MILA提出防御增强型网络:简单修改已有网络即可提升防攻击能力
1 引言
深度神经网络已经在很多不同任务上都取得了成功。这样的成功推动了其在可靠性与安全性至关重要的领域的应用,其中包括自动驾驶汽车(Bojarski et al., 2016)、医疗保健、人脸识别(Sharif et al., 2017)以及恶意软件检测(LeCun et al., 2015)。当智能体所使用的系统表现不佳时,安全性问题就会出现。当模型在训练过程中看到的输入数据的分布不同于模型评估的数据分布时,会出现可靠性问题。
对抗样本(Goodfellow et al., 2014)是一种攻击神经网络模型的方法。这种攻击是对输入进行微小的扰动,从而改变所预测的类别。需要指出,得到肉眼无法察觉的微小扰动是可能的。事实证明,简单的梯度方法就能让人找到往往能改变输出类别的修改输入的方式(Szegedy et al., 2013; Goodfellow et al., 2014)。更近期的一项研究还表明,有可能通过创造甚至能贴在摄像头上的贴片来改变具有高置信度的输出类别(Brown et al., 2017)。
为了应对对抗样本,研究者开发了一些防御方法。其中一些最为突出的防御类型包括特征压缩(Xu et al., 2017)、输入的自适应编码(Jacob Buckman, 2018)、与 distillation 相关的方法(Papernot et al., 2015)。现有的方法能实现一些稳健性,但大都不易部署。此外,事实证明很多方法都容易受到梯度掩码的影响。而其它一些方法还需要直接在可见空间中训练一个生成模型,这目前甚至在相对简单的数据集上也很难办到。
我们的目标是提供一种方法,其(i)是通用的,可加入到已有的网络中;(ii)能使网络在对抗攻击下保持稳健;(iii)能为输入数据的存在提供一个可靠的信号,且不取决于网络训练所基于的流形。直接在输入数据上使用生成模型来提升稳健性并不是什么新思想。我们的主要贡献是在所学习到的隐藏表征的分布上实现了这种稳健性,而不是让对流形外的样本的识别更容易,如图 1 所示。
我们提出了 Fortified Networks(防御增强型网络)。其防御增强方法包含使用去噪自动编码器来「装饰(decorate)」原始网络的隐藏层。我们使用了 Python 意义上的「装饰」,可以应用于任何函数(在这里是网络的一部分)并将其行为无明确修改地延展。防御增强方法满足上面陈述的三个目标。我们会讨论这种隐藏层的防御增强方法的直观理解并阐述该方法的一些显著属性。我们在 MNIST、Fashion-MNIST、CIFAR10 数据集上针对白盒攻击和黑盒攻击对我们提出的方法进行了评估。
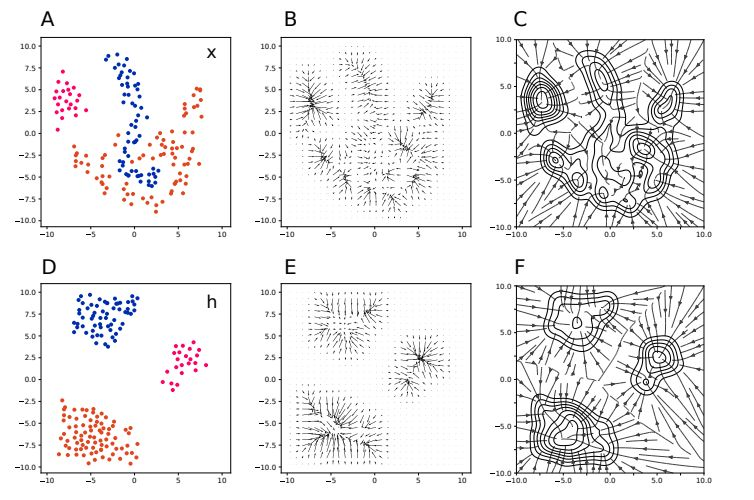
图 1:输入空间(上)和抽象的隐藏空间(下)中自动编码器动态的示意图。左边一列展示了来自三个不同类别的数据点,中间一列给出了描述自动编码器动态的向量场,右边一列展示了一些所得到的轨迹和吸引盆地(basin of attraction)。Fortified Networks 背后的关键动机是:在抽象空间中,可以使用更简单的统计结构来更轻松地识别指向数据流形之外的方向,这让其能更轻松地将对抗样本映射回其所投射的数据流形。
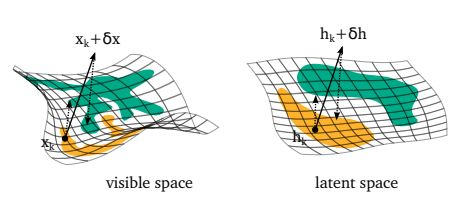
图 2:在可见空间(左)和隐藏空间(右)中映射回流形的过程的示意图。阴影区域表示空间中由给定类别的数据点所占据的区域(它们不表示决策边界)
