer("|") {
{
setNames(new String[]{
"appid", "zname", "flag"
});
}
});
setFieldSetMapper(new BeanWrapperFieldSetMapper<App>() {{
setTargetType(App.class);
}});
}
});
return reader;
}
// ....后面省略
}
注意,每个Bean配置都加一个name属性,然后自动注入里面需要通过@Qualifier注解来指定当前类中的Bean, 因为如果不指定name,Spring默认只会初始化一个Bean实例。
比如定义Job:
@Bean(name = "zappJob")
public Job zappJob(JobBuilderFactory jobBuilderFactory, @Qualifier("zappStep1") Step s1) {
return jobBuilderFactory.get("zappJob")
.incrementer(new RunIdIncrementer())
.flow(s1)//为Job指定Step
.end()
.listener(new MyJobListener("App"))//绑定监听器csvJobListener
.build();
}
另外一个LOG任务的配置也是同样。
好了,定义完成之后开始写测试方法:
@Test
public void testTwoJobs() throws Exception {
JobParameters jobParameters1 = new JobParametersBuilder()
.addLong("time", System.currentTimeMillis())
.addString("input.file.name", p.getCsvApp())
.toJobParameters();
jobLauncher.run(zappJob, jobParameters1);
JobParameters jobParameters2 = new JobParametersBuilder()
.addLong("time", System.currentTimeMillis())
.addString("input.file.name", p.getCsvLog())
.toJobParameters();
jobLauncher.run(zlogJob, jobParameters2);
logger.info("main线程完成");
while (true) {
Thread.sleep(2000000L);
}
}
这个是运行日志:
[ taskExecutor-1] o.s.b.c.l.support.SimpleJobLauncher : Job: [FlowJob: [name=zappJob]] launched with t [ taskExecutor-1] com.xncoding.trans.modules.MyJobListener : 任务-App处理开始 [ main] com.xncoding.service.BatchServiceTest : main线程完成 [ taskExecutor-2] o.s.b.c.l.support.SimpleJobLauncher : Job: [FlowJob: [name=zlogJob]] launched with t [ taskExecutor-2] com.xncoding.trans.modules.MyJobListener : 任务-Log处理开始 [ taskExecutor-1] o.s.batch.core.job.SimpleStepHandler : Executing step: [zappStep1] [ taskExecutor-2] o.s.batch.core.job.SimpleStepHandler : Executing step: [logStep1] [ taskExecutor-2] com.xncoding.trans.modules.MyJobListener : 任务-Log处理结束,总耗时=495ms [ taskExecutor-1] com.xncoding.trans.modules.MyJobListener : 任务-App处理结束,总耗时=585ms [ taskExecutor-2] o.s.b.c.l.support.SimpleJobLauncher : Job: [FlowJob: [name=zlogJob]] completed with [ taskExecutor-1] o.s.b.c.l.support.SimpleJobLauncher : Job: [FlowJob: [name=zappJob]] completed with
异常处理
默认情况下,Spring Batch遇到异常的时候会终止处理,比如遇到csv文件中解析错误就会终止异常。如果我想忽略掉这些异常继续处理, 可以配置在Reader中忽略异常。
这个在Step的定义中配置:
return stepBuilderFactory
.get("logStep1")
.<Log, Log>chunk(5000)//批处理每次提交5000条数据
.reader(reader)//给step绑定reader
.processor(processor)//给step绑定processor
.writer(writer)//给step绑定writer
.faultTolerant()
.retry(Exception.class) // 重试
.noRetry(ParseException.class)
.retryLimit(1) //每条记录重试一次
.skip(Exception.class)
.skipLimit(200) //一共允许跳过200次异常
// .taskExecutor(new SimpleAsyncTaskExecutor()) //设置每个Job通过并发方式执行,一般来讲一个Job就让它串行完成的好
