Spark1.6.0功能扩展——为HiveThriftServer2增加HA
前言
HiveThriftServer2是Spark基于HiveServer2实现的多Session管理的Thrift服务,提供对Hive的集中式管理服务。HiveThriftServer2作为Yarn上的Application,目前只支持yarn-client模式——即Driver运行在本地,ApplicationMaster运行在NodeManager所管理的Container中。yarn-client模式相较于yarn-cluster模式,在Driver和ApplicationMaster之间引入了额外的通信,因而服务的稳定性较低。
为了能够提高HiveThriftServer2的可用性,打算部署两个或者多个HiveThriftServer2实例,最终确定了选择HA的解决方案。网上有关HiveThriftServer2的HA实现,主要借助了HAProxy、Nginx等提供的反向代理和负载均衡功能实现。这种方案有个问题,那就是用户提交的执行SQL请求与HiveThriftServer2之间的连接一旦断了,反向代理服务器并不会主动将请求重定向到其他节点上,用户必须再次发出请求,这时才会与其他HiveThriftServer2建立连接。这种方案,究其根本更像是负载均衡,无法保证SQL请求不丢失、重连、Master/Slave切换等机制。
为了解决以上问题,我选择了第三种方案。
由于HiveThriftServer2本身继承自 HiveServer2,所以 HiveServer2自带的HA方案也能够支持HiveThriftServer2。对于 HiveServer2自带的HA方案不熟悉的同学,可以百度一下,相关内容还是很多的。如果按照我的假设,就使用 HiveServer2自带的HA方案的话,你会发现我的假设是错误的——HiveThriftServer2居然不支持HA。这是为什么呢?请读者务必保持平常心,我们来一起研究研究。
注意:我这里的Spark版本是1.6.0,Hive版本是1.2.1。
HiveServer2的HA分析
我从网上找到了一副能够有效展示 HiveServer2的HA原理的图( 具体来源无从考证 )。
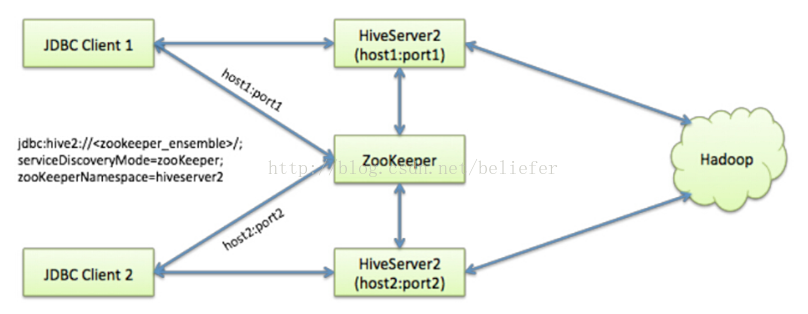
这幅图片很直观的为我们介绍了 HiveServer2的HA架构。整个架构实际上围绕着ZooKeeper集群,利用 ZooKeeper提供的创建节点、检索子节点等功能来实现。那么 ZooKeeper的HA是如何实现的呢?让我们来进行源码分析吧。
HiveServer2本身是由Java语言开发,熟悉Java应用(如 Tomcat、Spark的Master和Worker、Yarn的ResourceManager和NodeManager等 )的同学应该知道,任何的Java应用必须要有一个main class。 HiveServer2这个Thrift服务的main class就是 HiveServer2类。 HiveServer2的main方法如代码清单1所示。
代码清单1 HiveServer2的main方法
public static void main(String[] args) {
HiveConf.setLoadHiveServer2Config(true);
try {
ServerOptionsProcessor oproc = new ServerOptionsProcessor("hiveserver2");
ServerOptionsProcessorResponse oprocResponse = oproc.parse(args);
// 省略无关代码
// Call the executor which will execute the appropriate command based on the parsed options
oprocResponse.getServerOptionsExecutor().execute();
} catch (LogInitializationException e) {
LOG.error("Error initializing log: " + e.getMessage(), e);
System.exit(-1);
}
}
上边代码中首先创建了ServerOptionsProcessor对象并对参数进行解析,parse方法解析完参数返回了oprocResponse对象(类型为ServerOptionsProcessorResponse)。然后调用 oprocResponse的
getServerOptionsExecutor方法得到的对象实际为
StartOptionExecutor。最后调用了
StartOptionExecutor的
execute方法。
StartOptionExecutor的实现见代码清单2。
代码清单2 StartOptionExecutor的实现
static class StartOptionExecutor implements ServerOptionsExecutor {
@Override
public void execute() {
try {
startHiveServer2();
} catch (Throwable t) {
LOG.fatal("Error starting HiveServer2", t);
System.exit(-1);
}
}
}
从
代码清单2看到, StartOptionExecutor的 execute方法实际调用了startHiveServer2方法, startHiveServer2方法中与HA相关的代码如下:
if (hiveConf.getBoolVar(ConfVars.HIVE_SERVER2_SUPPORT_DYNAMIC_SERVICE_DISCOVERY)) {
server.addServerInstanceToZooKeeper(hiveConf);
} 可以看到调用了
HiveServer2的addServerInstanceToZooKeeper方法。这个addServerInstanceToZooKeeper的作用就是在指定的 ZooKeeper集群上创建持久化的父节点作为HA的命名空间,并创建持久化的节点将 HiveServer2的实例信息保存到节点上( addServerInstanceToZooKeeper方法的实现细节留给感兴趣的同学,自行阅读 ) 。 ZooKeeper集群如何指定?HA的命名空间又是什么?大家先记着这两个问题,最后在配置的时候,再告诉大家。
HiveThriftServer2为何不支持 HiveServer2自带 的HA?
