高铁人脸识别能抓逃犯吗?
如今人脸识别系统已经广泛应用于我们的生活中,如数码相机、门禁系统、机场的安全设施 、桌面软件、互联网应用(如Facebook)等等[1]。然而今日的一则关于“高铁人脸识别抓逃犯”的新闻一出[2],在评论中又引发了一阵阵怀疑。怀疑的中心问题在于,人脸识别系统真的能准确无误地在数以亿计的面孔中找出匹配的嫌疑人吗?
降维:减少冗余信息
完整的人脸识别系统一般由多个模块组成,在进行人脸识别之前首先要进行人脸检测(即在一张完整的图片中探测到人脸区域),以及图片的预处理、归一化等步骤(例如自动把倾斜的照片摆正)。本文就来介绍一下人脸识别的过程。(至于人脸检测的问题留待以后再议,就看评论中群众的呼声了。)
我们知道数码图片的基本表示方式是位图(bitmap)。一张大小 360x480 的黑白照片,每个像素点的取值范围是 0-255 之间的整数,通过简单的乘法原理可以算出,它可能产生 256 172800 种不同的照片。然而在这个天文数字的可能性中,不可能每一张照片都是人脸。事实上,符合正常人类脸部特征的照片只占这些可能性中极小的一部分。也就是说,如果以这样的方式表示图片,并且每张图片都是人脸的话,那么信息就是极其冗余的:位图用了 172800 个像素——也可以称为 172800 个特征——来表示一张人脸图片。由于人脸的规律性,我们其实可以用很少量的特征来表示,比如20个、50个、或100个。当然,如果我们只用20、50、100个特征表示人脸,这里的每个特征的意义就不再是一个像素点了。
上一段其实解释了数据挖掘中一个很重要的概念——降维(dimension reduction)。用数学的语言来说,人脸识别中最主要的工作就是把这些 172800 维空间中的向量转换为 20、50、100 维空间中的一组向量。这样转换的好处是什么呢?下面我们用一个具体例子来说明。
主成分分析:提取有代表性的脸型轮廓
现在有 40 个人的人脸图片,每人 10 张,一共 400 张图片(ORL Database [3])。为简单起见,我们把这组图片降到5维,也就是只用 5 个特征来表示一张人脸图片。上面提到,如果只用5个特征,那每个特征本身就不能是一个像素点这么简单。那么这5个特征是什么呢?如下所示:
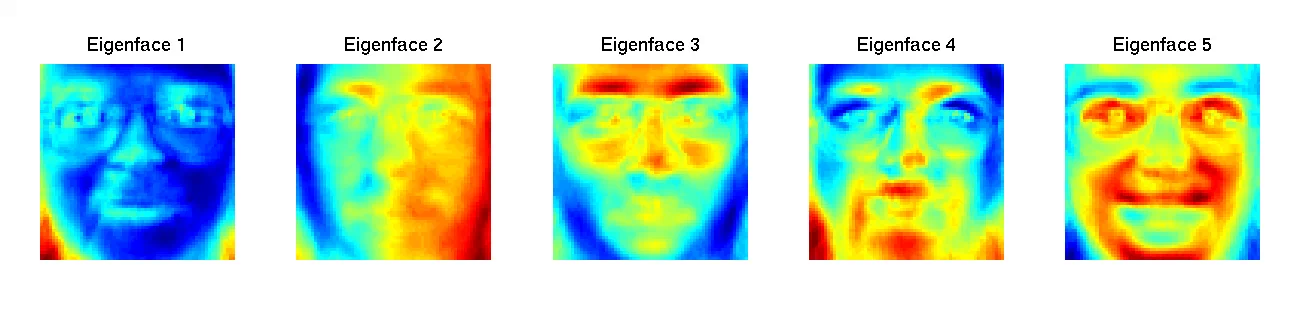
我们可以看到,这5个特征中的每一个都是一张酷似人脸轮廓的图片。OK,那么怎么用这 5 个特征表示一开始那400张人脸图片呢?我们用(线性)叠加的方式。假设(仅仅是假设)某张图片有这般组成:
原始图片 ≈ Eigenface1 ×0.1 +Eigenface2 ×0.3 +Eigenface3 ×(-0.7)+Eigenface4 ×0 +Eigenface5 ×2
那么这张图片就可以用(0.1,0.3,-0.7,0,2)这个向量(5维向量)表示。(这个公式中似乎有些奇怪的东西?看不懂没关系,我们后面再解释。)
到此为止我们用到的降维方法叫做主成分分析(PCA:Principle Component Analysis)[4],如果你用过任何数学软件或统计软件(如 Matlab、SPSS),里面肯定有这个功能。从字面意思上讲,通过把图片的表示从很高维的空间降到5维,我们提取出了这组人脸图片的“主要成分”(说白了就是人脸)。第一个特征(Eigenface1)刻画出了人脸最主要的构架,后面的几个特征(Eigenface2-5)再慢慢的细化。像素点可以称为低级(low-level)特征,相应地,“主要成分”可以成为高级(high-level)特征。同一个人的照片可以千变万化,为了实现人脸识别,我们当然不能一个一个像素点地去比对,而应该通过这些“主要成分”考察人脸图片是怎么构造/叠加出来的。不同的面孔有不同的构造方式,比如有的用 Eigenface2 的权重大一些,有的用 Eigenface3 的权重大一些,这样就实现了不同人面孔之间的区分。
关于上面的公式,我们还注意到以下两点:
1.左边和右边是约等号,也就是说,当我们用这 5 个特征以不同权重叠加起来,得到的是原始图片的一张近似图片。其实这就是生成这5个特征时采用的标准:用叠加的方式试图复原所有原始图片时产生的误差总和最小。虽然这里面有信息损失,但这5个特征反映出来的的确是400张图片里最关键的部分。如果需要,我们可以近似地把原始图片复原出来,比如这400张图片里的第一张:

