海康威视Oral论文:分层式共现网络,实现更好的动作识别和检测
动作识别和检测正得到计算机视觉领域越来越多的关注。近日,海康威视在 arXiv 发布了在这方面的一项实现了新的最佳表现的研究成果,该论文也是 IJCAI 2018 Oral 论文。
动作识别和检测等对人类行为的分析是计算机视觉领域一个基础而又困难的任务,也有很广泛的应用范围,比如智能监控系统、人机交互、游戏控制和机器人。铰接式的人体姿态(也被称为骨架(skeleton))能为描述人体动作提供非常好的表征。一方面,骨架数据在背景噪声中具有固有的稳健性,并且能提供人体动作的抽象信息和高层面特征。另一方面,与 RGB 数据相比,骨架数据的规模非常小,这让我们可以设计出轻量级且硬件友好的模型。
本论文关注的是基于骨架的人体动作识别和检测问题(图 1)。骨架的相互作用和组合在描述动作特征上共同发挥了关键性作用。有很多早期研究都曾试图根据骨架序列来设计和提取共现特征(co-occurrence feature),比如每个关节的配对的相对位置 [Wang et al., 2014]、配对关节的空间方向 [Jin and Choi, 2012]、Cov3DJ [Hussein et al., 2013] 和 HOJ3D [Xia et al., 2012] 等基于统计的特征。另一方面,带有长短期记忆(LSTM)神经元的循环神经网络(RNN)也常被用于建模骨架的时间序列 [Shahroudy et al., 2016; Song et al., 2017; Liu et al., 2016]。尽管 LSTM 网络就是为建模长期的时间依赖关系而设计的,但由于时间建模是在原始输入空间上完成的,所以它们难以直接从骨架上学习到高层面的特征 [Sainath et al., 2015]。而全连接层则有能力聚合所有输入神经元的全局信息,进而可以学习到共现特征。[Zhu et al., 2016] 提出了一种端到端的全连接深度 LSTM 网络来根据骨架数据学习共现特征。
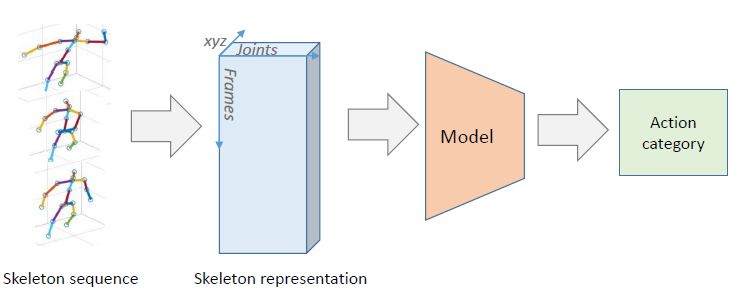
图 1:基于骨架的人体动作识别的工作流程
CNN 模型在提取高层面信息方面能力出色,并且也已经被用于根据骨架学习空间-时间特征 [Du et al., 2016; Ke et al., 2017]。这些基于 CNN 的方法可以通过将时间动态和骨架关节分别编码成行和列而将骨架序列表示成一张图像,然后就像图像分类一样将图像输入 CNN 来识别其中含有的动作。但是,在这种情况下,只有卷积核内的相邻关节才被认为是在学习共现特征。尽管感受野(receptive field)能在之后的卷积层中覆盖骨架的所有关节,但我们很难有效地从所有关节中挖掘共现特征。由于空间维度中的权重共享机制,CNN 模型无法为每个关节都学习自由的参数。这促使我们设计一个能获得所有关节的全局响应的模型,以利用不同关节之间的相关性。
