Dubbo入门(1) - 基础概念
随着互联网的逐渐发展和壮大,服务端的架构也在不断变得更庞大、更复杂。
大概的演变过程分为以下几个阶段:
-
单一应用架构
服务端解决所有问题,从数据储存到MVC。应用规模较小的时候可以采用这种架构,绝大多数学生时代的课设或是小型web项目都是这种结构。
一台服务器,一个开发框架,一个数据库便构成了一个完整的应用。
这一阶段主要的性能瓶颈是 ORM ,因为整体应用通常是对数据库CURD操作的一个封装,所以性能最终取决于数据库以及应用框架与数据库之间的连接部分。
-
垂直应用架构
当应用规模增大时,单一服务支撑整个应用就显得有些力不从心了,此时需要对服务进行拆解。
最常见的拆解是 前后端分离 ,此时服务端专注于提供接口,可以将服务进一步拆解成几个不相关的部分独立垂直部署,而前端提供一个统一的入口。
这一阶段的主要性能瓶颈是 MVC ,换句话说,页面的组织和开发将会是整个项目中最耗时的一部分(在没有复杂业务的前提下)。
-
分布式服务架构
当垂直应用越来越多时,就不可避免的产生交叉,此时的做法是将核心业务抽离出来,作为独立的服务中心部署。
而一个应用依赖的服务数量可能已经是一个非常庞大的数字,必须要对所有这些服务进行必要的监控、调整以及整合。
这一阶段主要的性能瓶颈便是 分布式服务框架(RPC) 。
-
流动计算架构
服务越来越多,容量的评估,小服务资源的浪费等问题便愈发严重,此时需增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率。
这一阶段的主要性能瓶颈是 资源调度和治理中心(SOA) 。
上面的演变流程可以参考下图:
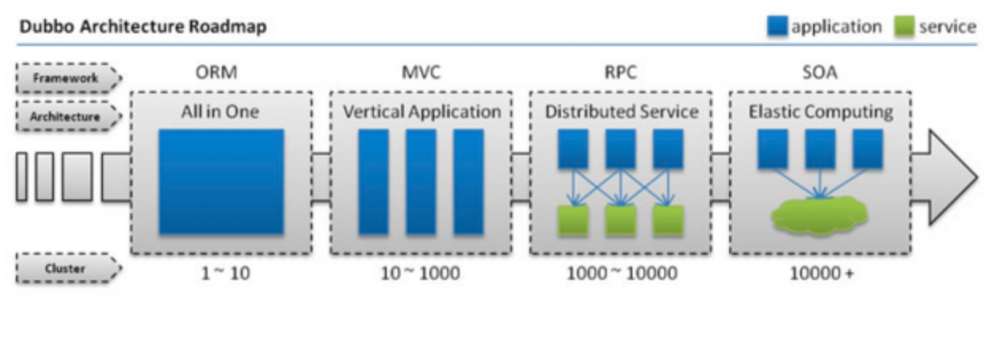
分布式服务框架的关注点
从个人理解的角度出发,针对大型应用编程的时候,设计的思路不再是面向服务器的一条龙式编程,而是 面向服务 的编程,这是一个重要的思维模式的转换。
开发人员的关注点也随之发生变化,在分布式服务框架中,我们需要关注的问题有以下几个:
-
服务之间如何通信?
其实从分布式的架构中不难看出,服务之间的通信其实是分布式框架的一个重点。要实现服务之间的通信,现在业内主要使用以下几种方案:
- (同步)高性能RPC,比如dubbo本身其实就是一个RPC框架,重点在于实现对于外部服务过程的 透明调用
- (同步)RESTful API,比起RPC可能性能略低,但是规范、可复用性强
- (异步)使用消息队列
值得注意的是,因为服务之间的通信变多,通信的管理工作也会成为一个重点。
-
客户端如何访问到服务?
当服务被拆分,部署到集群,客户端便再也无法通过固定的地址来访问到服务。此外,服务真正部署的节点还会随时发生变动:删除、增加或是故障,都需要客户端能够实时感知,为了实现这个效果,需要提供下面两个实现:
- API Gateway: 外界Client访问的一个统一入口,内部通过负载均衡等手段将客户端定向到真正的服务提供节点。
- 服务发现: 当新的服务接入、旧的服务删除,或者是已有的服务扩展集群时,业务都需要感知这些变动,这时候需要一个集中的节点注册/管理机制,比如
ZooKeeper或者etcd。
-
服务出现故障时怎么办?
