主流大数据系统在后台的层次角色及数据流向
最近有不少质疑大数据的声音,这些质疑有一定的道理,但结论有些以偏概全,应该具体问题具体分析。对大数据的疑问和抗拒往往是因为对其不了解,需要真正了解之后才能得出比较客观的结论。
大数据是一个比较宽泛的概念,它包含大数据存储和大数据计算,其中大数据计算可大致分为计算逻辑相对简单的大数据统计,以及计算逻辑相对复杂的大数据预测。下面分别就以上三个领域简要分析一下:第一,大数据存储解决了大数据技术中的首要问题,即海量数据首先要能保存下来,才能有后续的处理。因此大数据存储的重要性是毫无疑问的。第二,大数据统计是对海量数据的分析统计和轻度挖掘,例如统计海量用户产品的日/月活跃度、用户基于地区的分布、用户历史操作、运营侧数据指标等,这些需要大数据计算平台的支持才能实现,对于拥有海量用户的互联网公司来说是不可或缺的技术。第三,大数据预测领域才是争议最多的领域。事实上,预测必有误差、必有小概率事件,大数据预测的背后是各种机器学习/模式识别等深度挖掘算法,这些算法只是工具而已,用得好不好、恰不恰当还是要看应用的领域和使用者本身的能力。就像C++语言这个工具,适合做后台开发,不适合做网页前端,有C++编程很牛的程序员,也有编程很差的程序员,不能因为存在编程差的程序员而否定C++。此外,大数据预测想要做到精准,门槛非常高,所以有很多声称使用大数据预测的产品,实际效果往往不佳,给人们造成了大数据预测普遍不行的印象。由于门槛高,真正能掌握大数据预测能力,做到精准的,目前只有很少数产品。
综上所述,大数据存储和大数据统计是海量用户产品不可或缺的技术,而对于大数据预测技术,小概率事件必然出现,且并不是每个人都能运用得好。所以不能笼统地说大数据没有用处,要看具体领域,以及产品背后的团队。
大数据经过最近几年的发展,它的基础设施——各个大数据存储和计算平台已经比较成熟,业界主流的大数据平台在后台的层次角色一般如下图所示:
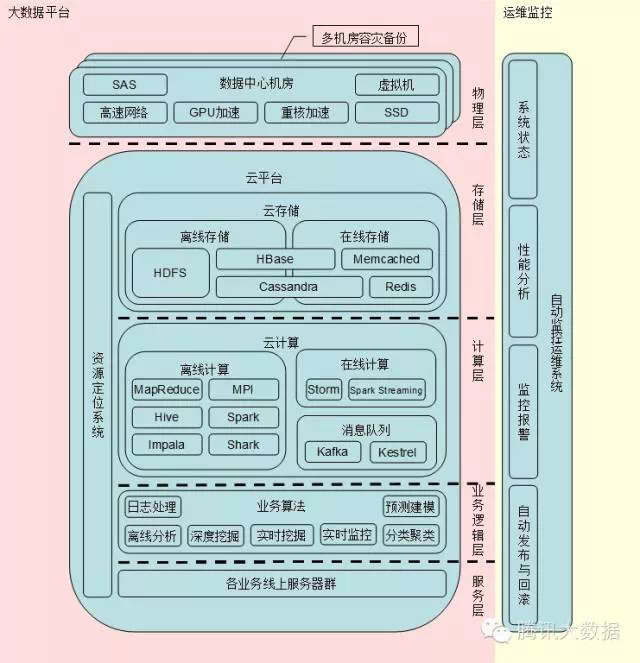
在物理层,根据不同的使用场景以及成本预算的考虑,会采用不同的硬件配置方案。对于自身容错备份机制较好的大存储系统,只需使用SATA硬盘即可;若所承载的平台自身容灾机制较弱甚至是无,且数据比较重要,则可以使用RAID或者SAS硬盘。对于大部分存储和计算平台来说,网络一般不是最大的瓶颈,所以使用千兆网卡和交换机即可;对于内部网络吞吐量非常大,内部网络IO已经成为瓶颈,并且时效性要求非常高的核心业务,可以使用万兆网卡和交换机提高性能。在计算性能上,近年来逐步兴起与成熟的语音识别技术和深度学习技术,由于计算量异常巨大,需要依靠GPU加速或者是重核卡的加速才能在可容忍的时间内完成计算,业界不少的专用集群都配备了GPU或是重核卡。随着SSD的成本不断下降,它成为对硬盘IO性能有高要求的应用非常有吸引力的选择。为了充分复用服务器的资源,将其空闲部分继续加以利用,虚拟机技术成为了有效的解决方案;同时虚拟机的资源隔离机制,使得服务器的资源分配可以达到更精细的粒度,从而使资源分配更加合理和高效。业界不少大数据平台,都搭建在了虚拟机集群之上。此外,为了保证服务的高可用性,防止机架、机房甚至是城市的网络、电源故障等突发灾情,重要的业务需要进行多机房、多城市的容灾部署。
