阿里巴巴论文提出针对影视作品的语音情感识别信息融合框架
语音领域的顶会 ICASSP 2018 将于 4 月 15-20 日在加拿大阿尔伯塔卡尔加里市举行。据机器之心了解,国内科技巨头阿里巴巴语音交互智能团队有 5 篇论文被此大会接收。本文对论文《An Ensemble Framework of Voice-Based Emotion Recognition System for Films and TV Programs》进行了介绍。
欢迎大家向机器之心推荐优秀的 ICASSP 2018 相关论文。
论文:《一种针对影视作品的语音情感识别信息融合框架》(An Ensemble Framework of Voice-Based Emotion Recognition System for Films and TV Programs)

论文链接: https://arxiv.org/abs/1803.01122.pdf
摘要:情感识别(即识别开心、忧伤等)现在愈来愈受到人们的关注,因为它可以提升人机交互界面的用户体验,进而提升产品的用户粘性,并在心理医疗健康方面等具有独特价值。基于语音的情感识别尤其具有现实意义,因为基于语音的人机交互界面具有相对较低的硬件要求。但是,在现实中,周围环境中存在着许多噪声,这些噪声将会降低系统的识别性能。在本文中我们提出了一套包含多个子系统的复合情感识别框架。这一框架会深入挖掘输入语音中与情感相关的各个方面的信息,从而提高系统的顽健性。
研究背景
在现实生活中,基于语音的人工智能系统处在复杂的场景当中,因而会面临各种各样的挑战。对于情感识别来说,主要的挑战来自于两个方面:1. 周围存在背景噪声,因而传统的特征提取,比如在整句话层面上提取统计参数的方法将受到严重干扰; 2. 用户说话的方式比较随意,不能如实验室中那样很好地控制输入语音,有时候用户会有一些发出一些非语音的声音,比如哭声,笑声,咳嗽声等,这些声音有些与情感有关,有些则完全无关。面对这两个挑战,我们提出了一套复合情感识别框架。这套框架会对底层和高层特征进行识别,因此可以对一些背景噪声有一定的顽健性;同时这套框架也会利用注意力模型(attention model)学习特征序列中重要时间点的特征,以及利用语音中的文本信息对情感信息进行分类——这些机制可以有效避免用户的非语音声音或者长静音对识别的干扰。
复合情感识别框架
在本文中,我们提出了一套复合的情感识别框架。这一框架由若干子系统组合而成,其中包括基于整句话(utterance level) 底层特征 (low level descriptor) 的识别系统,基于整句话高层表述的识别系统,基于序列特征的识别系统,以及基于语义信息的识别系统(见 Fig 1)。
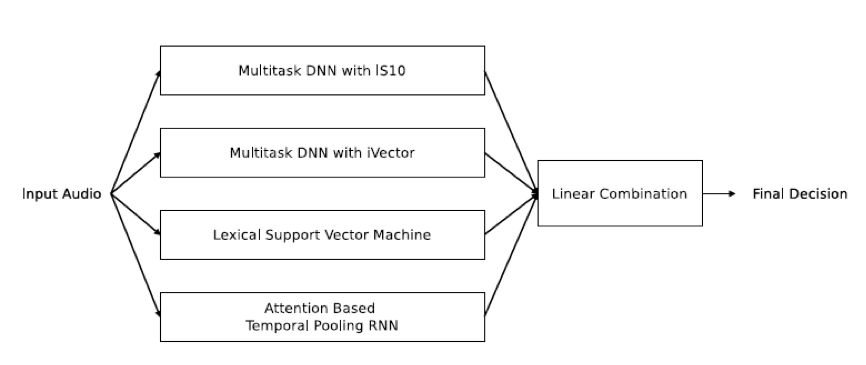
Fig 1 The proposed ensemble framework for emotion recognition
其中,基于整句话底层特征的识别系统为一个深度神经网络,采用多任务训练 (multitask learning) 方式进行训练 (见 Fig 2),采用的特征为从 opensmile 提取的 Interspeech 2010 LLD 特征集。在这个神经网络中,我们在 trunk 部分有两层隐层(hidden layer)(每层 4096 个神经元),在 branch 部分,每个任务有一层隐层(1024 神经元),之后有一层 柔性最大激活函数(softmax)。其中我们的神经元均使用精馏线性单元(rectified linear unit)。