我们提出了一种端到端的共现特征学习框架,其使用了 CNN 来自动地从骨架序列中学习分层的共现特征。我们发现一个卷积层的输出是来自所有输入通道的全局响应。如果一个骨架的每个关节都被当作是一个通道,那么卷积层就可以轻松地学习所有关节的共现。更具体而言,我们将骨架序列表示成了一个形状帧×关节×3(最后一维作为通道)的张量。我们首先使用核大小为 n×1 的卷积层独立地为每个关节学习了点层面的特征。然后我们再将该卷积层的输出转置,以将关节的维度作为通道。在这个转置运算之后,后续的层分层地聚合来自所有关节的全局特征。此外,我们引入了一种双流式的框架 [Simonyan and Zisserman, 2014] 来明确地融合骨架运动特征。
本研究工作的主要贡献总结如下:
-
我们提出使用 CNN 模型来学习骨架数据的全局共现特征,研究表明这优于局部共现特征。
-
我们设计了一种全新的端到端分层式特征学习网络,其中的特征是从点层面特征到全局共现特征逐渐聚合起来的。
-
我们全面地使用了多人特征融合策略,这让我们的网络可以轻松地扩展用于人数不同的场景。
-
在动作识别和检测任务的基准上,我们提出的框架优于所有已有的当前最佳方法。
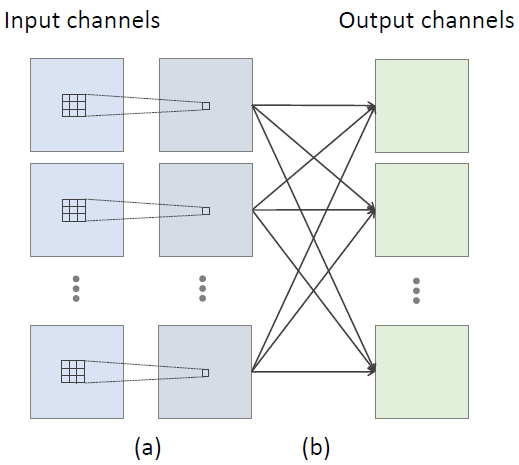
图 2:3×3 卷积的分解分为两个步骤。(a) 每个输入通道的空间域中的独立 2D 卷积,其中的特征是从 3×3 的临近区域局部聚合的。(b) 各个通道上逐个元素求和,其中的特征是在所有输入通道上全局地聚合。
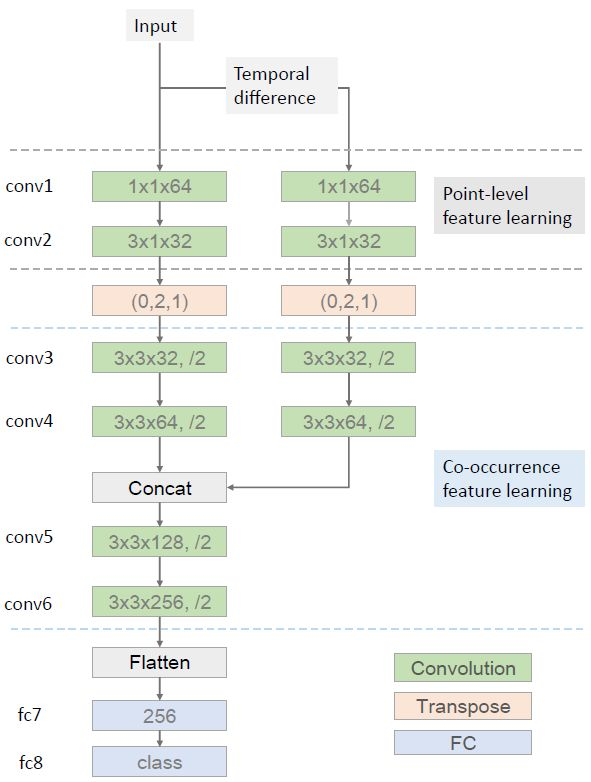
图 3:我们提出的分层式共现网络(HCN:Hierarchical Co-occurrence Network)的概况。绿色模块是卷积层,其中最后一维表示输出通道的数量。后面的「/2」表示卷积之后附带的最大池化层,步幅为 2。转置层是根据顺序参数重新排列输入张量的维度。conv1、conv5、conv6 和 fc7 之后附加了 ReLU 激活函数以引入非线性。
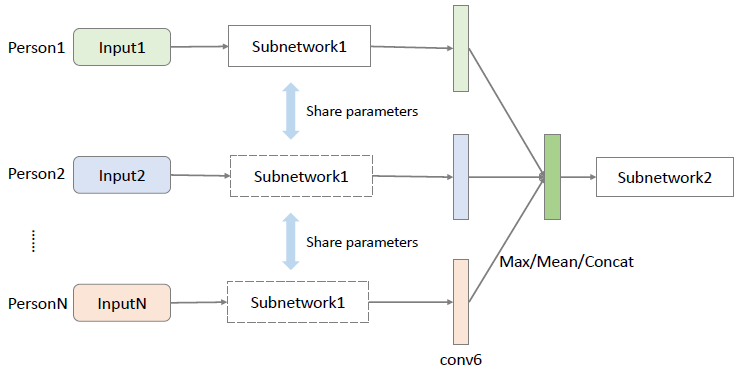
