人人都可参与的AI技术体验:谷歌发布全新搜索引擎Talk to Books
-
项目链接:https://research.google.com/semanticexperiences/
-
预训练模型下载地址:https://tfhub.dev/google/universal-sentence-encoder/1
这一项目目前包含交互式 AI 语言工具,它展示的主要人工智能技术是「词向量」。词向量是一种自然语言处理形式,向量的一些几何性质能够很好的反映词的句法或者句义。例如,两个词向量的差值对应词的关系,词向量的距离则对应词的相关或者相似性。对于选定的一组词,将其向量投影到空间中,词义相近的词向量在向量空间中表现出了有趣的聚类现象。例如国家名词聚成一类,大学名称则形成另一个聚类。
自然语言理解在过去几年发展迅速,部分要归功于词向量的发展,词向量使算法能够根据实际语言的使用实例了解词与词之间的关系。这些向量模型基于概念和语言的对等性、相似性或关联性将语义相似的词组映射到邻近点。去年,谷歌使用语言的层次向量模型对 Gmail 的 Smart Reply 进行了改进。最近,谷歌一直在探索这些方法的其他应用。
今天,谷歌向公众分享了 Semantic Experiences 网站,该网站上有两个示例,展示了这些新的方法如何驱动之前不可能的应用。Talk to Books 是一种探索书籍的全新方式,它从句子层面入手,而不是作者或主题层面。Semantris 是一个由机器学习提供支持的单词联想游戏,你可以在其中键入与给定提示相关联的词汇。此外,谷歌还发布了论文《Universal Sentence Encoder》,详细地介绍了这些示例所使用的模型。最后,谷歌为社区提供了一个预训练语义 TensorFlow 模块,社区可以使用自己的句子或词组编码进行实验。
建模方法
谷歌提出的方法通过为较大的语言块(如完整句子和小段落)创建向量,扩展了在向量空间中表征语言的想法。语言是由概念的层次结构组成的,因此谷歌使用模块的层次结构来创建向量,每个模块都要考虑与不同时间尺度上的序列所对应的特征。关联、同义、反义、部分关系、整体关系以及许多其他类型的关系都可以用向量空间语言模型来表示,只要我们以正确的方式进行训练,并且提出正确的「问题」。谷歌在论文《Efficient Natural Language Response for Smart Reply》中介绍了这种方法。
Talk to Books
通过 Talk to Books,谷歌提供了一种全新的图书搜索方式。你陈述一件事或提出一个问题,这个工具就会在书中找出能回答你的句子,这种方法不依赖关键词匹配。从某种意义上来说,你在和书「交谈」,得到的回答可以帮助你确定自己是否有兴趣阅读它们。
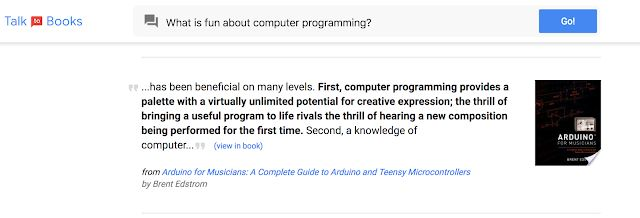
Talk to Books
该模型在十亿聊天句对上训练而成,学习识别哪些可能是好的回复。一旦你问问题(或者作出陈述),工具就在搜索十万本书中的所有句子,根据句子层面的语义找到与输入语句对应的内容;没有限制输入和输出结果之间关系的预置规则。
