一条数据的HBase之旅,简明HBase入门教程-Write全流程
如果将上篇内容理解为一个冗长的"铺垫 " ,那么,从本文开始,剧情才开始正式展开。本文基于提供的样例数据,介绍了写数据的接口,RowKey定义,数据在客户端的组装,数据路由,打包分发,以及RegionServer侧将数据写入到Region中的全部流程。

NoSQL漫谈
本文整体思路
-
前文内容回顾
-
示例数据
-
HBase可选接口介绍
-
表服务接口介绍
-
介绍几种写数据的模式
-
如何构建Put对象(包含RowKey定义以及列定义)
-
数据路由
-
Client侧的分组打包
-
Client发RPC请求到RegionServer
-
安全访问控制
-
RegionServer侧处理:Region分发
-
Region内部处理:写WAL
-
Region内部处理:写MemStore
为了保证"故事 " 的完整性,导致本文篇幅过长,非常抱歉,读者可以按需跳过不感兴趣的内容。
前文回顾
上篇文章《 一条数据的HBase之旅,简明HBase入门教程-开篇 》主要介绍了如下内容:
-
HBase项目概况(搜索引擎热度/社区开发活跃度)
-
HBase数据模型(RowKey,稀疏矩阵,Region,Column Family,KeyValue)
-
基于HBase的数据模型,介绍了HBase的适合场景(以 实体/事件 为中心的简单结构的数据)
-
介绍了HBase与HDFS的关系,集群关键角色以及部署建议
-
写数据前的准备工作:建立连接,建表
示例数据
(上篇文章已经提及,这里再复制一次的原因,一是为了让下文内容更容易理解,二是个别字段名称做了调整)
给出一份我们日常都可以接触到的数据样例,先简单给出示例数据的字段定义:

示例数据字段定义
本文力求简洁,仅给出了最简单的几个字段定义。如下是”虚构”的样例数据:
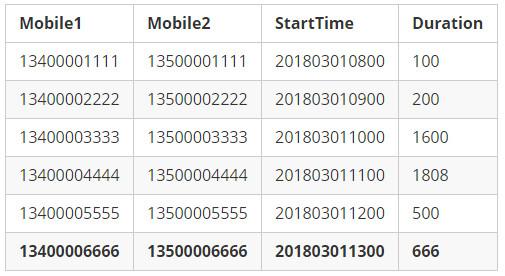
示例数据
在本文大部分内容中所涉及的一条数据,是上面加粗的最后一行 " Mobile1 " 为 " 13400006666 " 这行记录。在下面的流程图中,我们使用下面这样一个红色小图标来表示该数据所在的位置:

数据位置标记
可选接口
HBase中提供了如下几种主要的接口:
-
Java Client API
HBase的基础API,应用最为广泛。
-
HBase Shell
基于Shell的命令行操作接口,基于Java Client API实现。
-
Restful API
Rest Server侧基于Java Client API实现。
-
Thrift API
Thrift Server侧基于Java Client API实现。
-
MapReduce Based Batch Manipulation API
基于MapReduce的批量数据读写API。
除了上述主要的API,HBase还提供了 基于Spark的批量操作接口 以及 C++ Client 接口,但这两个特性都被规划在了3.0版本中,当前尚在开发中。
无论是HBase Shell/Restful API还是Thrift API,都是基于Java Client API实现的。因此,接下来关于流程的介绍,都是基于Java Client API的调用流程展开的。
