深度学习与经典机器学习的优劣势一览!
在过去几年中,深度学习已成为大多数AI类型问题的首选技术,掩盖了经典的机器学习。其中明显的原因是深度学习已经在包括言语、自然语言、视觉和玩游戏在内的各种各样的任务中多次表现出优异的表现。然而,尽管深度学习具有如此高的性能,但使用经典的机器学习和一些特定的情况下,使用线性回归或决策树而不是大型深度网络会更好。
在这篇文章中,我们将比较深度学习与传统的机器学习技术。在这样做的过程中,我们将找出两种技术的优点和缺点,以及它们在哪里,如何获得最佳的使用。

深度学习>经典机器学习
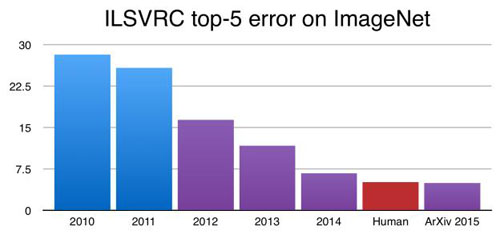
一流的表现:深度网络已经实现了远远超过传统ML方法的精确度,包括语音、自然语言、视觉和玩游戏等许多领域。在许多任务中,经典ML甚至无法竞争。例如,下图显示了ImageNet数据集上不同方法的图像分类准确性,蓝色表示经典ML方法,红色表示深度卷积神经网络(CNN)方法。
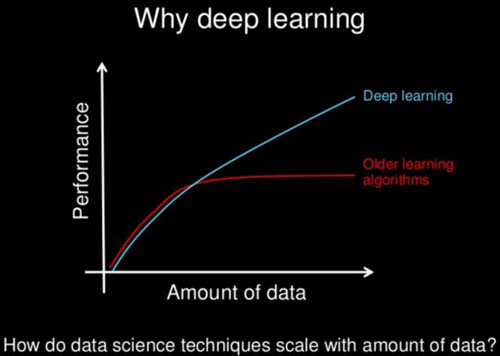
使用数据进行有效缩放:与传统ML算法相比,深度网络使用更多的数据可以更好地扩展。下面的图表是一个简单而有效的例子。很多时候,通过深层网络来提高准确性的最佳建议就是使用更多的数据!使用经典的ML算法,这种快速简单的修复方法甚至几乎没有效果,并且通常需要更复杂的方法来提高准确性。
不需要特征工程:经典的ML算法通常需要复杂的特征工程。首先在数据集上执行深度探索性数据分析,然后做一个简单的降低维数的处理。最后,必须仔细选择最佳功能以传递给ML算法。当使用深度网络时,不需要这样做,因为只需将数据直接传递到网络,通常就可以实现良好的性能。这完全消除了整个过程的大型和具有挑战性的特征工程阶段。
适应性强,易于转换:与传统的ML算法相比,深度学习技术可以更容易地适应不同的领域和应用。首先,迁移学习使得预先训练的深度网络适用于同一领域内的不同应用程序是有效的。
例如,在计算机视觉中,预先训练的图像分类网络通常用作对象检测和分割网络的特征提取前端。将这些预先训练的网络用作前端,可以减轻整个模型的训练,并且通常有助于在更短的时间内实现更高的性能。此外,不同领域使用的深度学习的基本思想和技术往往是相当可转换的。
例如,一旦了解了语音识别领域的基础深度学习理论,那么学习如何将深度网络应用于自然语言处理并不是太具有挑战性,因为基准知识非常相似。对于经典ML来说,情况并非如此,因为构建高性能ML模型需要特定领域和特定应用的ML技术和特征工程。对于不同的领域和应用而言,经典ML的知识库是非常不同的,并且通常需要在每个单独的区域内进行广泛的专业研究。
经典机器学习>深度学习
对小数据更好:为了实现高性能,深层网络需要非常大的数据集。之前提到的预先训练过的网络在120万张图像上进行了训练。对于许多应用来说,这样的大数据集并不容易获得,并且花费昂贵且耗时。对于较小的数据集,传统的ML算法通常优于深度网络。
财务和计算都便宜:深度网络需要高端GPU在大量数据的合理时间内进行训练。这些GPU非常昂贵,但是如果没有他们训练深层网络来实现高性能,这在实际上并不可行。要有效使用这样的高端GPU,还需要快速的CPU、SSD存储以及快速和大容量的RAM。传统的ML算法只需要一个体面的CPU就可以训练得很好,而不需要最好的硬件。由于它们在计算上并不昂贵,因此可以更快地迭代,并在更短的时间内尝试许多不同的技术。
更容易理解:由于传统ML中涉及直接特征工程,这些算法很容易解释和理解。此外,调整超参数并更改模型设计更加简单,因为我们对数据和底层算法都有了更全面的了解。另一方面,深层网络是“黑匣子”型,即使现在研究人员也不能完全了解深层网络的“内部”。由于缺乏理论基础、超参数和网络设计也是一个相当大的挑战。
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

