MIT和FB搞了个视频数据集,让Youtube视频审查更容易
雷锋网按:这里是,雷锋字幕组编译的Two minutes paper专栏,每周带大家用碎片时间阅览前沿技术,了解AI领域的最新研究成果。
原标题 SLAC Dataset From MIT and Facebook
翻译 | 祁晓君 字幕 | 凡江 整理 | 廖颖
论文标题:SLAC: A Sparsely Labeled Dataset for Action Classification and Localization
▷每周一篇2分钟论文视频解读

本期论文即将介绍的这个项目,用到了麻省理工学院和 Facebook 联合创建的数据集,该数据集名为SLAC(Sparsely Labeled ACtions),用于动作识别和定位。它包含520K以上的未修剪视频和1.75M剪辑注释,涵盖200个动作类别。该论文提出的框架使得注释视频剪辑花费的时间更少,仅为8.8秒,与传统的手动修剪和动作定位程序相比,标记时间节省超过95%。

一般来讲,数据集的目的是用来训练和测试学习算法的质量。本期视频提到的这类数据集包含了很多剪辑的短视频,这些短视频片段被传递给一个神经网络,由神经网络来对视频中发生的活动进行分类。在这个数据集中,神经网络在很多场景都会给出一个错误的逻辑答案。很简单,人类知道——我们可能会在一个装有攀岩墙的房间里,但我们不一定会锻炼;我们可能在游泳池附近,但我们不一定游泳。让神经网络知道有一个游泳池边可能发生游泳这个事情是非常容易的,但真正了解游泳是什么,却需要它对大量的数据进行理解。
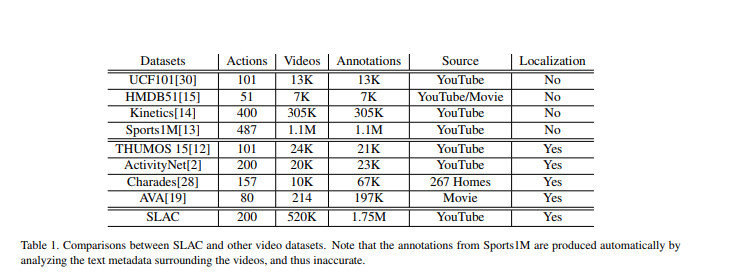
创建这样的数据集是一项非常艰巨的工作,因为它包含超过50万个视频,为200个不同的活动提供近200万个注释,并且还有很多预处理步骤需要执行才能使其可用。


所有这些视频都经过镜头和人物检测步骤,提取了包含某种人类活动的相关子片段。然后用两个不同的分类器查看,查看结果是根据两者之间是否存在共性,来决定这段视频剪辑是否被丢弃。这一步骤使得负面样本变得更难,因为上下文可能是正确的,但预期的活动可能并不是那样。一个典型的游泳池例子,就是穿着泳装的人,只是在摆弄手指,而不是在游泳。
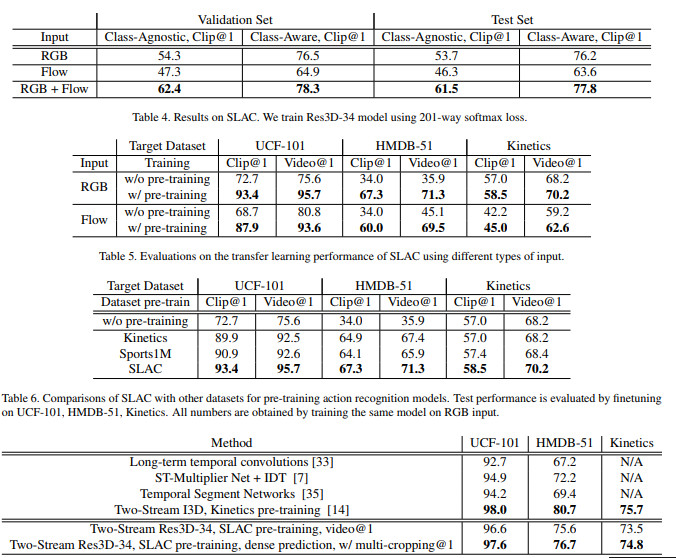
更有趣的部分是—— 当我们试图训练神经网络来处理其他松散相关的任务时,使用这个数据集进行预训练可显著提高分数。 图中给出了一些数字,这些数字是非常不可思议的——有些案例的成功率提高了30%以上,这本身就说明了问题。但是在其他情况下,差异约为10-15%,这种差异在成功率很高时也很明显。因为分类器越接近100%,下面剩下的案例就越难提高准确性。在这些情况下,即使是3%的改善也是显著的。
论文原文: https://arxiv.org/pdf/1712.09374.pdf
更多文章,关注雷锋网 (公众号:雷锋网) 雷锋网
添加雷锋字幕组微信号(leiphonefansub)为好友
备注「我要加入」,To be an AI Volunteer !
雷锋网原创文章,未经授权禁止转载。详情见 转载须知 。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