关于表服务接口的抽象
同步连接与异步连接,分别提供了不同的表服务接口抽象:
-
Table 同步连接中的表服务接口定义
-
AsyncTable 异步连接中的表服务接口定义
异步连接AsyncConnection获取AsyncTable实例的接口默认实现:

Create AsyncTable
同步连接ClusterConnection的实现类ConnectionImplementation中获取Table实例的接口实现:
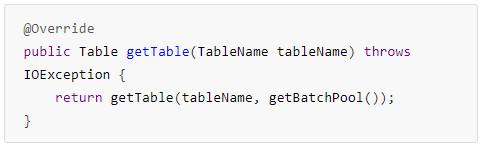
Create Table
写数据的几种方式
-
Single Put
单条记录单条记录的随机put操作。Single Put所对应的接口定义如下:
在AsyncTable接口中的定义:
CompletableFuture<Void> put(Put put);
在Table接口中的定义:
void put(Put put) throws IOException;
-
Batch Put
汇聚了几十条甚至是几百上千条记录之后的 小批次 随机put操作。
Batch Put只是本文对该类型操作的称法,实际的接口名称如下所示:
在AsyncTable接口中的定义:
List<CompletableFuture<Void>> put(List<Put> puts);
在Table接口中的定义:
void put(List<Put> puts) throws IOException;
-
Bulkload
基于MapReduce API提供的数据批量导入能力,导入数据量通常在GB级别以上,Bulkload能够绕过Java Client API直接生成HBase的底层数据文件(HFile)。
构建Put对象
设计合理的RowKey
RowKey通常是一个或若干个字段的直接组合或经一定处理后的信息,因为一个表中所有的数据都是基于RowKey排序的,RowKey的设计对读写都会有直接的性能影响。
我们基于本文的样例数据,先给出两种RowKey的设计,并简单讨论各自的优缺点:
样例数据:
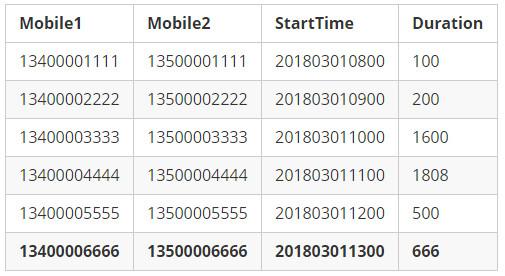
示例数据
RowKey Format 1 : Mobile1 + StartTime
为了方便读者理解,我们在两个字段之间添加了连接符”^”。如下是RowKey以及相关排序结果:
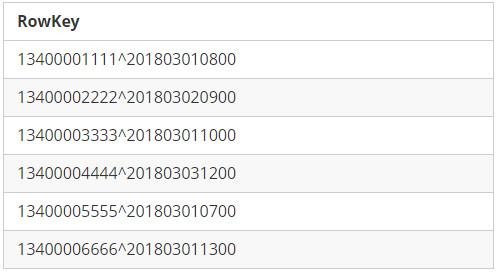
RowKey Format 1
RowKey Format 2 : StartTime + Mobile1
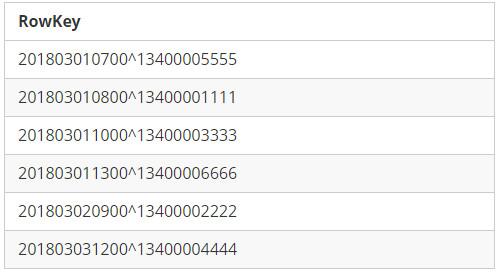
RowKey Format 2
从上面两个表格可以看出来,不同的字段组合顺序设计,带来截然不同的排序结果,我们将RowKey中的第一个字段称之为“ 先导字段 ”。第一种设计,有利于查询”手机号码XXX的在某时间范围内的数据记录”,但不利于查询”某段时间范围内有哪些手机号码拨出了电话?”,而第二种设计却恰好相反。
