机器学习小白看过来,带你全面了解分类器评价指标
雷锋网 (公众号:雷锋网) AI 研习社按:为你的分类器选择正确的评价指标十分关键。如果选不好,你可能会陷入这样的困境:你认为自己的模型性能良好,但实际上并非如此。
近日,towardsdatascience 上的一篇文章就深入介绍了分类器的评价指标,以及应该在什么场景下使用,雷锋网 AI 研习社将内容编译整理如下:
在本文中,你将了解到为什么评价分类器比较困难;为什么在大多数情况下,一个看起来分类准确率很高的分类器性能却没有那么理想;什么是正确的分类器评价指标;你应该在何时使用这些评价指标;如何创造一个你期望的高准确率的分类器。

目录
-
评价指标为什么如此重要?
-
混淆矩阵
-
准确度和召回率
-
F-Score
-
精确率和召回率的折衷
-
精确率和召回率的曲线
-
ROC、AUC 曲线和 ROC、AUC 值
-
总结
评价指标为什么如此重要?
通常来说,评价一个分类器要比评价一个回归算法困难得多。著名的 MNIST 数据集是一个很好的例子,它包含多张从 0 到 9 的手写数字图片。如果我们想要构建一个分类器来判断数值是否为 6,构建一个算法将所有的输入分类为非 6,然后你将在 MNIST 数据集中获得 90% 的准确率,因为数据集中只有大约 10% 的图像是 6。这是机器学习中一个主要的问题,也是你需要多用几个评价指标测试你的分类器的原因。
混淆矩阵
首先,你可以了解一下混淆矩阵,它也被称为误差矩阵。它是一个描述监督学习模型在测试数据上的性能的表格,其中真实的值是未知的。矩阵的每一行表示预测出的类中的实例,而每一列则表示实际类别中的实例(反之亦然)。它被称之为「混淆矩阵」的原因是,利用它你很容易看出系统在哪些地方将两个类别相混淆了。
你可以在下图中看到在 MNIST 数据集上使用 sklearn 中的「confusion_matrix()」函数得到的输出:

每一行表示一个实际的类别,每一列表示一个预测的类别。
第一行是实际上「非 6」(负类)的图像个数。其中,53459 张图片被正确分类为「非 6」(被称为「真正类」)。其余的 623 张图片则被错误地分类为「6」(假正类)。
第二行表示真正为「6」的图像。其中,473 张图片被错误地分类为「非 6」(假负类),5445 张图片被正确分类为「6」(真正类)。
请注意,完美的分类器会 100% 地正确,这意味着它只有真正类和真负类。
精确率和召回率
一个混淆矩阵可以给你很多关于你的(分类)模型做的有多好的信息,但是有一种方法可以让你得到更多的信息,比如计算分类的精确率(precision)。说白了,它就是预测为正的样本的准确率(accuracy),并且它经常是和召回率(recall,即正确检测到的正实例在所有正实例中的比例)一起看的。
sklearn 提供了计算精确率和召回率的内置函数:

