DockOne微信分享(一七〇):贝壳找房权限服务的探索和实践
【编者的话】认证授权,作为服务的重要组成部分之一,在微服务/平台化的背景下,迎来了新的挑战。庞杂的业务应用 vs 精深的中台服务,在权限模型上有何异同?又该如何分而治之,且自洽呢?在链家网向贝壳找房平台化的进程中,我们分别生产了”面向服务“和”面向用户“两套权限服务,试图打造一个立体的权限系统。
听了很多场Kubernetes的分享,深感大家贴近时代的潮流。今晚我抛砖引玉,来聊聊plain boring的权限系统,看看能不能唤醒大家那些good old days:)
贝壳找房是基于原有链家网的技术能力,新推出的房产平台服务。我们作为贝壳找房的基础技术团队,为业务系统提供了多个服务,比如用户中心,存储服务,图片服务,400号码服务等等。在对接各业务系统过程中,都面临着同样的问题:
- 身份标识:明确身份,我们才有能更精确而且有效地实现限流,融断,配额等功能;
- 权限分配:权限控制是大多数业务发展到一定阶段都需要面临的问题,如何确保不同业务的资源隔离,并实现细粒度的控制权限?
在单个服务中,这些问题看似简单,在多个服务特别是微服务架构下被放大了。
我们期望有这么一套系统,它能提供了统一的身份标识,进而提供可靠的认证机制,进而提供自助的权限管理。我们可以把密钥管理,接口签名,权限分发等等一系列问题抛之脑后,专注于自身服务。
刚好,我们当时使用着AWS的基础服务,有一定的AWS IAM使用经验。IAM的模型,十分契合我们的想法(或者说,我们已经被先入为主了)。但遗憾的是,IAM作为云服务的基础设施,是不对外提供服务的。
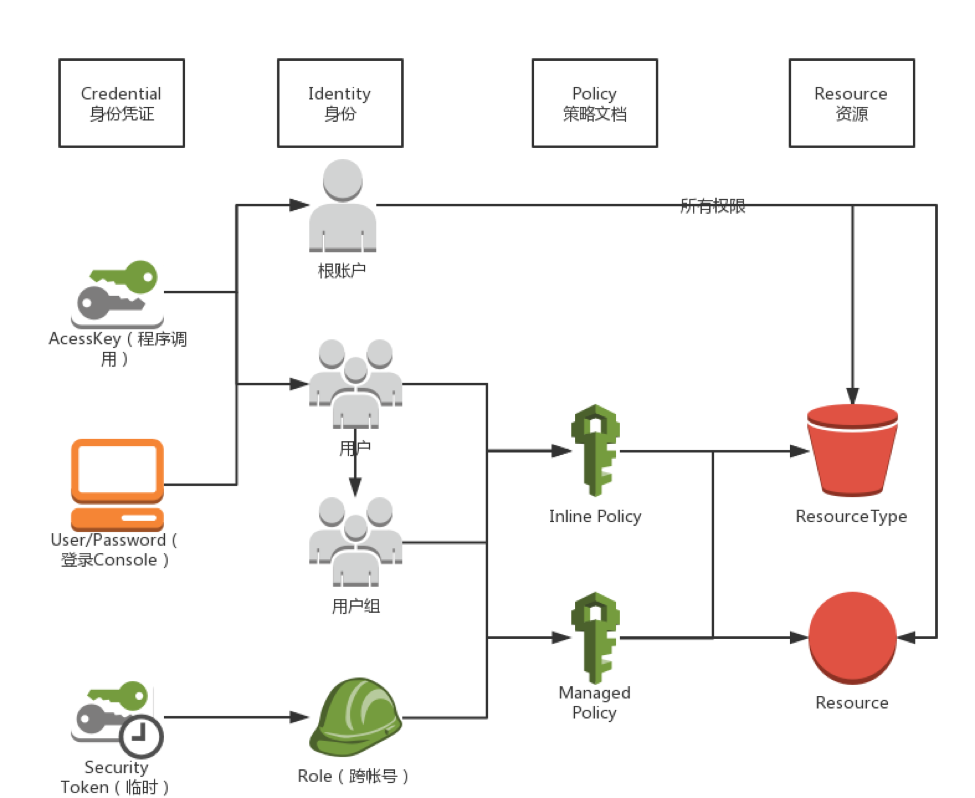
上图是AWS IAM一个简单的系统分解。对于不熟悉IAM的同学,可前往 https://docs.aws.amazon.com/zh ... .html 自行了解。
一开始,我们是强烈避免重复造轮子的,我们将目光转向了OpenStack的keystone,尝试二次开发。但经过短暂的调研后发现,keystone是一个传统的RBAC权限模型;每个服务维护着自己的policy.json,配置无法产品化;维护Token,给无状态的服务带来了负担。我们考虑到适配和理解层面上的阻抗,加之一定无法合并到上游的命运,无奈下放弃了这个方案。在没有合适的候选方案下,我们做了心理建设,开始了自研的工作。