2.每个特征有个奇怪的名字:Eigenface + 序号。如果你在大学学过线性代数并且到今天还没忘的话,或许你会联想到线性代数里的一个概念:特征向量和特征值(Eigenvector and Eigenvalue)。没错,这些 Eigenface(或许可以译作特征脸或本征脸)实际上就是原始图片协方差矩阵的特征向量(更多数学免去)。很奇妙吧?通过求特征向量就能做基本的人脸识别或文本分析,你是否也感到了数学之美?
堪比铁路网上订票系统?
当然,主成分分析用于实际中的人脸识别系统还是远远不够的。上世纪90年代的计算机科学家们又利用统计理论开发出了更好的方法,如线性判别分析(Linear/Fisher Discriminant Analysis)[6]。这是另一种降维方法,与主成分分析相比,同一个人的照片在转换后的低维空间中会更加紧凑,从而提高识别精度。跟 Eigenface 类似, 线性判别分析生成的特征也有一个名字,叫做费舍脸(Fisherface),以伟大的统计学家罗纳德•费舍(Ronald Fisher)命名。
实际场合中的人脸图片极为复杂,可能有各种姿势、表情,照相时的光线明暗和角度变换更加大了识别的难度。继 Eigenface 和 Fisherface 之后,人脸识别的研究成为计算机领域的热点之一,识别算法逐渐可以适应各种光线、角度或脸部本身的变化。例如下图是卡内基梅隆大学约10年前发布的人脸识别研究数据[7],可以看到同一个人照片呈现出的巨大差异。在这样复杂的环境中现有算法已经能达到大约95%的识别精度[8]。

万一哪个逃犯换了发型、戴了墨镜怎么办呢?比如有人说“我今年入关的时候,为了迷惑他们的识别系统,特意换上了黑框眼镜”,这样行得通吗?根据近年最新的研究[9],即使脸部有大面积遮挡(如下图),也能实现高精度的识别。但是这有个前提,就是说虽然每张图片都可以有所遮挡,但是人脸的每个部位必须在已有的数据中无遮挡的出现过至少一次。
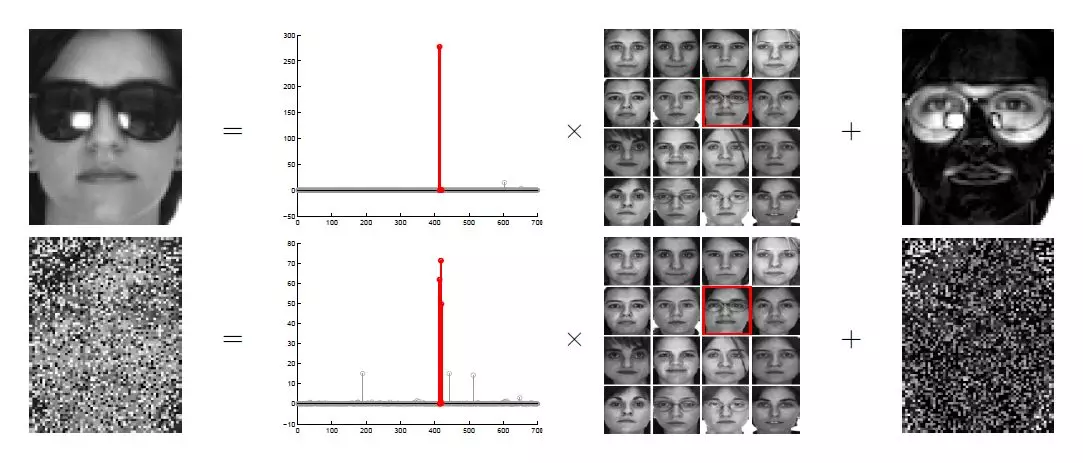
关于高铁新建人脸识别系统的新闻中还提到,“作案后的犯罪分子,即使整容,也能够被识别”。很多人的第一反应是“这也太不可思议了吧?整容之后肉眼都未必认得出来”,这话只说对了一半。的确,整容之后的人脸与整容之前有了很大区别 ,但是从另外一个角度上讲,相比于整容前后的区别,不同个体的脸部区别或许还要更大,而识别系统说到底是要找出相似度最大的人。依据脸部的骨架特点,整容是有限度的调整,而不是把一个人完全变成另一个人,只要不是真的把李小璐整成范冰冰的样子,算法还是有可能识别出来的。
如果上面的内容你都理解了,那么恭喜你已经对当今最先进的人脸识别技术或许有了大致的认识。人脸识别系统是否能准确无误地识别出逃犯,现在还不好说,特别是对于我们这样有着十几亿人口的国家,因为目前任何识别系统应该都没有处理/索引过如此大量的不同个体。高铁新安装的逃犯识别系统效果如何,就像铁路网上订票系统一样,还得通过实践的检验。
(作者: 邝冬晨 来源:超级数学建模)

永安期货资管倾力打造
——程序化交易高级培训班
本次培训班优秀的学员可推荐加入永安期货资产管理团队。
(点击下面的阅读原文查看详情)
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

