François Chollet 谈深度学习的局限性和未来 - 下篇

雷锋网 AI 科技评论按:本篇是 Keras 作者 François Chollet 撰写的一篇博客,文中作者结合自己丰富的开发经验分享一些自己对深度学习未来发展方向的洞见。另外本篇也是一个关于深度学习局限性及其未来的两篇系列文章之二。你可以在这里找到另一篇文章—— 《François Chollet 谈深度学习的局限性和未来 - 上篇》 。雷锋网 (公众号:雷锋网) AI 科技评论根据原文进行了编译。
鉴于我们所了解到的深度神经网络的工作机制、局限性以及当前的研究状况,我们是否可以预见到神经网络在中期之内将如何发展呢?这里分享一些我的个人想法。请注意我并没有能预测未来的水晶球,所以我所做的大部分预测可能都将失败。这完全就是一篇预测性的帖子,我之所以分享这些推测并不是希望它们在不久的未来会被证明是正确的,而是因为 这些预测在当前看来非常有趣而且具有实践性的 。
总的来说,我预见的几个主要方向是:
-
与通用计算机程序更接近的模型,建立在比我们当前可微分层要丰富得多的基元之上——这也是我们如何 令模型获得推理和抽象的策略 ,而这一点也是当前模型的根本弱点。
-
使上述成为可能的 新式学习策略 ——它可以使得模型摆脱当前的可微分变换。
-
需要更少的人类工程师参与的模型——无休止地调参不应该成为你工作的一部分。
-
对以前学习的特征和架构进行更大和更系统化的复用; 基于可复用和模块化子程序的元学习系统 (Meta-learning systems)。
此外值得注意的是,我的这些思考并不是针对已经成为监督式学习主力的深度学习。恰恰相反,这些思考适用于任何形式的机器学习,包括无监督学习、自我监督学习和强化学习。你的标签来自于哪里以及你的训练循环是什么样的,这些都不重要。这些机器学习的不同分支只是同一构造的不同方面。接下来让我们开始深入探讨。
模型即程序
正如我们在前一篇文章中所提到的,我们在机器学习领域可以预期的一个转变发展是,从纯粹模式识别并且只能实现局部泛化能力(Local generalization,见上篇)的模型,转向能够实现抽象和推理的模型,也就是可以达到终极的泛化能力。 目前人工智能程序能够进行的基本推理形式,都是由人类程序员硬编码的 :例如依靠搜索算法、图形处理和形式逻辑的软件。具体而言,比如在 DeepMind 的 AlphaGo 中,大部分的「智能」都是由专业程序员设计和硬编码的(如蒙特卡洛树搜索),从数据中学习只发生在专门的子模块(价值网络和策略网络)。但是在将来,这样的人工智能系统很可能会被完全学习,而不需要人工进行参与。
有什么办法可以做到这一点?让我们来考虑一个众所周知的网络类型:递归循环神经网络(RNN)。重要的一点是,递归循环神经网络比前馈网络的限制来的少。这是因为递归循环神经网络不仅仅是一种几何变换:它们是在 for 循环内重复应用的几何变换。时序 for 循环本身是由人类开发者硬编码的:它是网络的内置假设。自然地,递归神经网络在它们可以表征的内容上依然非常有限,主要是因为它们执行的每一步仍然只是一个可微分的几何变换,而它们从当前步到下一步传送信息的方式是通过连续几何空间(状态向量)中的点。现在,设想一下神经网络将以类似的方式「编程」,比如 for 循环编程基元,但不仅仅是一个带有硬编码的几何内存硬编码 for 循环,而是一大组编程基元,然后模型可以自由操纵这些基元以扩展它们的处理功能,例如 if 分支、while 循环、变量创建、长期记忆的磁盘存储、排序操作和高级数据结构(如列表、图和散列表等)等等。这样的网络可以表征的程序空间将远远大于当前深度学习模型可以表征的空间,并且其中一些程序甚至可以取得优越的泛化能力。