上面是两种设计都是两个字段的直接组合,这种设计在实际应用中,会带来读写 热点 问题,难以保障数据读写请求在所有Regions之间的负载均衡。避免热点的常见方法有如下几种:
Reversing
如果先导字段本身会带来热点问题,但该字段尾部的信息却具备良好的随机性,此时,可以考虑将先导字段做反转处理,将尾部几位直接提前到前面,或者直接将整个字段完全反转。
将 先导字段 Mobile1翻转后,就具备非常好的随机性。
例如:
13400001111^201803010800
将先导字段Mobile1反转后的RowKey变为:
11110000431^201803010800
Salting
Salting的原理是在RowKey的前面添加固定长度的随机Bytes,随机Bytes能保障数据在所有Regions间的负载均衡。
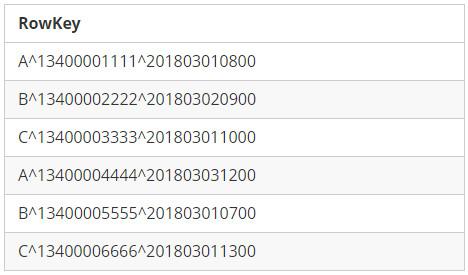
RowKey With Salting
Salting能很好的保障写入时将数据均匀分散到各个Region中,但对于读取却是不友好的,例如,如果读取Mobile1为”13400001111″在20180301这一天的数据记录时,因为Salting Bytes信息是随机选择添加的,查询时并不知道前面添加的Salting Bytes是”A”,因此{“A”, “B”, “C”}所关联的Regions都得去查看一下。
Hashing
Hashing是将一个RowKey通过一个Hash函数生成一组固定长度的bytes,Hash函数能保障所生成的随机bytes具备良好的离散度,从而也能够均匀打散到各个Region中。Hashing既有利于随机写入,又利于基于知道RowKey各字段的确切信息之后的随机读取操作,但如果是基于RowKey范围的Scan或者是RowKey的模糊信息进行查询的话,就会带来显著的性能问题,因为原来在字典顺序相邻的RowKey列表,通过Hashing打散后导致这些数据被分散到了多个Region中。
因此, RowKey的设计,需要充分考虑业务的读写特点 。
本文内容假设RowKey设计: reversing(Mobile1) +StartTime
也就是说,RowKey由反转处理后的Mobile1与StartTime组成。对于我们所关注的这行数据:

关注的数据记录
RowKey应该为: 66660000431^201803011300
因为创建表时预设的Region与RowKey强相关,我们现在才可以给出本文样例所需要创建的表的” Region分割点 “信息:
假设,Region分割点为“1,2,3,4,5,6,7,8,9”,基于这9个分割点,可以预先创建10个Region,这10个Region的StartKey和StopKey如下所示:
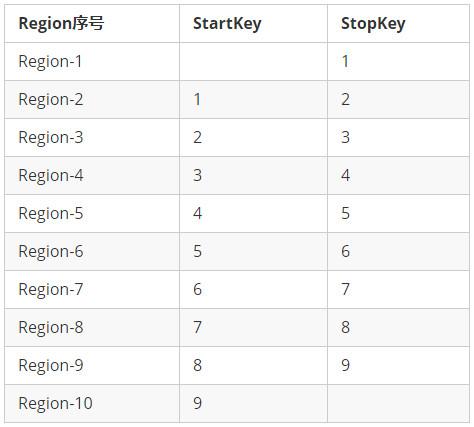
Region划分信息
-
第一个Region的StartKey为空,最后一个Region的StopKey为空
-
每一个Region区间,都包含StartKey本身,但不包含StopKey
-
由于Mobile1字段的最后一位是0~9之间的随机数字,因此,可以均匀打散到这10个Region中
定义列
