一文介绍3篇无需Proposal的实例分割论文
本文解析了实例分割领域中的三篇论文,它们不同于主流的基于 proposal 和 Faster-RCNN 的方法,比如 Mask R-CNN、MaskLab 以及最新的 PANet,后者在多个数据集(CityScapes、COCO 以及 MVD)上实现了当前最优的结果。
基于 proposal 的实例分割架构存在三个根本缺陷。首先,两个物体可能共享同一个或者非常相似的边界框。在这种情况中,mask head 无法区分要从边界框中拾取的对象。这对于其所在边界框中具有低填充率的线状物体(例如自行车和椅子)而言是非常严重的问题。第二,架构中没有任何能够阻止两个实例共享像素的东西存在。第三,实例的数量通常受限于网络能够处理的 proposal 的数量(通常为数百个)。
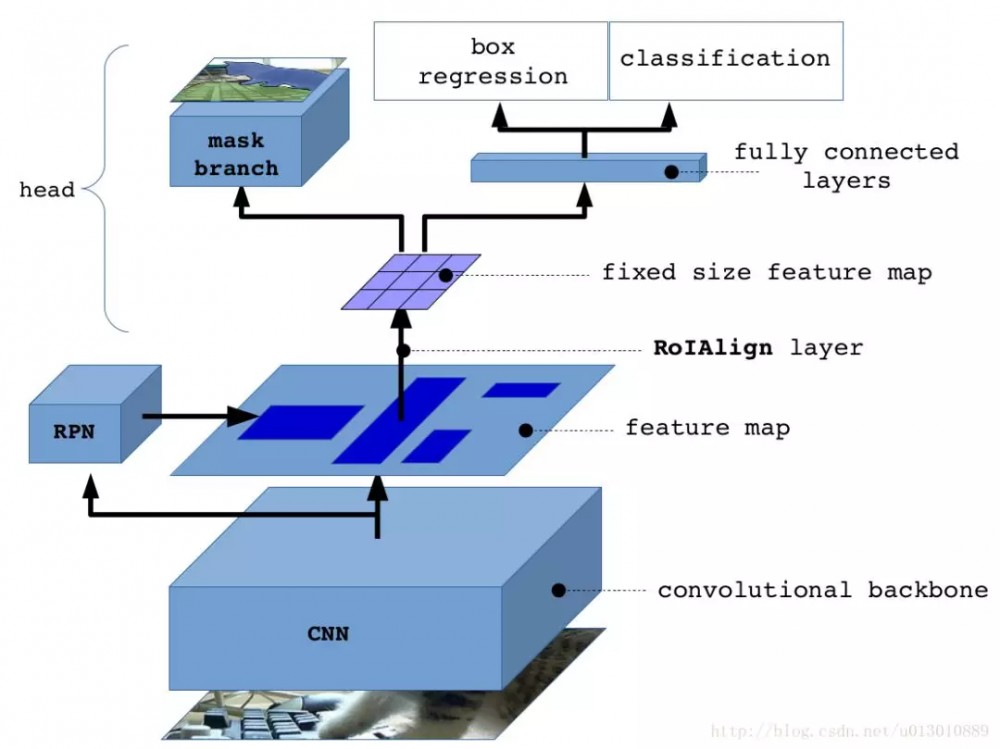
Mask R-CNN 的架构
此外,这种架构很复杂,难以调节和「调试」。在这个问题的前身目标检测中,已经成功使用了更简单的单阶段架构,比如 RetinaNet。
使用了实例嵌入之后,每个对象在 N 维空间中被分配了一个「颜色」。网络处理图像,并产生与输入图像相同大小的密集输出。网络输出中的每一个像素都是嵌入空间中的一个点。属于同一对象的点在嵌入空间中是比较接近的,而属于不同类别的点在嵌入空间中是远离的。解析图像嵌入空间会涉及到一些聚类算法。
论文 1: Semantic Instance Segmentation with a Discriminative Loss Function(基于判别损失函数的语义实例分割)
作者:Bert De Brabandere、Davy Neven、Luc Van Gool
-
论文地址:https://arxiv.org/abs/1708.02551
-
GitHub 地址:https://github.com/DavyNeven/fastSceneUnderstanding
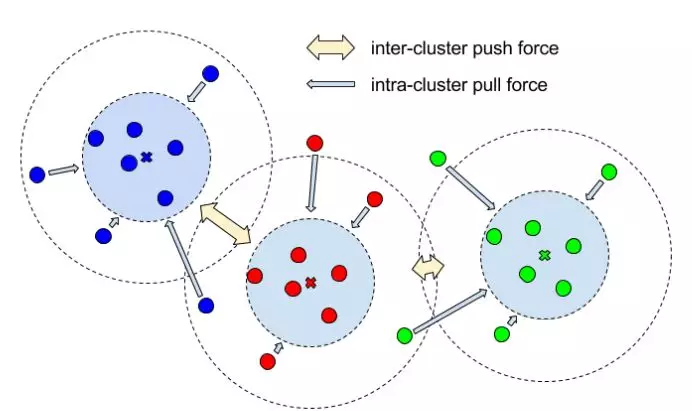
可视化对比损失
损失函数。这篇论文使用的对比损失由三部分组成:
(1)拉力。惩罚同一实例中所有元素与其平均值之间的距离。也就是说,获取一个实例的所有像素,并计算平均值。这种拉力会将同一实例中的所有像素点拉近到嵌入空间中的同一个点。简单说,就是减少每一个实例的嵌入方差。
(2)推力。获取所有中心点 (在嵌入空间中,而不是空间中心),然后将它们推得更远。
(3)正则化。中心点不应该离原点太远。
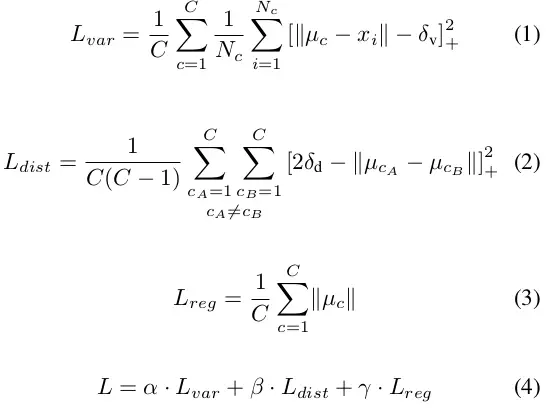
这里使用的α和β值都是 1,γ则被设置为 0.001。两个δ都是拉力和推力的阈值。
解析:在获得语义分割图 ( 车、狗、计算机、…) 之后,我们将每个类掩码细分为实例。这是通过在语义掩码中拾取随机未分配点并迭代地应用均值偏移算法来找到实例的均值点来实现的。
