死磕Java之聊聊LinkedList源码(基于JDK1.8)
工作快一年了,近期打算研究一下JDK的源码,也就因此有了死磕java系列
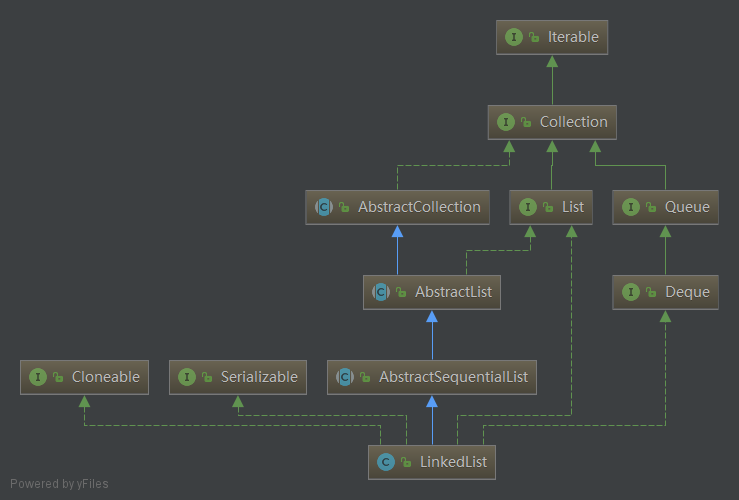
- LinkedList 是一个继承于AbstractSequentialList的双向链表,链表不需要capacity的设定,它也可以被当作堆栈、队列或双端队列进行操作。
- LinkedList 实现 List 接口,能对它进行队列操作,提供了相关的添加、删除、修改、遍历等功能。
- LinkedList 实现 Deque 接口,即能将LinkedList当作双端队列使用。
- LinkedList 实现了Cloneable接口,即覆盖了函数clone(),能克隆。
- LinkedList 实现java.io.Serializable接口,这意味着LinkedList支持序列化,能通过序列化去传输,包括网络传输与本地文件序列化。
- LinkedList 是非同步的,如若要在并发情况下使用建议选取java.util.concurrent包下的集合类型。
LinkedList的UML图
LinkedList的成员变量及其含义
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
transient int size = 0;
/**
* 指向头指针的节点.
* transient关键字扫盲,在实现Serilizable接口后,
* 将不需要序列化的属性前添加关键字transient,
* 序列化对象的时候,这个属性就不会序列化到指定的目的地中
*/
transient Node<E> first;
/**
* 指向尾节点。
*/
transient Node<E> last;
/**
* 构造方法的空实现。
*/
public LinkedList() {
}
/**
* 按照集合迭代器返回的顺序构造包含指定集合元素的列表。
*/
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
/**
* 链表的节点,私有实现。
*/
private static class Node<E> {
E item;
Node<E> next; // 链表的后继节点
Node<E> prev; // 链表的前驱节点
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
}
聊聊LinkedList的主要方法实现
我们主要看研究一下下面的几个方法,LinkedList其他方法都是通过调用这几个方法来实现功能,包括LinkedList的双端队列的方法也是。
/**
* 在链表头部插入元素.
*/
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
/**
* 在链表尾部插入元素.
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
// 链表防止并发下被修改的快速失败策略
modCount++;
}
/**
* 在指定节点前面插入元素.
*/
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
/**
* 移除链表的头部元素.
*/
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC 将元素置为空,让jvm在gc时回收资源
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
/**
* 移除链表的尾部元素.
*/
private E unlinkLast(Node<E> l) {
// assert l == last && l != null;
final E element = l.item;
final Node<E> prev = l.prev;
l.item = null;
l.prev = null; // help GC
last = prev;
if (prev == null)
first = null;
else
prev.next = null;
size--;
modCount++;
return element;
}
/**
* 移除某一个节点元素.
*/
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
/**
* 通过indexOf方法来定位给定的元素,若LinkedList中存在元素则返回该元素对应的index,
* 反之返回-1.