由于整个应用变成了分布式的服务,那么任何一个服务出现故障,都可能导致整个应用崩溃,同时由于服务数量的增加,错误的定位也更加困难,因此需要一个良好的监控机制。
用于保证服务可用性的解决手段(我了解的) 主要如下:
- 应用健康检查机制:通过心跳包等手段监控服务大盘的稳定性,做到故障的快速定位
- 熔断、限流、降级:当部分服务出现故障时,为了将损失最小化的一套应对流程,具体的实现可以参考
Hytrix
-
数据如何共享?
这也是分布式系统一个非常头疼的问题,由于服务的分散和数据量的增加,整个应用的数据将会被分散到很多不同的储存节点上,这导致数据的同步变得很艰难。
主要体现为以下两点:
-
服务分散了,但是某些数据是集中共用的,比如用户的账号信息,这时候需要一个集中的数据中心来管理,这方面可以参考SSO和OAuth的使用。
-
数据量太大,需要进行分库、分表,这时候如果有事务需要同时对物理隔离的数据进行操作,就需要考虑数据一致性如何保证。
根据著名的
CAP定律,在分布式系统中无法同时保证高可用性和强一致性。因此大多数场景下会妥协强一致性,而采用最终一致性,这部分的讨论可以移步此处了解更多。 -
总结
我们把分布式架构下的需要解决的问题梳理整理一下,就可以明白一个分布式服务框架需要提供哪些功能:
- API Gateway(服务入口)
- 服务间调用(RPC,RESTful)
- 服务发现(Zookeeper)
- 服务容错(Hytrix)
- 服务部署和治理(Docker,服务网格)
- 数据调用(数据中心、最终一致性)
用下面这个图可以更直观的了解整体的结构(原图是描述微服务的,但对分布式服务同样有效)
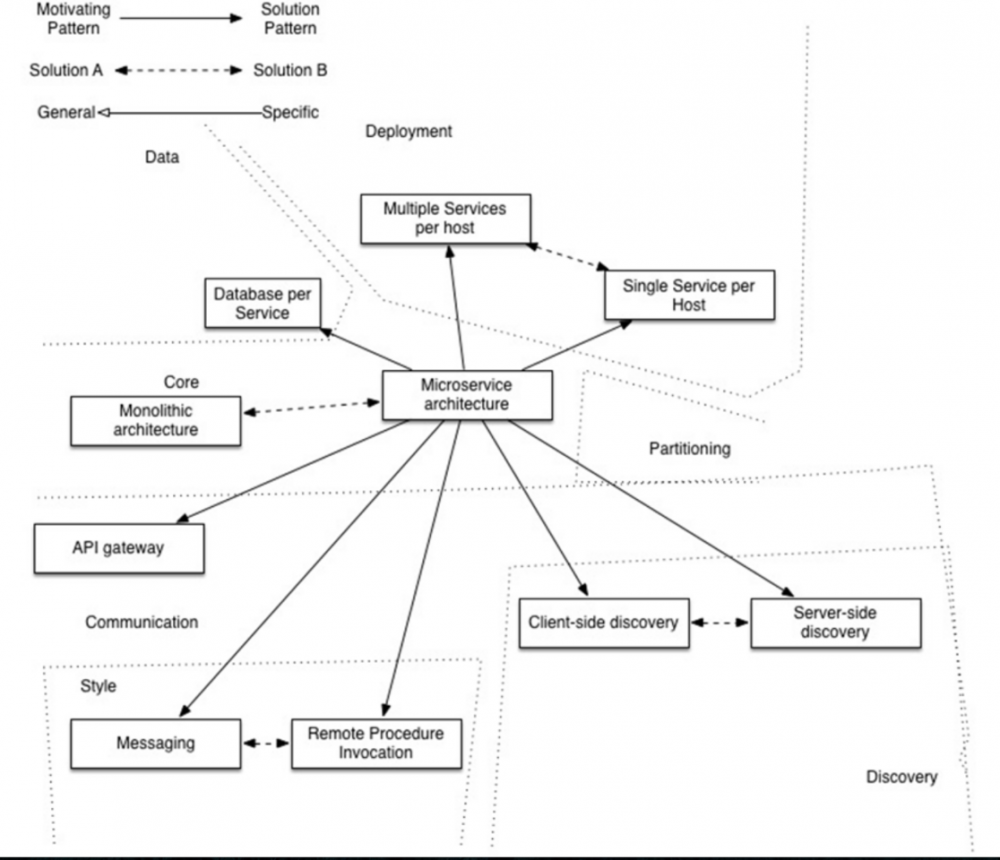
当然要写好一套分布式的服务,不只是使用一个分布式框架就可以解决的,还需要对服务进行合理的拆分,编写出适合分布式结构的代码,以及后期的治理、维护。
另外微服务、分布式服务等概念带来的意义在于给服务端开发者带来对技术架构的一个全新意识,而不是抽象的概念、定式的模板。具体落地使用什么样的解决方案,还是要针对业务场景来进行调整的。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