图 4:用于多人特征融合的后期融合(late fusion)图。最大、平均和连接操作在表现和泛化性能上得到了评估。
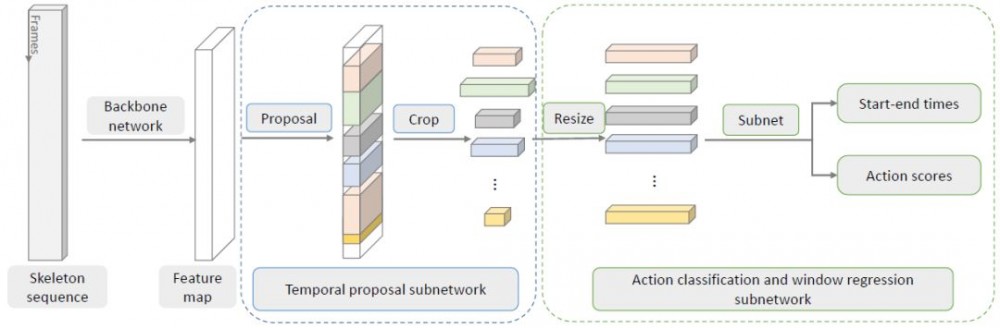
图 5:时间动作检测框架。图 3 描述了其中的骨干网络。还有两个子网络分别用于时间上提议的分割和动作分类。
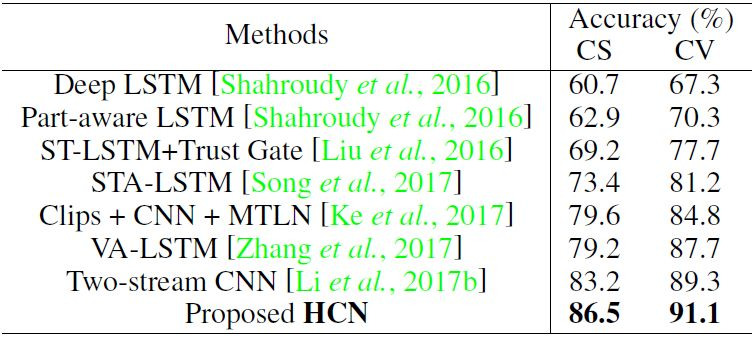
表 2:在 NTU RGB+D 数据集上的动作分类表现。CS 和 CV 分别表示 cross-subject 和 cross-view 的设置。
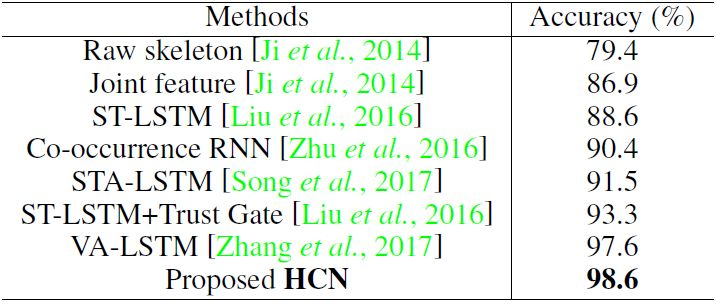
表 3:在 SBU 数据集上的动作分类表现。
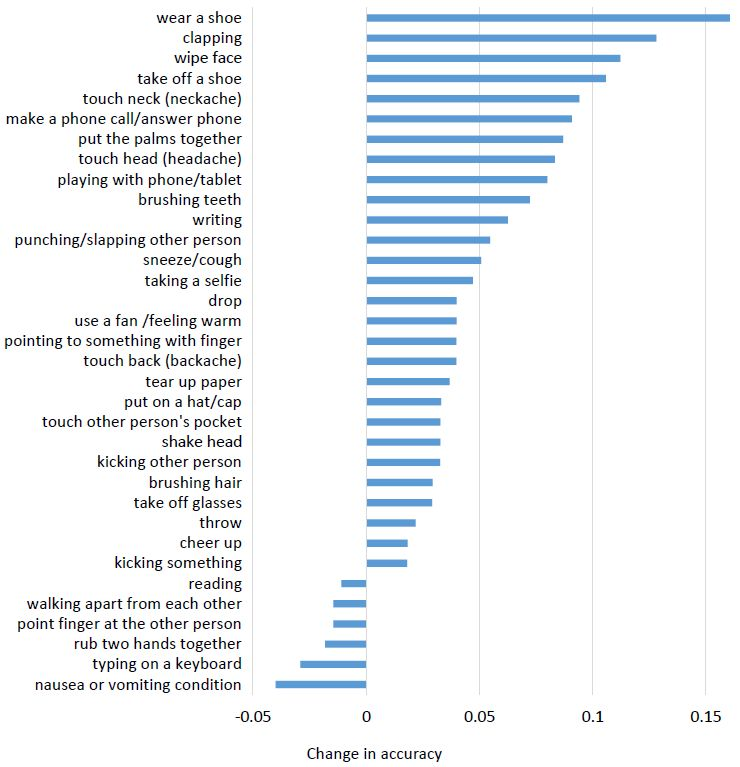
图 6:在 NTU RGB+D 数据集上的 cross-subject 设置中,在每个类别上 HCN 相对于 HCN-local 的准确度变化。为了清楚简明,这里只给出了变化超过 1% 的类别。
论文:使用分层聚合实现用于动作识别和检测的基于骨架数据的共现特征学习(Co-occurrence Feature Learning from Skeleton Data for Action Recognition and Detection with Hierarchical Aggregation)

论文链接: https://arxiv.org/abs/1804.06055
摘要:随着大规模骨架数据集变得可用,基于骨架的人体动作识别近来也受到了越来越多的关注。解决这一任务的最关键因素在于两方面:用于关节共现的帧内表征和用于骨架的时间演化的帧间表征。我们在本论文中提出了一种端到端的卷积式共现特征学习框架。这些共现特征是用一种分层式的方法学习到的,其中不同层次的环境信息(contextual information)是逐渐聚合的。首先独立地编码每个节点的点层面的信息。然后同时在空间域和时间域将它们组合成形义表征。具体而言,我们引入了一种全局空间聚合方案,可以学习到优于局部聚合方法的关节共现特征。此外,我们还将原始的骨架坐标与它们的时间差异整合成了一种双流式的范式。实验表明,我们的方法在 NTU RGB+D、SBU Kinect Interaction 和 PKU-MMD 等动作识别和检测基准上的表现能稳定地优于其它当前最佳方法。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