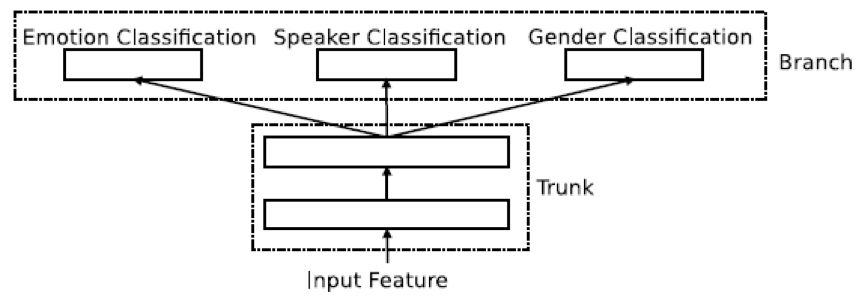
Fig 2 The multitask learning DNN
基于整句话高层表述的识别系统也是采用一个深度神经网络,同样也是采用多任务训练方式进行训练。采用的特征为 200 维 iVector(从一个由 4000 小时语音训练的语音识别 (ASR) 系统中提取)。这里我们采用的网络结构与底层特征识别系统的神经网络相同,唯一的区别为,这个一个系统在 trunk 部分每一层只有 1024 个神经元。
基于序列特征的子系统采用递归神经网络,对输入序列进行建模,在递归神经网络上采用基于 attention model 的加权池化层 (weighted pooling)(见 Fig 3),将输入的一个序列提取成一个高层表述。基于这个高层表述进行分类。这一子系统也采用多任务训练方式进行训练。这一递归网络与上述神经网络的大致结构相似,区别为在 trunk 部分,我们使用了 RNN,并且在 RNN 上利用 attention based weighted pooling layer 来提取高端表述(high level representation)。
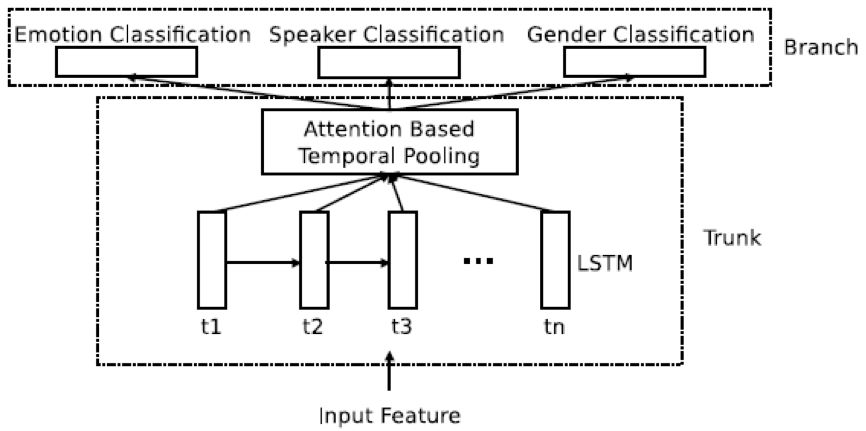
Fig 3 The attention based weighted pooling RNN
上述三个子系统中的多任务训练,我们采用三个任务,情感识别为主任务(权重为 1),说话人识别(权重为 0.3)和性别识别(权重为 0.6)为辅助任务。在多任务训练中,由于系统可以看到更多的任务信息,可以更好地检视输入的特征,因此可以更好地训练神经网络。
除了上述三个子系统外,还有一个子系统是基于文本的子系统。该子系统采用支持向量机(support vector machine),使用了从语音识别系统中获取的文本。这一系列子系统的识别结果会通过线性相加组合起来,从而得到最后的结果。
实验
我们在多模情感识别竞赛 2017 数据集(MEC 2017) 上测试这一套框架。MEC 2017 数据集是采集自影视作品,其中包含了许多背景噪声(汽车噪声,工厂噪声等等),以及说话人的非语音声音(哭声、笑声等等)。其中各类情感的分布如下。
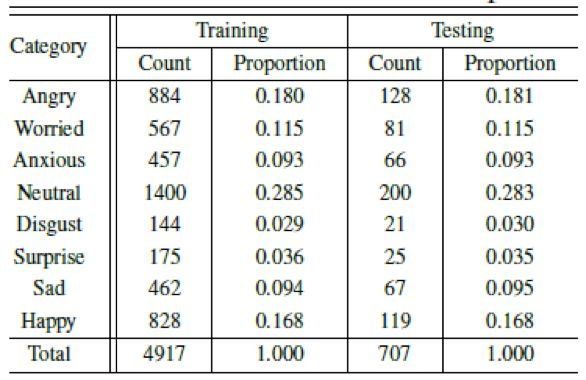
根据 MEC 2017 的建议,我们采用无权重平均 F-score(MAF)和准确率作为我们的衡量标准。考虑到数据库中的数据不平衡性,我们主要关注 MAF 指标。
实验中,我们采用两套系统作为参照系统,一套是 MEC2017 建议的 random forest 系统,还有一套是利用 Interspeech 2017 特征集搭建 DNN 的情感识别系统。具体实验结果如下:

由实验结果可以看到,我们提出的这一套框架,可以远远超过参照系统(分别增加了 11.9% 和 7.8% 准确率)。即使四个子系统的识别率参差不齐,最后组合之后的结果依然超过了所有的子系统,可以推测这个过程中全面检视输入信息,可以很有效的提高识别准确率和系统顽健性。
结论
我们将这一套系统应用于中文的影视作品数据库上。之所以应用到这一数据库上,是因为影视作品中的场景比较接近现实生活。结果显示,我们的系统可以全面超越现有的基于深度学习的前沿系统。这一成功,可以说明我们的这一套框架可以有助于在现实中实现情感识别。
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

