学界 | Uber AI论文:利用反向传播训练可塑神经网络,生物启发的元学习范式
原标题:学界 | Uber AI论文:利用反向传播训练可塑神经网络,生物启发的元学习范式
选自arXiv
机器之心编译
参与:Pedro、刘晓坤
怎样才能得到经过初始训练后就可以利用经验持续快速高效学习的智能体呢?Uber AI 近日研究表明,如同深度神经网络的连接权重,神经可塑性也可以通过梯度下降来优化。在模式记忆、图像重建和强化学习任务上,该方法得到了超越传统非可塑网络的表现,表明可微可塑性有望为元学习问题提供新的高效方法。
介绍:关于「学会学习(元学习)」的问题
最近的机器学习方向的成果很多都是利用大量训练数据进行大量训练,来学习单一复杂的问题(Krizhevsky et al., 2012; Mnih et al., 2015; Silver et al., 2016)。当学习完成之后,智能体的知识就固定不变了;如果这个智能体被用于其他的任务,那么它需要重新训练(要么完全重来,要么部分重新训练),而这又需要大量新的训练数据。相比较之下,生物智能体具备一种出色的能力,这个能力使它们快速高效地学习持续性经验:动物可以学会找到食物源并且记下(最快到达食物源的路径)食物源的位置,发现并记住好的或者不好的新事物或者新场景,等等——而这些往往只需要一次亲身经历就能完成。
赋予人工智能体终身学习的能力,对于它们掌控具有变化不可测特征的环境或是训练时未知特定特征的环境至关重要。例如,深度神经网络的监督学习能让神经网络从它训练时使用的特定、固定的字母表中识别字母;然而,自主性的学习能力能使智能体获取任何字母表的知识,包括人类设计者在训练时不知道的字母表。
自主性学习能力还有一个好处,那就是能让智能体在处理许多任务的时候(例如物体识别、迷宫寻径等等),存储任务中固定不变的结构到自己的固定知识部分中,而只从具体情况中学习剩下可能的变量。这样处理的结果是,学习一个当前的特定任务实例(也就是一般任务的多个实例间确实存在差异的实际潜在变量)会变得非常快,只需要少量甚至单个环境经历。
许多元学习方法已被运用于训练智能体的自主性学习。然而,不像现在的一些方法,生物大脑的长期学习被认为主要是通过突触可塑性来完成的——突触可塑性是神经元间连接的加强或减弱,它是神经活动造成的,经过百万年的进化,它能使拥有它的个体高效地学习。神经可塑性存在许多种构造,它们中很大一部分都遵循称为「赫布定律」的原则:如果一个神经元不停地激活另一个神经元,那么它们间的联系会加强(这个定律通常被总结为「一起激活的神经元被连接到一起」)(赫布于 1949 年提出)。这一原则是动物大脑里观察到的几种可塑性形式的基础,这使它们能从经验中学习并适应环境。
此前一直都有人研究在进化算法中利用可塑性连接来设计神经网络(Soltoggio et al. 2017),但是在深度学习方面的研究相对较少。然而,考虑到为复杂任务设计传统非可塑性神经网络时得到的不错的梯度下降结果,将反向传播训练运用到具有可塑性连接的网络是非常有意义的——通过梯度下降不仅能优化基础权重,还能优化每个连接的可塑性量。研究者之前论证过这个方法的理论可行性和分析易行性(Miconi, 2016)。