自研IAM比较好的情况是,在AWS IAM,阿里云RAM,腾讯云CAM等体系教育下,整个客户端的行为已经十分明确,服务端的业务行为基本能被倒推出来。唯一无从知晓的,是服务端的架构方式。
理想情况下,我认为性能最优的一个方案是:所有服务以一种语言实现,IAM的功能作为SDK的方式集成在服务之中,SDK依赖弹性伸缩的数据服务,辅以上层负载均衡依照AK将请求路由到不同的分区,以期保证性能的同时,达到更高的灵活度。
然而,我们根据我司的现实情况,做了一些不一样的决策:
由于我司开发语言以Java和PHP为首,我们需要以接口的形式提供多语言的支持。
由于我们无法把控服务实现的质量,我们决定:服务无法拿到使用方的Secrect Key。这会导致认证和授权的捆绑,势必不是最优解,但是我们能确保安全。
考虑到请求到服务,服务转到IAM做鉴权的场景,我们认为跨服务的鉴权也是不合理的,故对鉴权请求也做了AK/SK加密:只有服务对应的IAM主体才能操作对应服务资源,实现了自举。
最终的流程图:
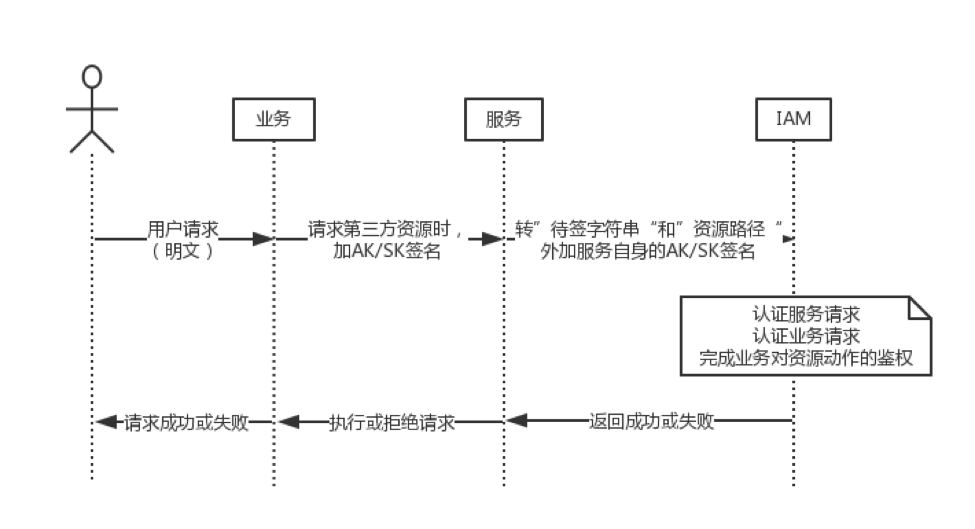
我们选择了Golang来实现IAM。服务到IAM的请求使用的是gRPC,通过grpc-gateway添加了HTTP接口的支持,方便测试。
由于Policy天生的复杂度,我们在落地MySQL的同时,按用户和服务为最小粒度,以protobuf的形式全量保存在Redis,然后拉取到BigCache做内存缓存。最终在m3.2xlarge的机器上,QPS可达到 1W+,Latency控制在2ms之内。由于避免了额外IO,再加之每个请求2次加解密的需求,和Resource基于字符串的匹配,导致CPU成为瓶颈。
由于考虑到了后续可能会开源,我们对RMDB,集中缓存,事件通知等外部依赖都使用了interface,做成了可插拔的组件。(如果群里有专利方面的大拿,还请不吝赐教,能否开源)
提个用户体验的小case,大家知道,由于权限系统会大量使用缓存,时效性一般不做严格保证。我们服务的内存级缓存,最初设置成了5分钟。在用户使用时,这5分钟的缓存,也造成了很大的干扰。我们发现,用户改完后,都会亲自测试下;等5分钟后再试,使用体验是反人类的。所以,我们认为对于权限系统来说,时效性应该是秒级。我们加上基于Redis的事件通知机制后,基于控制台的使用体验一下子就好转了。
