集合系列—LinkedHashMap源码分析
点击上方“ Java知音 ”,选择“置顶公众号”
技术文章第一时间送达!
作者:劳夫子 (Java知音获权转载)
http://www.cnblogs.com/liuyun1995/p/8330700.html
知音专栏
Javaweb练手项目源码下载
常用设计模式完整系列篇
100套IT类简历模板下载
Java常见面试题汇总篇
这篇文章我们开始分析LinkedHashMap的源码,LinkedHashMap继承了HashMap,也就是说LinkedHashMap是在HashMap的基础上扩展而来的。因此在看LinkedHashMap源码之前,读者有必要先去了解HashMap的源码,可以查看我上一篇文章的介绍《 集合系列—HashMap源码分析 》。
只要深入理解了HashMap的实现原理,回过头来再去看LinkedHashMap,HashSet和LinkedHashSet的源码那都是非常简单的。因此,读者们好好耐下性子来研究研究HashMap源码吧,这可是买一送三的好生意啊。
在前面分析HashMap源码时,我采用以问题为导向对源码进行分析,这样使自己不会像无头苍蝇一样乱分析一通,读者也能够针对问题更加深入的理解。本篇我决定还是采用这样的方式对LinkedHashMap进行分析。
1. LinkedHashMap内部采用了什么样的结构?

