MySQL智能调度系统
普通的数据库调度系统是按照一些重要的软件和硬件指标,将实例调度到机器上,这样的调度方式容易造成资源的浪费。本文将尝试根据数据库实例画像和线上机器的画像,制定合理的资源分配策略,最终实现资源节约,并为每季度的机器申请提供决策支持。
MySQL调度系统
本文根据重要指标对MySQL实例进行画像,并根据机器的指标对机器进行画像,将实例和机器进行合理的搭配,最大限度地节省资源。调度系统的框架图如下图,
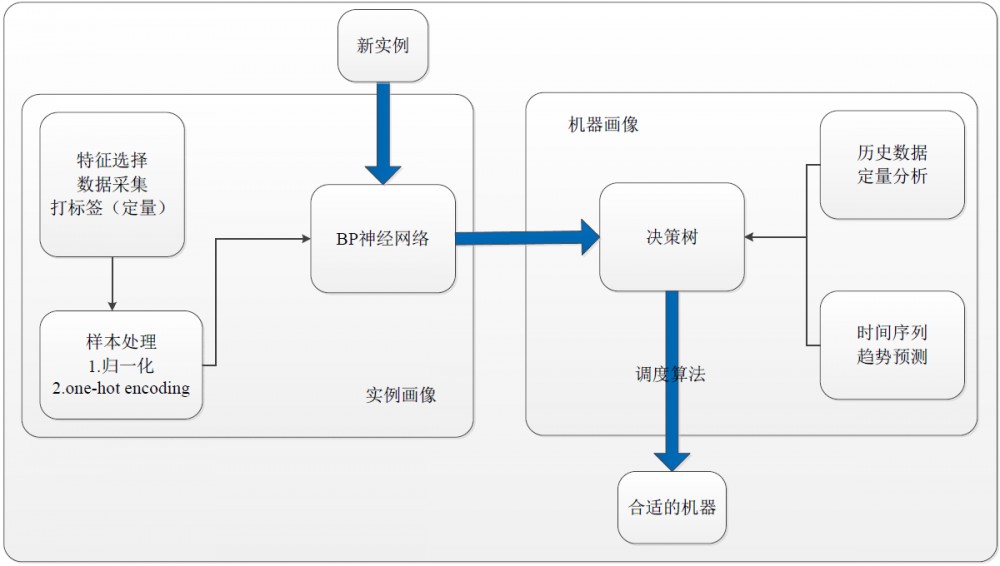
系统主要分为两部分:实例画像和机器画像,下面将对这两部分进行介绍。
实例画像
数据处理
结合线上MySQL集群的情况,确定主要指标为:CPU使用率,内存使用率,磁盘占用率,IO读,IO写,网卡入流量,网卡出流量,其中设定CPU使用率,内存,磁盘占用率为重要特征。因为同一端口的同机房主从库以及不同机房的从库之间,以上特征都会有不同的特征表现,我们决定以数据库实例(即监控实例)为基本单位,进行数据采集。我们使用定量分析值(基于小波分解)作为每个指标的历史数据的平均水平。
对于实例分类数目的制定,会涉及到的因素较多,先从主要维度上分为4大类(低消耗端口、计算型端口、存储型端口和重点综合型端口),后续可以根据需要在大类的基础上再进行细分。根据指标定量分析值,对每个实例进行人工的标注。
分类模型
经过上一个步骤的数据清洗和标注以后,得到了模型所需要的样本。由于样本中有些属性值比较大,比如网卡流量,而有些属性值比较小,比如cpu空闲率,他们之间差值比较大,所以我们首先需要对样本的值进行归一化操作。本文使用了min-max归一化的方法来处理数据。为了使用bp神经网络达到多分类的效果,项目中使用“one-hot encoding”对label进行处理。例如,label为1的经过处理以后,变为[1,0,0,0],其他的标签类似。
我们选择bp神经网络来完成多分类任务,其中输入层的神经元个数是7,隐藏层为14,输出层为4。根据上面的神经元个数,我们可以构建出一个bp神经网络。
为了验证模型的准确率,我们将已经标注的900多个样本按照7:3的比例进行了划分,即训练集有620,测试集269,用测试集进行测试,准确率均高于95%,能够达到预期的效果。
机器画像
我们CPU使用率、内存使用率和磁盘占用率三个比较重要的特征进行了预测,其中CPU和内存采用的是基于小波分解的BP神经网络模型,而磁盘占用率使用ARIMA模型。
有了上述三个重要指标的预测值和定量值以后,根据决策树模型,我们就可以对机器进行分类。
效果验证
该调度系统主要针对资源使用不均衡的机器(如磁盘使用率为80%,但内存和CPU使用率不足20%,或者内存利用率很高,但磁盘浪费60%以上), 这种机器大部分已经被标记为“高负载”或“不可用”,存在严重资源浪费的情况,已经不能分配新实例。该调度系统能根据各个机器的资源使用情况划分为不同种类,并将资源严重倾斜的机器筛选出来,进行资源的重新编排。通过合理的调度算法实现尽可能少的数据库迁移, 使机器负载达到均衡。
通过对一个机房机器的调度测试,发现本调度系统使至少三分之一的高负载机器,变为可用状态,可以继续往该机器上分配新的数据库实例,其它则变为各类资源使用情况均衡的高负载机器(即各个维度的资源都是高负载)。验证结果表明:本调度系统能在现有状况下,进一步提高机器资源的利用率,缩减成本。
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

