从0到1,滴滴DB自动化运维架构实践
滴滴现在主要使用的数据库是 MySQL。滴滴的业务扩展很快,目前 DB 服务器大致有 3000-4000 台,实例就更恐怖了,整体有 7000-8000。

在这种情况,靠纯人工去做运维是不可能的了,下面和大家我们自动化运维从 0 到 1 的实践。
今天的分享主要分为五个部分:
- 滴滴 DB 架构介绍
- 主要工作内容
- 主要关注模块
- 自动化模块
- 后续补充项
滴滴 DB 架构介绍
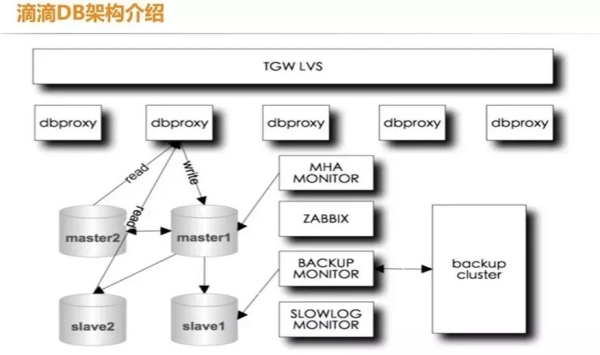
一般来说,自动化运维都会根据自己原有的架构来设计自动化运维平台,上图是滴滴 DB 的架构图,最上面是 TGW LVS,也就是大家所熟悉的 VIP,接下来是代理层 dbproxy。
代理层下面是 MySQL 的主从关系,一般情况是一主、一备主和一个从库,如果读取操作多,QPS 会比较高,从库也需相应的增多。
同时还要有 MySQL 高可用的监控来应对主库挂了等等的异常情况。运维监控,我们是使用最常见的 ZABBIX 来做的。除此之外,我们还做了备份模块和性能优化的模块。
dbproxy 相当于一个入口,连接应用,它是分布式的,因此每台上都会有自己的原始配置,所有的访问 DB 的流量都要经过 dbproxy 层。
dbproxy 会记录正常的访问日志,还有一些错误日志,例如没有加白名单或者是 SQL 语法错误等等都会在 dbproxy 层拦截,产生错误日志。
上图的架构就是我们在做自动化运维的初始部署,我们希望能够完成从业务申请到部署完成的一系列连贯动作。
主要工作内容
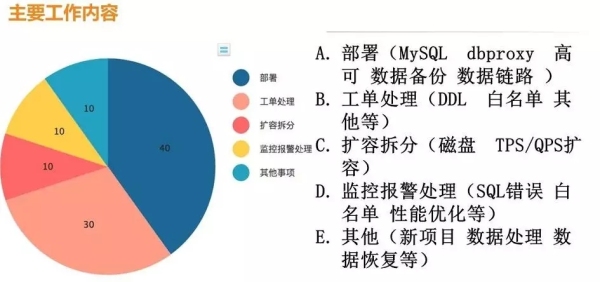
我们平时的工作内容如上图所示,基本包括部署、工单处理、扩容拆分、监控报警处理以及其他任务。
一周时间,RD 申请 30—50 个实例在我们的工作中是很常见的,这时如果没有自动化运维,单纯靠自己手工部署的话,是很消耗时间的。
工单处理的工作内容基本就是做一些 DDL、表结构的变更,白名单以及其他需求。
随着业务的发展,数据量会猛增,由于单机磁盘的存储是有限的,这时我们就要思考扩容、拆分的问题了。
还有一种情况是磁盘可能足够存储,但是你的 TPS/QPS 单机可能撑不住,这时也要去做扩容;监控报警处理指的是我们前面提到的 SQL 错误,白名单没有加以及其他一些报警。
其中,部署和工单处理是我们日常工作的重头,其占比大约为 70%。但是这一部分工作很容易自动化,一旦实现自动化,我们的工作强度会大大降低。