可以看到,由于LinkedHashMap是继承自HashMap的,所以LinkedHashMap内部也还是一个哈希表,只不过LinkedHashMap重新写了一个Entry,在原来HashMap的Entry上添加了两个成员变量,分别是前继结点引用和后继结点引用。
这样就将所有的结点链接在了一起,构成了一个双向链表,在获取元素的时候就直接遍历这个双向链表就行了。我们看看LinkedHashMap实现的Entry是什么样子的。
private static class Entry<K,V> extends HashMap.Entry<K,V> {
//当前结点在双向链表中的前继结点的引用
Entry<K,V> before;
//当前结点在双向链表中的后继结点的引用
Entry<K,V> after;
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
//从双向链表中移除该结点
private void remove() {
before.after = after;
after.before = before;
}
//将当前结点插入到双向链表中一个已存在的结点前面
private void addBefore(Entry<K,V> existingEntry) {
//当前结点的下一个结点的引用指向给定结点
after = existingEntry;
//当前结点的上一个结点的引用指向给定结点的上一个结点
before = existingEntry.before;
//给定结点的上一个结点的下一个结点的引用指向当前结点
before.after = this;
//给定结点的上一个结点的引用指向当前结点
after.before = this;
}
//按访问顺序排序时, 记录每次获取的操作
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
//如果是按访问顺序排序
if (lm.accessOrder) {
lm.modCount++;
//先将自己从双向链表中移除
remove();
//将自己放到双向链表尾部
addBefore(lm.header);
}
}
void recordRemoval(HashMap<K,V> m) {
remove();
}
}
2. LinkedHashMap是怎样实现按插入顺序排序的?
//父类put方法中会调用的该方法
void addEntry(int hash, K key, V value, int bucketIndex) {
//调用父类的addEntry方法
super.addEntry(hash, key, value, bucketIndex);
//下面操作是方便LRU缓存的实现, 如果缓存容量不足, 就移除最老的元素
Entry<K,V> eldest = header.after;
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
}
}
//父类的addEntry方法中会调用该方法
void createEntry(int hash, K key, V value, int bucketIndex) {
//先获取HashMap的Entry
HashMap.Entry<K,V> old = table[bucketIndex];
//包装成LinkedHashMap自身的Entry
Entry<K,V> e = new Entry<>(hash, key, value, old);
table[bucketIndex] = e;
//将当前结点插入到双向链表的尾部
e.addBefore(header);
size++;
}
LinkedHashMap重写了它的父类HashMap的addEntry和createEntry方法。当要插入一个键值对的时候,首先会调用它的父类HashMap的put方法。在put方法中会去检查一下哈希表中是不是存在了对应的key,如果存在了就直接替换它的value就行了,如果不存在就调用addEntry方法去新建一个Entry。
注意,这时候就调用到了LinkedHashMap自己的addEntry方法。我们看到上面的代码,这个addEntry方法除了回调父类的addEntry方法之外还会调用removeEldestEntry去移除最老的元素,这步操作主要是为了实现LRU算法,下面会讲到。
我们看到LinkedHashMap还重写了createEntry方法,当要新建一个Entry的时候最终会调用这个方法,createEntry方法在每次将Entry放入到哈希表之后,就会调用addBefore方法将当前结点插入到双向链表的尾部。这样双向链表就记录了每次插入的结点的顺序,获取元素的时候只要遍历这个双向链表就行了,下图演示了每次调用addBefore的操作。由于是双向链表,所以将当前结点插入到头结点之前其实就是将当前结点插入到双向链表的尾部。
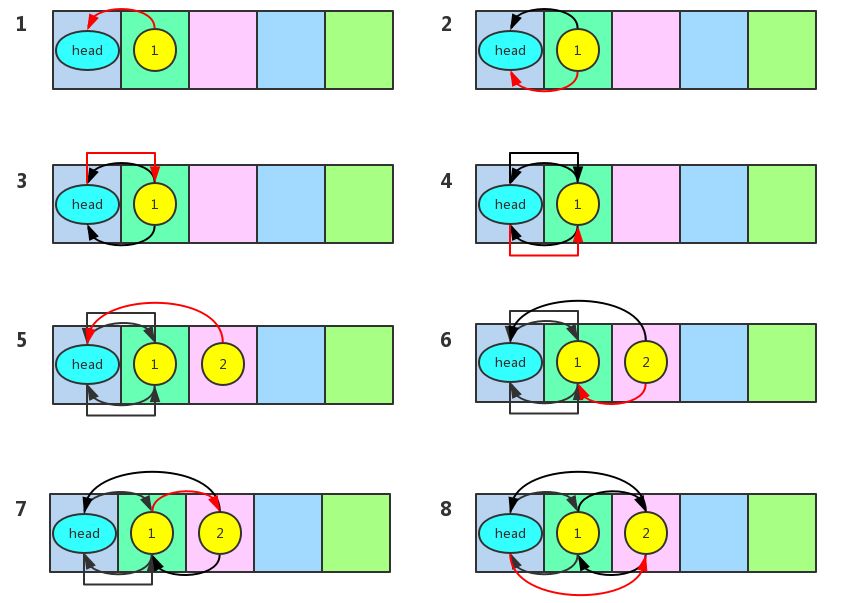
3. 怎样利用LinkedHashMap实现LRU缓存?
我们知道缓存的实现依赖于计算机的内存,而内存资源是相当有限的,不可能无限制的存放元素,所以我们需要在容量不够的时候适当的删除一些元素,那么到底删除哪个元素好呢?
LRU算法的思想是,如果一个数据最近被访问过,那么将来被访问的几率也更高。所以我们可以删除那些不经常被访问的数据。接下来我们看看LinkedHashMap内部是怎样实现LRU机制的。
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V> {
//双向链表头结点
private transient Entry<K,V> header;
//是否按访问顺序排序
private final boolean accessOrder;
...
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
//根据key获取value值
public V get(Object key) {
//调用父类方法获取key对应的Entry
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null) {
return null;
}
//如果是按访问顺序排序的话, 会将每次使用后的结点放到双向链表的尾部
e.recordAccess(this);
return e.value;
}
private static class Entry<K,V> extends HashMap.Entry<K,V> {
...
//将当前结点插入到双向链表中一个已存在的结点前面
private void addBefore(Entry<K,V> existingEntry) {
//当前结点的下一个结点的引用指向给定结点
after = existingEntry;
//当前结点的上一个结点的引用指向给定结点的上一个结点
before = existingEntry.before;
//给定结点的上一个结点的下一个结点的引用指向当前结点
before.after = this;
//给定结点的上一个结点的引用指向当前结点
after.before = this;
}
//按访问顺序排序时, 记录每次获取的操作
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
//如果是按访问顺序排序
if (lm.accessOrder) {
lm.modCount++;
//先将自己从双向链表中移除
remove();
//将自己放到双向链表尾部
addBefore(lm.header);
}
}
...
}
//父类put方法中会调用的该方法
void addEntry(int hash, K key, V value, int bucketIndex) {
//调用父类的addEntry方法
super.addEntry(hash, key, value, bucketIndex);
//下面操作是方便LRU缓存的实现, 如果缓存容量不足, 就移除最老的元素
Entry<K,V> eldest = header.after;
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
}
}
//是否删除最老的元素, 该方法设计成要被子类覆盖
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
}
为了更加直观,上面贴出的代码中我将一些无关的代码省略了,我们可以看到LinkedHashMap有一个成员变量accessOrder,该成员变量记录了是否需要按访问顺序排序,它提供了一个构造器可以自己指定accessOrder的值。
每次调用get方法获取元素式都会调用e.recordAccess(this),该方法会将当前结点移到双向链表的尾部。现在我们知道了如果accessOrder为true那么每次get元素后都会把这个元素挪到双向链表的尾部。这一步的目的是区别出最常使用的元素和不常使用的元素,经常使用的元素放到尾部,不常使用的元素放到头部。
我们再回到上面的代码中看到每次调用addEntry方法时都会判断是否需要删除最老的元素。判断的逻辑是removeEldestEntry实现的,该方法被设计成由子类进行覆盖并重写里面的逻辑。
注意,由于最近被访问的结点都被挪动到双向链表的尾部,所以这里是从双向链表头部取出最老的结点进行删除。下面例子实现了一个简单的LRU缓存。
public class LRUMap<K, V> extends LinkedHashMap<K, V> {
private int capacity;
LRUMap(int capacity) {
//调用父类构造器, 设置为按访问顺序排序
super(capacity, 1f, true);
this.capacity = capacity;
}
@Override
public boolean removeEldestEntry(Map.Entry<K, V> eldest) {
//当键值对大于等于哈希表容量时
return this.size() >= capacity;
}
public static void main(String[] args) {
LRUMap<Integer, String> map = new LRUMap<Integer, String>(4);
map.put(1, "a");
map.put(2, "b");
map.put(3, "c");
System.out.println("原始集合:" + map);
String s = map.get(2);
System.out.println("获取元素:" + map);
map.put(4, "d");
System.out.println("插入之后:" + map);
}
}
结果如下:

注:以上全部分析基于JDK1.7,不同版本间会有差异,读者需要注意

正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