在软件层面上,第一层首先是云存储层。按时效性划分,各个大数据存储平台一般分为离线存储和在线存储两种类型。离线存储用来对超大规模数据(一般PB以上)进行持久性存储,适用于数据访问响应时间要求低(秒级以上)的场景。在主流平台里最典型的就是hadoop的HDFS。在线存储用来对海量数据进行实时的访问,适用于在线服务场景或者是对数据访问响应时间有高要求的计算任务提供支持的场景。在线存储不一定需要对数据进行持久化,同时它既可以是原始数据,也可以只是缓存的数据。在主流的平台里,Memcached是一个分布式内存缓存系统,不提供持久化。Redis与Memcached类似,但是它提供了持久化能力及主从同步能力,所支持的数据类型和操作更加丰富。以上两者是典型的缓存系统,在中等数据规模下表现较好,对于更大数据规模就会比较吃力,这时就需要使用HBase或者Cassandra等支持实时场景的大容量存储系统。同时,由于HBase和Cassandra支持超大规模数据的持久化存储,它们也可以用在离线存储领域。
大数据的计算层平台按照时效性划分,也分为离线计算和在线计算(或叫实时计算)两种类型,而各个计算间的数据传递工作一部分由存储系统完成,另一部分由数据管道系统(如消息队列系统等)完成。离线计算平台通常用来处理数据量巨大,耗时长的计算任务,适用于对大量数据的统计分析和深度挖掘。典型的离线计算平台有:作为通用并行计算模型的hadoop MapReduce、Spark;高性能并行计算的MPI;数据仓库式计算的Hive、Impala、Shark;图模型计算的Pregel、Bagel、GraphX等。在线计算/实时计算平台通常用来处理流式数据,适用于计算量一般较轻,且时效性需求高或永不间断的计算场景。常见的实时计算平台有:Storm、S4、Spark Streaming等。消息队列平台一般用于上下游计算的数据衔接,特别是时效性要求较高的计算流程,每个计算步骤的输出结果写入消息队列平台后,下游计算可立即感知并启动计算,缩短反应时间。业界用得较多的平台包括轻量级的Kestrel,以及重量级、容错性好的Kafka。
业务逻辑层承载着各个业务具体的计算逻辑,一般来说有日志处理、离线分析、深度挖掘、分类聚类、预测建模等离线业务,也有实时挖掘、实时监控等实时处理业务。
最外的服务层就是直接对外提供服务的各个业务的线上服务器集群。
位于后台的各个大数据平台,为了容灾、资源复用、例行维护的考虑,其服务访问入口可能会发生变化,因此往往需要一个资源定位系统来获取各个平台当前最新的服务访问入口。通过资源定位系统提供的自动定位服务能力,各个平台服务接口的迁移就可以对使用者透明。
在大数据各平台的整体层次结构中,最不可或缺的配套系统就是自动监控运维系统。海量数据的处理,对存储和计算的压力都是非常巨大的,所以各个平台出现硬件异常和软件异常的概率急速上升,因此需要一套自动监控运维系统来不断监控各个服务器的硬件状况,操作系统层面的CPU、内存、IO、网络等各个指标,大数据平台层面的运作情况,业务逻辑层面的服务状态等。另外一方面,虽然各个大数据平台都具有一定的容错能力,但是并不是所有类型的错误都能够容忍,并且当出现了可容忍的小错误时,往往预示着更致命的错误隐藏在背后,若不及时发现,就很可能导致非常严重的后果。因此需要监控运维系统将这些小问题提前预警出来,以便将事故扼杀在萌芽中。自动监控运维系统一般具有系统状态检测、性能分析、监控报警、自动发布与回滚等能力。尤其是自动发布与回滚能力,对于海量用户的业务来说,是必不可少的,可以大大减轻运维的工作量,消除容易出错的人工环节,增加业务的稳定性。
