自监督对抗哈希SSAH:当前最佳的跨模态检索框架
简介
随着来自不同种类搜索引擎和社交媒体的多媒体数据的爆炸式增长,近年来跨模态检索已经成为了一个人们急需面对的议题 [20, 21, 22, 23, 24, 25, 29, 35, 36, 41, 42, 45]。跨模态检索的主要目标是用一种模态(比如:文本)的查询请求来检索具有相似语义但处于其他模态(比如:图片) 的内容。考虑到在实际应用场景中对于低存储消耗和快速响应查询的要求,哈希算法可以通过给相似的跨模态内容赋予相似的哈希码的方式,将高维的多模态数据映射到一个公共的哈希码空间,因而在跨模态检索领域获得了广泛的关注。考虑到不同模态的内容在特征表示和分布上存在着极大的差异(即模态鸿沟),如何探索不同模态的语义关联的足够多细节继而打破模态鸿沟就显得十分必要了。目前大多数的浅层跨模态哈希方法(不论是无监督方法 [2, 10, 14, 18] 还是有监督方法 [7, 17, 19, 26, 30, 40, 33])都试图在公共的哈希空间中捕捉语义的关联。而相比无监督方法,有监督方法能够充分利用语义标签或者关联信息提取跨模态之间的相关性,从而获得更好的性能。然而,几乎所有的已有浅层跨模态哈希方法都基于手工编写的特征,这就一定程度上限制了实例的可区分性表征,继而降低了学习到的二进制哈希码的准确率。
近年来,深度学习已经在不同应用中的高可区分性特征学习上获得了成功。然而,尽管深度学习可以更有效地捕捉不同模态内容之间的非线性相关性,目前将深度学习应用到跨模态哈希上的工作相对还比较少 [3, 9, 12, 31, 43]。此外,值得一提的是,目前的深度跨模态哈希方法中仍然存在着一些常见缺陷。首先,这些方法仅仅直接使用单类别标签来度量不同模态内容之间的语义相关性。而事实上,在标准的跨模态基准数据集比如 NUS-WIDE [6] 和 Microsoft COCO [15] 中,一幅图像可以分配不同类别的标签。由于这种方式可以更准确地描述不同模态内容之间的语义相关性,因而它是非常有益的。其次,这些方法往往通过使用特定预定义的损失函数来限制相关的哈希码从而强制减少模态鸿沟 [4]。其中使用的哈希码往往小于 128 位。这意味着大多数有用的信息都被消除了,使得哈希码无法捕捉到不同模态之间的内在一致性。相比而言,高维的特定模态的特征往往包含着有助于打破模态鸿沟的更多冗余信息。因此,如何促进获得更多的冗余语义相关信息,并建立更准确的模态关联,对于在真实应用中获得可观的性能显得尤为重要。
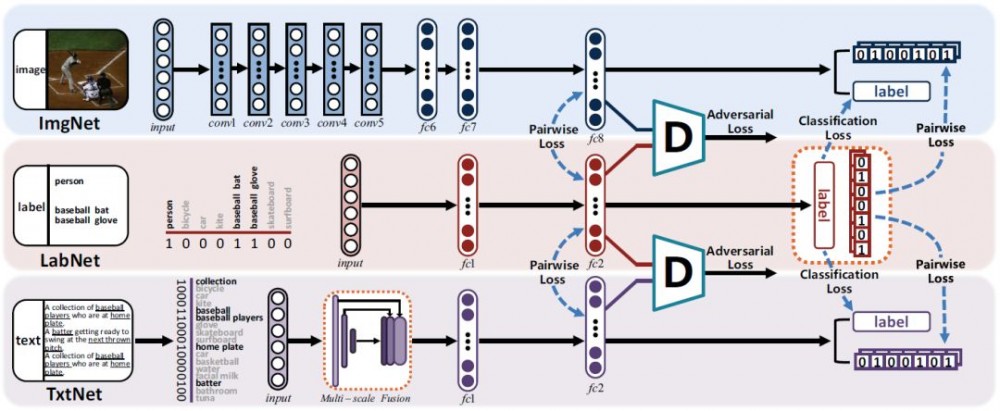
图 1: 本文提出的 SSAH 模型框架。
在这篇论文中,研究者提出了一个全新的自监督对抗哈希(SSAH)方法来帮助解决跨模态检索问题。具体来说,作者使用两个对抗网络来联合学习高维特征和它们在不同模态下的对应哈希编码。同时,一方面使用对抗学习来有监督地最大化不同模态之间语义关联和特征分布一致性;另一方面无缝添加一个自监督的语义网络,来发现多标签标注中的语义信息。该模型的主要亮点如下:
-
本文提出了一个新型的用于跨模态检索的自监督对抗哈希模型。据作者介绍,这是第一批尝试将对抗学习应用到跨模态哈希问题的工作之一。
-
本文将自监督语义学习和对抗学习结合,以尽可能保留不同模态之间的语义相关性和表征一致性。使用这种方式可以有效地打破模态鸿沟。
-
基于三个评测数据集的大规模实验结果,表明本文提出的 SSAH 明显优于当前最好的基于传统方法和深度学习方法的跨模态哈希算法。
本文提出的 SSAH
在不丢失通用性的同时,研究者聚焦于双模态(即图像和文本)上的跨模态检索。图 1 的流程图可以很好地展示 SSAH 方法的一般原则。这个方法主要由三个部分组成,包括了一个自监督语义生成网络(LabNet)和两个分别用于图像和文本的对抗网络(ImgNet 和 TexNet)。
具体来说,LabNet 的目标设定使它可以从多标签标注中学习到语义特征。然后,它可以被视为用于监督两个阶段的模态特征学习的公共语义空间。第一个阶段,在公共的语义空间中将来自不同生成网络的模态特定的特征联系起来。考虑到深度神经网路的每个输出层都包含了语义信息,在公共的语义空间中将模态特定的特征联系起来,可以帮助提高模态之间的语义相关性。第二个阶段,把语义特征和模态特定的特征同时馈送进两个判别网络。因此,在相同语义特征的监督下,两个模态的特征分布最终会趋于一致。

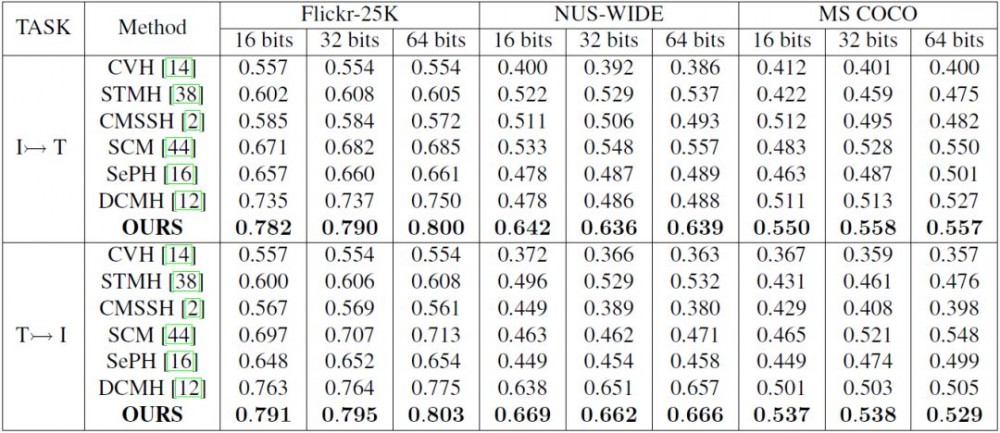
表 2:不同方法在不同基准上的 MAP 结果。加粗内容为最高的准确率。基线方法基于 CNN-F 特征。
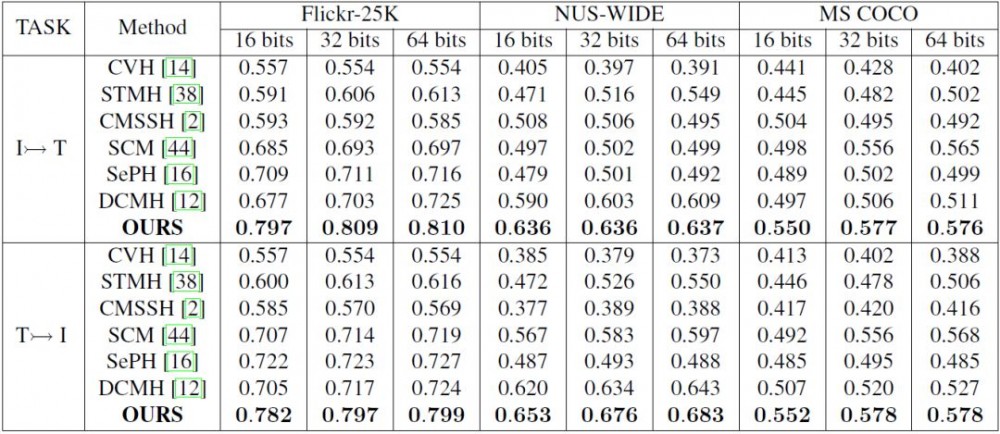
表 3:不同方法在不同基准上的 MAP 结果。加粗内容为最高的准确率。基线方法基于 vgg19 特征。
论文:Self-Supervised Adversarial Hashing Networks for Cross-Modal Retrieval(用于跨模态检索的自监督对抗哈希网络)

论文地址:https://arxiv.org/abs/1804.01223
摘要:由于深度学习的成功,最近跨模态检索获得了显著发展。但是,仍然存在一个关键的瓶颈,即如何缩小多模态之间的模态差异,进一步提高检索精度。本文提出了一种自监督对抗哈希(SSAH)方法。这种将对抗学习以自监督的方式引入跨模态哈希的研究,目前还处于研究早期。这项工作的主要贡献是采用了两个对抗网络来最大化不同模态之间的语义相关性和表征一致性。另外,我们还设计了一个自监督的语义网络,这个网络针对多标签信息进一步挖掘高层语义信息,使用得到的语义信息作为监督信息来指导不同模态的特征学习过程,以此,模态间的相似关系可以同时在共同语义空间和 Hamming 空间内得以保持,有效地减小了模态之间的差异,进而产生精确的哈希码,提高检索精度。在三个基准数据集上进行的大量实验表明所提出的 SSAH 优于最先进的方法。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