每一个列在HBase中体现为一个KeyValue,而每一个KeyValue拥有特定的组成结构,这一点在上一篇文章的数据模型章节已经提到过。
所谓的定义列,就是需要定义出每一个列要存放的列族(Column Family)以及列标识(Qualifier)信息。
我们假设,存放样例数据的这个表名称为” TelRecords ” ,为了简单起见,仅仅设置了1个名为”I”的列族。
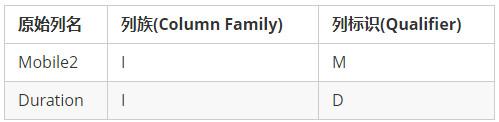
Column Family以及列标识定义
因为Mobile1与StartTime都已经被包含在RowKey中,所以,不需要再在列中存储一份。关于列族名称与列标识名称,建议应该简短一些,因为这些信息都会被包含在KeyValue里面,过长的名称会导致数据膨胀。
基于RowKey和列定义信息,就可以组建HBase的Put对象, 一个Put对象用来描述待写入的一行数据 ,一个Put可以理解成与某个RowKey关联的1个或多个KeyValue的集合。
至此,这条数据已经转变成了Put对象,如下图所示:
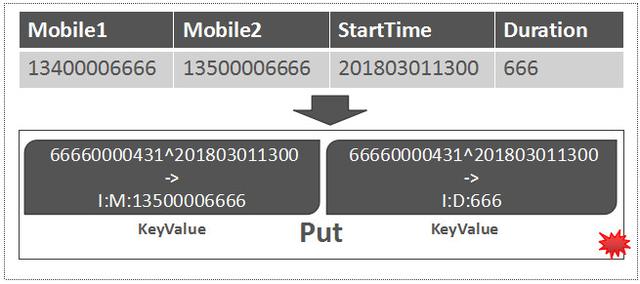
Put
数据路由
初始化ZooKeeper Session
因为meta Region存放于ZooKeeper中,在第一次从ZooKeeper中读取META Region的地址时,需要先初始化一个ZooKeeper Session。ZooKeeper Session是ZooKeeper Client与ZooKeeper Server端所建立的一个会话,通过心跳机制保持长连接。
获取Region路由信息
通过前面建立的连接,从ZooKeeper中读取meta Region所在的RegionServer,这个读取流程,当前已经是异步的。获取了meta Region的路由信息以后,再从meta Region中定位要读写的RowKey所关联的Region信息。如下图所示:
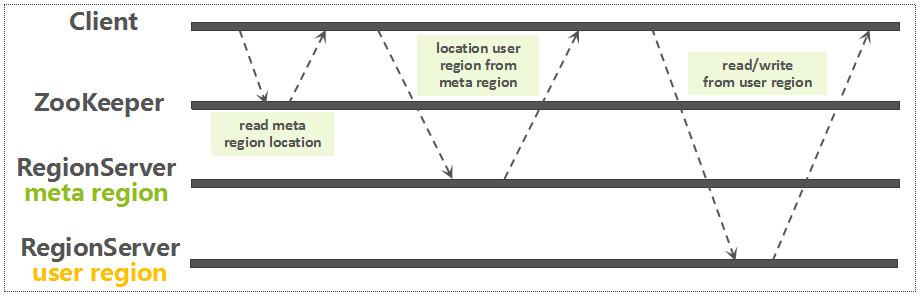
Region Routing
因为每一个用户表Region都是一个RowKey Range,meta Region中记录了每一个用户表Region的路由以及状态信息,以RegionName(包含表名,Region StartKey ,Region ID,副本ID等信息)作为RowKey。基于一条用户数据RowKey,快速查询该RowKey所属的Region的方法其实很简单:只需要基于表名以及该用户数据RowKey,构建一个虚拟的Region Key,然后通过Reverse Scan的方式,读到的第一条Region记录就是该数据所关联的Region。如下图所示:

Location User Region
Region只要不被迁移,那么获取的该Region的路由信息就是一直有效的,因此,HBase Client有一个Cache机制来缓存Region的路由信息,避免每次读写都要去访问ZooKeeper或者meta Region。
进阶内容1:meta Region究竟在哪里?
meta Region的路由信息存放在ZooKeeper中,但meta Region究竟在哪个RegionServer中提供读写服务?
