矩阵分解之 SVD 和 SVD++
(点击 上方公众号 ,快速关注,获取学习资料!)
推荐阅读时间:10min~12min
文章内容:矩阵分解在推荐系统中的应用
前期内容回顾:
-
近邻推荐之基于用户的协同过滤
-
近邻推荐之基于物品的协同过滤
-
近邻推荐之 Slope One 算法
-
如何为协同过滤选择合适的相似度算法
前面的内容是关于近邻推荐的相关知识,来看下另外一种推荐方法:矩阵分解。

为什么需要矩阵分解
协同过滤可以解决我们关注的很多问题,但是仍然有一些问题存在,比如:
-
物品之间存在相关性,信息量并不随着向量维度增加而线性增加
-
矩阵元素稀疏,计算结果不稳定,增减一个向量维度,导致近邻结果差异很大的情况存在
上述两个问题,在矩阵分解中可以得到解决。原始的矩阵分解只适用于评分预测问题,这里所讨论的也只是针对于评分预测问题。
矩阵分解
矩阵分解简介
矩阵分解,简单来说,就是把原来的大矩阵,近似分解成两个小矩阵的乘积,在实际推荐计算时不再使用大矩阵,而是使用分解得到的两个小矩阵。
具体来说,假设用户物品评分矩阵为 R,形状为 mxn,即 m 个用户, n 个物品。我们选择一个很小的数 k,k 比 m 和 n 都小很多,然后通过算法生成两个矩阵 P 和 Q,这两个矩阵的要求如下:P 的形状是 mxk,Q 的形状是 nxk, P 和 Q 的转置相乘结果为 R。也就是说分解得到的矩阵P和Q可以还原成原始的矩阵R。
用公式来描述就是:
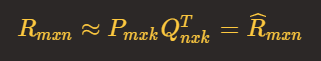
其中 R 表示真实的用户评分矩阵,一般有很多缺失值(缺失值表示用户没有对该物品评分),带尖帽的 R 表示使用分解矩阵预测的用户评分矩阵,它补全了所有的缺失值。
从另一个角度来看,矩阵分解就是把用户和物品都映射到一个 k 维空间中(这里映射后的结果用户用矩阵P表示,物品用矩阵Q表示),这个 k 维空间不是我们直接看得到的,也不一定具有非常好的可解释性,每一个维度也没有名字,所以常常叫做隐因子。
SVD
SVD 全程奇异值分解,原本是是线性代数中的一个知识,在推荐算法中用到的 SVD 并非正统的奇异值分解。
前面已经知道通过矩阵分解,可以得到用户矩阵和物品矩阵。针对每个用户和物品,假设分解后得到的用户 u 的向量为 p_u,物品 i 的向量为 q_i,那么可以得到:
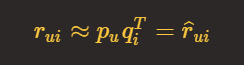
问题关键来了,如何为每个用户和物品生成k维向量呢?这个问题可以转化成机器学习问题,要解决机器学习问题,就需要寻找损失函数以及优化算法。
损失函数如下:
损失函数有两部分,加号前面是控制模型的偏差,加号后面控制模型的方差。控制偏差表示的目的是为了让分解后的矩阵预测分数与实际分数之间的误差越小越好;控制方差表示得到的隐因子越简单越高,这样使得保证模型在预测真正的任务时的效果。
求解损失函数优化算法常用的选择有两个,一个是随机梯度下降(SGD),另一个是交替最小二乘(ALS) 。这里以梯度下降为例。
-
准备好用户物品的评分矩阵,每一条评分数据看做一条训练样本;
-
给分解后的 U 矩阵和 V 矩阵随机初始化元素值;
-
用 U 和 V 计算预测后的分数;
-
计算预测的分数和实际的分数误差;
-
按照梯度下降的方向更新 U 和 V 中的元素值;
-
重复步骤 3 到 5,直到达到停止条件。
增加偏置的SVD
在实际应用中,会存在以下情况:相比于其他用户,有些用户给分就是偏高或偏低。相比于其他物品,有些物品就是能得到偏高的评分。所以使用pu * qiT 来定义评分是有失偏颇的。我们可以认为 评分 = 兴趣 + 偏见。

其中,μ表示全局均值, bu表示用户偏见,bi表示物品偏见。
举例来说,一个电影网站全局评分为 3.5 分,你评分电影时比较严格,一般打分比平均分都要低 0.5,《肖申克的救赎》的平均分比全局平均分要高 1 分。这里 u=3.5,bu=-0.5,bi=1分。
SVD++
实际生产中,用户评分数据很稀少,也就是说显示数据比隐式数据少很多,这些隐式数据能否加入模型呢?
SVD++ 就是在 SVD 模型中融入用户对物品的隐式行为。我们可以认为 评分=显式兴趣 + 隐式兴趣 + 偏见。
那么隐式兴趣如何加入到模型中呢?首先,隐式兴趣对应的向量也是 k 维,它由用户有过评分的物品生成。
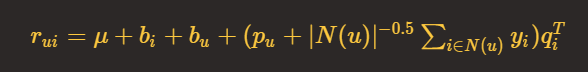
其中,|N(u)|表示用户u的行为物品集,yj表示物品j所表达的隐式反馈。
总结
介绍了在评分数据中非常受欢迎 SVD 算法以及改进。比如加入偏置信息,考虑隐式反馈等。
相关推荐:
-
如何为协同过滤选择合适的相似度算法
-
近邻推荐之 Slope One 算法
-
近邻推荐之基于物品的协同过滤
-
近邻推荐之基于用户的协同过滤
-
如何构建基于内容的推荐系统
-
如何从文本中构建用户画像
-
一文告诉你什么是用户画像
-
推荐系统中重要却又容易被忽视的问题有哪些
-
个性化推荐系统中的绕不开的经典问题有哪些
-
推荐系统这么火,但你真的需要吗
-
一文告诉你到底什么是推荐系统
点击这里领取BAT面试题 ==》: BAT机器学习/深度学习面试300题
点击这里领取AI小抄表 ==》: AI 小抄表福利大放送,快来收藏吧
欢迎加入脑洞科技栈微信交流群,群内每天都有关于 Python和机器学习 主题的 有料 分享。
后台回复 “ 加群 ”获取二维码入群。
作者:1or0,脑洞大开(www.naodongopen.com)签约作者,专注于机器学习研究。
脑洞科技栈
专注于人工智能领域

长按,识别二维码,加关注
回复关键字可获取大量学习资料!
本文 为脑洞科技栈撰写,转载请注明出处,并给出本公众号链接地址
更多精彩内容,请点击“ 阅读原文 ”
戳这里戳这里~
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