我们的工作痛点前面也提到了一部分,第一个就是因为量大,我们每周都会有很多的新申请,所以这部分工作的自动化是迫在眉睫的。
其次,我们的业务还有一个特点就是峰值比较集中,因为打车一般都集中发生在早高峰或晚高峰,所以系统的瓶颈也集中在这两个时间段。
第三个是数据库的延时,业务一般都会有超时时间的设置,数据库的延时是非常敏感的。
一个查询进入到数据库再到返回结果的延时,这里的延迟指的不是我们平常意义上的主从同步数据的延时,指的是对业务 SQL 的响应时间,在线 DDL 的表结构修改也会影响到延时。
最后就是工作的多样性。
主要关注模块

做自动化运维,之前的模块肯定是不能丢掉的。之前,我们的高可用、数据备份、监控报警、在线 DDL 系统等重点关注模式是使用 PT,现在我们改用了 ghost。
在完成整个运维自动化的过程中,我们做的第一步是 DBA 的自动化运维,其次是数据库系统服务化。
当然现在我们的功能还达不到云服务商提供的那样,但是业务如果需要申请一个 DB,相关人员在平台上操作几步就可以自己完成。

既然要做自动化运维,那么所有的东西就必须要标准化。我们根据之前的架构做了一些标准化的工作。
例如 OS 初始化的标准化(文件系统,内核设置,磁盘挂载目录等)和数据库层面的标准化(配置文件、部署路径、多实例目录命名规则以及 ID 的命名规则)。
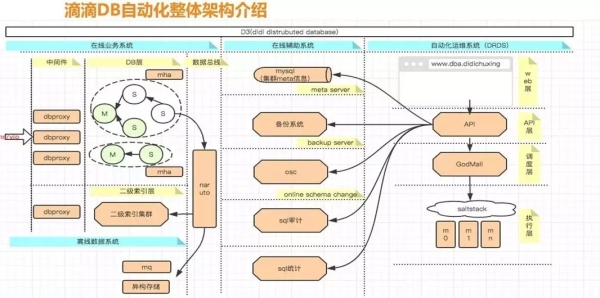
上图是滴滴 DB 自动化架构的细节展示。
在线业务系统的最左侧是 VIP,第二列是代理层中间件,第三列是 MySQL,在这一层我们一般是用 MHA 来保证 MySQL 的高可用。
第四列是数据总线,很多人可能不理解数据总线,我举个简单的例子,如果乘客或者司机想要查询历史订单,那么你当然不能直接去线上的订单库里查询。
线上订单库一般是按城市来分的,所以你还需要按照司机或乘客的 ID 将订单数据哈希到另一张表里,并且在这个新的库里进行历史数据的查询,相当于对数据重新做了一次分发和哈希。
在线辅助系统主要包括 MySQL 集群 meta 信息、在线 DDL、SQL 审计、SQL 统计等。
自动化运维系统的 Web 层更多的是前端、界面化的东西,接下来是 API 层、调度层和执行层。
API 层联动着很多操作,假设我现在去 Web 端申请了一个实例,那么接下来 API 层就会有一些动作。
例如新建实例、新建 MySQL 集群、新建 dbproxy,之后还需要做备份相关的东西。
自动化模块
在线业务系统

中间件的扩容指的是 dbproxy 层,可能我们最开始只有三台,但是随着访问的增多,它本身也需要扩容。
DB 层,就如我们刚才看到的 MHA 那一块,一开始我们可能申请了三台,一个主库、一个备主库和一个从库,我们需要进行部署、扩容和备份。
上图中的拆分主要是根据 QPS/TPS 来进行拆分,还有就是一些故障机的下线。
数据链路层,这一层做的功能还是比较强大的,因为好多东西都依赖这一层。
我们是利用了开源的 canal+kafka+zookeeper,对数据重新做哈希,比如我上游可能是根据城市来分表的,那我下游就有可能把多个城市的表聚合起来。
在线辅助系统
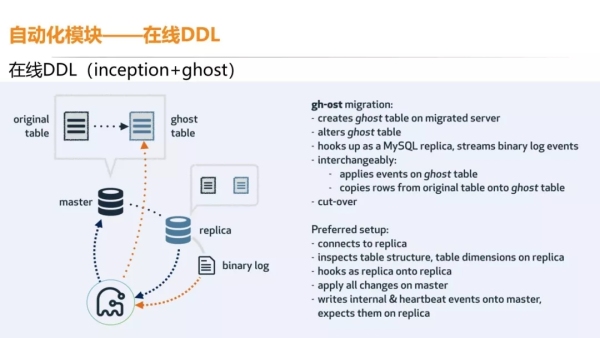
在线辅助系统就是之前说的备份系统、高可用、SQL 审计以及它的优化建议,监控报警、定时任务、数据链路的耗时分析。
定时任务怎么理解?实际应用可能会有一些按天数分表的情况,一般来说,业务肯定不会每天去建一个新表。
所以这些操作都会由定时任务调度来处理,还有一些监控脚本、备份脚本、历史数据删除脚本都会在定时任务里。
数据链路的耗时分析,如果前端要访问数据库,那么需要经过的层比较多,先要通过 dbproxy,再要通过 MySQL,MySQL 回包……
这整个过程中,哪个过程是最耗时的?我们会绘制一个整个过程的时间序列图,这样就可以一目了然的看出哪里耗时最严重。
自动化运维系统

