集合类HashMap,HashTable,ConcurrentHashMap区别?
1.HashMap
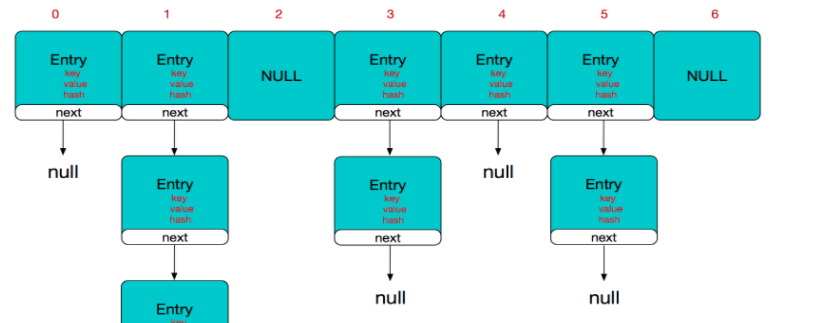 简单来说,HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,如果定位到的数组位置不含链表(当前entry的next指向null),那么对于查找,添加等操作很快,仅需一次寻址即可;如果定位到的数组包含链表,对于添加操作,其时间复杂度依然为O(1),因为最新的Entry会插入链表头部,仅需简单改变引用链即可,而对于查找操作来讲,此时就需要遍历链表,然后通过key对象的equals方法逐一比对查找。所以,性能考虑,HashMap中的链表出现越少,性能才会越好。
hash函数(对key的hashcode进一步进行计算以及二进制位的调整等来保证最终获取的存储位置尽量分布均匀)
简单来说,HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,如果定位到的数组位置不含链表(当前entry的next指向null),那么对于查找,添加等操作很快,仅需一次寻址即可;如果定位到的数组包含链表,对于添加操作,其时间复杂度依然为O(1),因为最新的Entry会插入链表头部,仅需简单改变引用链即可,而对于查找操作来讲,此时就需要遍历链表,然后通过key对象的equals方法逐一比对查找。所以,性能考虑,HashMap中的链表出现越少,性能才会越好。
hash函数(对key的hashcode进一步进行计算以及二进制位的调整等来保证最终获取的存储位置尽量分布均匀)
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }查找函数
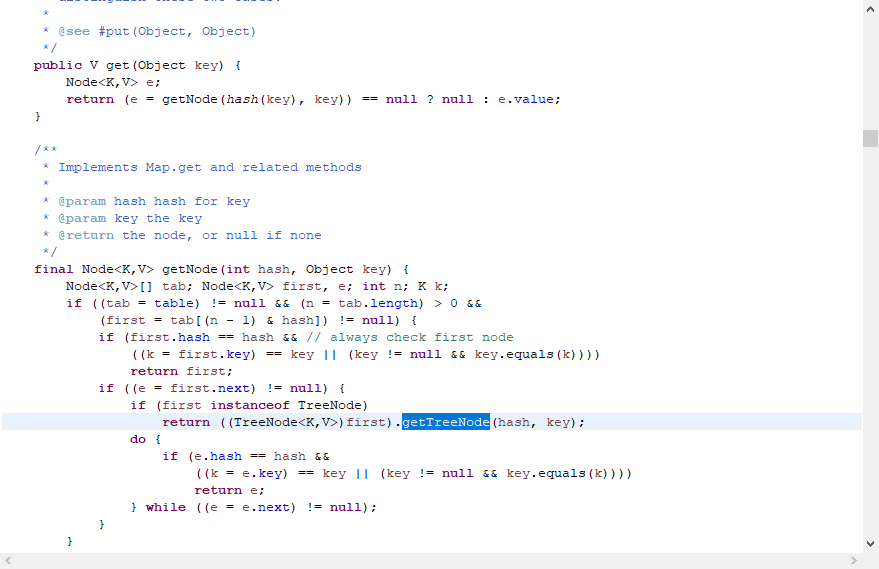 在JDK1.8 对hashmap做了改造,如下图
在JDK1.8 对hashmap做了改造,如下图
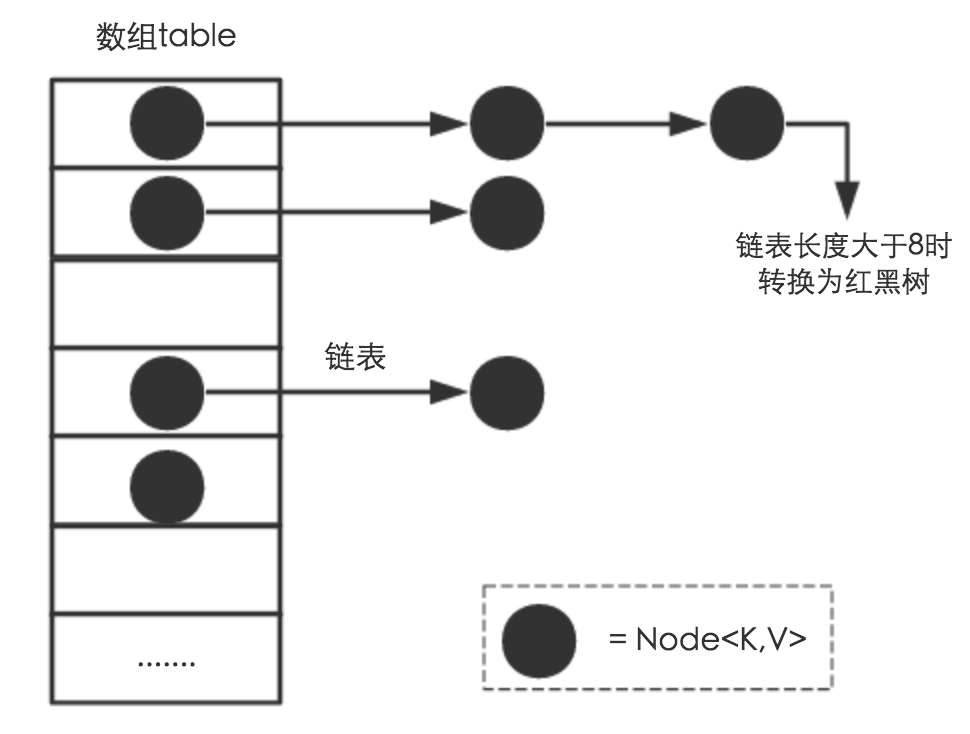
JDK 1.8 以前 HashMap 的实现是 数组+链表,即使哈希函数取得再好,也很难达到元素百分百均匀分布。 当 HashMap 中有大量的元素都存放到同一个桶中时,这个桶下有一条长长的链表,这个时候 HashMap 就相当于一个单链表,假如单链表有 n 个元素,遍历的时间复杂度就是 O(n),完全失去了它的优势。 针对这种情况,JDK 1.8 中引入了 红黑树(查找时间复杂度为 O(logn))来优化这个问题
2.HashTable
 Hashtable它包括几个重要的成员变量:table, count, threshold, loadFactor, modCount。
Hashtable它包括几个重要的成员变量:table, count, threshold, loadFactor, modCount。
- table是一个 Entry[] 数组类型,而 Entry(在 HashMap 中有讲解过)实际上就是一个单向链表。哈希表的"key-value键值对"都是存储在Entry数组中的。
- count 是 Hashtable 的大小,它是 Hashtable 保存的键值对的数量。
- threshold 是 Hashtable 的阈值,用于判断是否需要调整 Hashtable 的容量。threshold 的值="容量*加载因子"。
- loadFactor 就是加载因子。
- modCount 是用来实现 fail-fast 机制的。