在1.0版本中,引入了一个新特性,使得Master可以”兼任”一个RegionServer角色(可参考HBASE-5487, HBASE-10569),从而可以将一些系统表的Region分配到Master的这个RegionServer中,这种设计的初衷是为了简化/优化Region Assign的流程,但这依然带来了一系列复杂的问题,尤其是Master初始化和RegionServer初始化之间的Race,因此,在2.0版本中将这个特性暂时关闭了。详细信息可以参考:HBASE-16367,HBASE-18511,HBASE-19694,HBASE-19785,HBASE-19828
客户端侧的数据分组“打包”
如果这条待写入的数据采用的是Single Put的方式,那么,该步骤可以略过(事实上,单条Put操作的流程相对简单,就是先定位该RowKey所对应的Region以及RegionServer信息后,Client直接发送写请求到RegionServer侧即可)。
但如果这条数据被混杂在其它的数据列表中,采用Batch Put的方式,那么,客户端在将所有的数据写到对应的RegionServer之前,会先分组”打包”,流程如下:
-
按Region分组 :遍历每一条数据的RowKey,然后,依据meta表中记录的Region信息,确定每一条数据所属的Region。此步骤可以获取到Region到RowKey列表的映射关系。
-
按RegionServer”打包” :因为Region一定归属于某一个RegionServer(注:本文内容中如无特殊说明,都未考虑Region Replica特性),那属于同一个RegionServer的多个Regions的写入请求,被打包成一个MultiAction对象,这样可以一并发送到每一个RegionServer中。
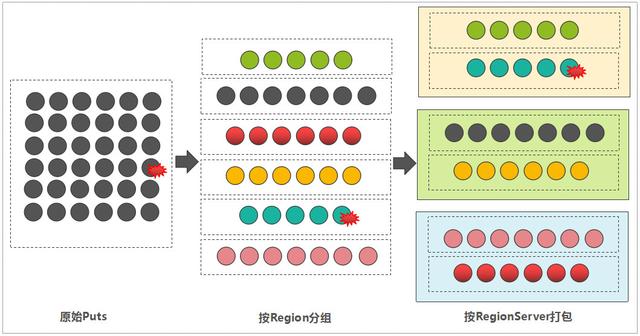
数据分组与打包
Client发送写数据请求到RegionServer
类似于Client发送建表到Master的流程,Client发送写数据请求到RegionServer,也是通过RPC的方式。只是,Client到Master以及Client到RegionServer,采用了不同的RPC服务接口。
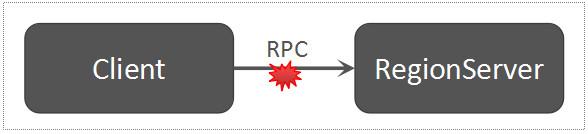
Client Send Request To RegionServer
single put请求与batch put请求,两者所调用的RPC服务接口方法是不同的,如下是Client.proto中的定义:

Client Proto定义
安全访问控制
如何保障UserA只能写数据到UserA的表中,以及禁止UserA改写其它User的表的数据,HBase提供了ACL机制。ACL通常需要与Kerberos认证配合一起使用,Kerberos能够确保一个用户的合法性,而ACL确保该用户仅能执行权限范围内的操作。
HBase将权限分为如下几类:
-
READ(‘R’)
-
WRITE(‘W’)
-
EXEC(‘X’)
-
CREATE(‘C’)
-
ADMIN(‘A’)
可以为一个用户/用户组定义整库级别的权限集合,也可以定义Namespace、表、列族甚至是列级别的权限集合。
RegionServer端处理:Region分发
RegionServer的RPC Server侧,接收到来自Client端的RPC请求以后,将该请求交给Handler线程处理。