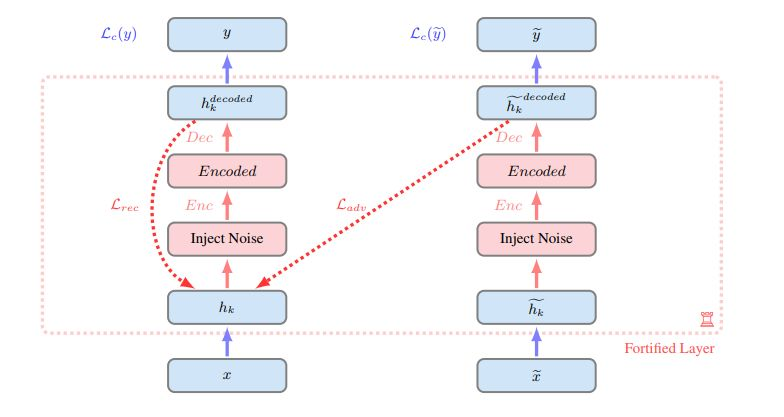
图 3:单层的 fortified network 的图示。使用数据样本 x 及其对应的对抗样本  对网络进行评估。隐藏单元 hk 和
对网络进行评估。隐藏单元 hk 和  中都会添加噪声,然后使用编码器 Enc 进行编码,再通过解码器 Dec 解码。自动编码器(用红色表示)的训练目标是重建对应清洁输入的隐藏单元 hk。虚线表示两个重建成本:良性样本的重建成本(Lrec)和对抗样本的重建成本(Ladv)。注意,一个层可以在网络中的任何位置得到防御增强。
中都会添加噪声,然后使用编码器 Enc 进行编码,再通过解码器 Dec 解码。自动编码器(用红色表示)的训练目标是重建对应清洁输入的隐藏单元 hk。虚线表示两个重建成本:良性样本的重建成本(Lrec)和对抗样本的重建成本(Ladv)。注意,一个层可以在网络中的任何位置得到防御增强。
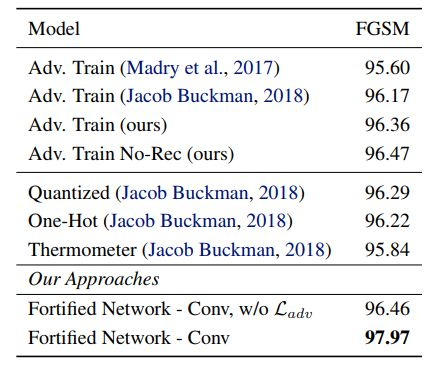
表 1:使用 FGSM 进行的白盒 MNIST 攻击下,不同方法的准确度,其中的模型是一个卷积网络。我们使用了 ε 为 0.3 的标准 FGSM 攻击参数,并且与其他研究者发表的对抗训练防御方法进行了比较。我们也执行了 ablation study,考虑了移除对抗样本 Ladv 上的重建误差的情况,以及将防御增强层中的激活函数从 leaky relu 改成 tanh 的情况——我们发现这对这一情况有所助益。尽管我们的基准和预先防御增强的网络使用了 relu 激活函数,但我们发现通过在所有层中使用 leaky relu,使用标准对抗训练在 FGSM ε = 0.3 上的准确度可以提升至 99.2%,这说明我们自己的基准和过去研究所报告的基准一直都太弱了。
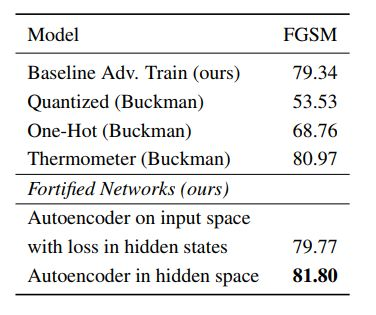
表 4:在使用标准的 ε = 0.03 的 FGSM 的白盒 CIFAR 攻击下的准确度,其中每个模型都是一个卷积网络。我们的基准对抗训练方法是来自(Nicolas Papernot, 2017)的残差网络模型。
标题:防御增强型网络:通过建模隐藏表征的流形来提升深度网络的稳健性(Fortified Networks: Improving the Robustness of Deep Networks by Modeling the Manifold of Hidden Representations)

论文:https://arxiv.org/abs/1804.02485v1
深度网络已经在很多不同的重要任务上得到了出色的结果。但是,它仍然有一个众所周知的缺点:在与训练数据分布不同的数据上训练时往往表现不佳——即使这些不同之处非常细微,比如对抗样本的情况。我们提出了 Fortified Networks,这是一种对已有网络进行的简单修改,能够通过识别不在数据流形上的隐藏状态来强化深度网络中隐藏层的防御,并且还能将这些隐藏状态映射回网络表现优良的数据流形部分。我们的主要贡献是表明:增强这些隐藏状态的防御能提升深度网络的稳健性;并且我们的实验(i)表明这种方法能在黑盒和白盒威胁模型中提升标准对抗攻击下的稳健性;(ii)说明我们所获得的提升并非主要源自梯度掩码问题;(iii)表明了在隐藏层而非输入空间执行这种防御增强的优势。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