平均值的第一个假设是最初拾取的随机像素的嵌入。然后围绕该点 (在嵌入空间中) 扩展一组点,然后再次计算它们的平均值,并且重复该过程直到平均值的变化不显著。根据我的经验,算法只需不超过 10 次迭代就能收敛。大多数时候 3 - 4 次迭代就足够了。
用于在嵌入空间中展开实例掩码的半径与拉阈值是相同的。理论上,如果测试误差为 0,并且中心之间的最小距离至少是方差分量的拉阈值的两倍,我们可以使用这些阈值来解析图像。距离不大于拉阈值的所有点都应属于同一实例。由于测试误差几乎从不为零,因此均值偏移算法被用来来寻找嵌入的高密度部分的中心。
视频链接:https://www.youtube.com/watch?v=hJg7ik4x95U
这种跟踪过程在二维嵌入空间中的良好可视化,其中集合的模式,以及密度的峰值,最终都被找到。
误差来源

这些结果展示了 Cityscapes 数据集中大多数误差的来源。如果语义分割不是预测出来的,而是使用了真实标签,AP50 的结果从 40.2 跳到 58.5。如果实际的中心点也被使用了,而且没有使用 mean-shift 做估计,那么,得分几乎会额外增长 20,最终达到 77.8。目前最先进的结果是使用 PANet 在 COCO 数据集上在未使用预训练的情况下达到 57.1(参考 https://www.cityscapes-dataset.com/benchmarks/)。这与使用语义分割的真实值的结果是一样的。我们知道,嵌入本身就是相当好的。
实例嵌入
下面是一个实例嵌入的例子,通过网络实际训练得到。它被用于解决 Data Science Bowl 2018 中提出的问题,它目前由 Kaggle 运营,目的是寻找医疗图像中的细胞核。
左上角是原始图像。中上部分的图像是语义分割(这里只有背景和前景两类)。其余是嵌入空间中 64 个通道中的前 7 个通道。从潜入中可以明显看出,网络学到了在空间上区分细胞核的通道。以对角线或者水平编码为例。一些将图像中心的距离进行编码。然而,在实例内部,颜色是均匀的。这给我们提供了一些关于网络学习分割实例的洞见。

论文 2:Semantic Instance Segmentation via Deep Metric Learning(基于深度度量学习的实例语义分割)
作者:Alireza Fathi、Zbigniew Wojna、Vivek Rathod、Peng Wang、Hyun Oh Song、Sergio Guadarrama、Kevin P. Murphy
论文地址:https://arxiv.org/abs/1703.10277
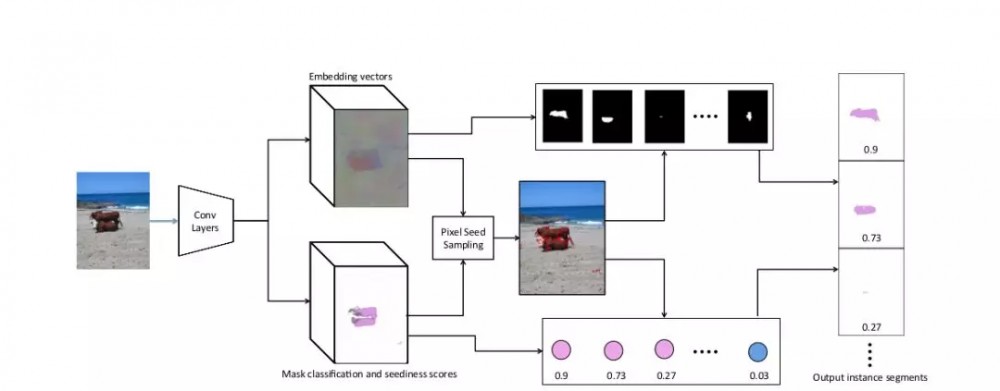
基于深度度量学习的语义实例分割一文中所提出的网络架构
