TPU加AutoML:50美元快速训练高效的ImageNet图像分类网络
昨日,Jeff Dean 在推特上表示他们在 ImageNet 图像分类上发布了新的 DAWNBench 结果,新型 AmoebaNet-D 网络在 TPU 上实现了最低的训练时间和最少的训练成本。在这一个基准测试上,基于进化策略的 DAWNBench 要比残差网络效果更好,且训练成本降低了一倍。机器之心简要介绍了该基准测试和 AmoebaNet 网络架构,并提供了使用 TPU 进行 AmoebaNet 试验的项目地址。
Jeff Dean 展示的两个基准测试都是 DAWNBench 上的结果,DAWNBench 是斯坦福发布的一套基准测试,主要关注于端到端的深度学习训练和推断过程。虽然目前很多基准仅关注于模型精度,但 DAWNBench 格外关注计算时间和成本,它们是深度模型所需的关键资源。DAWNBench 提供了一套通用的深度学习工作负载参考集,因此能量化不同优化策略、模型架构、软件框架、云计算和硬件中的训练时间、训练成本、推断延迟和推断成本等重点指标。
DAWNBench 基准结果提交地址:https://github.com/stanford-futuredata/dawn-bench-entries
如下是各网络架构在图像分类 Top-5 验证准确率(ImageNet 数据集上)达到 93% 所需要的时间。Jeff Dean 所展示的 AmoebaNet-D 在同等的硬件条件下要比 50 层的残差网络要快很多,它们所使用的框架也都展示在下图。此外,DAWNBench 上所有的基准测试都需要提供测试源代码。

下图展示了不同模型 Top-5 准确率达到 93% 所需要的成本,因为 AmoebaNet-D 和 ResNet-50 使用相同的硬件,所以减少一半时间也就意味着成本减少了一半。

ResNet-50 已经是非常经典且成功的架构,即使我们将层级数增加到 100 至 150 层,网络的最终准确度也不会有一个质的提高。但新型的 AmoebaNet-D 大大减少了计算时间,这种网络基于进化策略能高效搜索神经网络架构并实现快速的训练。谷歌上个月其实已经介绍了这种网络,详细内容前查看: 进化算法 + AutoML,谷歌提出新型神经网络架构搜索方法 。
AmoebaNet
在 ICML 2017 大会中展示的论文《Large-Scale Evolution of Image Classifiers》中,谷歌用简单的构建模块和常用的初始条件设置了一个进化过程。其主要思想是让人「袖手旁观」,让进化算法大规模构建网络架构。当时,从非常简单的网络开始,该过程可以找到与手动设计模型性能相当的分类器。这个结果振奋人心,因为很多应用可能需要较少的用户参与。例如,一些用户可能需要更好的模型,但没有足够的时间成为机器学习专家。
接下来要考虑的问题自然就是手动设计和进化的组合能不能获得比单独使用一个方法更好的结果。因此,在近期论文《Regularized Evolution for Image Classifier Architecture Search》(即 AmoebaNet)中,谷歌通过提供复杂的构建模块和较好的初始条件来参与进化过程。此外,谷歌还使用其新型 TPUv2 芯片来扩大计算规模。通过现代硬件、专家知识和进化过程的组合,谷歌获得了在两个流行的图像分类基准 CIFAR-10 和 ImageNet 上的当前最优模型。
-
AmoebaNet 论文:Regularized Evolution for Image Classifier Architecture Search
-
论文地址:https://arxiv.org/pdf/1802.01548.pdf
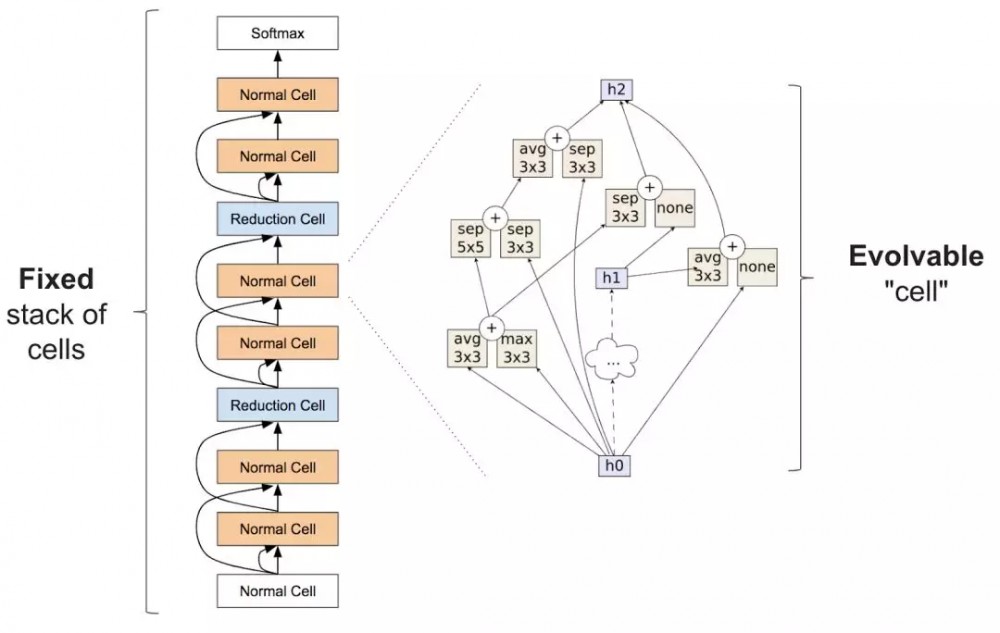
该论文中,群体中初始化的模型必须遵从 cell 外部堆叠(由专家设计)。这类似于 Zoph et al. (2017) 论文中的架构设计思想(如下图)。尽管这些种子模型中的 cell 是随机的,但是我们不再从简单模型开始,这样更易获得高质量模型。