使用jps命令查看 HiveThriftServer2的进程信息,如图。
HiveThriftServer2的main方法(见代码清单3)中创建了HiveServerServerOptionsProcessor对象,并调用了其process方法。
代码清单3 HiveThriftServer2的main方法
def main(args: Array[String]) {
val optionsProcessor = new HiveServerServerOptionsProcessor("HiveThriftServer2")
if (!optionsProcessor.process(args)) {
System.exit(-1)
}
// 省略无关代码
}
HiveServerServerOptionsProcessor的实现见代码清单4。
代码清单4 HiveServerServerOptionsProcessor的实现
private[apache] class HiveServerServerOptionsProcessor(serverName: String)
extends ServerOptionsProcessor(serverName) {
def process(args: Array[String]): Boolean = {
// A parse failure automatically triggers a system exit
val response = super.parse(args)
val executor = response.getServerOptionsExecutor()
// return true if the parsed option was to start the service
executor.isInstanceOf[StartOptionExecutor]
}
} 从
代码清单4看到, HiveServerServerOptionsProcessor继承了我们前文所说的 ServerOptionsProcessor,并增加了process方法。 process方法中调用了父类 ServerOptionsProcessor的parse方法解析参数,并得到 类型为 ServerOptionsProcessorResponse的response,之后调用了 response的 getServerOptionsExecutor方法得到对象executor( 实际类型为 StartOptionExecutor ), 最后只是判断 executor的类型是否是 StartOptionExecutor。
可以看到 HiveServerServerOptionsProcessor的process方法,自始至终都没有调用 StartOptionExecutor的 execute方法,从而也就无法完成向 ZooKeeper集群注册服务,所以 HiveThriftServer2没能支持HA。
为 HiveThriftServer2添加HA功能
由于HiveServer2的startHiveServer2方法是静态私有方法,所以HiveThriftServer2不能够直接调用。为了使得HiveThriftServer2能够调用,只能采用反射来实现。在HiveThriftServer2的main方法中添加反射调用addServerInstanceToZooKeeper方法的代码见代码清单5。
代码清单5 反射调用 addServerInstanceToZooKeeper方法
if (SparkSQLEnv.hiveContext.hiveconf.getBoolVar(ConfVars.HIVE_SERVER2_SUPPORT_DYNAMIC_SERVICE_DISCOVERY)) {
val method = server.getClass.getSuperclass.getDeclaredMethod("addServerInstanceToZooKeeper", classOf[org.apache.hadoop.hive.conf.HiveConf])
method.setAccessible(true)
method.invoke(server, SparkSQLEnv.hiveContext.hiveconf)
}
至此,我们的改造完成。
配置
既然通过修改源码, HiveThriftServer2已经采用了 HiveServer2的HA实现,所以就可以采用与 HiveServer2相同的配置。在hive-site.xml文件中添加以下配置:
<property> <name>hive.server2.support.dynamic.service.discovery</name> <value>true</value> </property> <property> <name>hive.server2.zookeeper.namespace</name> <value>hiveserver2_zk</value> </property> <property> <name>hive.zookeeper.quorum</name> <value>zkNode1:2181,zkNode2:2181,zkNode3:2181</value> </property> <property> <name>hive.zookeeper.client.port</name> <value>2181</value> </property>
以上配置中,各个配置项的含义为:
- hive.server2.zookeeper.namespace: HiveServer2注册到 ZooKeeper集群时,需要的命名空间。实际上,第一个有此配置的 HiveServer2实例将在 ZooKeeper集群的根节点下创建以命名空间为名称的持久化节点。
- hive.server2.support.dynamic.service.discovery:是否开启 HiveServer2的动态服务发现。开启此配置后, HiveServer2将向 ZooKeeper集群的 命名空间节点下创建服务的信息节点。
- hive.zookeeper.quorum: ZooKeeper集群的参与者列表。
- hive.zookeeper.client.port: ZooKeeper集群开放给客户端使用的端口。
测试
我们启动两个 HiveThriftServer2实例,然后打开 ZooKeeper客户端,就可以看到 ZooKeeper集群的根节点下名称为hiveserver2_zk的持久化节点,如下图所示。

我们查看 hiveserver2_zk节点下已经注册的服务,如下图所示。

使用beeline来测试,首先进入beeline,然后使用jdbc连接 HiveThriftServer2,如下图所示。
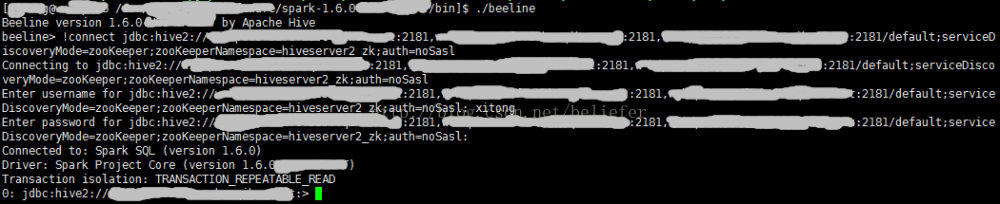
通过jdbc连接时使用的jdbc URL的格式为:jdbc:hive2://<zookeeper quorum>/<dbName>;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace= hiveserver2_zk
在连接的过程中需要输入用户名、密码等信息。最终beeline会通过hive-jdbc从多个 HiveThriftServer2实例中 选择一个连接。
使用Java语言时,通过java jdbc也可以使用此 HiveThriftServer2实例,只不过需要的jdbc driver为org.apache.hive.jdbc.HiveDriver。
功能扩展
通过 ZooKeeper集群的服务发现,我们实现的HA实际跟HAProxy、Nginx等提供的负载均衡功能没有太多区别。如果发生网络超时、连接断开、执行失败等情况时,我们的客户端程序也会失败。为了在发生以上异常时能够进行重连、重试、选择其他服务进行重连,这都需要客户端代码去实现。由于实现方式多种多样,所以这里就不具体罗列,只将我个人实现的HiveThriftHAHelper类的各个关键功能进行介绍:
- init:从 jdbc URL中解析出必要的参数,例如 zookeeper quorum、 serviceDiscoveryMode、 zooKeeperNamespace等。
- getServerHosts:从 ZooKeeper集群获取各个HiveThriftServer2实例的信息,并进行缓存。
- selectHost:从 HiveThriftServer2实例中按照随机、轮询、Master/Slave等多种策略选择服务。
- execute:选择服务、执行SQL、异常重试等。
这样我们在网络超时时可以进行重试、连接断开时选择其他节点进行重试、用户不必反复提交SQL、支持负载均衡、支持 Master/Slave等。
关于《 Spark内核设计的艺术 架构设计与实现 》
经过近一年的准备,基于Spark2.1.0版本的《 Spark内核设计的艺术 架构设计与实现 》一书现已出版发行,图书如图: 
纸质版售卖链接如下:
京东: https://item.jd.com/12302500.html
电子版售卖链接如下:
京东: https://e.jd.com/30389208.html
正文到此结束
- 本文标签: 图片 服务器 https apr NFV Select src executor Nginx tomcat 京东 SDN parse client Service apache db 集群 管理 解析 百度 Property 架构设计 java node cat IDE HTML 开发 message id 端口 进程 UI App 参数 Master Hadoop tar 配置 CEO value trigger Haproxy 源码 sql 空间 XML ACE IO 测试 负载均衡 zookeeper 代码 实例 http
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