这篇论文的主要贡献是为每个像素学习种子得分。这个分数告诉我们像素是否是扩展 mask 的良好候选。上篇论文中,种子是随机选择的,然后使用均值漂移算法(mean-shift algorithm)对中心进行细化。然而这里只进行了一次扩展。

将所有类别和带宽上的最大值作为种子得分。
这篇论文建议为每个像素学习几个可能的种子。我们为嵌入空间中的每个半径和每一个类别都学习了一个种子。因此,如果我们有 C 个类别和 T 个带宽(半径),那么每个像素就有 C×T 个种子「候选」。而对于每一个像素而言,只有得分最高的种子会被考虑。
嵌入损失:在这篇论文中,使用像素对惩罚嵌入。我们一并考虑来自同一实例和不同实例的像素对。
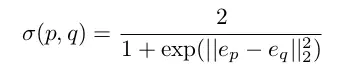
嵌入空间中的一个 logistic 距离函数
这篇论文使用了一个修正版的 logistic 函数,它能够将嵌入空间中的欧氏距离变换到 [0,1] 区间。嵌入空间中比较接近的像素对会被分配一个接近于 1 的数值,比较远离的像素对会被分配一个接近于 0 的数值。
自然,对数损失也被用作一个损失函数。实例的大小可能会变化,因此,为了缓解这种不平衡问题,像素对会根据所属实例的大小进行加权。
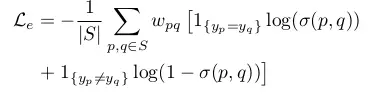
基于像素对之间的 logistic 距离的对数损失
种子损失:对于每个像素,模型学习几个种子得分。这是一个由带宽 (嵌入空间中的半径) 和类别组合而成的分数。由于种子评分接近但不同于语义分割,因此每次评估嵌入时都确定每个种子评分的基本真实性。mask 围绕像素的嵌入展开,并且如果具有基本事实实例的 IoU 超过某个阈值,则该像素被认为是实例的类别种子。损失函数将会为这个类别惩罚一个较低的种子得分。
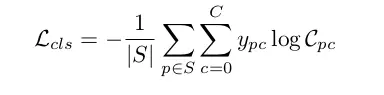
种子损失
在每一个批量中,每幅图像仅评估大约 10 个种子,并且是随机选取的。学习几个这样的模型,每个带宽一个。带宽越宽,对象越大。在某种程度而言,接收最高得分的带宽就是模型将它的估计传达给实例大小 (相对于嵌入空间中的距离) 的方式。
训练过程。本文基于 COCO 数据集预训练的 ResNet-101 作为主干。训练从没有分类/种子预测开始,也就是说λ为 0,并且随着嵌入的稳定发展,更新到 0.2。
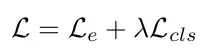
以不同尺度 ( 0.25,0.5,1,2 ) 对主干进行评价,并将评价结果反馈给种子和嵌入头。
解析:学习到种子之后,程序就很直接了当了。提出了一种图像最佳种子集的选取方法。它一方面优化了高种子得分,另一方面优化了嵌入空间的多样性。
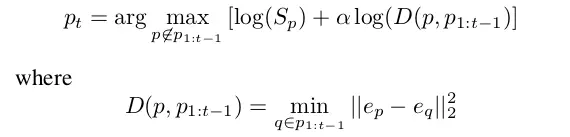