本研究表明,该方法确实可以成功为非平凡任务训练大型网络(数百万的参数)。为了演示该方法,作者将其应用到三个不同类型的任务:复杂模式记忆(包括自然图像)、单样本分类(Omniglot 数据集)和强化学习(迷宫探索问题)。结果表明,可塑性网络在 Omniglot 数据集上得到了有竞争力的结果,并展现了它对迷宫探索问题的性能优化,以及它在复杂模式记忆的问题中优于非可塑性循环网络(LSTM)几个数量级的表现。这个结果不仅有利于寻找基于梯度的神经网络训练的新研究途径,同时也说明之前归因于进化或者先验设计的神经结构元属性实际上也是可以用梯度下降处理的,这也暗示仍然存在很大一部分我们之前没有想到过的元学习算法。
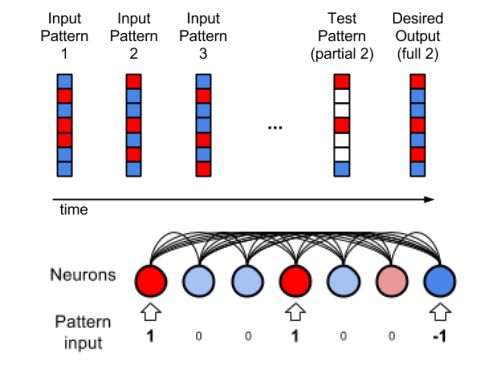
图 1:顶部:任务概念描述。底部:架构构造描述。
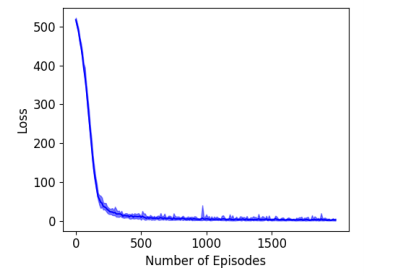
图 2:1000 位模式记忆的学习曲线(显示了十次结果:阴影区域表示了最小损失和最大损失,粗曲线表示平均损失)。
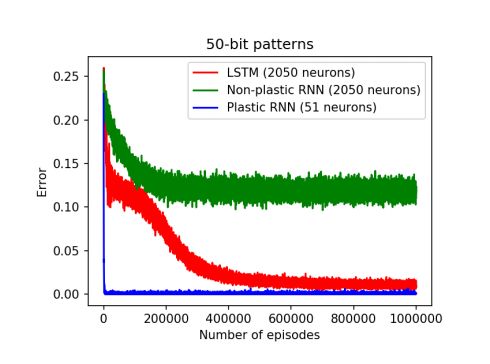
图 3:使用具有 2050 个神经元的非可塑 RNN 的 50 位模式记忆的学习曲线(绿线),使用具有 2050 个神经元的 LSTM 的学习曲线(红线),以及具有相同参数却只用了 51 个神经元的可微可塑权重网络的学习曲线(蓝线)。

图 4:(a) 利用有遮挡的图像测试集(训练时没使用过的数据)进行典型图像重建的结果。每一行都是一个完整的重建过程。
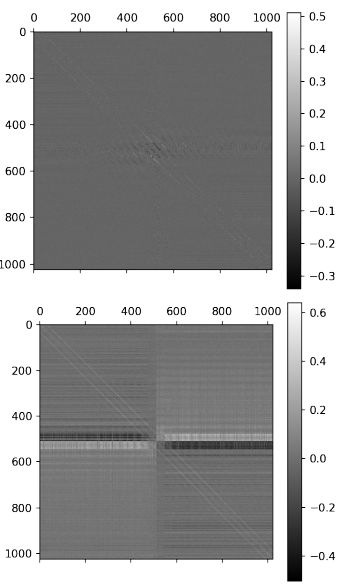
图 4:(b) 训练后的基线权重 wi,j 矩阵(顶部)以及可塑性系数αi,j(底部)。每一列描述了单个单元的输入,垂直相邻的元素描述图像中水平相邻像素的输入。注意两个矩阵中的关键结构。
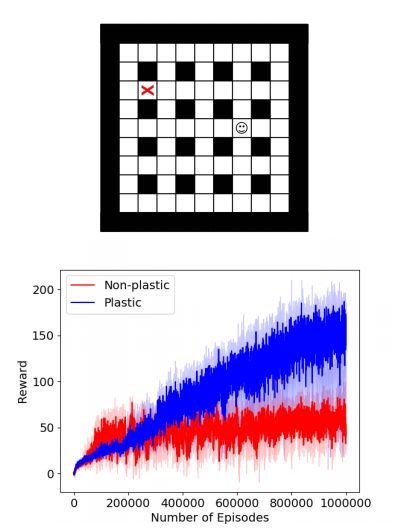
图 6:顶部:迷宫的示意图,指出了智能体的位置(用笑脸表示)以及奖励位置(用红十字表示,红十字只用于图像演示:奖励对智能体来说是不可见的)。底部:迷宫探索任务的训练曲线:每个训练事件(episode)通过 15 次运行得到中位数奖励以及四分位数奖励。
论文:Differentiable plasticity: training plastic neural networks with backpropagation(可微可塑性:利用反向传播训练可塑神经网络)

论文地址:https://arxiv.org/pdf/1804.02464.pdf
摘要: 我们怎样才能训练出能在初始训练之后利用经验持续快速高效学习的智能体呢?这里我们得到了生物大脑主要学习机制的启发:经过精巧进化得到的,能使生物终身高效学习的神经可塑性。我们发现,就如同连接权重,神经可塑性可以通过赫布可塑连接的大型(数百万个参数)循环网络的梯度下降来优化。首先,拥有超过二百万参数的循环可塑网络通过训练可以记忆和重建新的、高维度的(1000+像素)之前训练时没见过的自然图像。最重要的是,传统的非可塑循环网络不能解决这种问题。此外,经过训练的可塑网络可以解决常见的元学习问题诸如 Omniglot 任务,其结果十分优秀并且参数开销也很小。最后,在强化学习领域,可塑网络处理迷宫探索任务的表现优于非可塑的网络。我们得出结论,可微可塑性有望为元学习问题提供新的高效方法。
本文为机器之心编译, 转载请联系本公众号获得授权 。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com 
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