如果是single put,则该步骤比较简单,因为在发送过来的请求参数MutateRequest中,已经携带了这条记录所关联的Region,那么直接将该请求转发给对应的Region即可。
如果是batch puts,则接收到的请求参数为MultiRequest,在MultiRequest中,混合了这个RegionServer所持有的多个Region的写入请求,每一个Region的写入请求都被包装成了一个RegionAction对象。RegionServer接收到MultiRequest请求以后,遍历所有的RegionAction,而后写入到每一个Region中,此过程是 串行 的:
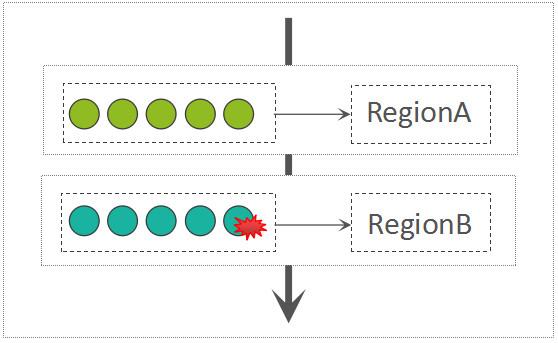
Write Per Region
从这里可以看出来,并不是一个batch越大越好,大的batch size甚至可能导致吞吐量下降。
Region内部处理:写WAL
HBase也采用了LSM-Tree的架构设计:LSM-Tree利用了传统机械硬盘的“ 顺序读写速度远高于随机读写速度 ”的特点。随机写入的数据,如果直接去改写每一个Region上的数据文件,那么吞吐量是非常差的。因此,每一个Region中随机写入的数据,都暂时先缓存在内存中(HBase中存放这部分内存数据的模块称之为 MemStore ,这里仅仅引出概念,下一章节详细介绍),为了保障数据可靠性,将这些随机写入的数据 顺序写入 到一个称之为WAL(Write-Ahead-Log)的日志文件中,WAL中的数据按时间顺序组织:
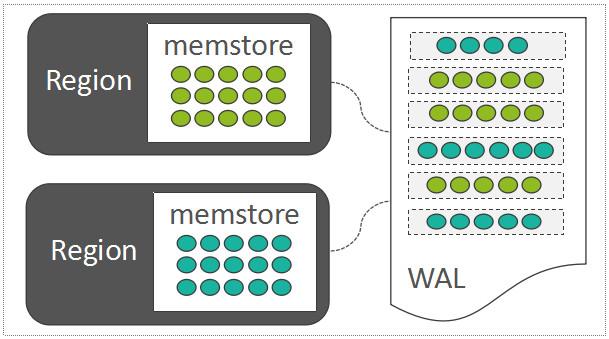
MemStore And WAL
如果位于内存中的数据尚未持久化,而且突然遇到了机器断电,只需要将WAL中的数据回放到Region中即可:

WAL Replay
在HBase中,默认一个RegionServer只有一个可写的WAL文件。WAL中写入的记录,以 Entry 为基本单元,而一个Entry中,包含:
-
WALKey 包含{Encoded Region Name,Table Name,Sequence ID,Timestamp}等关键信息,其中,Sequence ID在维持数据一致性方面起到了关键作用,可以理解为一个事务ID。
-
WALEdit WALEdit中直接保存待写入数据的所有的KeyValues,而这些KeyValues可能来自一个Region中的多行数据。
也就是说,通常,一个Region中的一个batch put请求,会被组装成一个Entry,写入到WAL中:
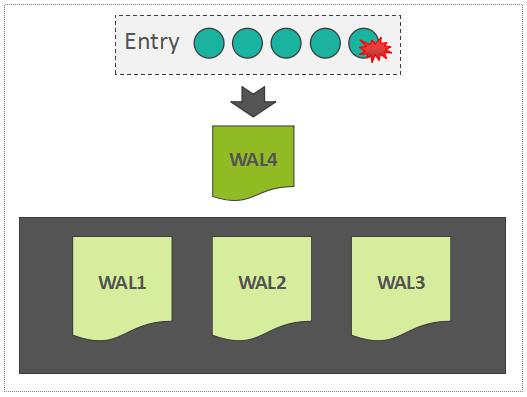
Write into WAL
将Entry写到文件中时是支持压缩的,但该特性默认未开启。
WAL进阶内容
WAL Roll and Archive
当正在写的WAL文件达到一定大小以后,会创建一个新的WAL文件,上一个WAL文件依然需要被保留,因为这个WAL文件中所关联的Region中的数据,尚未被持久化存储,因此,该WAL可能会被用来回放数据。
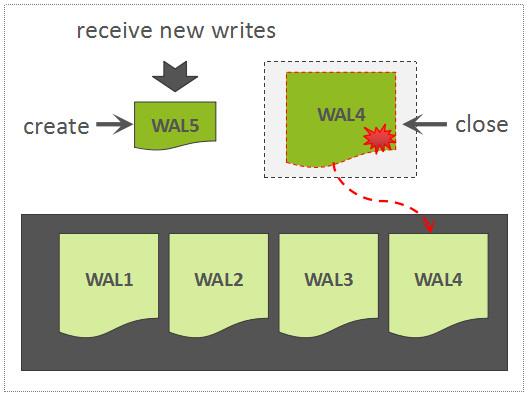
Roll WAL
如果一个WAL中所关联的所有的Region中的数据,都已经被持久化存储了,那么,这个WAL文件会被暂时归档到另外一个目录中:
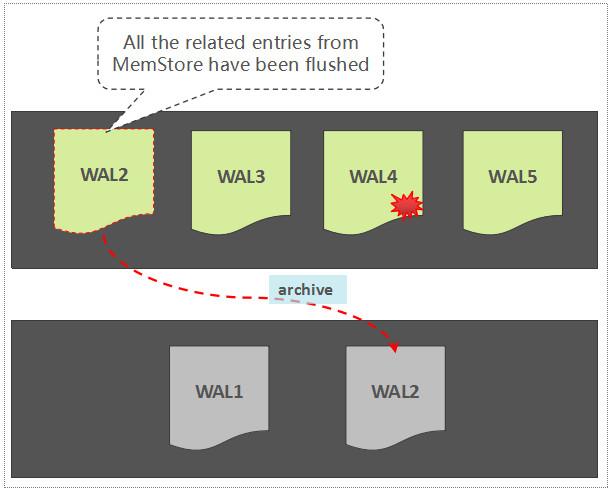
