通过 Q-learning 深入理解强化学习
本文将带你学习经典强化学习算法 Q-learning 的相关知识。在这篇文章中,你将学到:(1)Q-learning 的概念解释和算法详解;(2)通过 Numpy 实现 Q-learning。
故事案例:骑士和公主
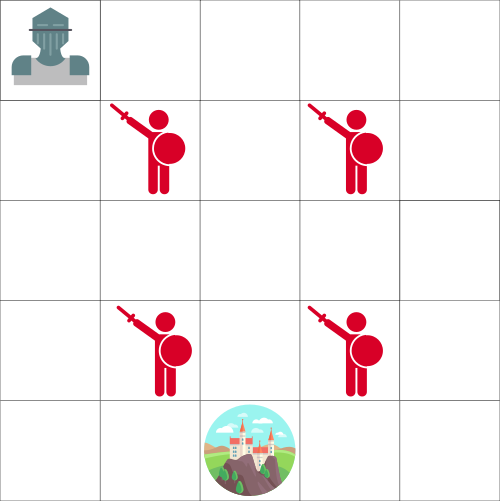
假设你是一名骑士,并且你需要拯救上面的地图里被困在城堡中的公主。
你每次可以移动一个方块的距离。敌人是不能移动的,但是如果你和敌人落在了同一个方块中,你就会死。你的目标是以尽可能快的路线走到城堡去。这可以使用一个「按步积分」系统来评估。
-
你在每一步都会失去 1 分(每一步失去的分数帮助智能体训练的更快)
-
如果碰到了一个敌人,你会失去 100 分,并且训练 episode 结束。
-
如果进入到城堡中,你就获胜了,获得 100 分。
那么问题来了:如何才能够创建这样的智能体呢?
下面我将介绍第一个策略。假设智能体试图走遍每一个方块,并且将其着色。绿色代表「安全」,红色代表「不安全」。

同样的地图,但是被着色了,用于显示哪些方块是可以被安全访问的。
接着,我们告诉智能体只能选择绿色的方块。
但问题是,这种策略并不是十分有用。当绿色的方块彼此相邻时,我们不知道选择哪个方块是最好的。所以,智能体可能会在寻找城堡的过程中陷入无限的循环。
Q-Table 简介
下面我将介绍第二种策略:创建一个表格。通过它,我们可以为每一个状态(state)上进行的每一个动作(action)计算出最大的未来奖励(reward)的期望。
得益于这个表格,我们可以知道为每一个状态采取的最佳动作。
每个状态(方块)允许四种可能的操作:左移、右移、上移、下移。
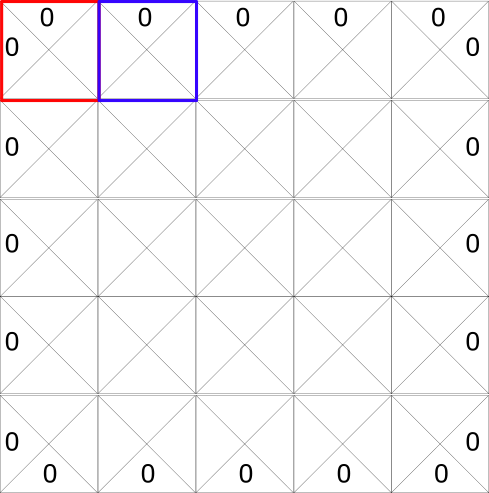
「0」代表不可能的移动(如果你在左上角,你不可能向左移动或者向上移动!)
在计算过程中,我们可以将这个网格转换成一个表。
这种表格被称为 Q-table(「Q」代表动作的「质量」)。每一列将代表四个操作(左、右、上、下),行代表状态。每个单元格的值代表给定状态和相应动作的最大未来奖励期望。
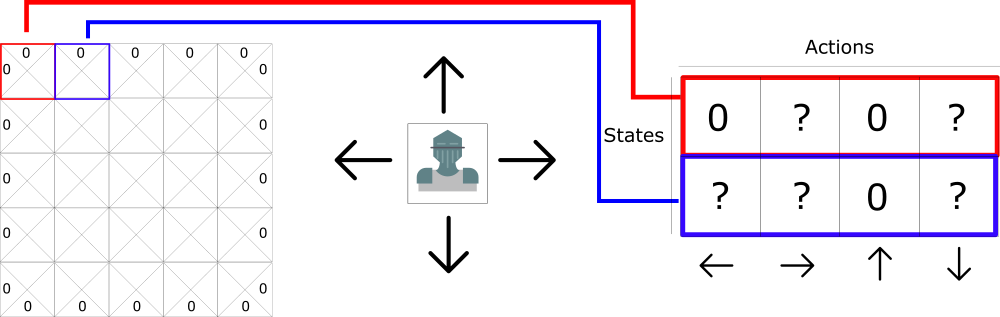
每个 Q-table 的分数将代表在给定最佳策略的状态下采取相应动作获得的最大未来奖励期望。
为什么我们说「给定的策略」呢?这是因为我们并不实现这些策略。相反,我们只需要改进 Q-table 就可以一直选择最佳的动作。
将这个 Q-table 想象成一个「备忘纸条」游戏。得益于此,我们通过寻找每一行中最高的分数,可以知道对于每一个状态(Q-table 中的每一行)来说,可采取的最佳动作是什么。
太棒了!我解决了这个城堡问题!但是,请等一下... 我们如何计算 Q-table 中每个元素的值呢?
为了学习到 Q-table 中的每个值,我们将使用 Q-learning 算法。
Q-learning 算法:学习动作值函数(action value function)
动作值函数(或称「Q 函数」)有两个输入:「状态」和「动作」。它将返回在该状态下执行该动作的未来奖励期望。
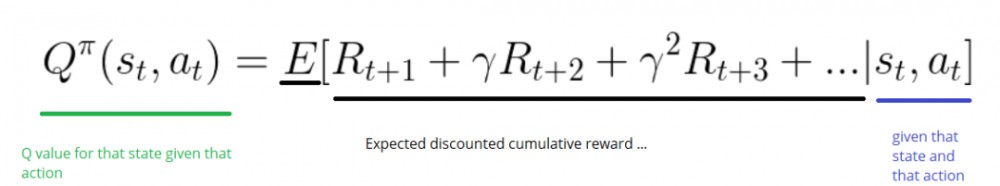
我们可以把 Q 函数视为一个在 Q-table 上滚动的读取器,用于寻找与当前状态关联的行以及与动作关联的列。它会从相匹配的单元格中返回 Q 值。这就是未来奖励的期望。