自动化运维系统的调度层我们是基于 Python 和 tornado,底层执行是采用 saltstack。

上面这张图片有 tornado 和 saltstack 的官网链接,大家可以参考。
在线 DDL

下面我再讲几个案例。根据架构,我们首先要去细分需要做哪些东西?分析完之后,我们还需要从中挑选出更为重要的模块,例如占用工时较久的部署,优先自动化。
在线 DDL 是一个比较重要的模块,它的业务峰值是比较集中的,有可能一个表是非常大的,你想避开高峰期,例如想在晚 10 点到早 8 点做完,但是有可能是做不完的。
时间跨度大一直是在线 DDL 的一个痛点,而且有些大表的业务修改是很敏感的。
在线 DDL 的一般逻辑就是先创建一个空表,修改空表的表结构,把历史数据和增量数据同步到新表中,最后一步就是 rename table,对新表和旧表做一次交换。
我们之前数据量不是很大的时候使用的是 pt。pt 的话,历史数据一般是通过 INSERT LOW_PRIORITY IGNORE INTO ,而增量数据是通过 trigger 来做的。
但是这种方法会有个问题,你对原表的操作都会通过触发器来触发一个相应的操作,它对于 QPS 来说是双倍的,而且是同时。
例如你在对一个表访问,它上面 100 多个 TPS,对于业务来说,正常情况可能是 100 毫秒或者是几毫秒的耗时,但你在修改这个的时候,耗时会很长,甚至有可能会访问不成功。
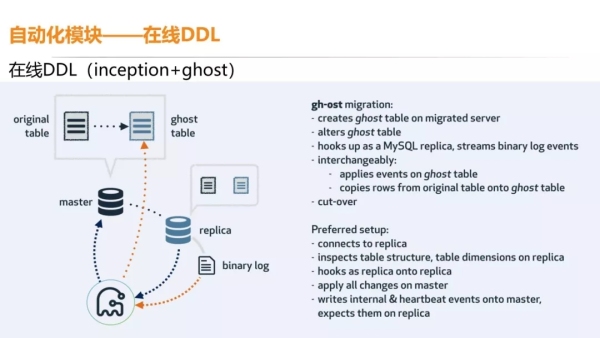
后来,我们经过调研就选择了 inception+ghost,没有触发器。
它的原理是先去建一个新表,对新表进行表结构的修改,再去解析一个从库对旧表操作的 binlog 来回放增量数据的处理。
原有的老数据也是通过单个 chunk 的方式复制到新表中,新数据通过回放从库对旧表的操作 binlog 来回写到新表中。
所以对于主库的压力比较低,主库上旧表和新表的写入也是异步的,避免了触发器同步执行的弊端,比如新加一个字段或者修改字段的类型。
当然它也是有版本迭代的,大家可以根据自己的需求来进行修改。
Saltstack实例
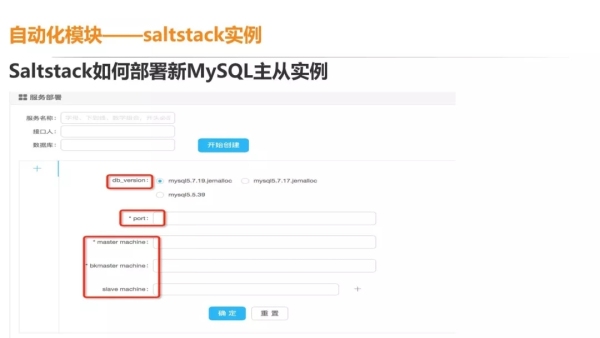
这个是前面提到的 saltstack 实例,如何通知底层来做相关的新建任务?其实就是通过 saltstack 来去调用底层执行。
假设我现在要新建一个 MySQL 的主从实例,最上面是服务名称,这个服务名称一般都是以用途来命名。
接下来是选择版本和 port,还要选择主库、备主库、从库,如果你的 QPS 非常高,那三台机器是不够的,需要增加几台,直接加在后面就可以了。
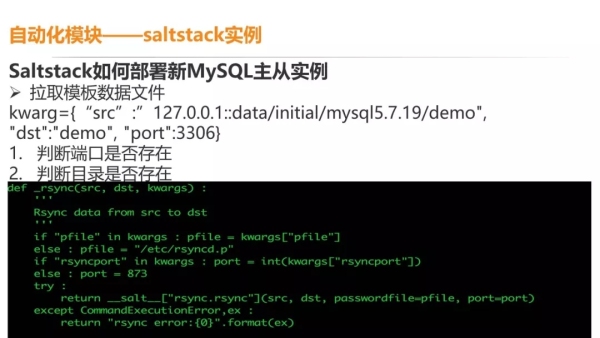
针对 MySQL 的新建,我们会有一个模板一样的数据文件,其中已经包含了 MHA 所需要的用户信息,类似于连接信息、授权等等都会在这个 Demo 的文件里。
新建 MySQL,相当于我先去拷一个模板文件,调用接口,新建端口,这个端口一般来说是多实例的。
dst 一般是根据你申请的数据库或者服务名来定义目标机器的目录名称。传进来之后,就要判断机器上这个端口是否存在。
如果存在的话,是不可以再新建一个同样的端口;如果不存在的话,我们下一步就是判断目录是否存在。
这里需要强调的一点是,salt 是一步一步开始执行的,一旦哪个步骤出现错误,那就是直接失败,不再接着往下继续了。

