Java 集合Hashtable源码深入解析
前面,我们已经系统的对List进行了学习。接下来,我们先学习Map,然后再学习Set;因为Set的实现类都是基于Map来实现的(如,HashSet是通过HashMap实现的,TreeSet是通过TreeMap实现的)。
首先,我们看看Map架构。
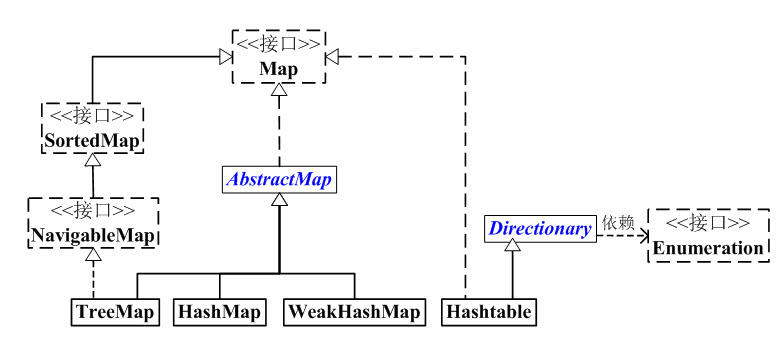
”。
在对各个实现类进行详细之前,先来看看 各个接口和抽象类的大致介绍 。
1 Map
Map的定义如下:
public interface Map<K,V> { }
Map 是一个键值对(key-value)映射接口。 Map映射中不能包含重复的键;每个键最多只能映射到一个值。 Map 接口提供三种collection 视图,允许以 键集 、 值集 或 键-值映射 关系集的形式查看某个映射的内容。 Map 映射顺序。有些实现类,可以明确保证其顺序,如 TreeMap;另一些映射实现则不保证顺序,如 HashMap 类。 Map 的实现类应该提供2个“标准的”构造方法: 第一个,void(无参数)构造方法,用于创建空映射;第二个,带有单个 Map 类型参数的构造方法,用于创建一个与其参数具有相同键-值映射关系的新映射 。实际上,后一个构造方法允许用户复制任意映射,生成所需类的一个等价映射。尽管无法强制执行此建议(因为接口不能包含构造方法),但是 JDK 中所有通用的映射实现都遵从它。
Map的API
abstract void clear() abstract boolean containsKey(Object key) abstract boolean containsValue(Object value) abstract Set<Entry<K, V>> entrySet() abstract boolean equals(Object object) abstract V get(Object key) abstract int hashCode() abstract boolean isEmpty() abstract Set<K> keySet() abstract V put(K key, V value) abstract void putAll(Map<? extends K, ? extends V> map) abstract V remove(Object key) abstract int size() abstract Collection<V> values()
说明:(01) Map提供接口分别用于返回 键集 、 值集 或 键-值映射关系 集。 entrySet()用于返回 键-值集的Set集合 keySet()用于返回 键集的Set集合 values()用户返回 值集的Collection集合 因为Map中不能包含重复的键;每个键最多只能映射到一个值。所以, 键-值集、键集都是Set,值集时Collection。
(02) Map提供了“键-值对”、“根据键获取值”、“删除键”、“获取容量大小”等方法。
2 Map.Entry
Map.Entry的定义如下:
interface Entry<K,V> { }
Map.Entry是Map中内部的一个接口,Map.Entry是 键值对 ,Map通过 entrySet() 获取Map.Entry的键值对集合,从而通过该集合实现对键值对的操作。
Map.Entry的API
abstract boolean equals(Object object) abstract K getKey() abstract V getValue() abstract int hashCode() abstract V setValue(V object)
3 AbstractMap
AbstractMap的定义如下:
public abstract class AbstractMap<K,V> implements Map<K,V> {}
AbstractMap类提供 Map 接口的骨干实现,以最大限度地减少实现此接口所需的工作。 要实现不可修改的映射,编程人员只需扩展此类并提供 entrySet 方法的实现即可,该方法将返回映射的映射关系 set 视图。通常,返回的 set 将依次在 AbstractSet 上实现。此 set 不支持 add() 或 remove() 方法,其迭代器也不支持 remove() 方法。
要实现可修改的映射,编程人员必须另外重写此类的 put 方法(否则将抛出 UnsupportedOperationException),entrySet().iterator() 返回的迭代器也必须另外实现其 remove 方法。
AbstractMap的API
abstract Set<Entry<K, V>> entrySet()
void clear()
boolean containsKey(Object key)
boolean containsValue(Object value)
boolean equals(Object object)
V get(Object key)
int hashCode()
boolean isEmpty()
Set<K> keySet()
V put(K key, V value)
void putAll(Map<? extends K, ? extends V> map)
V remove(Object key)
int size()
String toString()
Collection<V> values()
Object clone()
4 SortedMap
SortedMap的定义如下:
public interface SortedMap<K,V> extends Map<K,V> { }
SortedMap是一个继承于Map接口的接口。它是一个有序的SortedMap键值映射。 SortedMap的排序方式有两种: 自然排序 或者 用户指定比较器 。 插入有序 SortedMap 的所有元素都必须实现 Comparable 接口(或者被指定的比较器所接受)。