总而言之,我们将远离「硬编码算法智能」(手工软件),以及「学习几何智能」(深度学习)。我们将拥有 提供推理和抽象能力的形式化算法模块 ,以及 提供非正式直觉和模式识别功能的几何模块 。整个系统只需要很少的人工参与即可完成学习。
我认为人工智能相关的一个子领域可能即将迎来春天,那就是程序合成(Program synthesis),特别是神经程序合成(Neural program synthesis)。程序合成包括通过使用搜索算法(比如在遗传编程中可能是遗传搜索)来自动生成简单的程序,用以探索可能程序的巨大空间。当找到与需求(需求通常以一组输入-输出对进行提供)相匹配的程序时,搜索将停止。正如你所想的,它是否让你想起了机器学习:给出输入-输出对作为「训练数据」,我们找到一个将输入映射到输出的「程序」,并且能将它泛化到其它输入。不同之处在于,我们不是在硬编码程序(神经网络)中学习参数值,而是通过离散搜索过程生成源代码。
我一定会非常期待在接下来的几年内这个子领域会再次迎来第二个春天。特别是,我期待在深度学习和程序合成之间出现一个交叉子领域,在该领域我们不会采用通用语言生成程序,而是增强了一套丰富的算法原语的生成神经网络(几何数据处理流),例如 for 循环等等。这应该比直接生成源代码更加容易处理和有用,它将大大扩展机器学习可以解决的问题范围——我们可以根据适当的训练数据自动生成程序空间。符号 AI(Symbolic AI) 和几何 AI(Geometric AI)的融合,当代递归神经网络可以看做是这种混合算法几何模型的开山鼻祖。
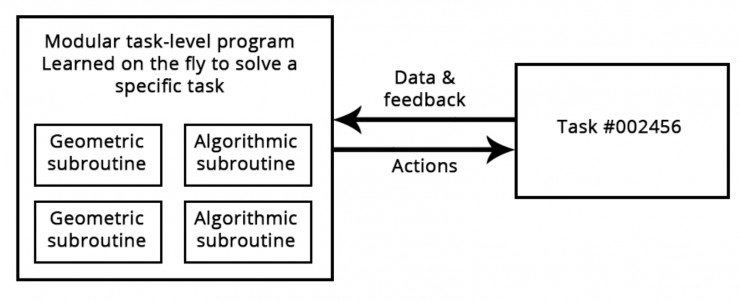
依靠几何基元(模式识别与直觉)和算法基元(推理、搜索和存储)的学习程序
超越反向传播和可微分层
如果机器学习模型变得更像是一段程序,那么它们将变得不再可微——当然这些程序仍然会将连续的几何层作为子程序进行使用,这都是可微的,但是整个模型却不会。因此,在固定的硬编码网络中使用反向传播来调整权重值无法成为将来训练模型的首选办法——至少它无法像现在这样独占鳌头。我们需要找出能有效训练非微分系统的方法。目前的方法包括有遗传算法、进化策略、某些强化学习方法和交替方向乘子法(Alternating direction method of multipliers, ADMM)。自然而然的,梯度下降法哪儿也不会去——梯度信息对于优化可微分参数函数总是有用的。但是我们的模型肯定会比单纯的可微参数函数来的更加强大,因此它们的自主改善(「机器学习」中的「学习」)需要的将不仅仅是反向传播。
此外,反向传播是端到端的学习模式,这对于学习良好的链式转换是一件好事情,但在计算效率上却非常低效,因为它没有充分利用深度神经网络的模块化特性。为了提高效率,有一个通用的策略:引入模块化以及层次结构。 所以我们可以通过引入分离的训练模块以及它们之间的一些同步机制,以分层的方式组织起来,从而使得反向传播计算更加高效 。DeepMind 近期的工作「合成梯度」在某种程度上反映出了这一策略。我预期不久的将来在这一块将有更多的工作开展。
我们可以预见的一个未来就是,这些模型将变得全局不可微分(但将具有局部可微分性),然后通过有效的搜索过程而不是梯度策略进行训练。另一方面,通过利用一些更高效版本的反向传播以发挥梯度下降策略的最大优点,局部可微分区域将得到更快的训练速度。
自动化机器学习