迭代地选择种子,每个新种子被选择为在嵌入空间中远离先前选择的种子。所选择的第一种子是图像中种子得分最高的像素。第二个将会是既具有高种子得分,另一方面又会在嵌入空间中不太接近的种子。使用参数α控制两个要求之间的平衡。α需要被调节,对此参数测试的范围在 0.1 和 0.6 之间。与 NMS 不同,这里所用的方法鼓励嵌入空间的多样性,而不仅仅是空间多样性。

基于深度度量学习的语义实体分割的一些结果
论文 3: Recurrent Pixel Embedding for Instance Grouping(用于实例分组的递归像素嵌入)
作者:Shu Kong、Charless Fowlkes
-
论文链接:https://arxiv.org/abs/1712.08273
-
GitHub 地址:https://github.com/aimerykong/Recurrent-Pixel-Embedding-for-Instance-Grouping
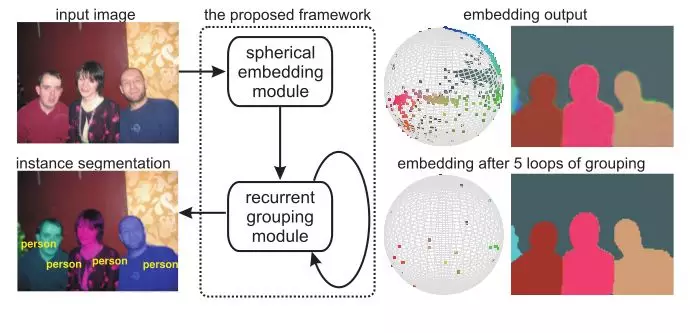
这篇论文提出了在 n 球面上进行嵌入,并利用余弦距离来度量像素的接近程度。然而,本文的主要贡献是基于高斯模糊均值偏移 ( GBMS ) 算法的改进版本的递归分组模型。
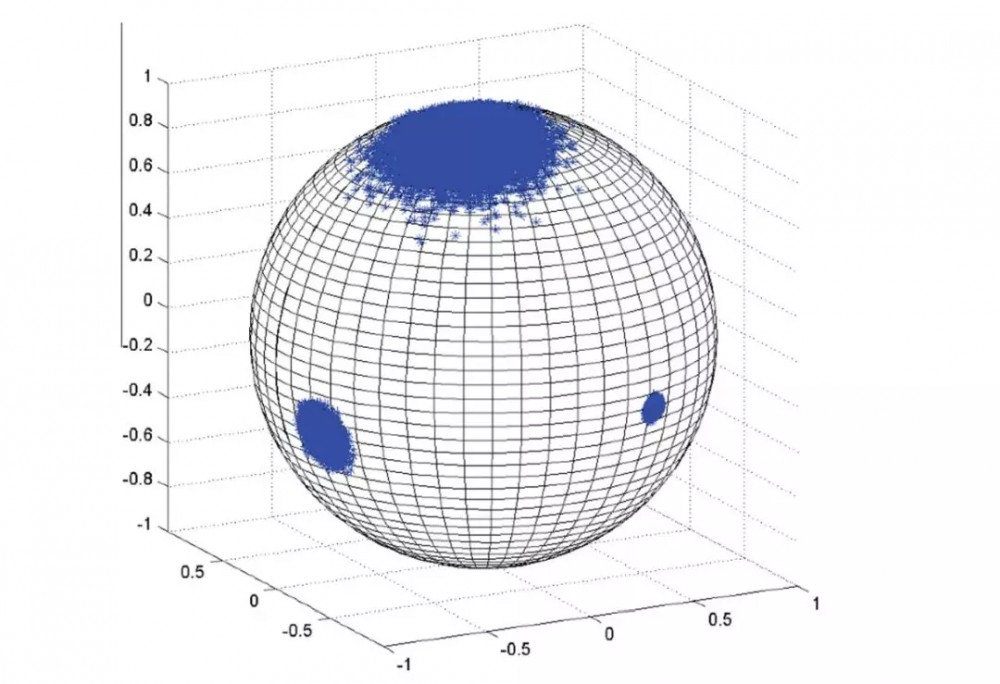
GBMS 是一种迭代算法,类似于第一篇论文中用于寻找实例中心的简单均值漂移算法。在这个版本中,所有像素被认为是潜在的种子。所有像素在每次迭代中相对于它们周围的密度被更新。向「重心」移动,就好像图像的嵌入空间是一个产生行星的星云。距离越远,对彼此的影响就越小。距离由高斯的带宽控制,这是标准差,从下面的算法中可以清楚地看出。

GBMS 中存在三次收敛保证,因此在应用多次变换之后,最终我们应该得到非常密集、几乎呈点状的聚类。有关 GBMS 更多信息,请参见:http://www.cs.cmu.edu/~aarti/SMLRG/miguel_slides.pdf。
为了将该算法引入到网络中,它已经被使用矩阵运算来表达了。

简单地应用上述算法是没有意义的,因为嵌入在球体上,并且它们的接近度使用余弦变换来测量。描述所有点之间距离的接近度矩阵可以使用以下的变换来计算:
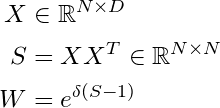
测量球体上的距离,而不是使用 L2 范数。此外,在应用 GBMS 步骤之后,需要对生成的嵌入进行规范化,以便它们位于单位球体上。
训练:使用了像素对的损失,与前一篇论文类似,其阈值为所需的不同对 (α) 的距离。每个像素对都使用校准的余弦距离来衡量,它的变化范围是 [0,1],而不是 [-1,1]。
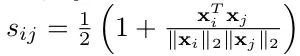
校准余弦距离
损失通过循环分组模型的每个应用被反向传播。以后的应用阶段只会出现非常困难的情况。作者以快速 RCNN 训练中的硬否定挖掘为例,比较了这一性质。
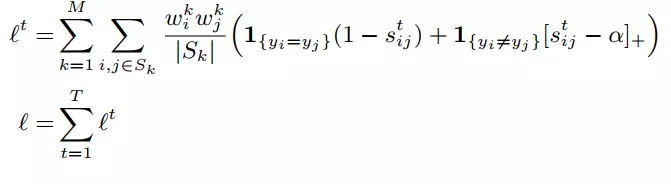