WAL Archive
注意,这里不是直接将WAL文件删除掉,这是一种稳妥且合理的做法,原因如下:
-
避免因为逻辑实现上的问题导致WAL被误删,暂时归档到另外一个目录,为错误发现预留了一定的时间窗口
-
按时间维度组织的WAL数据文件还可以被用于其它用途,如增量备份,跨集群容灾等等,因此,这些WAL文件通常不允许直接被删除,至于何时可以被清理,还需要额外的控制逻辑
另外,如果对写入HBase中的数据的可靠性要求不高,那么,HBase允许通过配置跳过写WAL操作。
思考:put与batch put的性能为何差别巨大?
在网络分发上,batch put已经具备一定的优势,因为batch put是打包分发的。
而从写WAL这块,看的出来,batch put写入的一小批次Put对象,可以通过一次sync就持久化到WAL文件中了,有效减少了IOPS。
但前面也提到了,batch size并不是越大越好,因为每一个batch在RegionServer端是被串行处理的。
利用Disruptor提升写并发性能
在高并发随机写入场景下,会带来大量的WAL Sync操作,HBase中采用了Disruptor的RingBuffer来减少竞争,思路是这样:如果将瞬间并发写入WAL中的数据,合并执行Sync操作,可以有效降低Sync操作的次数,来提升写吞吐量。
Multi-WAL
默认情形下,一个RegionServer只有一个被写入的WAL Writer,尽管WAL Writer依靠顺序写提升写吞吐量,在基于普通机械硬盘的配置下,此时只能有单块盘发挥作用,其它盘的IOPS能力并没有被充分利用起来,这是Multi-WAL设计的初衷。Multi-WAL可以在一个RegionServer中同时启动几个WAL Writer,可按照一定的策略,将一个Region与其中某一个WAL Writer绑定,这样可以充分发挥多块盘的性能优势。
关于WAL的未来
WAL是基于机械硬盘的IO模型设计的,而对于新兴的非易失性介质,如3D XPoint,WAL未来可能会失去存在的意义,关于这部分内容,请参考文章《从HBase中移除WAL?3D XPoint技术带来的变革》。
Region内部处理:写MemStore
每一个Column Family,在Region内部被抽象为了一个HStore对象,而每一个HStore拥有自身的MemStore,用来缓存一批最近被随机写入的数据,这是LSM-Tree核心设计的一部分。
MemStore中用来存放所有的KeyValue的数据结构,称之为CellSet,而CellSet的核心是一个ConcurrentSkipListMap,我们知道,ConcurrentSkipListMap是Java的跳表实现,数据按照Key值有序存放,而且在高并发写入时,性能远高于ConcurrentHashMap。
因此,写MemStore的过程,事实上是将batch put提交过来的所有的KeyValue列表,写入到MemStore的以ConcurrentSkipListMap为组成核心的CellSet中:
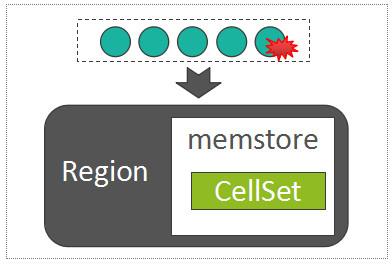
Write Into MemStore