Zoph et al. (2017) 论文中提到的构建模块。左侧是完整神经网络的外部结构,自下而上地通过一串堆叠的重复 cell 解析输入数据。右侧是 cell 的内部结构。算法旨在寻找能够获取准确网络的 cell。
在 AmoebaNet 中,谷歌所用进化算法的一大重要特征是采用了一种正则化形式:相比于移除最差的神经网络,他们移除了最老的神经网络(无论它有多好)。这提升了对任务优化时所发生变化的稳健性,并最终更可能得到更加准确的网络。
TPU 实现
项目地址:https://github.com/tensorflow/tpu/tree/master/models/experimental/amoeba_net
这些代码是基于 AmoebaNet 论文的结果实现的,代码的起始点来自 NASNet 实现和图像处理代码的分支。
预准备
1.建立一个谷歌云项目
跟随谷歌云官网的 Quickstart Guide 中的指示来获取 GCE VM(虚拟机)以访问 Cloud TPU。
为了运行该模型,你需要:
-
一个 GCE VM 实例和相关的 Cloud TPU 资源;
-
一个 GCE bucket 来保存你的训练检查点;
-
ImageNet 训练和验证数据预处理为 TFRecord 格式,并保存在 GCS(可选项)。
2.格式化数据
数据应该被格式化为 TFRecord 格式,可通过以下脚本完成:
https://github.com/tensorflow/tpu/blob/master/tools/datasets/imagenet_to_gcs.py
如果你没有准备好的 ImageNet 数据集,你可以用一个随机生成的伪造数据集来测试模型。该数据集位于 Cloud Storage 的这个位置:gs://cloud-tpu-test-datasets/fake_imagenet。
训练模型
通过执行以下命令来训练模型(代入合适的值):
python amoeba_net.py / --tpu_name=$TPU_NAME / --data_dir=$DATA_DIR / --model_dir=$MODEL_DIR 如果你没有在相同的项目和 zone 中的 GCE VM 上运行这个脚本,你需要加上——project 和——zone 的 Flag 来为 Cloud TPU 指定你希望使用的值。
这将用单块 Cloud TPU 在 ImageNet 数据集上以 256 的批量大小训练一个 AMoebaNet-D 模型。通过默认的 Flag,模型应该能在 48 小时内(包括每经过几个 epoch 之后的评估时间)达到超过 80% 的准确率。
你可以运行 TensorBoard(例如 tensorboard -logdir=$MODEL_DIR)来查看损失曲线和其它关于训练过程的元数据。(注意:如果你在 VM 上运行,请确保恰当地配置 ssh 端口转送或 GCE 防火墙规则。)
你也可以使用以下代码在 7.5 小时内将 AmoebaNet-D 模型训练到 93% 的 top-5 准确率。
python amoeba_net.py / --tpu_name=$TPU_NAME / --data_dir=$DATA_DIR / --model_dir=$MODEL_DIR / --num_cells=6 / --image_size=224 / --num_epochs=35 / --train_batch_size=1024 / --eval_batch_size=1024 / --lr=2.56 / --lr_decay_value=0.88 / --mode=train / --iterations_per_loop=1152
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

