分布式文件系统设计与实现
忙着开发软件,最近一直没什么时间写作。
今天我们谈一下关于分布式文件系统。
分布式文件系统在一直在存储领域拥有举足轻重的地位,涉及知识也比较多。
主流分布式系统设计,主要分为三个方向:
[1] 分布式存储系统
[2] 分布式计算系统
[3] 分布式管理系统
今天我们谈 分布式存储系统 中我们比较熟悉的 非结构化数据存储 设计与实现。
谈到分布式文件系统,目前大家比较熟悉的GFS(Google File System)或者GFS开源实现HDFS。
目前在国内已经家喻户晓,稍微大一点的公司都在使用HDFS,可以说HDFS是大数据系统的基石。
Hadoop 3.1版本发布,增加对各种云端存储系统的支持,设计很有意思,以后内容会介绍。
非结构化数据存储
GFS是开发出来存储Google海量的日志数据,网页,文档等文本信息,并且对其进行批处理,比如:配合 mapreduce 为文档建立倒排索引,计算网页 PageRank。
设计初衷,为了支持更大规模数据处理和很高的合计吞吐量,拥有很强的扩展性,可容纳那么大了的非结构化数据。
因为数据分布式存储,需要大量取数据计算,必须支持很强的容错性,设计之初贴近实际生产,组合一堆普通机器形成集群,提供强大的存储能力,大量机器配合工作,系统故障和硬件故障被认为是常态。
GFS很好地解决了,大文件,大规模顺序数据追加写,提供很高的合计吞吐量。
GFS,HDFS一类的分布式文件系统,非常适合数据一旦写入,文件很少修改的场景。这样的设计导致几乎无法支持随机访问(random access)操作,面对低延迟、实时性要求高的场景不适合。
GFS分布式文件系统,并非标准的Posix标准实现,GFS主要提供快照和记录追加操作,多路结果合并。
-
GFS架构
使用Master->Slave设计,元数据信息主要由Master管理,这样的设计大大降低系统的实现难度。
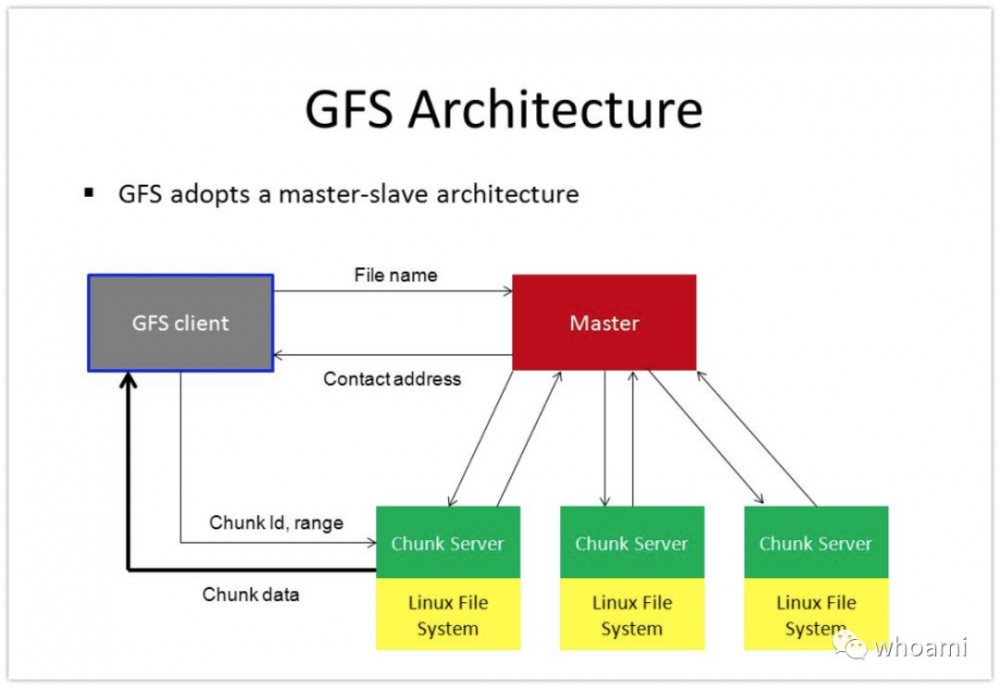
为防止Master压力过大,限制了数据存储大量,GFS中数据存储单元使用Chunk表示,Chunk支持64M。
Master节点掌握整个集群数据存储核心数据,集群扩展能力受限于master节点内存,比如:大量小文件导致元数据信息爆满。
分布式文件系统多副本,可支持容错的读取数据,根据负载情况,最近副本取数据。
因为集群支持容错,故障自动恢复,所以整个集群可以扩展到很大规模,在传统MPI、MPP中无法支持很大规模。
而今天我们也看到MPP和支持超大规模分布式文件系统融合的案例,使得MPP计算层可扩展到更大规模。
-
热点数据
分布式文件系统,热点数据,导致系统局部过载而出现严重故障?