原数据的 Demo 数据文件建好了,下一步就是建立模板的配置文件。配置文件和数据文件有很多相似之处,都是先去判断端口是否存在,数据文件目录是否存在,然后创建目录。
salt 其实在系统里面内置了很多命令可供用户调用,最后判断 MySQL 版本来拉取模板配置文件。

因为模板配置文件是通用的,所以下一步就是修改配置文件,比如 port 信息,datadir、binlogdir 等等。
这个部分也是一个 salt 模块,就是把模板文件中的 port 替换成你传进来的 port。

下一步就是启动 MySQL,数据文件拉取过来了,配置文件修改完成了,直接去启动 MySQL 就可以了。
启动之后,因为你建立的是一个主从复制关系的集群,假设现在建立了三个实例,而复制关系还没有配置,这个地方就相当于传一些参数来配置复制关系的。
以上是 MySQL 新建的过程,dbproxy 的新建过程大致也是差不多的。一般都会做 Demo 的东西拉取过来,之后修改配置文件,再去启动。
后续补充项

MySQL、dbproxy 和 MHA 的搭建备份都已经实现自动化了,但是我们现在还有一些东西没有实现自动化,例如以下几点:
- 资源管理和分配,申请一个实例,资源池中的机器如何选择还没有自动化。
- VIP 自动分配,其实在我司是运维来做的,VIP 是绑定在后端 dbproxy 机器上的,没有自动化的原因是因为我们不太好推动。
- 细粒度的监控报警,服务器的动态或者数据库的连接信息或者状态,你是可以看到的。但是如果线上新上线了一个东西,但是库里还没有新加字段。
如果是不重要的模块,可能直接跑一个脚本。我们希望做到 dbproxy 层的报警都可以直接发给集群的创建者。
- 慢查分析,优化建议,现在我们有搜集慢查分析的相关信息,但是没有做到自动化的页面上去。

朱进卓,滴滴资深 DBA,主要负责专车、快车等核心业务线数据库维护,数据库架构设计、优化、高可用维护,滴滴内部自动化平台 RDS 部分模块开发。先后就职于搜狐畅游和金山,技术涉猎 MySQL 、Redis、MongoDB、OpenStack、Python、Go。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