在将来, 模型架构将能够通过学习实现 ,而不是需要由工程师手工设置。并且自动化学习架构与使用更丰富的基元和程序式机器模型(Program-like machine learning models)将结合在一起。
目前深度学习工程师大部分工作都是使用 Python 脚本来处理数据,然后花费很多的时间来调整深度网络的架构和超参数以获得一个还过得去的模型——或者说甚至获得一个性能最先进的模型,如果这个工程师是够雄心勃勃的话。毋庸置疑,这样的做法并非最佳的,但是此时深度学习技术依然可以发挥一定的效用。不过不幸的是,数据处理部分却很难实现自动化,因为它通常需要领域知识以及对工程师想要的效果有非常清晰的高层次理解。然而,超参数调整是一个非常简单的搜索过程,并且我们已经知道了工程师在这种情况下想要取得什么效果:它由正在被微调的网络的损失函数定义。设置基本的「AutoML」系统已经很常见了,它将负责大部分模型的调整。我甚至在几年前设置了自己的模型并赢得了 Kaggle 竞赛。
在最基本的层面上,这样的系统可以简单地调整栈中堆叠的层数、顺序以及每一层中的单元或者说滤波器的数量。这通常是通过类似于 Hyperopt 这样的库来完成的,我们在《Deep Learning with Python》的第 7 章中曾讨论过这点。但我们的志向可以更加远大,并尝试从零开始学习适当的架构,然后尽可能减少限制条件。这可以通过强化学习或者遗传算法来实现。
另一个重要的 AutoML 方向是与 模型权重一起联合学习模型架构 。由于从头开始训练一个全新的架构,并且还要在每次尝试中对架构进行微调是非常耗时和低效的,所以一个真正强大的 AutoML 系统可以在通过 训练数据反向调整模型特征的同时设法改进体系结构 ,从而消除所有的计算冗余。当我正在撰写这些内容时,这些方法已经开始出现了。
当这种情况发生时,机器学习工程师的工作不会消失,恰恰相反,工程师将在价值创造链上走上高地。他们将开始投入更多精力来打造真正反映业务目标的复杂损失函数,并深入理解他们的模型如何影响他们所部署的数字生态系统(例如,负责消费模型预测结果以及产生模型训练数据的用户),而这些问题目前只有巨头公司才有暇顾及。
终生学习和模块化子程序复用
如果模型变得越来越复杂并且建立在更丰富的算法基元之上,那么这种增加的复杂度将需要在不同任务之间实现更好地复用性,而不是每当我们有了新任务或者新数据集之后还需要从头开始训练新模型。事实上,许多数据集都因为数据量不够大而不足以支持从头训练新的复杂模型,并且需要利用来自先前数据集中的信息。就像你不需要在每次打开一本新书时都重新学习一遍英语一样。此外,由于当前任务与以前遇到的任务之间可能存在大量的重叠,因此对每个新任务都从头开始训练模型的做法非常低效。
此外,近年来反复出现的一个显著的观测结果是,训练相同的模型以同时执行几个松散连接的任务,将产生一个对每个任务都更好的模型。例如,训练相同的神经机器翻译模型以覆盖从英语到德语、法语到意大利语的翻译,将得到一个比单独训练来得更好的模型。又比如与图像分割模型一起训练图像分类模型,共享相同的卷积核,从而产生一个在两项任务中都表现更好的模型,等等。这一点非常直观:这些看起来似乎不相关的任务之间总是存在着信息重叠,因此联合训练模型比起只在某一特定任务上训练的模型,可以获取与每项单独任务有关的大量信息。
我们目前沿着跨任务模型复用(Model reuse across tasks)的方向所做的工作就是,利用预训练权重模型来处理常见任务,例如视觉特征提取。你将在第 5 章看到这一点。在将来,我希望这种泛化能力能实现更佳的普适性:我们不仅会复用以前学过的特征(子模型的权重值),还会复用模型架构和训练过程。随着模型变得越来越像程序,我们将开始重用程序子程序(Program subroutines),比如人类编程语言中的函数和类。
