Google和Netflix共同开源新的Canary分析工具Kayenta
编者按
Google和Netflix联合发布了全新的开源Canary分析工具Kayenta。Canary(金丝雀部署)是现代Devops和持续交付中重要的一环,指的是把少量(通常1%-3%)的流量导到含有新版本的canary部署上运行一段时间并和当前的生产环境比较,再决定是否将新版本部署到所有机器的过程。转载请注明出处和原文链接。
以下是项目代码:
为了成规模的实现持续交付,你不仅需要快速地发布软件更新,更需要能安全地发布。今天,Google和Netflix很高兴的发布Kayenta,一款开源的自动化Canary分析服务,该服务能让团队降低高速发布新部署时的相关风险。
由Google和Netflix联合开发的Kayenta是由Netflix内部的Canary系统进化而来,然后重新定义得完全开放,可扩展而且可以处理更多高级的用户案例。它可以给与企业团队快速推送更改到生产环境的信息,通过减少易出错又耗时耗力的人工或者临时的Canary分析。
这允许团队能够轻易的在Spinnaker流水线内搭建起自动的canary分析步骤。Kayenta从源头取回用户设置的数据,运行统计分析再为这次canary提供一个聚合的分数。基于这个分数和设定的成功率限制,Kayenta可以自动接收或者拒绝这次canary,或者出发人工审查逻辑。
“自动化的canary分析是Netflix生产部署重要的一环,我们很兴奋能够发布Kayenta。我们和Google在Kayenta上的合作产生了一种灵活的架构,这个架构会帮助实现在一系列的部署场景下使用自动化的canary分析,这些场景包括应用,配置和数据的更改。Spinnaker和Kayenta的整合让团队可以专注于流水线和部署而不需要用另一个工具做canary分析。年底之前,我们预计Kayenta会每天做出数千个canary判断。Spinnaker和Kayenta都是快速,高可靠又易用的工具,帮助在减少部署风险同时实现快速大规模部署。”
— Greg Burrell, Senior Reliability Engineer at Netflix
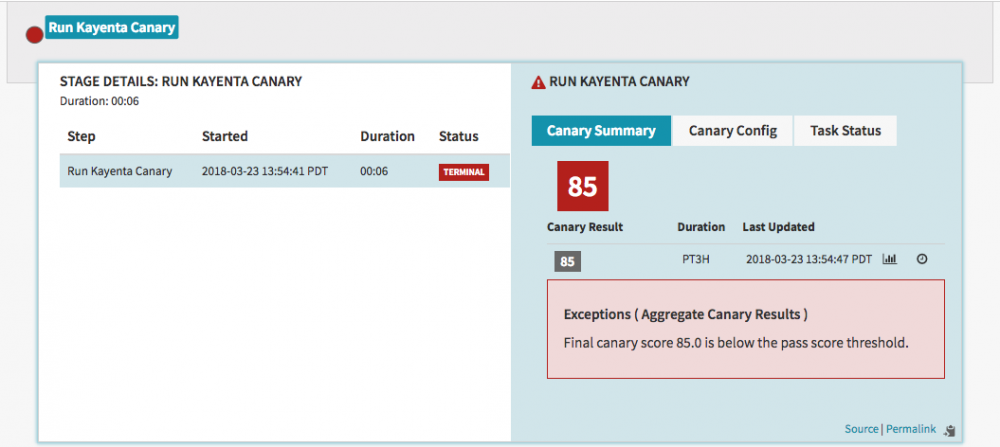
Kayenta的最终分析报告如下图所示:
大规模持续交付的挑战
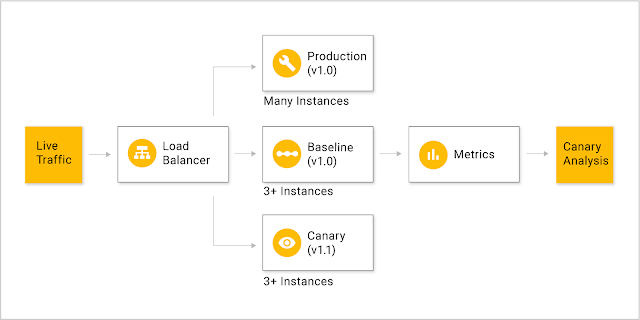
Canary分析是减少生产环境中更新对终端用户影响的风险的好方法。基本的思路是把很小的一部分生产环境流量,例如1%,同时导到含有最新更新的部署的服务器(这也就是所谓的canary)以及与目前生产环境代码和配置一样的服务器(基准参考)上去。生产环境本身没有任何更改。典型地配置是canary和基准配置分别分配三台服务器,生产环境分配多台服务器。建立基准参考服务器是为了减少启动效应从而降低基准服务器和canary服务器间的系统误差。之后系统会比较canary服务器和基准服务器之间关键指标的差别。要继续部署的话需要canary服务器的性能不差于基准服务器的性能。
Canary分析过程通常以人工的,临时的或者统计学上错误的方式进行的。比如说,一个团队成员会人工的检查canary和生产环境的日志和显示多项指标的图表(比如CPU使用,内存使用,错误率,每个请求的CPU使用),来决定是否继续部署新的修改。人工或者临时的canary分析会造成下列额外的挑战:
-