在服务端接入的时候,造成很大困扰的是,IAM对Body的加签设定。大家知道,基本上所有语言,HTTP Request Body都是流式设计,这意味着服务在做验签之前,要消费掉body,同时feed到sha256等hash算法内。这样的话,业务逻辑和验签逻辑交织在一起,造成了耦合。我们萌发了自己定义加签规范的念头,将这个需求拆解成两步:带body的请求带content-md5头,IAM验证头信息,服务可选验证content-md5. 这就演化成了我们统一API签名的项目,具体就不展开了。
当服务方接入IAM,常常需要一个思路上的转化:服务方自己其实不是资源的拥有者!在IAM体系中,资源的拥有者是首次申请资源的根帐号,根帐号再将权限切割出来分配给子用户。服务方仅提供服务能力,在控制台内不能对资源做任何管控,管控是由业务方自主完成的!
可以说,IAM很好的达到了我们对它的预期。但对服务来说,天生多租户/平台化的要求,导致了IAM推广落地的难度,我们急需一个落地媒介,这就是服务目录。
服务目录作为链家网基础服务部孵化的内部项目,类似云服务WebConsole的统一入口,旨在降低沟通成本,提高使用体验。
服务目录提供了一个基于React的前端框架,和一个基于NodeJS的大前端,内嵌了多个服务面板。
每个服务面板可自行打包,独立内嵌,互不干扰。
服务目录以IAM系统做身份认证,提供了统一的应用到服务间签名SDK,以及服务端到IAM间SDK。
由于服务目录有代理用户操作的需求,我们给服务目录的NodeJS大前端颁发了一个Super AK,由此AK发起的请求完全受信,做到了和IAM服务的打通。
我们期待服务目录能够盘活整个中台服务体系,乃至有需求的业务应用,使服务逐步平台化,产品化。
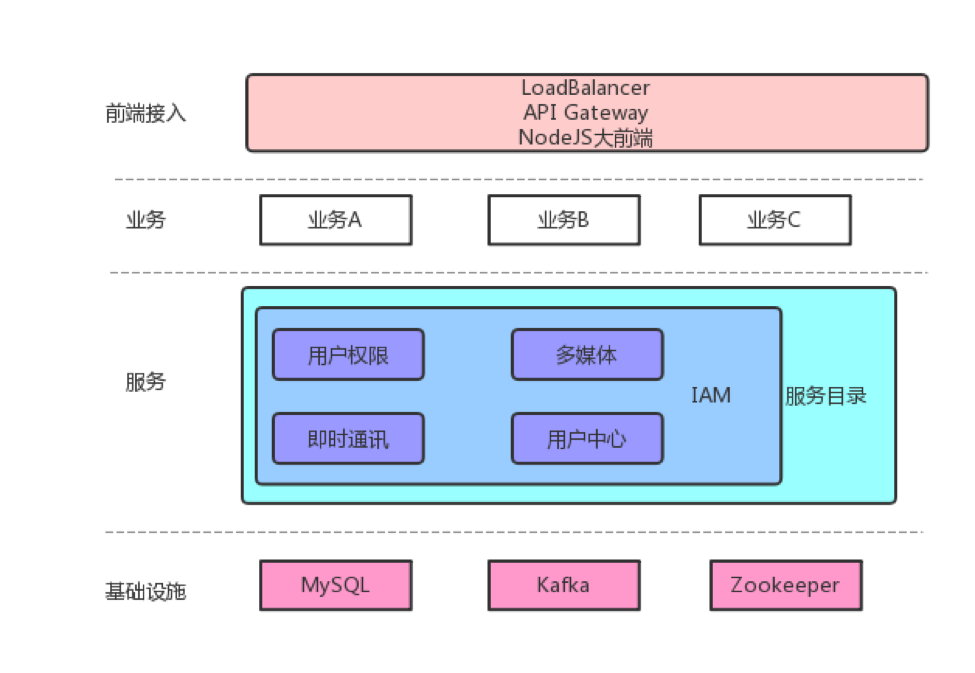
上图是我们预期的整体架构。业务层负责对接具体的业务,其他所有层为其赋能;服务层提供业务无关的通用能力,但不直接参与到具体的业务实现;基础设施层提供稳定可靠的存储/计算等能力。业务到服务间通过IAM授权,用户通过服务目录管理资源。所有层都具有监控报警等基础能力。