// .throttleLimit(10) //并发任务数为 10,默认为4
.build();
上面定义了使用可容忍异常模式,遇到Exception异常就重试1次,对于ParseException异常不重试,所有异常都会忽略掉,不会导致程序终止。 但是最大允许跳过200次异常,超过这个数字就终止执行了。
然后改一下csv文件,把某个字段改大点,超过数据库中定义长度:
1|等哈哈哈|01 2|等哈哈哈|02 3|等哈哈哈|025555 4|等哈哈哈|02 5|等哈哈哈|02
重新执行发现正常执行完成,数据库中只插入了4条数据,id为3的没有。
通用配置
更进一步,如果有多个CSV文件需要导入,那么安装上面的写法。每次都要定义一个新的Config类,一个新的Bean类,代码重复率很高。
实际上可以定义一个通用配置,去掉里面的显示Bean类,通过Java反射机制,还有@StepScope注解, 实现每次运行时候根据JobParameters初始化不同的Job。
如果有一个新的CSV文件需要导入,只需要新建一个Bean,定义好相应的列,然后将Bean的属性列表、插入SQL语句作为参数传入即可。
测试代码:
/**
* 测试一个配置类,可同时运行多个任务
* @throws Exception 异常
*/
@Test
public void testCommonJobs() throws Exception {
JobParameters jobParameters1 = new JobParametersBuilder()
.addLong("time",System.currentTimeMillis())
.addString(KEY_JOB_NAME, "App")
.addString(KEY_FILE_NAME, p.getCsvApp())
.addString(KEY_VO_NAME, "com.xncoding.trans.modules.zapp.App")
.addString(KEY_COLUMNS, String.join(",", new String[]{
"appid", "zname", "flag"
}))
.addString(KEY_SQL, "insert into z_test_App (appid, zname, flag) values(:appid, :zname, :flag)")
.toJobParameters();
jobLauncher.run(commonJob, jobParameters1);
JobParameters jobParameters2 = new JobParametersBuilder()
.addLong("time",System.currentTimeMillis())
.addString(KEY_JOB_NAME, "Log")
.addString(KEY_FILE_NAME, p.getCsvLog())
.addString(KEY_VO_NAME, "com.xncoding.trans.modules.zlog.Log")
.addString(KEY_COLUMNS, String.join(",", new String[]{
"logid", "msg", "logtime"
}))
.addString(KEY_SQL, "insert into z_test_Log (logid, msg, logtime) values(:logid, :msg, :logtime)")
.toJobParameters();
jobLauncher.run(commonJob, jobParameters2);
logger.info("Main线程执行完成");
while (true) {
Thread.sleep(2000000L);
}
}
FAQ
在进行Oracle操作的时候报一个错误:
ORA-08177: 无法连续访问此事务处理
原因:Spring Batch 默认是 ISOLATION_SERIALIZABLE
官方文档说明:
The default is ISOLATION_SERIALIZABLE, which prevents accidental concurrent execution of the same job (ISOLATION_REPEATABLE_READ would work as well).
而Oracle默认的事务隔离级别是ISOLATION_READ_COMMITTED
解决方案就是修改 JobRepositoryFactoryBean 的定义,加一个配置:
jobRepositoryFactoryBean.setIsolationLevelForCreate("ISOLATION_READ_COMMITTED");
正文到此结束
- 本文标签: 开发 src ACE JMS ORM springboot web db tar 安装 API parse 参数 build Word FAQ bean validator java db2 map 管理 解析 REST schema http 监听器 Service 分布式 spring cvs js sql NSA HTML list dataSource ask 线程池 Action Spring Boot 目录 tab https 安全 IDE App value 企业 运营 Jobs Property id mysql 源码 git cat 数据 CTO key 同步 DDL Job 处理器 IO classpath ip 线程 开发者 时间 provider 统计 Quartz queue executor token 测试 数据库 UI 代码 XML final core Spring Batch message mapper 模型 定制 maven Oracle 配置 多线程 实例
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