速度和规模瓶颈:对于Google或者Netflix这样企业,每天都要在多个部署之间做多个性能比较,手工的canary分析实际上不可行。即使对于其他的企业,手工的canary分析也无法跟上持续交付的速度。为每个canary发布都配置仪表图需要大量人力,手工的比较canary和基准之间的几百个指标也是费事费神。
-
考虑人工错误:手工canary分析需要主观评估,容易导致认为的错误和偏见。人们通常难以区分真正的问题和噪音,也容易在理解指标和日志的时候产生错误。人工的收集,检测然后聚集多个canary指标更让人工错误容易出现。
-
错误决策的风险:比较一个新部署和一个在生产环境中运行很久服务器之间的短期指标是一种不正确的评估canary健康程度的方法。主要原因是你无法知道性能的差距是到底是统计上相关的还是只是随机事件。结果就是你可能会把不好的更新部署到生成环境中。
-
对于高级用例的支持不佳:要优化持续交付周期中的canary分析,你需要高置信度地知道是接受还是拒绝一个canary。然而增加接受还是拒绝canary的置信度非常耗时,因为你无法处理诸如实时调整边界和参数这样的高级用例。
Kayenta的方法
和人工临时的分析相比,Kayenta自动对用户定义的指标上运行统计测试,并且返回一个总分(成功,模棱两可或者失败)。这种严格的分析会帮助做出继续部署或者回国的决定,并且识别传统canary分析捕捉不到的不好的部署。Kayenta的其他好处还包括:
-
开放:想要使用商用自动canary分析的企业团队必须要把私密的指标提供给软件提供商,这会导致对于供应商的严重依赖。
-
为混合云和多云量身定做:Kayenta为多canary间检测问题提供了一致的方法,无论目标环境是什么。再考虑它和Spinnaker的整合,Kayenta使团队能够在多环境中进行自动canary分析,包括Google Cloud Platform (GCP),Kubernetes,本地机房以及其他的云服务提供商。
-
可扩展:Kayenta让添加新的指标源,判断条件和数据源变的容易。因此,你可以配置Kayenta根据你的需求服务不同的环境。
-
快速提供置信度:Kayenta允许在进行自动canary分析的时候实时调整标准和参数。这让你可以一旦收集足够数据就决定是接受还是拒绝一个canary。
-
低学习成本:开始试用Kayenta非常容易。不用写定制脚本或者人工获取canary指标,合并这些指标在在其之上运行统计分析来决定是否部署或者回滚这个canary。Kayenta会在canary分析结果中提供链接满足深度的诊断需求。
-
洞察:对于高级用例来说,Kayenta能帮助进行回溯canary分析。这给了工程和运营团队如何逐渐细化和提高canary分析提供了洞察。
与Spinnaker整合

Kayenta与Spinnaker的整合在Spinnaker中提供了一个新的“Canary”流水线步骤。在其中你可以定义使用哪些指标使用某个来源,包括诸如Stackdriver, Prometheus, Datadog或者Netflix的内部工具比如Atlas。接下来Kayenta从源头拿到指标数据,创建一对对照/实现组的时间序列并且调用一个Canary Judge。Canary Judge会运行统计测试,单独评估每一个参数,然后返回一个范围在0-100的总分,总分是基于预先设置好的指标重要度算得的。基于用户的配置,分数可以被归类成“成功”,“模棱两可”或者“失败”。成功会把canary继续往生产环境部署,模棱两可分会触发人工审核逻辑,失败触发回滚。
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

