用TensorFlow实现物体检测的像素级分类
雷锋网 AI 科技评论按:本文由「图普科技」编译自 Using Tensorflow Object Detection to Do Pixel Wise Classification 。
最近,TensorFlow 的「物体检测 API」有了一个新功能,它能根据目标对象的像素位置来确定该对象的像素。换句话来说,TensorFlow 的物体检测从原来的图像级别成功上升到了像素级别。
使用 TensorFlow 的「物体检测 API」图片中的物体进行识别,最后的结果是图片中一个个将不同物体框起来的方框。最近,这个「物体检测 API」有了一个新功能,它能根据目标对象的像素位置确定该对象的像素,实现物体的像素分类。

TensorFlow 的物体检测 API 模型——Mask-RCNN
实例分割
「实例分割」是物体检测的延伸,它能让我们在普通的物体检测的基础上获取关于该对象更加精确、全面的信息。
在什么情况下我们才需要这样精确的信息呢?
-
无人驾驶汽车
为了确保安全,无人驾驶汽车需要精确定位道路上其他车辆和行人。
-
机器人系统
机器人在连接两个部件时,如果知道这两个部件的确切位置,那么机器人的操作就会更加高效、准确。
「实例分割」的方法有很多,TensorFlow 进行「实例分割」使用的是 Mask RCNN 算法。
Mask R-CNN 算法概述
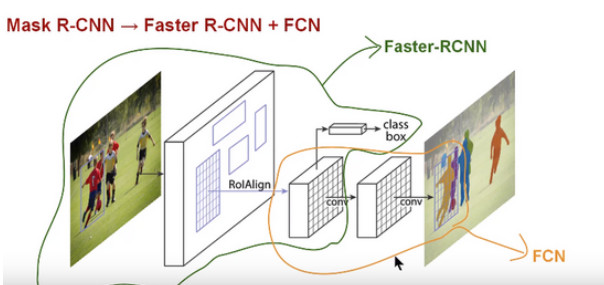
Mask RCNN 算法架构
在介绍 Mask RCNN 之前,我们先来认识一下 Faster R-CNN。
Faster-RCNN 是一个用于物体检测的算法,它被分为两个阶段:第一阶段被称为「候选区域生成网络」(RPN),即生成候选物体的边框;第二阶段本质上是 Fast R-CNN 算法,即利用 RolPool 从每个候选边框获取对象特征,并执行分类和边框回归。这两个阶段所使用的特征可以共享,以更快地获得图像推算结果。
Faster R-CNN 对每个候选对象都有两个输出,一个是分类标签,另一个是对象边框。而 Mask-RCNN 就是在 Faster R-CNN 的两个输出的基础上,添加一个掩码的输出,该掩码是一个表示对象在边框中像素的二元掩码。但是这个新添加的掩码输出与原来的分类和边框输出不同,它需要物体更加精细的空间布局和位置信息。因此,Mask R-CNN 需要使用「全卷积神经网络」(FCN)。

全卷积神经网络(FCN)的算法架构
「全卷积神经网络」是「语义分割」中十分常见的算法,它利用了不同区块的卷积和池化层,首先将一张图片解压至它原本大小的三十二分之一,然后在这种粒度水平下进行预测分类,最后使用向上采样和反卷积层将图片还原到原来的尺寸。
因此,Mask RCNN 可以说是将 Faster RCNN 和「全卷积神经网络」这两个网络合并起来,形成的一个庞大的网络架构。
实操 Mask-RCNN
-
图片测试
你可以利用 TensorFlow 网站上的共享代码来对 Mask RCNN 进行图片测试。以下是我的测试结果:

Mask RCNN on Kites Image
-
视频测试
对我来说,最有意思的是用 YouTube 视频来测试这个模型。我从 YouTube 上下载了好几条视频,开始了视频测试。
视频测试的主要步骤:
1. 使用 VideoFileClip 功能从视频中提取出每个帧; 2. 使用 fl_image 功能对视频中截取的每张图片进行物体检测,然后用修改后的视频图片替换原本的视频图片; 3. 最后,将修改后的视频图像合并成一个新的视频。
GitHub地址为: https://github.com/priya-dwivedi/Deep-Learning/blob/master/Mask_RCNN/Mask_RCNN_Videos.ipynb
Mask RCNN 的深入研究
下一步的探索包括:
-
测试一个精确度更高的模型,观察两次测试结果的区别;
-
使用 TensorFlow 的物体检测 API 在定制的数据集上对 Mask RCNN 进行测试。
本文由雷锋网专栏作者编译,转载需经雷锋网 (公众号:雷锋网) 许可。
via kdnuggets
雷锋网版权文章,未经授权禁止转载。详情见 转载须知 。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