put 方法
put 方法的整个流程为:- 判断 value 是否为空,为空则抛出异常;
- 计算 key 的 hash 值,并根据 hash 值获得 key 在 table 数组中的位置 index,如果 table[index] 元素不为空,则进行迭代,如果遇到相同的 key,则直接替换,并返回旧 value;
- 否则,我们可以将其插入到 table[index] 位置。
public synchronized V put(K key, V value) {
// Make sure the value is not null确保value不为null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
//确保key不在hashtable中
//首先,通过hash方法计算key的哈希值,并计算得出index值,确定其在table[]中的位置
//其次,迭代index索引位置的链表,如果该位置处的链表存在相同的key,则替换value,返回旧的value
Entry tab[] = table;
int hash = hash(key);
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
V old = e.value;
e.value = value;
return old;
}
}
modCount++;
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
//如果超过阀值,就进行rehash操作
rehash();
tab = table;
hash = hash(key);
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
//将值插入,返回的为null
Entry<K,V> e = tab[index];
// 创建新的Entry节点,并将新的Entry插入Hashtable的index位置,并设置e为新的Entry的下一个元素
tab[index] = new Entry<>(hash, key, value, e);
count++;
return null;
}get 方法
相比较于 put 方法,get 方法则简单很多。其过程就是首先通过 hash()方法求得 key 的哈希值,然后根据 hash 值得到 index 索引(上述两步所用的算法与 put 方法都相同)。然后迭代链表,返回匹配的 key 的对应的 value;找不到则返回 null。public synchronized V get(Object key) {
Entry tab[] = table;
int hash = hash(key);
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return e.value;
}
}
return null;
}3.ConcurrentHashMap
在JDK1.7版本中,ConcurrentHashMap的数据结构是由一个Segment数组和多个HashEntry组成 Segment数组的意义就是将一个大的table分割成多个小的table来进行加锁,也就是上面的提到的锁分离技术,而每一个Segment元素存储的是HashEntry数组+链表,这个和HashMap的数据存储结构一样
Segment数组的意义就是将一个大的table分割成多个小的table来进行加锁,也就是上面的提到的锁分离技术,而每一个Segment元素存储的是HashEntry数组+链表,这个和HashMap的数据存储结构一样
