OKHTTP3源码2-连接池管理
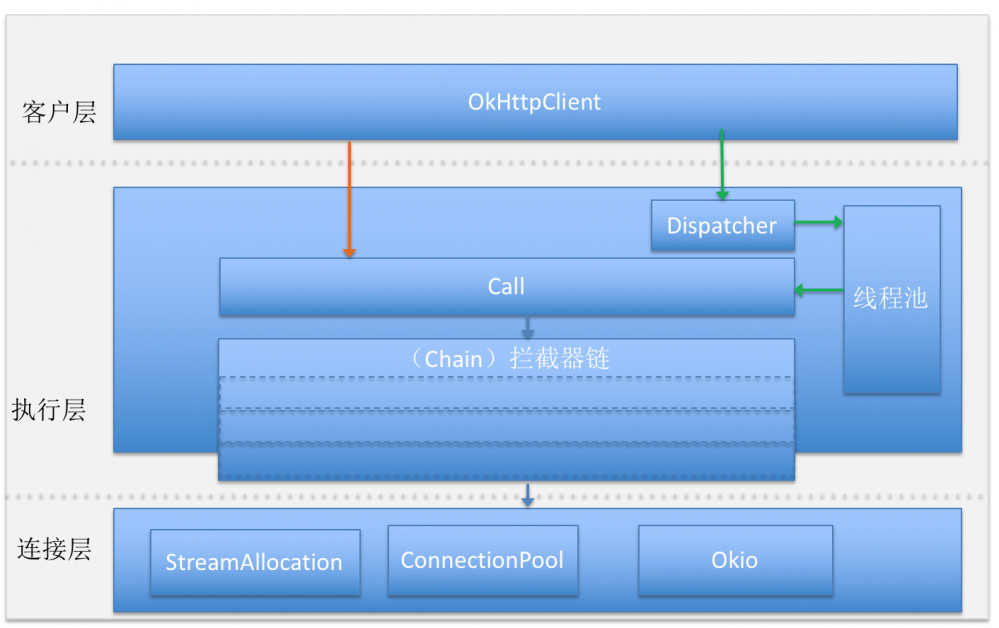
在 《OKHTTP3源码和设计模式-1》 ,中整体介绍了 OKHttp3 的源码架构,重点讲解了请求任务的分发管理和线程池以及请求执行过程中的拦截器。这一章我们接着往下走认识一下 OKHttp3 底层连接和连接池工作机制。
RealCall 封装了请求过程, 组织了用户和内置拦截器,其中内置拦截器 retryAndFollowUpInterceptor -> BridgeInterceptor -> CacheInterceptor 完执行层的大部分逻辑 ,ConnectInterceptor -> CallServerInterceptor 两个拦截器开始迈向连接层最终完成网络请求。
连接层连接器
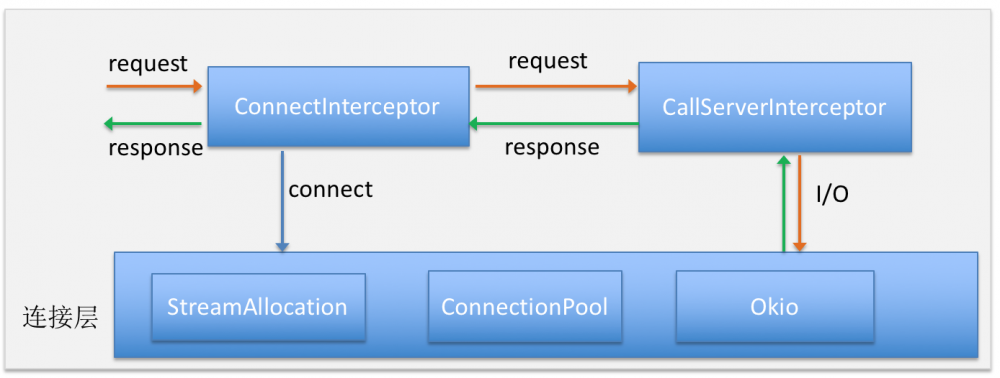
ConnectInterceptor 的工作很简单, 负责打开连接; CallServerIntercerceptor 是核心连接器链上的最后一个连接器,
负责从当前连接中写入和读取数据。
连接的打开
/** Opens a connection to the target server and proceeds to the next interceptor. */
// 打开一个和目标服务器的连接,并把处理交个下一个拦截器
public final class ConnectInterceptor implements Interceptor {
public final OkHttpClient client;
public ConnectInterceptor(OkHttpClient client) {
this.client = client;
}
@Override public
Response intercept(Chain chain) throws IOException {
RealInterceptorChain realChain = (RealInterceptorChain) chain;
Request request = realChain.request();
StreamAllocation streamAllocation = realChain.streamAllocation();
// We need the network to satisfy this request. Possibly for validating a conditional GET.
