字符集及其存储方式(解决乱码问题)
阅读大概需要4分钟 
在我们进行 文本挖掘 或 处理文档 时,都要面临一个最最基本的问题->就是解决 乱码 问题。在此,介绍最本质的字符编码。
我们熟悉的有三种: ASCII 字符集,中文字符集( GBK ), Unicode 字符集
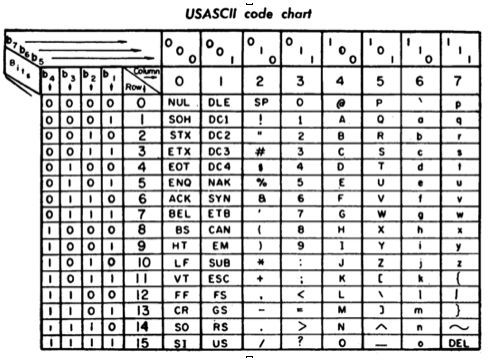
ASCII字符集
故事:
美国信息交换标准代码,这是计算机上 最早 使用的通用的编码方案。那个时候计算机还只是拉丁文字的专利,根本没有想到现在计算机的发展势头,如果想到了,可能一开始就会使用unicode了。当时绝大部分专家都认为,要用计算机,必须熟练掌握英文。这种编码占用 7个Bit ,在计算机中占用一个字节,8位, 最高位 没用,通讯的时候有时用作 奇偶校验位 。因此ASCII编码的取值范围实际上是:0x00-0x7f,只能表示 128 个字符。后来发现128个不太够用,做了扩展,叫做 ASCII扩展编码 ,用足八位,取值范围变成:0x00-0xff,能表示 256 个字符。其实这种扩展意义不大,因为256个字符表示一些非拉丁文字远远不够,但是表示拉丁文字,又用不完。所以扩展的意义还是为了下面的 ANSI编码 服务。
- 单字节 存储
用 一个字节 (8位)来表示字符
共2^7=128个字符
字符集:规则的集合
字符 -> 字符对应的二进制数字
存储方式:
字符对应的二进制数字 -> 实际存储数值
中文字符集
GBK 全称《汉字内码扩展规范》(GBK即“国标”、“扩展”汉语拼音的第一个字母,英文名称: Chinese Internal Code Specification ) ,中华人民共和国全国信息技术标准化技术委员会1995年12月1日制订,国家技术监督局标准化司、电子工业部科技与质量监督司1995年12月15日联合以技监标函1995 229号文件的形式,将它确定为技术规范指导性文件。这一版的GBK规范为1.0版。
产生原因:ASCII 字符集 无法表示中文
GBK等汉字编码:
多字节 存储, 兼容ASCII , 存储方式:EUC4-CN
高位为1 的字节,表示其是一个双字节二进制码
Unicode
Unicode (统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为 每种语言 中的 每个字符 设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。1990年开始研发,1994年正式公布。
支持世界上 几乎所有字符 的字符集
表示范围:0000 ~ 10FFFF、 100多万个符号
存储方式:UTF-8, UTF-16, UTF-32
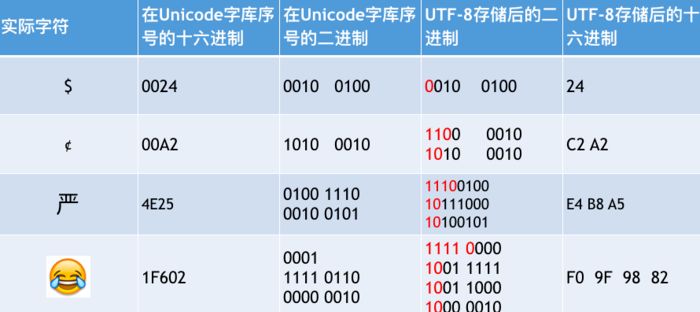
UTF-8:
UTF-8 (8-bit Unicode Transformation Format)是一种针对Unicode的 可变长度 字符编码,又称 万国码 。由Ken Thompson于1992年创建。现在已经标准化为RFC 3629。UTF-8用 1到4个字节编码 Unicode字符。用在网页上可以同一页面显示中文简体繁体及其它语言(如英文,日文,韩文)。
变长存储 : 使用1~4个字节。
对于 单字节 的符号,字节的 第一位设为0 ,后面7位为这个符号的unicode码。因此 对于英语 字母,UTF-8编码和ASCII码是 相同 的。
对于 n字节 的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。

很明显,在 C++ 中为了解决是汉字还是字母的问题上,判断其二进制 首位 即可。而java则不用,有直接扫描字符的函数。(还有同学问了,那为啥要用C++...a simple reason 嘛,C++快  )
)
再举个实例:
OK,回归主题: 乱码 ?
例如:UTF-8存储方式的文件,用GBK方式读取 or GBK存储方式的文件,用UTF-8方式读取 就会产生乱码
ANSI - Windows中默认的字符集
这个还得了解!
在你在 windows 下保存一个文本时, 默认 的第一个保存方式就是这个东东。
在中文Windows操作系统中:
对于英文文件是ASCII字符集。
对于简体中文文件是 GB2312 字符集。
繁体中文版会采用 Big5 字符集。
在日文Windows操作系统中:
对于英文字符是ASCII字符集。
对于日文字符是 Shift_JIS 。
不同 ANSI 编码之间 互不兼容 ,当信息在国际间交流时, 无法 将属于两种语言的文字, 存储在同一段 ANSI 编码的文本中。
参考潘达师兄ppt
每日托福单词
consensus n. 一致意见,共识
stereotype n. 思维定势 v. 刻板地对待
larva n.幼虫
vague adj. 含糊的,不明确的
saint n. 圣徒,圣人
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