另外,所有SortedMap 实现类都应该提供 4 个“标准”构造方法: (01) void(无参数)构造方法 ,它创建一个空的有序映射,按照键的自然顺序进行排序。 (02) 带有一个 Comparator 类型参数的构造方法 ,它创建一个空的有序映射,根据指定的比较器进行排序。 (03) 带有一个 Map 类型参数的构造方法 ,它创建一个新的有序映射,其键-值映射关系与参数相同,按照键的自然顺序进行排序。 (04) 带有一个 SortedMap 类型参数的构造方法 ,它创建一个新的有序映射,其键-值映射关系和排序方法与输入的有序映射相同。无法保证强制实施此建议,因为接口不能包含构造方法。
SortedMap的API
// 继承于Map的API abstract void clear() abstract boolean containsKey(Object key) abstract boolean containsValue(Object value) abstract Set<Entry<K, V>> entrySet() abstract boolean equals(Object object) abstract V get(Object key) abstract int hashCode() abstract boolean isEmpty() abstract Set<K> keySet() abstract V put(K key, V value) abstract void putAll(Map<? extends K, ? extends V> map) abstract V remove(Object key) abstract int size() abstract Collection<V> values() // SortedMap新增的API abstract Comparator<? super K> comparator() abstract K firstKey() abstract SortedMap<K, V> headMap(K endKey) abstract K lastKey() abstract SortedMap<K, V> subMap(K startKey, K endKey) abstract SortedMap<K, V> tailMap(K startKey)
5 NavigableMap
NavigableMap的定义如下:
public interface NavigableMap<K,V> extends SortedMap<K,V> { }
NavigableMap是继承于SortedMap的接口。它是一个可导航的键-值对集合,具有了为给定搜索目标报告最接近匹配项的导航方法。 NavigableMap分别提供了获取“键”、“键-值对”、“键集”、“键-值对集”的相关方法。
NavigableMap的API
abstract Entry<K, V> ceilingEntry(K key) abstract Entry<K, V> firstEntry() abstract Entry<K, V> floorEntry(K key) abstract Entry<K, V> higherEntry(K key) abstract Entry<K, V> lastEntry() abstract Entry<K, V> lowerEntry(K key) abstract Entry<K, V> pollFirstEntry() abstract Entry<K, V> pollLastEntry() abstract K ceilingKey(K key) abstract K floorKey(K key) abstract K higherKey(K key) abstract K lowerKey(K key) abstract NavigableSet<K> descendingKeySet() abstract NavigableSet<K> navigableKeySet() abstract NavigableMap<K, V> descendingMap() abstract NavigableMap<K, V> headMap(K toKey, boolean inclusive) abstract SortedMap<K, V> headMap(K toKey) abstract SortedMap<K, V> subMap(K fromKey, K toKey) abstract NavigableMap<K, V> subMap(K fromKey, boolean fromInclusive, K toKey, boolean toInclusive) abstract SortedMap<K, V> tailMap(K fromKey) abstract NavigableMap<K, V> tailMap(K fromKey, boolean inclusive)
说明:
NavigableMap除了继承SortedMap的特性外,它的提供的功能可以分为4类: 第1类, 提供操作键-值对的方法。 lowerEntry、floorEntry、ceilingEntry 和 higherEntry 方法,它们分别返回与小于、小于等于、大于等于、大于给定键的键关联的 Map.Entry 对象。 firstEntry、pollFirstEntry、lastEntry 和 pollLastEntry 方法,它们返回和/或移除最小和最大的映射关系(如果存在),否则返回 null。 第2类, 提供操作键的方法 。这个和第1类比较类似 lowerKey、floorKey、ceilingKey 和 higherKey 方法,它们分别返回与小于、小于等于、大于等于、大于给定键的键。 第3类, 获取键集 。 navigableKeySet、descendingKeySet分别获取正序/反序的键集。 第4类,获取键-值对的子集。