boolean doExtensiveHealthChecks = !request.method().equals("GET");
// 打开连接
HttpCodec httpCodec = streamAllocation.newStream(client, doExtensiveHealthChecks);
RealConnection connection = streamAllocation.connection();
// 交个下一个拦截器
return realChain.proceed(request, streamAllocation, httpCodec, connection);
}
}
单独看 ConnectInterceptor 的代码很简单,不过连接正在打开的过程需要看看 streamAllocation.newStream(client, doExtensiveHealthChecks),内部执行过程。还是先整体上了看看 StreamAllocation 这个类的作用。
StreamAllocation
StreamAllocation 处于上层请求和底层连接池直接 , 协调请求和连接池直接的关系。先来看看 StreamAllocation 对象在哪里创建的? 回到之前文章中介绍的 RetryAndFollowUpInterceptor, 这是核心拦截器链上的顶层拦截器其中源码:
@Override
public Response intercept(Chain chain) throws IOException {
Request request = chain.request();
streamAllocation = new StreamAllocation(
client.connectionPool(), createAddress(request.url()), callStackTrace);
...省略代码
}
这里, 每一次请求创建了一个 StreamAllocation 对象, 那么问题来了? 之前我们说过每一个 OkHttpClient 对象只有一个对应的连接池, 刚刚又说到 StreamAllocation 打开连接, 那么 StreamAllocation 是如何创建连接池的呢?我们很容易就去 StreamAllocation 中找连接池创建的逻辑,但是找不到。 连接池创建的地方在 OkHttpClient 中:
public Builder() {
dispatcher = new Dispatcher();
protocols = DEFAULT_PROTOCOLS;
connectionSpecs = DEFAULT_CONNECTION_SPECS;
eventListenerFactory = EventListener.factory(EventListener.NONE);
proxySelector = ProxySelector.getDefault();
cookieJar = CookieJar.NO_COOKIES;