在分布式非结构化数据存储中,是非常常见的,比如我们某个公共库文件或程序,为使用方便和容错,大家把它存储在HDFS,它被切块存储于100个节点的集群某3个机器中,由于大量业务系统或者程序随机加载引用,导致某3个机器压力特别大,看到监控系统飘红。
我们可以通过增加副本数量,来让更多副本能提供访问服务,解决问题。
早期使用MapReduce/Spark系统,为缩短计算时间,默认3副本,我们提高到6,9个,增加数据本地化计算的几率。
-
元数据
集群扩展Slave受限于Master节点内容,元数据信息都存在Master,并且常驻内存,大量小文件也会造成Master性能下降。
-
操作日志
操作日志的作用
[1] 持久化存储metadata
[2] 存储完整的操作命令,保障最终的操作顺序
元数据信息的变更,全都是通过日志记录来实现的,通过日志复制到多个节点,保障可靠性,即使主节点损坏,也可恢复其他节点为主节点,继续提供服务。日志可复现任何一个时间点的操作行为,保障系统数据。
-
Check point
当operation log达到一定大小时,GFS master会做checkpoint,相当于把内存的B-Tree格式的信息dump到磁盘中。当master需要重启时,可以读最近一次的checkpoint,然后replay它之后的operation log,加快恢复的时间。
做checkpoint的时候,GFS master会先切换到新的operation log,然后开新线程做checkpoint,所以,对新来的请求是基本是不会有影响的。
状态数据,底层主要使用高度压缩的B-Tree存储。
-
快照
使用copy-on-writer实现,基本上不会对现有数据读取有影响。
只读数据存储
[1] 适合追加方式的写入和读取操作
[2] 很少有随机写入操作
目前HDFS,GFS主要用来存储海量的离线数据,提供海量非结构化数据存储场景。
如果需要支持随机写、更新、删除数据,就选其他系统,比如:Kudu
冗余解决方案
容错考虑需要,有三倍冗余,目前主要有Erasure Codes实现,奇偶校验方法,可以缩小大量存储占用。
小结
[1] 没有在文件系层面提供任何的Cache机制,访问顺序读取加载大量文件,Cache支持意义不大
[2] 单个应用执行时机会不会重复读取数据
[3] GFS/HDFS适合流式读取一个大型数据集
[4] 在大型数据集中随机seek到某个位置,之后每次读取少量数据,提升效率。
[5] GFS/HDFS设计预期是使用大量的不可靠节点组件集群,因此,灾难冗余是此类系统设计的核心。
[6] 存储固定大小的Chunk,容易重新均衡数据。
[7] 原子记录追加,保障系统数据一致性。
[8] 中心Master设计,让复杂的分布式系统实现简单化,不用考虑数据一致性,元数据同步问题。
GFS/HDFS设计初衷,保障有大量并发读写操作时,能够提供很高的合计吞吐量。
通过分离控制流(Master)和数据流(Chunk client)来实现,所以我们经常提起的Edge节点会对整个系统性能有很大的影响。
Master节点负载过高,通过Chunk租约将控制权交给主副本(主Chunk),将Master压力降到最低。
目前类似GFS的开源实现,主流选择HDFS,而且HDFS在实现上,弥补很多GFS中的不足。我也没看到有可替代HDFS的系统,因为有HDFS造就今天繁荣的Hadoop生态系统,数据分析引擎、数据存储引擎百花齐放。
软件系统的设计与实现是为解决现实问题而出现,设计上会有很多权衡,不同的权衡造就不同的系统,各自有擅长的场景。
欢迎关注微信公众号[Whoami],阅读更多内容。

原创文章,转载请注明: 转载自Itweet的博客
本博客的文章集合: http://www.itweet.cn/blog/archive
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