MemStore因为涉及到大量的随机写入操作,会带来大量Java小对象的创建与消亡,会导致大量的内存碎片,给GC带来比较重的压力,HBase为了优化这里的机制,借鉴了操作系统的内存分页的技术,增加了一个名为MSLab的特性,通过分配一些固定大小的Chunk,来存储MemStore中的数据,这样可以有效减少内存碎片问题,降低GC的压力。当然,ConcurrentSkipListMap本身也会创建大量的对象,这里也有很大的优化空间,去年阿里的一篇文章透露了阿里如何通过优化ConcurrentSkipListMap的结构来有效减少GC时间。
进阶内容2:先写WAL还是先写MemStore?
在0.94版本之前,Region中的写入顺序是先写WAL再写MemStore,这与WAL的定义也相符。
但在0.94版本中,将这两者的顺序颠倒了,当时颠倒的初衷,是为了使得行锁能够在WAL sync之前先释放,从而可以提升针对单行数据的更新性能。详细问题单,请参考HBASE-4528。
在2.0版本中,这一行为又被改回去了,原因在于修改了行锁机制以后(下面章节将讲到),发现了一些性能下降,而HBASE-4528中的优化却无法再发挥作用,详情请参考HBASE-15158。改动之后的逻辑也更简洁了。
进阶内容3:关于行级别的ACID
在之前的版本中,行级别的任何并发写入/更新都是互斥的,由一个行锁控制。但在2.0版本中,这一点行为发生了变化,多个线程可以同时更新一行数据,这里的考虑点为:
-
如果多个线程写入同一行的不同列族,是不需要互斥的
-
多个线程写同一行的相同列族,也不需要互斥,即使是写相同的列,也完全可以通过HBase的MVCC机制来控制数据的一致性
-
当然,CAS操作(如checkAndPut)或increment操作,依然需要独占的行锁
更多详细信息,可以参考HBASE-12751。
至此,这条数据已经被同时成功写到了WAL以及MemStore中:

Data Written In HBase
总结
本文主要内容总结如下:
-
介绍HBase写数据可选接口以及接口定义。
-
通过一个样例,介绍了RowKey定义以及列定义的一些方法,以及如何组装Put对象
-
数据路由,数据分发、打包,以及Client通过RPC发送写数据请求至RegionServer
-
RegionServer接收数据以后,将数据写到每一个Region中。写数据流程先写WAL再写MemStore,这里展开了一些技术细节
-
简单介绍了HBase权限控制模型
需要说明的一点,本文所讲到的MemStore其实是一种"简化 " 后的模型,在2.0版本中,这里已经变的更加复杂,这些内容将在下一篇介绍Flush与Compaction的流程中详细介绍。
本文作者:毕杰山
本文首发于:NoSQL漫谈(nosqlnotes.com),欢迎关注"NoSQL漫谈"。
正文到此结束
- 本文标签: 权限控制 ip 搜索引擎 NOSQL API value 开发 http cache shell cat sql RESTful key 操作系统 src ORM 一致性 tab 压力 zookeeper 数据 实例 参数 client Action 模型 认证 线程 HBase UI 遍历 入门教程 Connection 文章 高并发 备份 tar 安全 Region Disruptor 分页 同步 1111 id java apr HBase Shell 空间 REST 性能问题 数据模型 Master 目录 负载均衡 HDFS 配置 时间 组织 总结 ACE 长连接 架构设计 https 集群 map SDN list 锁 删除 IO
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