socketFactory = SocketFactory.getDefault();
hostnameVerifier = OkHostnameVerifier.INSTANCE;
certificatePinner = CertificatePinner.DEFAULT;
proxyAuthenticator = Authenticator.NONE;
authenticator = Authenticator.NONE;
// 创建连接池
connectionPool = new ConnectionPool();
dns = Dns.SYSTEM;
followSslRedirects = true;
followRedirects = true;
retryOnConnectionFailure = true;
connectTimeout = 10_000;
readTimeout = 10_000;
writeTimeout = 10_000;
pingInterval = 0;
}
OkHttpClient 默认构造函数的 Builder , 在这里创建了连接池。所以这里我们也可以看到, 如果我们对默认连接池不满,我们是可以直通过 builder 接指定的。
搞懂了 StreamAllocation 和 ConnectionPool 的创建 , 我们再来看看 StreamAllocation 是怎么打开连接的?直接兜源码可能有点绕 ,先给一个粗略流程图,然后逐点分析。
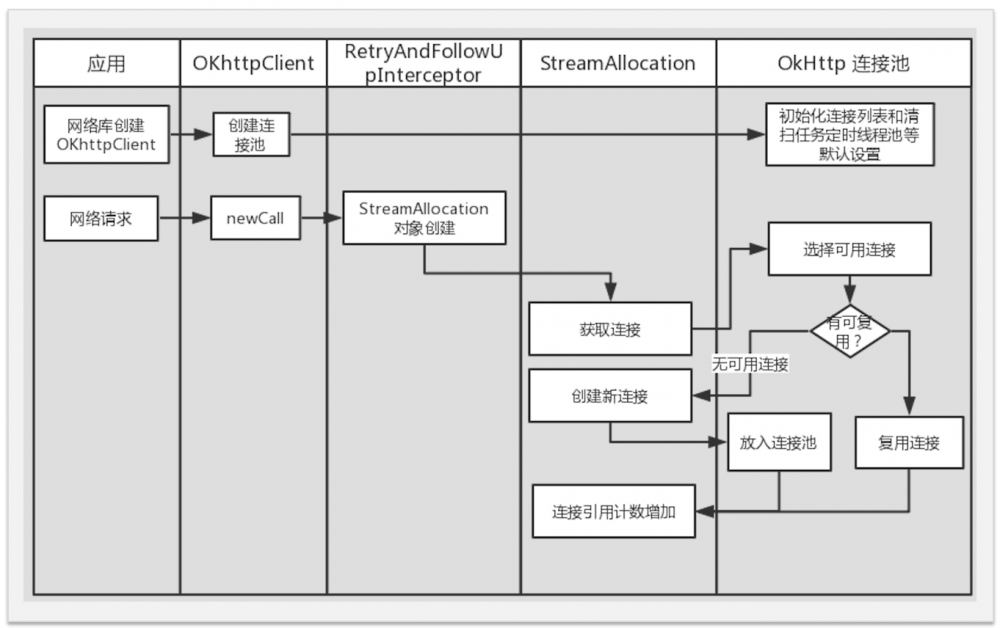
链接池实现
相信大家都有一些 Http 协议的基础(如果没有就去补了,不然看不懂)都知道 Http 的下层协议是 TCP。TCP 连接的创建和断开是有性能开销的,在 Http1.0 中,每一次请求就打开一个连接,在一些老的旧的浏览器上,如果还是基于 Http1.0,体验会非常差; Http1.1 以后支持长连接, 运行一个请求打开连接完成请求后, 连接可以不关闭, 下次请求时复用此连接,从而提高连接的利用率。当然并不是连接打开后一直开着不关,这样又会造成连接浪费,怎么管理?
在OKHttp3 的默认实现中,使用一个双向队列来缓存所有连接, 这些连接中最多只能存在 5 个空闲连接,空闲连接最多只能存活 5 分钟。
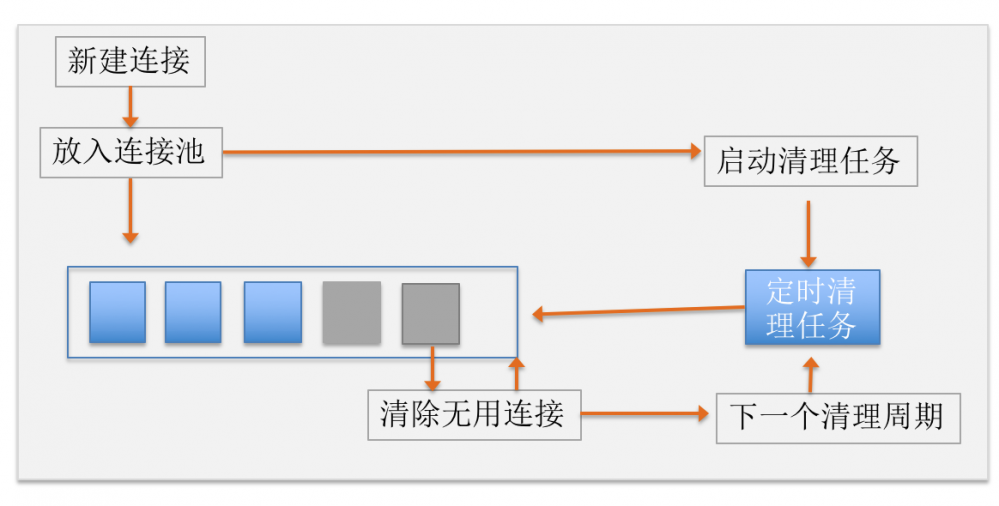
定期清理实现
public final class ConnectionPool {
/**
* Background threads are used to cleanup expired connections. There will be at most a single
* thread running per connection pool. The thread pool executor permits the pool itself to be
* garbage collected.