聊完业务和服务之间的权限管控,我们来聊聊用户和业务之间的权限管理。
大家可能认为,这不是集成个Shiro生成几张数据库表的事儿吗?诚然,这样的确能满足需求。
但是,当业务扩大到成百上千个,每个业务都去做权限系统的CRUD及其对应的后台页面时,这就产生了巨大的浪费。如果再加上审批审计,批量导入导出,业务层控件开发等等一系列功能呢?再加上PM/运营人员的学习使用成本呢?
所以,统一的业务层用户权限体系仍然是有很大价值的。但如何做到能够灵活地支持多个业务方?在业务方有需求的时候,能快速的响应,或者指导业务方自身完成,对我们来说,仍然是一个巨大的挑战。
很有趣的是,在刚刚做完IAM主体开发后,我们立马拿到了一个新的项目:重构用户中心权限服务。
我想每个互联网公司都有一套自己的用户中心,链家网的用户中心是由用户信息,单点登陆,及权限系统三部分组成。权限系统发源于B端业务,初期很好地满足了业务需求,但随着业务的发展,新功能的添加,慢慢凸显出一些矛盾:
- 权限和用户中心的代码,同一仓库,耦合性高,缺乏独立上线的能力。
- 用户中心支持内网外用户,而权限系统只支持内网用户。
- 权限系统的多租户支持是以每个table添加appid column实现的;租户间容易相互干扰,容易造成数据的不一致。
- 基于RMDB的API没有做上层封装,使用复杂;权限信息拉取,需要三个请求,导致性能低下。
- 时效性低:人员变动引起的权限变化,得等到每晚凌晨跑批处理;角色的生效,也得手动跑批。
- 传统页面应用,没有写入接口。
- 数据安全问题,没有坚持最小安全原则
稍微铺垫一下,跟IAM系统截然相反,用户权限系统,是基于RBAC权限模型。
之前的同学在权限点的维度上,创造性地附加了“约束”的概念。“约束”是一个KV的结构,描述了权限点(功能权限)对应的数据范围。
使用方式为:业务接入方,在用户登陆后,向我们拉取权限信息,缓存在本地;之后所有的操作,即可通过角色信息,权限点列表,和权限对应的数据约束,解释出yes or no的结果。
所以,分析下来,“用户权限系统”实际上是一个垂直领域的,支持多租户的CMS系统。
在用户权限系统中,约束是权限点的扩展,那角色的扩展呢?用户的扩展呢?