*/
public boolean contains(Object o) {
return indexOf(o) != -1;
}
/**
* 在链表尾部追加元素.
*/
public boolean add(E e) {
linkLast(e);
return true;
}
/**
* 移除链表中的指定元素,分两种情况进行处理,当元素为空时与元素不为空时,时间复杂度为O(n).
*/
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
/**
* 将一个集合的所有元素追加到链表的尾部.
*/
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
/**
* 将指定集合中的所有元素插入到该列表中,从指定位置开始。将当前在该位置的元素(如果有的话)
* 和任何后续元素向右移动(增加它们的索引)。新元素将以指定集合的迭代器返回的顺序出现在列表中。
*/
public boolean addAll(int index, Collection<? extends E> c) {
checkPositionIndex(index);
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0)
return false;
Node<E> pred, succ;
if (index == size) {
succ = null;
pred = last;
} else {
succ = node(index);
pred = succ.prev;
}
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
Node<E> newNode = new Node<>(pred, e, null);
if (pred == null)
first = newNode;
else
pred.next = newNode;
pred = newNode;
}
if (succ == null) {
last = pred;
} else {
pred.next = succ;
succ.prev = pred;
}
size += numNew;
modCount++;
return true;
}
/**
* 清空链表.
*/
public void clear() {
// Clearing all of the links between nodes is "unnecessary", but:
// - helps a generational GC if the discarded nodes inhabit
// more than one generation
// - is sure to free memory even if there is a reachable Iterator
for (Node<E> x = first; x != null; ) {
Node<E> next = x.next;
x.item = null;
x.next = null;
x.prev = null;
x = next;
}
first = last = null;
size = 0;
modCount++;
}
// Positional Access Operations 以下是位置访问操作
/**
* 获取链表中对应索引的节点,时间复杂度为O(n)
*/
public E get(int index) {
// 检查index是否越界
checkElementIndex(index);
return node(index).item;
}
/**
* 更新对应index的元素,并返回旧值,时间复杂度为O(n).
*/
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}
/**
* 在指定索引添加元素,时间复杂度为O(1).
*/
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
/**
* 移除指定索引的元素,时间复杂度为O(1).
*/
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
/**
* 查找指定index位置的元素.
*/
Node<E> node(int index) {
// assert isElementIndex(index);
// 在查找对应index位置的元素的时候,java开发人员做了一层优化
// 当index大于size的一半时从前向后查
// 当index小于size的一半时从后向前查
// 这样的话时间复杂度就变成了index/2
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
// Search Operations
/**
* 查找指定元素的index,从前向后查
*/
public int indexOf(Object o) {
int index = 0;
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
}
/**
* 查找指定元素的index,从后向前查
*/
public int lastIndexOf(Object o) {
int index = size;
if (o == null) {
for (Node<E> x = last; x != null; x = x.prev) {
index--;
if (x.item == null)
return index;
}
} else {
for (Node<E> x = last; x != null; x = x.prev) {
index--;
if (o.equals(x.item))
return index;
}
}
return -1;
}
正文到此结束
热门推荐










相关文章

近期评论
-
已经加上
-
阳光星河 https://www.276227.com
-
-
-
-
I really enjoyed reading your post it was both informative and personal, which I think is the perfect combo. You explained things in a simple way that actually helped me understand better. It didn't feel overwhelming at all. Thanks for taking the time to share your experience. It's posts like these that make a real difference for people who are looking for genuine advice. Keep up the great work! I came across Libya's e-visa option while planning a spontaneous trip. Understanding the Libya tourist visa requirements helped me feel confident before booking. Everything was surprisingly straightforward. Once I arrived, I was amazed by the Roman ruins, local hospitality, and peaceful coastal towns. It felt like stepping into a place that time forgot, in the best way.
-
Interesting post!
-
-
请问站点支持RSS吗,url是什么?解析不到,看了下首页源码里好像也没有。
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