想想今天软件开发的过程:一旦工程师解决了一个特定的问题(例如 Python 中的 HTTP 请求问题),他们会将其打包为一个抽象且可以重用的库。这样未来面临类似问题的工程师可以通过简单地搜索现有的库,然后下载并在项目中使用它来解决问题。相类似地,在未来元学习(Meta-learning)系统将可以通过筛选高级可重用块的全局库来组装全新的程序。当系统发现自己为几个不同任务开发了类似的程序子程序时,如果能够具备「抽象」的能力,即子程序的可重用版本,然后就将其存储到全局库种。这样的过程将实现抽象的能力,这是实现「终极泛化」的必要组成部分:在不同任务和领域发现有用的子程序可以被认为「抽象」了一些问题解决方案的某些方面。这里「抽象」的定义与软件工程中的抽象概念相似。这些子程序可以是几何的(具有预训练表征的深度学习模块)也可以是算法的(更接近当代软件工程师使用的软件库)。
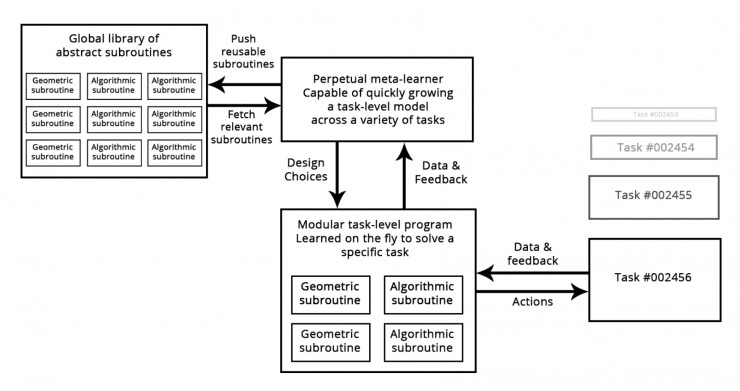
元学习器能够使用可复用基元(算法和几何)快速开发针对特定任务的模型,从而实现“极端泛化”。
总结:洞见未来
总而言之,这里是一些我对机器学习长期发展的洞见:
-
模型将更加像程序,并且将具有远远超出我们目前使用的输入数据的连续几何变换的能力。这些 程序可以说更接近人类对周围环境和自身抽象的心理模型 ,并且由于其丰富的算法性质,它们将具有更强的泛化能力。
-
特别是,模型将 融合算法模块和几何模块 ,算法模块可以提供正式推理、搜索和抽象能力,而几何模块可以提供非正式的直觉和模式识别功能。AlphaGo(一个需要大量手动软件工程和人为设计决策的系统)提供了一个早期的例子,它展示了当符号 AI 和几何 AI 融合之后将是什么样子。
-
通过使用存储在可复用子程序全局库(这是一个通过在数以万计的以前的任务和数据集上学习的高性能模型演变而来的库)中的模块部件,它们将实现自动成长,而不是由人类工程师手工设定。由于元学习系统确定了常见的问题解决模式,它们将变成一个可复用的子程序——就像当代软件工程中的函数和类一样——并添加到全局库中,从而实现了抽象能力。
-
这个全局库和相关联的模型成长系统(Model-growing system)将能够在某种形式上实现类人的「极限泛化」:给定一个新任务、新情况,系统将能够组装一个适用于新任务的全新工作模型,而只需要很少的数据。这要归功于 1) 丰富的具有强泛化能力的类程序基元(Program-like primitives);2) 具有相似任务的丰富经验。就像人类可以花费很少的时间玩好一个全新复杂的视频游戏一样,因为他们有许多以前的游戏经验,并且因为从以前经验得出的模型是抽象和类程序的,而不是刺激和行为之间的基本映射。
-
因此,这种永 久学习模型成长系统(Perpetually-learning model-growing system)可以被称为通用人工智能(Artificial General Intelligence, AGI) 。但是不要担忧任何机器人启示录将会降临:因为这单纯只是一个幻想,它来自于人们对智能和技术的一系列深刻误解。然而,对这方面的批评并不在本篇的讨论范畴之内。
Via keras.io ,雷锋网 AI 科技评论编译。
雷锋网原创文章,未经授权禁止转载。详情见 转载须知 。

正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