put操作
对于ConcurrentHashMap的数据插入,这里要进行两次Hash去定位数据的存储位置从上Segment的继承体系可以看出,Segment实现了ReentrantLock,也就带有锁的功能,当执行put操作时,会进行第一次key的hash来定位Segment的位置,如果该Segment还没有初始化,即通过CAS操作进行赋值,然后进行第二次hash操作,找到相应的HashEntry的位置,这里会利用继承过来的锁的特性,在将数据插入指定的HashEntry位置时(链表的尾端),会通过继承ReentrantLock的tryLock()方法尝试去获取锁,如果获取成功就直接插入相应的位置,如果已经有线程获取该Segment的锁,那当前线程会以自旋的方式去继续的调用tryLock()方法去获取锁,超过指定次数就挂起,等待唤醒。staticclassSegment<K,V>extendsReentrantLockimplementsSerializable {
get操作
ConcurrentHashMap的get操作跟HashMap类似,只是ConcurrentHashMap第一次需要经过一次hash定位到Segment的位置,然后再hash定位到指定的HashEntry,遍历该HashEntry下的链表进行对比,成功就返回,不成功就返回null。 计算ConcurrentHashMap的元素大小是一个有趣的问题,因为他是并发操作的,就是在你计算size的时候,他还在并发的插入数据,可能会导致你计算出来的size和你实际的size有相差(在你return size的时候,插入了多个数据),要解决这个问题,JDK1.7版本用两种方案。- 第一种方案他会使用不加锁的模式去尝试多次计算ConcurrentHashMap的size,最多三次,比较前后两次计算的结果,结果一致就认为当前没有元素加入,计算的结果是准确的;
- 第二种方案是如果第一种方案不符合,他就会给每个Segment加上锁,然后计算ConcurrentHashMap的size返回。
JDK1.8的实现
JDK1.8的实现已经摒弃了Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用Synchronized和CAS来操作,整个看起来就像是优化过且线程安全的HashMap,虽然在JDK1.8中还能看到Segment的数据结构,但是已经简化了属性,只是为了兼容旧版本。
put操作
在上面的例子中我们新增个人信息会调用put方法,我们来看下。- 如果没有初始化就先调用initTable()方法来进行初始化过程
- 如果没有hash冲突就直接CAS插入
- 如果还在进行扩容操作就先进行扩容
- 如果存在hash冲突,就加锁来保证线程安全,这里有两种情况,一种是链表形式就直接遍历到尾端插入,一种是红黑树就按照红黑树结构插入,
- 最后一个如果该链表的数量大于阈值8,就要先转换成黑红树的结构,break再一次进入循环
- 如果添加成功就调用addCount()方法统计size,并且检查是否需要扩容
get操作