前面给出了各个大数据系统在后台的层次结构,接下来介绍一下业务数据在各个平台之间的流向关系。
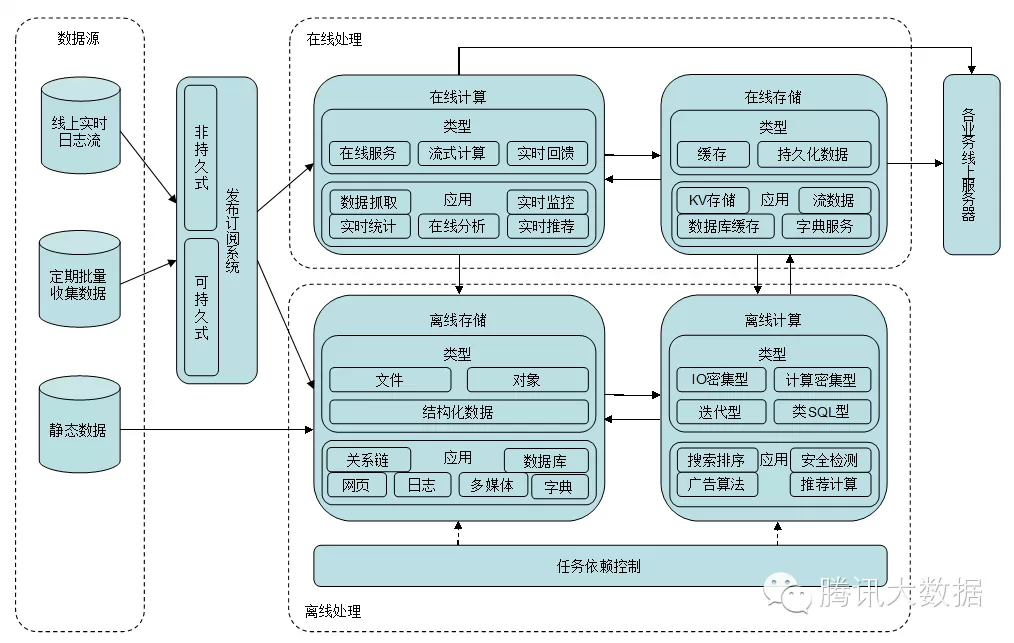
如上图所示,数据的来源一般有三种:第一种是线上的实时日志流;第二种是定期批量收集和更新的数据;第三种是长期不变的静态数据。前两种数据通常发布到订阅发布系统当中,以通知下游消费者进行消费。静态数据一般直接保存在离线存储系统中,供需要时访问。
发布订阅系统负责管理数据的发布和收集下游的订阅需求,将数据分发给对应的消费者,一部分数据会发送到在线计算平台,另一部分数据会落入离线存储平台。发布订阅系统可分为持久式和非持久式,可根据业务的特性选用。
对于在线处理部分,在线计算平台所需的数据一部分来自从发布订阅系统中获取实时数据,另一部分来自在线存储系统。在线计算平台常见的计算类型有在线服务、流式计算、实时回馈等,分别服务于数据抓取、实时统计、实时监控、在线分析、实时推荐等应用。在线存储平台中的数据一般分为临时缓存数据和持久化数据,这些数据通常来自在线计算平台和离线计算平台。在线存储平台承载的应用有:KV缓存、数据库缓存、流式数据、字典服务等。
对于离线处理部分,离线存储平台负责对文件、对象、结构化数据的存储,服务于日志、网页、关系链、多媒体、字典、数据库等应用,它的数据来源非常丰富。而离线计算平台的数据一般来自离线存储和在线存储,计算结果往往也写回离线和在线存储平台。离线计算平台上的计算分为IO密集型、计算密集型、迭代型、类SQL型等类型,分别对搜索排序、广告算法、个性化推荐、安全检测等应用提供支持。
这里不得不提的是用在离线处理中的任务依赖控制系统。在线处理的各系统由于基本上是数据流驱动或者是事件驱动的,所以不需要显式地设置各个任务的上下游依赖关系,数据和事件的流式传播即触发了对应的计算。而对于离线处理,各个任务都是批量处理的方式,因此需要等上游完成批量处理,下游才能开始接着处理。现实中往往采用定时器+预估完成时间的方式来粗略地隐式地配置任务依赖,这样带来的问题是:第一,预估时间不准确,造成时间的浪费或是无效的计算;第二,上游的延迟会引起下游的连锁反应,不具有弹性的容忍机制;第三,随着任务增多,依赖关系配置和执行时间的预估变得越发复杂和不可控,而且任务迁移时很容易发生任务丢失和依赖失效的问题。任务依赖控制系统正是为了解决这些问题而诞生的,它把所有任务的依赖拓扑关系放到全局统一的视图中,将这些任务集中起来管理,可视化地配置它们的依赖关系,任务的迁移变得简单可靠。同时,它负责监控每个任务的完成情况,如果成功完成,则马上触发下游的任务;如果失败,则进行重试,直到执行成功才触发下游任务,或者超过重试次数阈值后进行告警。这种自动化的依赖触发方式,缩短了整体业务耗时,并具有弹性容忍延时能力。
对于大数据处理来说,数据是素材,平台是工具。工欲善其事,必先利其器。大数据各个层次的平台已经日臻成熟,我们对其原理与架构也清晰明了。而海量数据中蕴含的巨大价值能否被有效挖掘,就看使用者们的功力了。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