*/
// 后台定期清理连接的线程池
private static final Executor executor = new ThreadPoolExecutor(0 /* corePoolSize */,
Integer.MAX_VALUE /* maximumPoolSize */, 60L /* keepAliveTime */, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(), Util.threadFactory("OkHttp ConnectionPool", true));
/** The maximum number of idle connections for each address. */
private final int maxIdleConnections;
private final long keepAliveDurationNs;
// 后台定期清理连接的任务
private final Runnable cleanupRunnable = new Runnable() {
@Override
public void run() {
while (true) {
// cleanup 执行清理
long waitNanos = cleanup(System.nanoTime());
if (waitNanos == -1) return;
if (waitNanos > 0) {
long waitMillis = waitNanos / 1000000L;
waitNanos -= (waitMillis * 1000000L);
synchronized (ConnectionPool.this) {
try {
ConnectionPool.this.wait(waitMillis, (int) waitNanos);
} catch (InterruptedException ignored) {
}
}
}
}
}
};
双向队列
// 存储连接的双向队列 private final Deque<RealConnection> connections = new ArrayDeque<>();
放入连接
void put(RealConnection connection) {
assert (Thread.holdsLock(this));
if (!cleanupRunning) {
cleanupRunning = true;
executor.execute(cleanupRunnable);
}
connections.add(connection);
}
获取连接
RealConnection get(Address address, StreamAllocation streamAllocation, Route route) {
assert (Thread.holdsLock(this));
for (RealConnection connection : connections) {
if (connection.isEligible(address, route)) {
streamAllocation.acquire(connection);
return connection;
}
}
return null;
}
StreamAllocation.连接创建和复用
ConnectionPool 的源码逻辑还是相当比较简单, 主要提供一个双向列表来存取连接, 使用一个定时任务定期清理无用连接。 二连接的创建和复用逻辑主要在 StreamAllocation 中。
寻找连接
private RealConnection findHealthyConnection(int connectTimeout, int readTimeout,
int writeTimeout, boolean connectionRetryEnabled, boolean doExtensiveHealthChecks)
throws IOException {
while (true) {
// 核心逻辑在 findConnection()中
RealConnection candidate = findConnection(connectTimeout, readTimeout, writeTimeout,
connectionRetryEnabled);
// If this is a brand new connection, we can skip the extensive health checks.
synchronized (connectionPool) {
if (candidate.successCount == 0) {
return candidate;
}
}
// Do a (potentially slow) check to confirm that the pooled connection is still good. If it
// isn't, take it out of the pool and start again.
if (!candidate.isHealthy(doExtensiveHealthChecks)) {
noNewStreams();
continue;
}
return candidate;
}
}
findConnection():
private RealConnection findConnection(int connectTimeout, int readTimeout, int writeTimeout,
boolean connectionRetryEnabled) throws IOException {
Route selectedRoute;
synchronized (connectionPool) {
// 省略部分代码...
// Attempt to get a connection from the pool. Internal.instance 就是 ConnectionPool 的实例
Internal.instance.get(connectionPool, address, this, null);
if (connection != null) {
// 复用此连接
return connection;
}
// 省略部分代码...