于是,我们新加入了几个扩展点,方便业务各个维度的自定义需求:
- Property属性 作为角色的扩展,属性有预定义的相关类型:如单选枚举,多选枚举,组织树,自定义等等。租户内角色属性是一致的,租户间角色属性是多Schema的。
- Extension约束 作为权限点的扩展,约束也支持类型。约束需预先挂接到权限点;角色添加权限点时,约束以对应的控件渲染,同时可附加“不约束”和“为空”两种状态。
- 用户有统一的UCID,但每个业务有不同的用户属性。我们支持多数据源用户的同步,同步来的用户属性归属在数据源名字空间下,其他所有业务均可使用。用户的属性有一个很重要的作用,用来实现基于规则的自动绑定,比如这样的表达式:(user.sex == “M” && user.age > 30) || (user.orgCode contains “1111”) 。
在这里,我想着重提一下”类型“,我认为这是一个很好的设计:它保证了底层数据的独立性,稳定性;在上层以控件形态,指导自然人使用;对应用提供了meta信息,指导SDK解释含义。它将一个个无含义的KV,填充了血肉,贴近了业务。
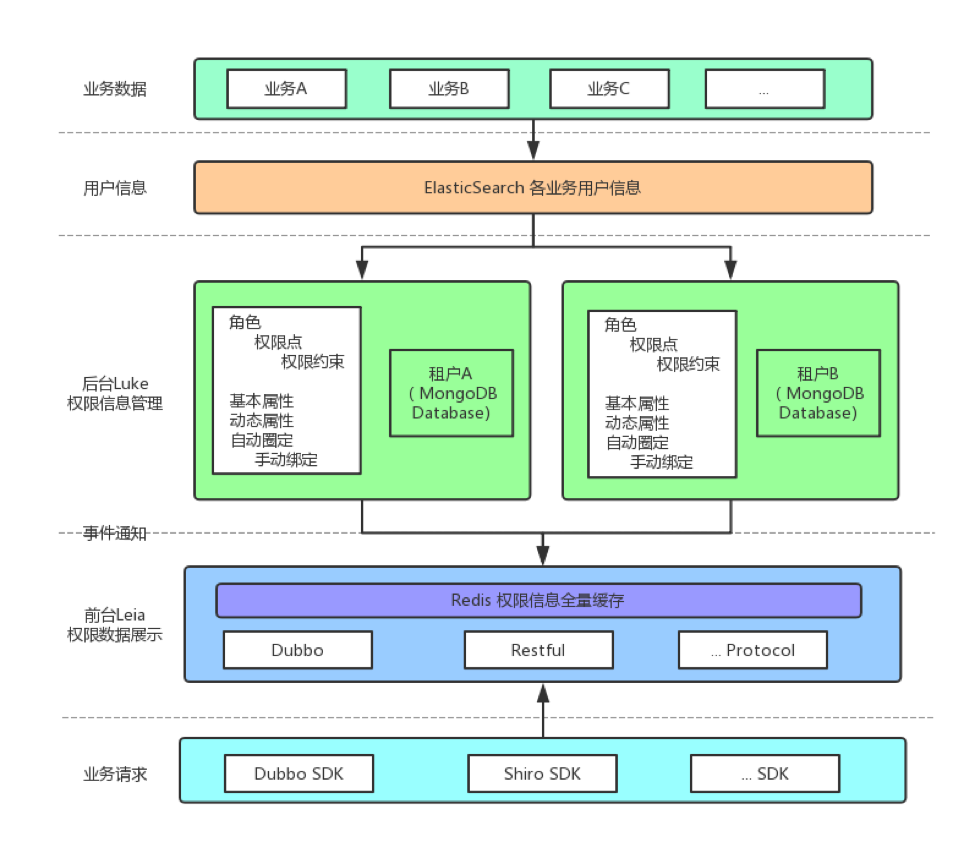
上图是我们用户权限系统的简单架构图。
我们把它实现成了一个DB级别隔离的多租户系统,一个CQRS(读写模型分离)的系统,一个业务端 Multi-Schema的系统。
如上图,后台Luke使用的技术栈是NodeJS (TypeScript) / GraphQL (Apollo + Dataloader) / MongoDB (Mongoose);服务目录的控制台LukePanel的技术栈是ES6 / React / Apollo Client / AntDesign; Luke和LukePanel通过项目Chawbacca公用前后台验证逻辑;前台Leia因为要支持Dubbo,选择了Spring,提供了WebFlux API 和 Dubbo Facade,通过SpEL做权限的实时计算。
从技术选型上可以看出,我们推崇合适的工具做合适的事情。TypeScript和GraphQL都给了我们很大的惊喜,通过Schema Stitch和JSON scalar,我们透明处理了DB隔离和MultiSchema,在保证工程质量的同时,确保了工程进度。
谈到权限的实时生效,我们可以改进之前的定时跑批,做到基于事件流的实时处理。然而,考虑到“潜在用户刷新量大”和“刷新需加锁串行执行”的问题,为保证时效性,我们并没有选择这种方案,而是选择了“首次访问时做实时计算“的实现方式,这样可以筛选出真实用户,事件处理只需要”无脑“清缓存即可,而代价仅是计算支持一定的并发,且延迟不能太大。
比较好玩的是,所有权限系统,第一件客户始终是自己,通过自举,给自己赋能,是一件很有乐趣的事儿。