现在,我们有了一个更好的评价分类器的指标。我们的模型将图片预测为「6」的情况有 89% 是正确的。召回率告诉我们它将 92% 的真正为「6」的实例预测为「6」。
当然,还有更好的评价方法。
F-值
你可以把精确率和召回率融合到一个单独的评价指标中,它被称为「F-值」(也被称为「F1-值」)。如果你想要比较两个分类器,F-值会很有用。它是利用精确率和召回率的调和平均数计算的,并且它将给低的数值更大的权重。这样一来,只有精确率和召回率都很高的时候,分类器才会得到高 F-1 值。通过 sklearn 很容易就能计算 F 值。
从下图中,你可以看到我们的模型得到了 0.9 的 F-1 值:

不过 F-值并不是万能的「圣杯」,精确率和召回率接近的分类器会有更好的 F-1 分数。这是一个问题,因为有时你希望精确率高,而有时又希望召回率高。事实上,精确率越高会导致召回率越低,反之亦然。这被称为精确率和召回率的折衷,我们将在下一个章节讨论。
精确率和召回率的折衷
为了更好地解释,我将举一些例子,来说明何时希望得到高精确率,何时希望得到高召回率。
高精确率:
如果你训练了一个用于检测视频是否适合孩子看的分类器,你可能希望它有高的精确率。这意味着,这个你希望得到的分类器可能会拒绝掉很多适合孩子的视频,但是不会给你包含成人内容的视频,因此它会更加保险。(换句话说,精确率很高)
高召回率:
如果你想训练一个分类器来检测试图闯入大楼的人,这就需要高召回率了。可能分类器只有 25% 的精确率(因此会导致一些错误的警报),只要这个分类器有 99% 的召回率并且几乎每次有人试图闯入时都会向你报警,但看来是一个不错的分类器。
为了更好地理解这种折衷,我们来看看随机梯度下降(SGD)的分类器如何在 MNIST 数据集上做出分类决策。对于每一个需要分类的图像,它根据一个决策函数计算出分数,并将图像分类为一个数值(当分数大于阈值)或另一个数值(当分数小于阈值)。
下图显示了分数从低(左侧)到高(右侧)排列的手写数字。假设你有一个分类器,它被用于检测出「5」,并且阈值位于图片的中间(在中央的箭头所指的地方)。接着,你会在这个阈值右边看到 4 个真正类(真正为「5」的实例)和 1 个假正类(实际上是一个「6」)。这一阈值会有 80% 的精确率(五分之四),但是它仅仅只能从图片中所有的 6 个真正的「5」中找出 4 个来,因此召回率为 67%(六分之四)。如果你现在将阈值移到右侧的那个箭头处,这将导致更高的精确率,但召回率更低,反之亦然(如果你将阈值移动到左侧的箭头处)。
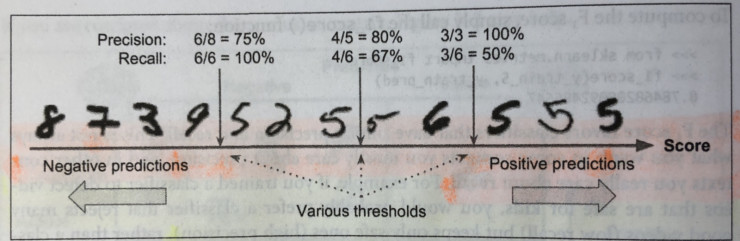
精确率/召回率曲线
精确率和召回率之间的折衷可以用精确率-召回率曲线观察到,它能够让你看到哪个阈值最佳。
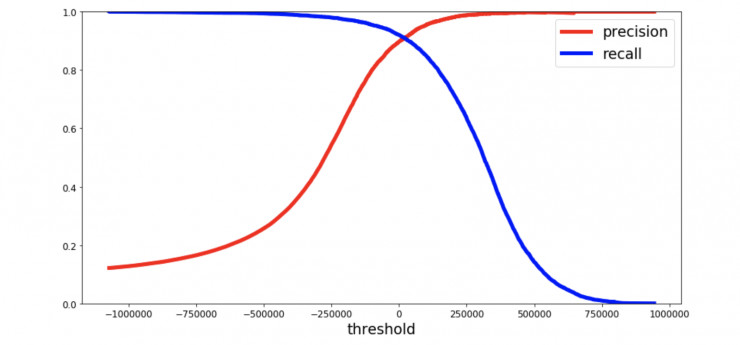
另一种方法是将精确率和召回率以一条曲线画出来:
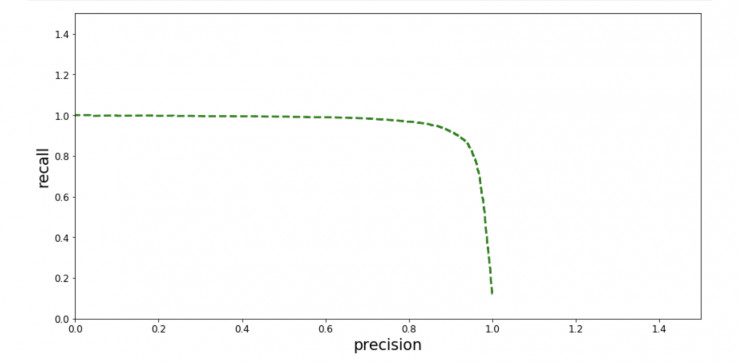
在上图中,可以清晰地看到,当精确率大约为 95% 时,精准率升高,召回率迅速下降。根据上面的两张图,你可以选择一个为你当前的机器学习任务提供最佳精确率/召回率折衷的阈值。如果你想得到 85% 的精确率,可以查看第一张图,阈值大约为 50000。
ROC、AUC 曲线和 ROC、AUC 值
ROC 曲线是另一种用于评价和比较二分类器的工具。它和精确率/召回率曲线有着很多的相似之处,当然它们也有所不同。它将真正类率(true positive rate,即recall)和假正类率(被错误分类的负实例的比例)对应着绘制在一张图中,而非使用精确率和召回率。
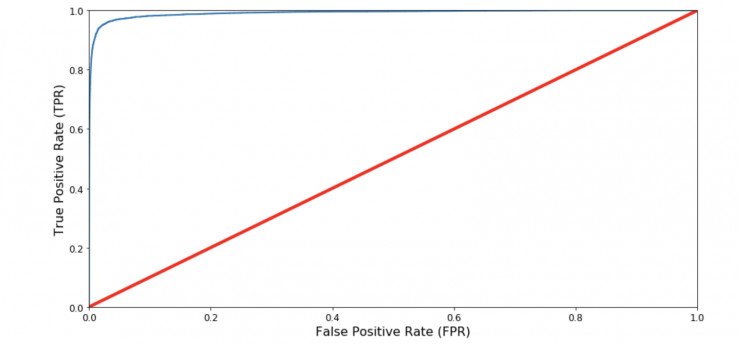
当然,在这里也有所折衷。分类器产生越多的假正类,真正类率就会越高。中间的红线是一个完全随机的分类器,分类器的曲线应该尽可能地远离它。
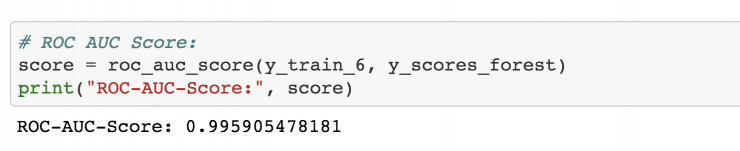
通过测量 ROC 曲线下方的面积( AUC),ROC 曲线为比较两个分类器的性能提供了一种方法。这个面积被称作 ROC AUC值,100% 正确的分类器的 ROC AUC 值为 1。
一个完全随机的分类器 ROC AUC 为 0.5。下图中是 MNIST 模型的输出:
总结
通过以上介绍,大家将学习到如果评价分类器,以及用哪些工具去评价。此外,还能学到如何对精确率和召回率进行折衷,以及如何通过 ROC AUC 曲线比较不同分类器的性能。
我们还了解到,精确率高的分类器并不像听起来那么令人满意:因为高精确率意味着低召回率。
下次当你听到有人说一个分类器有 99% 的精确率或准确率时,你就知道你应该问问他这篇帖子中讨论的其它指标如何。
资源链接
https://en.wikipedia.org/wiki/Confusion_matrix
https://github.com/Donges-Niklas/Classification-Basics/blob/master/Classification_Basics.ipynb
https://www.amazon.de/Hands-Machine-Learning-Scikit-Learn-TensorFlow/dp/1491962291/ref=sr_1_1?ie=UTF8&qid=1522746048&sr=8-1&keywords=hands+on+machine+learning
via towardsdatascience
雷锋网 AI 研习社编译整理。
雷锋网原创文章,未经授权禁止转载。详情见 转载须知 。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