我们现在要回到开始的例子中,我们对个人信息进行了新增之后,我们要获取所新增的信息,使用String name = map.get(“name”)获取新增的name信息,现在我们依旧用debug的方式来分析下ConcurrentHashMap的获取方法get()publicV get(Object key) {Node<K,V>[] tab; Node<K,V> e, p;intn, eh; K ek;inth = spread(key.hashCode());//计算两次hashif((tab = table) !=null&& (n = tab.length) >0&&(e = tabAt(tab, (n -1) & h)) !=null) {//读取首节点的Node元素if((eh = e.hash) == h) {//如果该节点就是首节点就返回if((ek = e.key) == key || (ek !=null&& key.equals(ek)))returne.val;}//hash值为负值表示正在扩容,这个时候查的是ForwardingNode的find方法来定位到nextTable来//查找,查找到就返回elseif(eh <0)return(p = e.find(h, key)) !=null? p.val :null;while((e = e.next) !=null) {//既不是首节点也不是ForwardingNode,那就往下遍历if(e.hash == h &&((ek = e.key) == key || (ek !=null&& key.equals(ek))))returne.val;}}returnnull;}
- 计算hash值,定位到该table索引位置,如果是首节点符合就返回
- 如果遇到扩容的时候,会调用标志正在扩容节点ForwardingNode的find方法,查找该节点,匹配就返回
- 以上都不符合的话,就往下遍历节点,匹配就返回,否则最后就返回null
- JDK1.8的实现降低锁的粒度,JDK1.7版本锁的粒度是基于Segment的,包含多个HashEntry,而JDK1.8锁的粒度就是HashEntry(首节点)
- JDK1.8版本的数据结构变得更加简单,使得操作也更加清晰流畅,因为已经使用synchronized来进行同步,所以不需要分段锁的概念,也就不需要Segment这种数据结构了,由于粒度的降低,实现的复杂度也增加了
- JDK1.8使用红黑树来优化链表,基于长度很长的链表的遍历是一个很漫长的过程,而红黑树的遍历效率是很快的,代替一定阈值的链表,这样形成一个最佳拍档
- JDK1.8为什么使用内置锁synchronized来代替重入锁ReentrantLock,我觉得有以下几点:
- 因为粒度降低了,在相对而言的低粒度加锁方式,synchronized并不比ReentrantLock差,在粗粒度加锁中ReentrantLock可能通过Condition来控制各个低粒度的边界,更加的灵活,而在低粒度中,Condition的优势就没有了
- JVM的开发团队从来都没有放弃synchronized,而且基于JVM的synchronized优化空间更大,使用内嵌的关键字比使用API更加自然
- 在大量的数据操作下,对于JVM的内存压力,基于API的ReentrantLock会开销更多的内存,虽然不是瓶颈,但是也是一个选择依据
4.总结
Hashtable和HashMap有几个主要的不同:线程安全以及速度。仅在你需要完全的线程安全的时候使用Hashtable,而如果你使用Java 5或以上的话,请使用ConcurrentHashMap吧。
正文到此结束
- 本文标签: ConcurrentHashMap HashTable HashMap 集合类
- 版权声明: 本文由HARRIES原创发布,转载请遵循《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

