使用dplyr进行数据操作(50个实例)
dplyr软件包是R中功能最强大,最受欢迎的软件包之一。该软件包由最受欢迎的R程序员Hadley Wickham编写,他编写了许多有用的R软件包,如ggplot2,tidyr等。本文包括一些示例和如何使用使用dplyr软件包来清理和转换数据。这是一个关于数据操作和数据处理的完整教程。
什么是dplyr?
dplyr是一个强大的R软件包,用于处理,清理和汇总非结构化数据。简而言之,它使得R中的数据探索和数据操作变得简单快捷。

dplyr有什么特别之处?
软件包“dplyr”包含许多主要使用的数据操作功能,例如应用过滤器,选择特定列,排序数据,添加或删除列以及聚合数据。这个包的另一个最重要的优点是学习和使用dplyr函数非常容易。也很容易回想起这些功能。例如,filter()用于过滤行。
dplyr与基本R函数
dplyr函数处理速度比基本R函数快。 这是因为dplyr函数是以计算有效的方式编写的。 它们在语法上也更稳定,并且比向量更好地支持数据帧。
SQL查询与dplyr
数十年来人们一直在使用SQL来分析数据。 每个现代数据分析软件如Python,R,SAS等都支持SQL命令。 但SQL从未被设计为执行数据分析。 它专为查询和管理数据而设计。 有许多数据分析操作在SQL失败或使简单的事情困难。 例如,计算多个变量的中位数,将宽格式数据转换为长格式等。而 dplyr软件包的设计目的是进行数据分析。
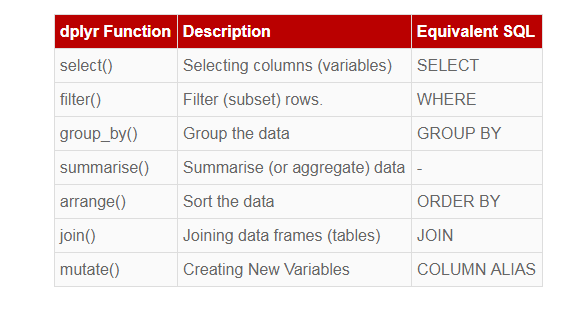
dplyr函数的名称类似于SQL命令,如用于选择变量的select(),group_by() - 通过对变量进行分组来组合数据,join() - 将两个数据集合在一起。 还包括inner_join()和left_join()。 它也支持SQL常用的子查询。
如何安装和加载dplyr软件包
要安装dplyr软件包,请键入以下命令。
install.packages("dplyr")
要加载dplyr包,请在下面输入命令
library(dplyr)
常用的dplyr的函数
数据:各国的收入数据
在本教程中,我们使用以下数据,其中包含2002年至2015年各州产生的收入。注意:此数据不包含各州的实际收入数据。
该数据集包含51个观测值(行)和16个变量(列)。 下面显示了数据集前6行的快照。
数据集下载链接 (密码:9ny3)
如何加载数据
提交以下代码。 在下面的代码中更改文件路径。
mydata <- read.csv("D:/datasets/sampledata.csv")
实例1:随机选择N行
sample_n函数从数据框(或表)中随机选择行。 函数的第二个参数告诉R要选择的行数。
sample_n(mydata, 3)

实例2:随机选择总行的N%
sample_frac函数随机返回N%的行。 在下面的例子中,它随机返回10%的行。
sample_frac(mydata, 0.1)
实例3:基于所有变量(完整行)删除重复行
distinct函数用于消除重复行
x1 <- dplyr::distinct(mydata)
在此数据集中,没有单个重复行,因此返回的行数与mydata中的行数相同。
实例4:基于单个变量删除重复行
.keep_all函数用于保留输出数据框中的所有其他变量。
x2 <- dplyr::distinct(mydata, Index, .keep_all= TRUE)
实例5:基于多个变量删除重复行
在下面的例子中,我们使用两个变量 - Index,Y2010来确定唯一性。
x3 <- dplyr::distinct(mydata, Index, Y2010, .keep_all= TRUE)
实例6:选择变量(或列)
假设你被要求只选择几个变量。 下面的代码选择变量“Index”,从“State”到“Y2008”的列。
mydata2 <- select(mydata, Index, State:Y2008)
实例7:删除变量
变量前面的减号表示R放弃变量。
mydata3 <- select(mydata, -Index, -State)
上面的代码也可以写成:
mydata4 <- select(mydata, -c(Index, State))
实例8:选择或删除以"Y"开始的变量
starts_with()函数用于选择以字母开头的变量。
mydata5 <- select(mydata, starts_with('Y'))
在starts_with()之前添加一个负号表示将删除以'Y'开始的变量
mydata6 <- select(mydata, -starts_with('Y'))
以下函数可帮助您根据名称选择变量。 
实例9:选择变量名中包含"l"的变量
mydata7 <- select(mydata, contains('l'))
实例10:重新排列变量
下面的代码保持变量'State'在前面,其余的变量跟随其后。
mydata8 <- select(mydata, State, everything())
实例11:变量重命名
rename函数可用于重命名变量。 在下面的代码中,我们将'Index'变量重命名为'Index1'。
mydata9 <- rename(mydata, Index1=Index) names(mydata9)

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