在我们探索环境(environment)之前,Q-table 会给出相同的任意的设定值(大多数情况下是 0)。随着对环境的持续探索,这个 Q-table 会通过迭代地使用 Bellman 方程(动态规划方程)更新 Q(s,a) 来给出越来越好的近似。
Q-learning 算法流程
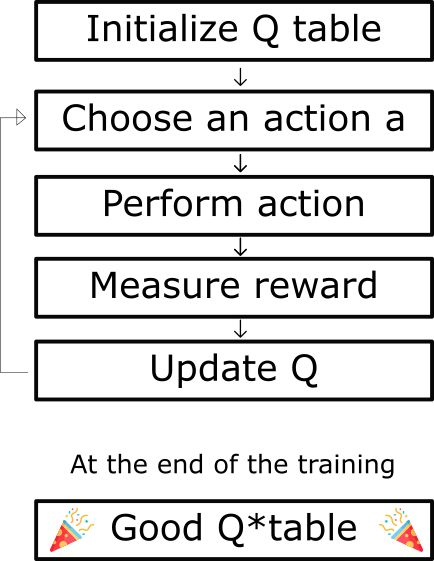

Q-learning 算法的伪代码
步骤 1:初始化 Q 值。我们构造了一个 m 列(m = 动作数 ),n 行(n = 状态数)的 Q-table,并将其中的值初始化为 0。