今晚讲了两个权限体系,希望能给大家一些启发。在实现的过程中,我们收获很多乐趣,我们也希望能把这两个系统真正落地下来,产生应有的价值。希望大家多多指教!
Q&A
Q:请问链家这个业务和服务之间的权限管控,和Kubernetes中的RBAC实现有什么区别呢?
A:Sorry,对Kubernetes的RBAC模式不熟悉,但是我想都是基于同一个权限模型,不会有太大差距。RBAC有RBAC1,2,3,4多个粒度,都是基于最基本的角色/权限的扩充。我刚刚看了下文档,看到了支持用户组Group,resourceNames支持到了Row Based粒度,从功能上应该算完备了吧。
Q:为什么选择Golang作为后端的实现呢?有遇到什么印象深刻的“坑”吗?
A:因为我们team主推的语言是Go:)由于Golang,gRPC,Protobuf都是Google主推的项目,集成的体验还是相当愉悦的。
我们实现的时候,遵循了社区的建议,Library over Framework(比如orm选择了sqlx),没有遇到太多的坑。
有几个小坑可以分享下:
HTTP Content-Length / Host等Header实际上不在Headers对象里,而是作为了request的基础属性,在我们实现签名的时候被坑了一把。
HMac的Hashlib不支持Reset,我们无法放到sync.Pool中。因为加解密重度依赖此模块,我们不得以用type alias + internal包路径hack了一把。
最后还有说好的dep要进官方,结果被Russ的vgo横插了一把,感觉很怨念,又要切工具了。
以上内容根据2018年5月3日晚微信群分享内容整理。 分享人 尹吉峰,链家网基础架构部研发工程师,开源爱好者/参与者,酷爱原型搭建,现负责基础权限服务 。DockOne每周都会组织定向的技术分享,欢迎感兴趣的同学加微信:liyingjiesa,进群参与,您有想听的话题或者想分享的话题都可以给我们留言。
正文到此结束
- 本文标签: ip 进程 UI 需求 组织 Uber http ORM 专注 web 教育 配置 代码 key Amazon 推广 业务层 模型 java 质量 数据库 sql OpenStack json 同步 运营 Property id spring db 房产 安全 Google MongoDB dubbo src scala 服务端 目录 node 密钥 API Kubernetes 开源 lib 用户中心 希望 权限控制 云 tab 负载均衡 保安 管理 HTML 锁 client 1111 IO token mysql 认证 js 产品 redis App 开发 schema ACE 图片 mongo 测试 https 互联网 数据 空间 阿里云 TypeScript 凌晨 cache 工程师 PHP
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

