Java杂记1—数据类型和变量
在说变量之前,我们先来说一下数据是什么?变量和数据是分不开的。
数据在计算机中实际上就是二进制,0101010101。这些二进制实际上是不方便操作的,也不方便管理,哪个人能够直接识别二进制串?
没有吧。所以为了方便管理和操作,在几乎所有的高级语言中都引入了数据类型和变量的概念。
数据类型
知道了什么是数据,那么数据类型就好解释了,数据类型实际上就是用于对数据归类的,方便理解和操作。
数据在计算机内部都是二进制,二进制程序员很难直接理解和操作啊,对于整数使用 int/long,对于小数使用 float/double, 对于字符串使用 String,使用这些数据类型和类,程序员理解和操作起来就方便多了
通过数据类型定义为数据进行分类之后,计算机就可以规范的为不同的数据类型分配不同大小的内存空间。
数据类型的作用
- 类型检查提高安全性
- 合理的内存分配
例如java中就有八种基本数据类型
- 整数类型: byte/short/int/long
- 小数类型 :float/double
- 字符类型:char
- 布尔类型:boolean
就像世界万物都是由元素周期表中的108个基本元素组成的,基本数据类型就相当于化学中的基本元素,而对象就相当于世界万物,String就是char组成的,日期类型就是long。
浮点数
浮点类型介绍
long类型转换成float类型是不需要强制类型转换的,也就是说相对于flaot类型,long类型是小类型,存储的范围要更小。然而flaot只占了4个字节,而long却占了8个字节,long类型的存储空间要比float类型大。
浮点数使用 IEEE(电气和电子工程师协会)格式。 浮点数类型使用 符号位、指数、有效位数(尾数)来表示。
在java中,float 和 double 的结构如下:
类型|符号位|指数域|有效位域
-|-|-
float|1位|8位|23位
double|1位|11位|52位
浮点数的精度问题
-
存储的小数数值可能是模糊值
为什么这么说呢?看下面的代码
public static void main(String[] args) { double d1 = 0.1; double d2 = 0.2; System.out.println(d1+d2 == 0.3); System.out.println(d1+d2); }上述代码的运行结果是false 0.30000000000000004
也就是double类型的0.1加上0.2 并不是精确的0.3,需要注意的是出现这样的结果不是因为运算错误,而是二进制无法精确的表示十进制的0.3。就像十进制的3/10无法用小数精准表示一样,很多小数都无法准确的用浮点型表示。
小数的十进制转成二进制,十进制的小数要不断乘2,直到最后的结果为整数才是最终的二进制值,但有可能最后的结果是一个无限值,浮点型就无法表示了。
但是对于 整数 来说,在浮点数的有效范围内,则都是精确的。转换算法:十进制的整数转成二进制的算法是不断对2求余数,不会存在无限值的情况。
-
浮点数的有效位及精度
浮点型所能表示的有效位是有限的,所以哪怕是整数只要超出有效位数,也只能存近似值,也就是超出最低有效位的数据将会丢失,从而造精度丢失。 float类型的二进制有效位是24位,对应十进制的7 ~ 8位数字;double类型的二进制53位,对应十进制的10 ~ 11位数字。
double、float类型 所能表示的范围比int、long类型表示的范围要广。但是不能完美的表示整型,浮点类型的精度丢失会造成一些问题。
public static void main(String[] args) { int a = 3000000; int b = 30000000; float f1 = a; float f2 = b; System.out.println("3000000==3000001 "+(f1==f1+1)); System.out.println("30000000==30000001 "+(f2==f2+1)); System.out.println("3000000的有效二进制位数:"+ Integer.toBinaryString(a).length()); System.out.println("30000000的有效二进制位数:"+ Integer.toBinaryString(b).length()); }运行结果:
3000000 == 3000001 false 30000000 == 30000001 true 3000000的有效二进制位数: 22 30000000的有效二进制位数: 25
上面的例子很好体现了精度丢失所带来的后果:
30000000==30000001的比较居然为true了。而造成这种结果的原因就是 30000000的有效二进制位数是25位,超出了float所能表示的有效位24位,最后一位就被舍去,所以就造成在刚加的1也被舍去,因此30000000的加一操作前后的浮点型表示是一样的。如果上面的例子中的浮点型用double就不会丢失精度,因为double的精度是52位。
-
如何解决浮点数精度丢失问题
JDK为此提供了两个高精度的大数操作类给我们:BigInteger、BigDecimal。
Char类型
char用于表示一个字符,这个字符可以是中文字符,也可以是英文字符。赋值时把常量字符用单引号括起来。
我们知道在java内部处理字符时,采用的都是Unicode。char本质上是一个固定占用两个字节的无符号正整数,这个正整数对应于Unicode编号,用于表示那个Unicode编号对应的字符。由于固定占用两个字节,char只能表示Unicode编号在65536以内的字符,而不能表示超出范围的字符。对于超出这个范围的会使用使用两个char。
char的赋值
//Ascii码 char c = 'A' //中文字符 char c = '哈' // 十进制 Unicode编号 char c = 39532 // 16进制 Unicode编号 char c = 0x9a6c //Unicode字符形式 char c = '/u9a6c'
char的运算
由于char本质上是一个整数,所以可以进行整数可以进行的一些运算,在进行运算时会被看做int,但由于char占两个字节,运算结果不能直接赋值给char类型,需要进行强制类型转换,这和byte, short参与整数运算是类似的。
char类型的比较就是其Unicode编号的比较。
char的加减运算就是按其Unicode编号进行运算,一般对字符做加减运算没什么意义,但Ascii码字符是有意义的。比如大小写转换,大写A-Z的编号是 65-90,小写a-z的编号是97-122,正好相差32,所以大写转小写只需加32,而小写转大写只需减32。加减运算的另一个应用是加密和解密,将 字符进行某种可逆的数学运算可以做加解密。
变量
内存中保存数据的一块区域。
为了操作数据,我们需要把数据放入内存中,数据在磁盘中是没有办法直接操作的,需要先读取到内存中,才能够进行直接的操作。而内存在计算机中实际上就是一块儿有地址编号的连续空间,在我们把数据放入内存中某个位置之后,为了方便找到和操作这个数据,需要给这个位置起一个名字,这个过程就是通过变量声明和赋值来表示的。
在现实生活中,硅谷广场有自己的地址编号,文化路86号(内存地址编号),但是同时也有自己的名字(变量名)
换句话说,所谓变量,你可以把它看做一个容器,可以用来承载一些东西,什么意思呢?你的基本类型的值,对象类型的引用都可以放入变量中,这个过程被称之为变量的赋值。之所以叫变量,是因为它表示的是内存中的位置,这个位置存放的值是可以变化的。
虽然变量的值是可以变化的,但名字是不变的,这个名字应该代表程序员心目中这块内存位置的意义,这个意义应该是不变的,比如说这个变量int second表示时钟秒数,在不同时间可以被赋予不同的值,但它表示的就是时钟秒数。之所以说应该是因为这不是必须的,如果你非要起一个变量名叫age但赋予它身高的值,计算机也拿你没办法。
变量就是给数据起名字,方便找不同的数据,它的值可以变,但含义不应变
变量的操作分为两个部分,变量的声明和变量的引用。
变量的声明,必须有变量的类型和变量名
通过声明变量,每个变量赋予一个数据类型和一个有意义的名字
声明变量之后,就在内存分配了一块位置,但这个位置的内容是未知的,赋值就是把这块位置的内容设为一个确定的值。
变量的赋值,使用赋值运算符=
赋值形式很简单,直接把熟悉的数字常量形式赋值给变量即可,对应的内存空间的值就从未知变成了确定的常量。但常量不能超过对应类型的表示范围
同时我们可以通过生活中的一些小案例来进一步形象化的说明变量:
变量就像是一个杯子,可以容纳一些东西。
而杯子,有不同的大小和类型,对应在java中就是int short等他们的大小不一样,可以放置的数据也是不一样的。
变量的分类
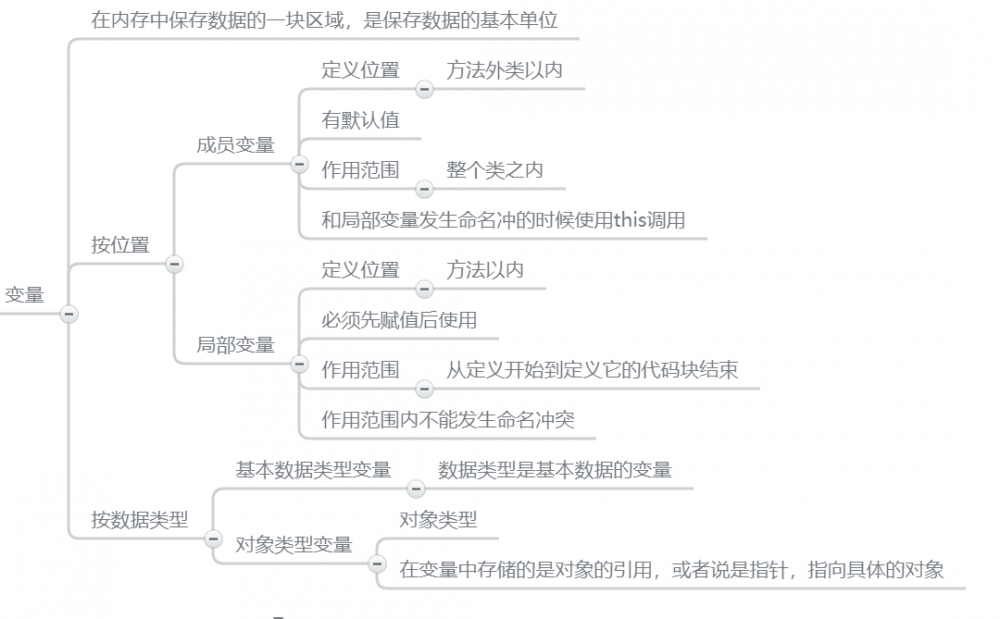
需要进行解释的就是对象类型,在java中实际上是没有对象变量的,因为数据并没有放在变量中,放的是引用。也就是在对象类型的变量这个杯子中放置的是对象的引用(地址), 引用就像是一个遥控器 。
整个逻辑是,变量中放引用,引用指向对象数据。
我不能保证每一个地方都是对的,但是可以保证每一句话,每一行代码都是经过推敲和斟酌的。希望每一篇文章背后都是自己追求纯粹技术人生的态度。
永远相信美好的事情即将发生。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