步骤 2:在整个生命周期中(或者直到训练被中止前),步骤 3 到步骤 5 会一直被重复,直到达到了最大的训练次数(由用户指定)或者手动中止训练。
步骤 3:选取一个动作。在基于当前的 Q 值估计得出的状态 s 下选择一个动作 a。
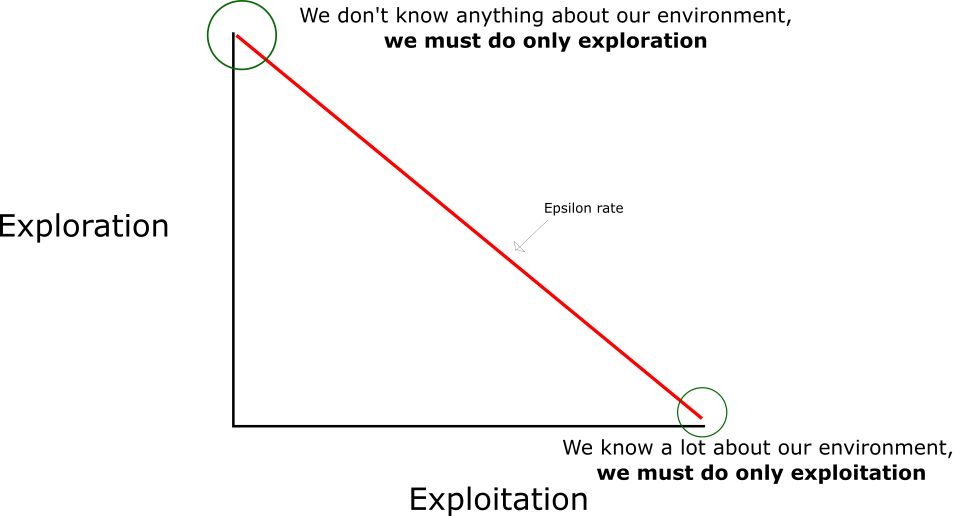
但是……如果每个 Q 值都等于零,我们一开始该选择什么动作呢?在这里,我们就可以看到探索/利用(exploration/exploitation)的权衡有多重要了。
思路就是,在一开始,我们将使用 epsilon 贪婪策略:
-
我们指定一个探索速率「epsilon」,一开始将它设定为 1。这个就是我们将随机采用的步长。在一开始,这个速率应该处于最大值,因为我们不知道 Q-table 中任何的值。这意味着,我们需要通过随机选择动作进行大量的探索。
-
生成一个随机数。如果这个数大于 epsilon,那么我们将会进行「利用」(这意味着我们在每一步利用已经知道的信息选择动作)。否则,我们将继续进行探索。
-
在刚开始训练 Q 函数时,我们必须有一个大的 epsilon。随着智能体对估算出的 Q 值更有把握,我们将逐渐减小 epsilon。
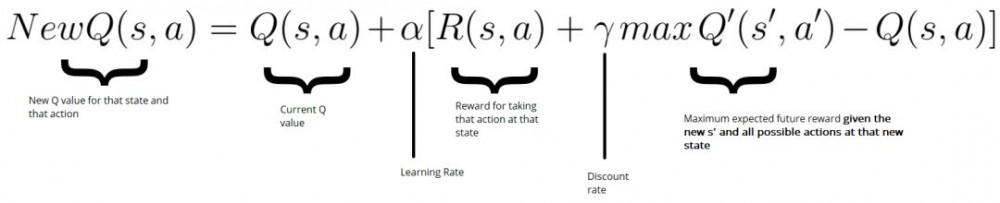
步骤 4-5:评价!采用动作 a 并且观察输出的状态 s' 和奖励 r。现在我们更新函数 Q(s,a)。
我们采用在步骤 3 中选择的动作 a,然后执行这个动作会返回一个新的状态 s' 和奖励 r。
接着我们使用 Bellman 方程去更新 Q(s,a):
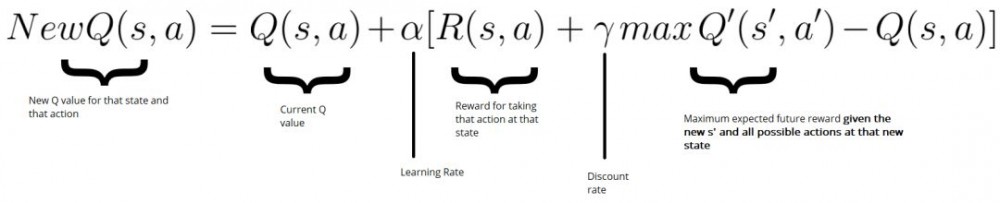
如下方代码所示,更新 Q(state,action):
New Q value = Current Q value + lr * [Reward + discount_rate * (highest Q value between possible actions from the new state s’ ) — Current Q value ]
让我们举个例子:

-
一块奶酪 = +1
-
两块奶酪 = +2
-
一大堆奶酪 = +10(训练结束)
-
吃到了鼠药 = -10(训练结束)
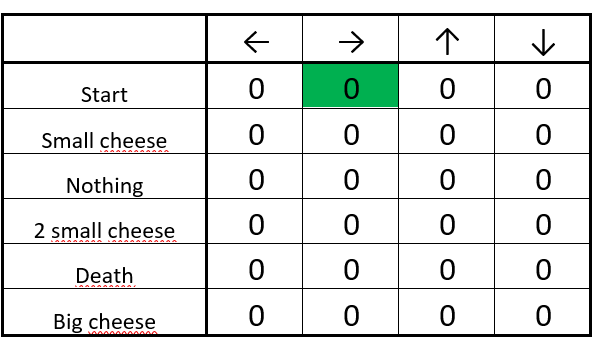
步骤 1:初始化 Q-table
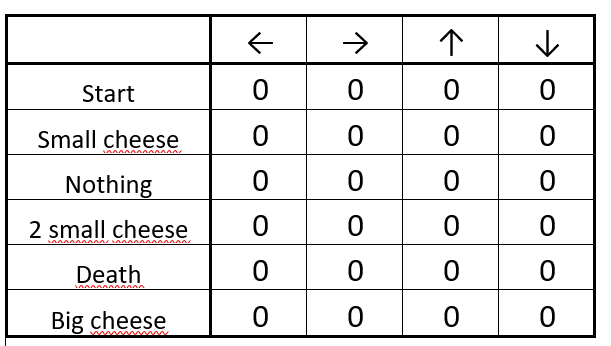
初始化之后的 Q-table
步骤 2:选择一个动作。从起始点,你可以在向右走和向下走其中选择一个。由于有一个大的 epsilon 速率(因为我们至今对于环境一无所知),我们随机地选择一个。例如向右走。

我们随机移动(例如向右走)
我们发现了一块奶酪(+1),现在我们可以更新开始时的 Q 值并且向右走,通过 Bellman 方程实现。
步骤 4-5:更新 Q 函数

-
首先,我们计算 Q 值的改变量 ΔQ(start, right)。
-
接着我们将初始的 Q 值与 ΔQ(start, right) 和学习率的积相加。
可以将学习率看作是网络有多快地抛弃旧值、生成新值的度量。如果学习率是 1,新的估计值会成为新的 Q 值,并完全抛弃旧值。
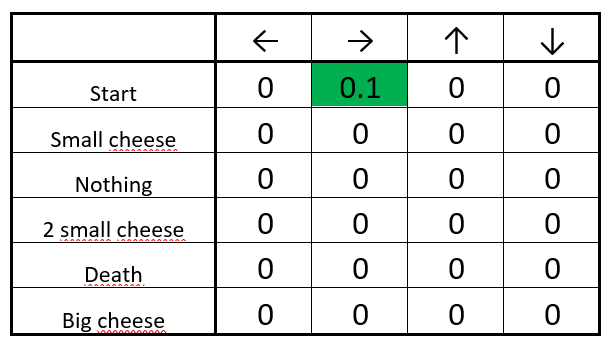
更新后的 Q-table
太好了!我们刚刚更新了第一个 Q 值。现在我们要做的就是一次又一次地做这个工作直到学习结束。
实现 Q-learning 算法
既然我们知道了它是如何工作的,我们将一步步地实现 Q-learning 算法。代码的每一部分都在下面的 Jupyter notebook 中直接被解释了。
你可以在我的深度强化学习课程 repo 中获得代码。
项目地址: https://github.com/simoninithomas/Deep_reinforcement_learning_Course/blob/master/Q%20learning/Q%20Learning%20with%20FrozenLake.ipynb
回顾
-
Q-learning 是一个基于值的强化学习算法,利用 Q 函数寻找最优的「动作—选择」策略。
-
它根据动作值函数评估应该选择哪个动作,这个函数决定了处于某一个特定状态以及在该状态下采取特定动作的奖励期望值。
-
目的:最大化 Q 函数的值(给定一个状态和动作时的未来奖励期望)。
-
Q-table 帮助我们找到对于每个状态来说的最佳动作。
-
通过选择所有可能的动作中最佳的一个来最大化期望奖励。
-
Q 作为某一特定状态下采取某一特定动作的质量的度量。
-
函数 Q(state,action)→返回在当前状态下采取该动作的未来奖励期望。
-
这个函数可以通过 Q-learning 算法来估计,使用 Bellman 方程迭代地更新 Q(s,a)
-
在我们探索环境之前:Q-table 给出相同的任意的设定值→ 但是随着对环境的持续探索→Q 给出越来越好的近似。
就是这些了!不要忘记自己去实现代码的每一部分——试着修改已有的代码是十分重要的。
试着增加迭代次数,改变学习率,并且使用一个更复杂的环境(例如:8*8 方格的 Frozen-lake)。祝你玩的开心!
下次,我将探讨深度 Q-learning,它是 2015 年深度增强学习最大的突破之一。并且,我将训练一个打「毁灭战士(Doom)」游戏、能杀死敌人的智能体!(敬请期待机器之心的更新~)
原文链接: https://medium.freecodecamp.org/diving-deeper-into-reinforcement-learning-with-q-learning-c18d0db58efe
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

