如何实现分布式锁
一、为什么要使用分布式锁
为了保证一个方法或属性在高并发情况下的同一时间只能被同一个线程执行,在传统单体应用单机部署的情况下,可以使用Java并发处理相关的API(如ReentrantLock或Synchronized)进行互斥控制。在单机环境中,Java中提供了很多并发处理相关的API。但是,随着业务发展的需要,原单体单机部署的系统被演化成分布式集群系统后,由于分布式系统多线程、多进程并且分布在不同机器上,这将使原单机部署情况下的并发控制锁策略失效,单纯的Java API并不能提供分布式锁的能力。为了解决这个问题就需要一种跨JVM的互斥机制来控制共享资源的访问,这就是分布式锁要解决的问题!二、分布式锁应该具备哪些条件
在分析分布式锁的三种实现方式之前,先了解一下分布式锁应该具备哪些条件:1、在分布式系统环境下,一个方法在同一时间只能被一个机器的一个线程执行; 2、高可用的获取锁与释放锁; 3、高性能的获取锁与释放锁; 4、具备可重入特性; 5、具备锁失效机制,防止死锁; 6、具备非阻塞锁特性,即没有获取到锁将直接返回获取锁失败。
三、分布式锁的三种实现方式
目前几乎很多大型网站及应用都是分布式部署的,分布式场景中的数据一致性问题一直是一个比较重要的话题。分布式的CAP理论告诉我们“任何一个分布式系统都无法同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance),最多只能同时满足两项。”所以,很多系统在设计之初就要对这三者做出取舍。在互联网领域的绝大多数的场景中,都需要牺牲强一致性来换取系统的高可用性,系统往往只需要保证“最终一致性”,只要这个最终时间是在用户可以接受的范围内即可。 在很多场景中,我们为了保证数据的最终一致性,需要很多的技术方案来支持,比如分布式事务、分布式锁等。有的时候,我们需要保证一个方法在同一时间内只能被同一个线程执行。基于数据库实现分布式锁; 基于缓存(Redis等)实现分布式锁; 基于Zookeeper实现分布式锁;尽管有这三种方案,但是不同的业务也要根据自己的情况进行选型,他们之间没有最好只有更适合!
3.1基于数据库实现分布式锁
使用基于数据库的这种实现方式很简单,但是对于分布式锁应该具备的条件来说,它有一些问题需要解决及优化: 1、因为是基于数据库实现的,数据库的可用性和性能将直接影响分布式锁的可用性及性能,所以,数据库需要双机部署、数据同步、主备切换; 2、不具备可重入的特性,因为同一个线程在释放锁之前,行数据一直存在,无法再次成功插入数据,所以,需要在表中新增一列,用于记录当前获取到锁的机器和线程信息,在再次获取锁的时候,先查询表中机器和线程信息是否和当前机器和线程相同,若相同则直接获取锁; 3、没有锁失效机制,因为有可能出现成功插入数据后,服务器宕机了,对应的数据没有被删除,当服务恢复后一直获取不到锁,所以,需要在表中新增一列,用于记录失效时间,并且需要有定时任务清除这些失效的数据; 4、不具备阻塞锁特性,获取不到锁直接返回失败,所以需要优化获取逻辑,循环多次去获取。 5、在实施的过程中会遇到各种不同的问题,为了解决这些问题,实现方式将会越来越复杂;依赖数据库需要一定的资源开销,性能问题需要考虑。3.2基于缓存(Redis等)实现分布式锁
1、选用Redis实现分布式锁原因: (1)Redis有很高的性能; (2)Redis命令对此支持较好,实现起来比较方便 2、使用命令介绍: (1)SETNXSETNX key val:当且仅当key不存在时,set一个key为val的字符串,返回1;若key存在,则什么都不做,返回0。expire key timeout:为key设置一个超时时间,单位为second,超过这个时间锁会自动释放,避免死锁。delete key:删除key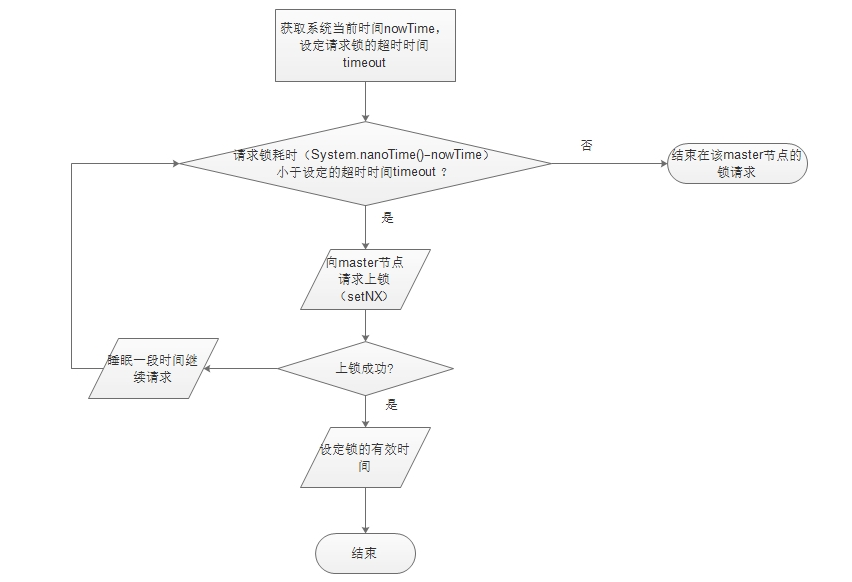
3.3基于Zookeeper实现分布式锁
ZooKeeper是一个为分布式应用提供一致性服务的开源组件,它内部是一个分层的文件系统目录树结构,规定同一个目录下只能有一个唯一文件名。基于ZooKeeper实现分布式锁的步骤如下: (1)创建一个目录mylock; (2)线程A想获取锁就在mylock目录下创建临时顺序节点; (3)获取mylock目录下所有的子节点,然后获取比自己小的兄弟节点,如果不存在,则说明当前线程顺序号最小,获得锁; (4)线程B获取所有节点,判断自己不是最小节点,设置监听比自己次小的节点; (5)线程A处理完,删除自己的节点,线程B监听到变更事件,判断自己是不是最小的节点,如果是则获得锁。 这里推荐一个Apache的开源库Curator,它是一个ZooKeeper客户端,Curator提供的InterProcessMutex是分布式锁的实现,acquire方法用于获取锁,release方法用于释放锁。 优点:具备高可用、可重入、阻塞锁特性,可解决失效死锁问题。 缺点:因为需要频繁的创建和删除节点,性能上不如Redis方式。3.4总结
上面的三种实现方式,没有在所有场合都是完美的,所以,应根据不同的应用场景选择最适合的实现方式。 在分布式环境中,对资源进行上锁有时候是很重要的,比如抢购某一资源,这时候使用分布式锁就可以很好地控制资源。 当然,在具体使用中,还需要考虑很多因素,比如超时时间的选取,获取锁时间的选取对并发量都有很大的影响,上述实现的分布式锁也只是一种简单的实现,主要是一种思想,正文到此结束
- 本文标签:
- 版权声明: 本文由HARRIES原创发布,转载请遵循《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