这是一种独特的能力,可以帮助你找到关键词搜索未必找得到的有趣书籍,但是仍有改进空间。例如,上述实验在句子层面有作用(而不是像 Gmail 的 Smart Reply 那样是在段落层面),那么「完美」匹配的句子可能仍属「断章取义」。你可能会发现找到的书或文章并非自己想要的,或者选中某篇文章的理由并不明显。你还可能注意到著名的书籍未必排序靠前;该实验仅观察了单个句子的匹配程度。不过,它有一个好处,就是这个工具可以帮助人们发现意想不到的作者和书籍,以及 surface book。
Semantris
谷歌还发布了 Semantris,一个由该技术支持的单词联想游戏。你输入一个单词或词组,游戏屏幕上会排列出所有单词,排序根据这些单词与输入内容的对应程度。使用该语义模型,近义词、反义词和邻近概念都不在话下。
试用地址:https://research.google.com/semantris
Arcade 版本(见下图)的时间压力使得你输入单个单词作为提示。而 Blocks 版本没有时间压力,你可以尽情尝试输入词组和句子。
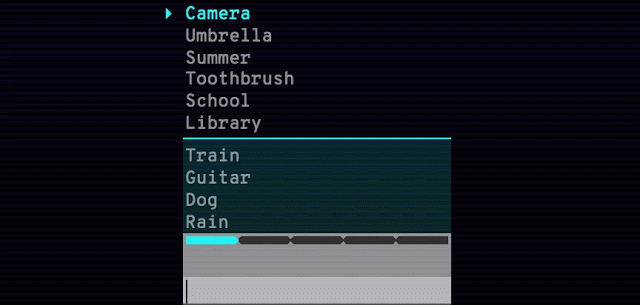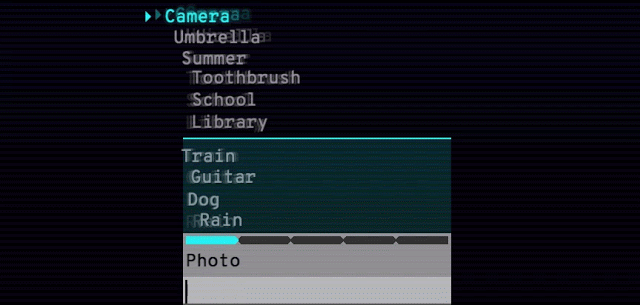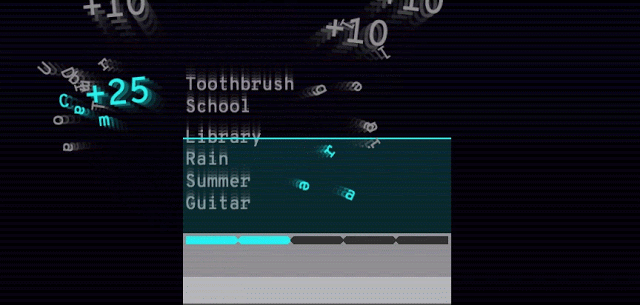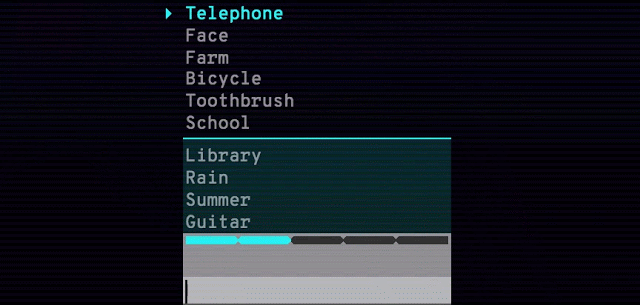
Semantris Arcade
本文分享的示例仅仅是使用这些新工具的几个可能方式。其他潜在应用还包括分类、语义相似度、语义聚类、白名单应用(从多个方案中选择正确的回复)和语义搜索(比如 Talk to Books)。期待社区提出更多想法和更多有创意的应用案例。
相关论文:Universal Sentence Encoder

论文链接:https://arxiv.org/abs/1803.11175
摘要:我们展示了将句子编码成嵌入向量的模型,可用于面向其他 NLP 任务的迁移学习。该模型高效,且在多项迁移任务中性能良好。该编码模型的两个变体允许准确率和计算资源之间的权衡。对于这两种变体,我们调查并作了关于模型复杂度、计算资源消耗、迁移任务可用性和任务性能之间关系的报告。我们将该模型与通过预置词嵌入使用单词级别迁移学习的基线模型和未使用迁移学习的基线模型进行了对比,发现使用句子嵌入的迁移学习性能优于单词级别的迁移学习。句子嵌入的迁移学习在具备少量监督训练数据的迁移任务中也能实现非常好的性能。我们在检测模型偏差的词嵌入关联测试(WEAT)中获得了很好的结果。
原文链接:https://research.googleblog.com/2018/04/introducing-semantic-experiences-with.html
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