用于实例分组的递归像素嵌入所使用的损失函数
作者在文中使用的α值为 0.5。请注意,实例的大小用于重新平衡大小实例之间的损失。
解析:在分组模块的几个应用之后,聚类应该非常密集,随机挑选值应该产生足够好的种子。
出于实际目的,仅使用 GBMS 步骤中的一些像素是有意义的,因为计算相似性矩阵可能是极其昂贵的。所采用的像素量是速度/精度的折衷考虑。
其他方法
实例嵌入并不是基于网络的唯一推荐方法。这里还有一切涉及解决实例分割中的问题的其他方法的论文,
-
基于循环注意力机制的端到端实例分割(End-to-End Instance Segmentation with Recurrent Attention): https://arxiv.org/abs/1605.09410
-
用于实例分割的深分水岭变换(Deep Watershed Transform for Instance Segmentation):https://arxiv.org/abs/1611.08303
-
联合嵌入:用于联合检测和分组的端到端学习(Associative Embedding: End-to-End Learning for Joint Detection and Grouping):http://ttic.uchicago.edu/~mmaire/papers/pdf/affinity_cnn_cvpr2016.pdf
-
SGN:用于实例分割的序列分组网络(SGN: Sequential Grouping Networks for Instance Segmentation):https://www.cs.toronto.edu/~urtasun/publications/liu_etal_iccv17.pdf
总结
与基于 proposal 的解决方案相比,这些论文的结果并没有竞争力。我们论述了三篇关于损失函数和解析的解决方法。
(1)基于判别损失函数的语义实例分割
使用了非成对的损失函数。使用图像中所有像素产生了特别丰富的梯度。
(2)基于深度度量学习的实例语义分割
引入了种子模型,同时帮助我们分类并拾取最佳种子,做了速度优化。
(3)用于实例分组的递归像素嵌入
GBMS 是均值漂移的一种变体,在网络内部用于训练和解析。创建了非常密集的聚类。
这些方法能够结合起来使用,以产生更好的结果。它们比基于 proposal 的方法更简单,也可能更快,同时避免了基于 proposal 的实例分割架构存在的三个根本缺陷。 
原文链接: https://medium.com/@barvinograd1/instance-embedding-instance-segmentation-without-proposals-31946a7c53e1
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