// 创建新新连接
result = new RealConnection(connectionPool, selectedRoute);
// 引用计数
acquire(result);
}
synchronized (connectionPool) {
// Pool the connection. 放入连接池
Internal.instance.put(connectionPool, result);
}
// 省略部分代码...
return result;
}
StreamAllocation 主要是为上层提供一个连接, 如果连接池中有复用的连接则复用连接, 如果没有则创建新的。无论是拿到可复用的还是创建新的, 都要为此连接计算一下引用计数。
public void acquire(RealConnection connection) {
assert (Thread.holdsLock(connectionPool));
if (this.connection != null) throw new IllegalStateException();
this.connection = connection;
// 连接使用allocations列表来记录每一个引用
connection.allocations.add(new StreamAllocationReference(this, callStackTrace));
}
Realconnection
Realconnection 封装了底层 socket 连接, 同时使用 OKio 来进行数据读写, OKio 是 square 公司的另一个独立的开源项目, 大家感兴趣可以去深入读下 OKio 源码, 这里不展开。
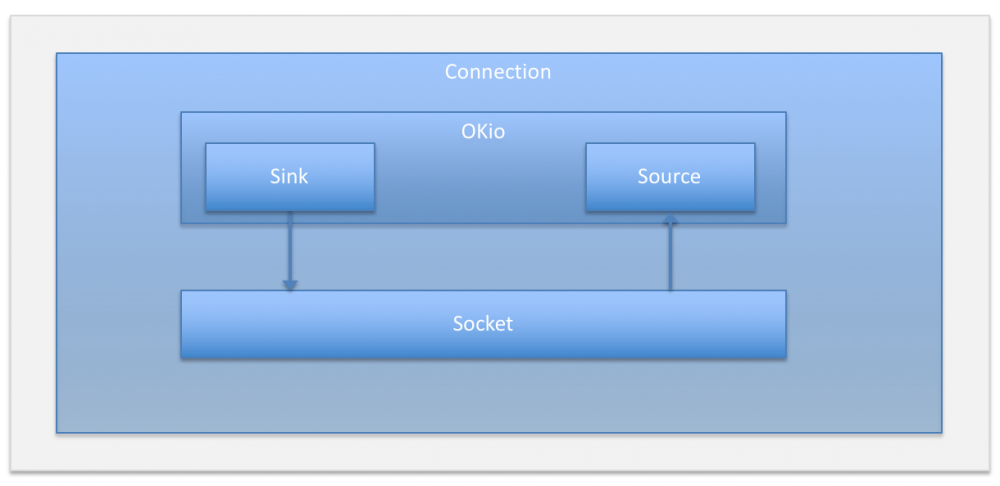
/** Does all the work necessary to build a full HTTP or HTTPS connection on a raw socket. */
private void connectSocket(int connectTimeout, int readTimeout) throws IOException {
Proxy proxy = route.proxy();
Address address = route.address();
rawSocket = proxy.type() == Proxy.Type.DIRECT || proxy.type() == Proxy.Type.HTTP
? address.socketFactory().createSocket()
: new Socket(proxy);
rawSocket.setSoTimeout(readTimeout);
try {
// 打开 socket 连接
Platform.get().connectSocket(rawSocket, route.socketAddress(), connectTimeout);
} catch (ConnectException e) {
ConnectException ce = new ConnectException("Failed to connect to " + route.socketAddress());
ce.initCause(e);
throw ce;
}
// 使用 OKil 连上 socket 后续读写使用 Okio
source = Okio.buffer(Okio.source(rawSocket));
sink = Okio.buffer(Okio.sink(rawSocket));
}
正文到此结束
- 本文标签: 源码 cat TCP 开源 http IO 协议 线程 设计模式 final ECS executor ssl find 代码 组织 core cache 服务器 tar 管理 list src ORM rmi 开源项目 value client queue DNS IDE 实例 build 线程池 Thread pool https 数据 Select Connection 文章 id ip UI CTO ThreadPoolExecutor ACE 长连接
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