6 Dictionary
Dictionary的定义如下:
public abstract class Dictionary<K,V> {}
NavigableMap是JDK 1.0定义的键值对的接口,它也包括了操作键值对的基本函数。
Dictionary的API
abstract Enumeration<V> elements() abstract V get(Object key) abstract boolean isEmpty() abstract Enumeration<K> keys() abstract V put(K key, V value) abstract V remove(Object key) abstract int size()
概要
前一章,我们学习了HashMap。这一章,我们对Hashtable进行学习。 我们先对Hashtable有个整体认识,然后再学习它的源码,最后再通过实例来学会使用Hashtable。
第1部分 Hashtable介绍
Hashtable 简介
和HashMap一样,Hashtable 也是一个 散列表 ,它存储的内容是 键值对(key-value)映射 。 Hashtable 继承于Dictionary ,实现了Map、Cloneable、java.io.Serializable接口。 Hashtable 的函数都是 同步的 ,这意味着它是线程安全的。它的key、value都不可以为null。此外,Hashtable中的映射不是有序的。
Hashtable 的实例有两个参数影响其性能: 初始容量 和 加 载因子 。容量 是哈希表中桶 的数量,初始容量 就是哈希表创建时的容量。注意,哈希表的状态为 open:在发生“哈希冲突”的情况下,单个桶会存储多个条目,这些条目必须按顺序搜索。加载因子 是对哈希表在其容量自动增加之前可以达到多满的一个尺度。初始容量和加载因子这两个参数只是对该实现的提示。关于何时以及是否调用 rehash 方法的具体细节则依赖于该实现。 通常, 默认加载因子是 0.75 , 这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查找某个条目的时间(在大多数 Hashtable 操作中,包括 get 和 put 操作,都反映了这一点)。
Hashtable的构造函数
// 默认构造函数。 public Hashtable() // 指定“容量大小”的构造函数 public Hashtable(int initialCapacity) // 指定“容量大小”和“加载因子”的构造函数 public Hashtable(int initialCapacity, float loadFactor) // 包含“子Map”的构造函数 public Hashtable(Map<? extends K, ? extends V> t)
Hashtable的API
synchronized void clear()
synchronized Object clone()
boolean contains(Object value)
synchronized boolean containsKey(Object key)
synchronized boolean containsValue(Object value)
synchronized Enumeration<V> elements()
synchronized Set<Entry<K, V>> entrySet()
synchronized boolean equals(Object object)
synchronized V get(Object key)
synchronized int hashCode()
synchronized boolean isEmpty()
synchronized Set<K> keySet()
synchronized Enumeration<K> keys()
synchronized V put(K key, V value)
synchronized void putAll(Map<? extends K, ? extends V> map)
synchronized V remove(Object key)
synchronized int size()
synchronized String toString()
synchronized Collection<V> values()
第2部分 Hashtable数据结构
Hashtable的继承关系
java.lang.Object
↳ java.util.Dictionary<K, V>
↳ java.util.Hashtable<K, V>
public class Hashtable<K,V> extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable { }
Hashtable与Map关系如下图:
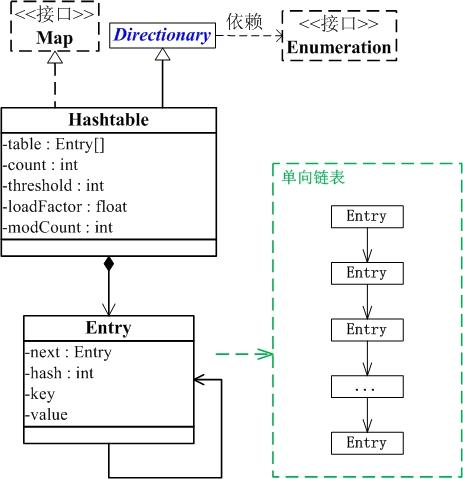
table, count, threshold, loadFactor, modCount 。
table 是一个Entry[]数组类型,而Entry实际上就是一个单向链表。哈希表的"key-value键值对"都是存储在Entry数组中的。
count 是Hashtable的大小,它是Hashtable保存的键值对的数量。
threshold 是Hashtable的阈值,用于判断是否需要调整Hashtable的容量。threshold的值="容量*加载因子"。
loadFactor 就是加载因子。
modCount
是用来实现fail-fast机制的
第3部分 Hashtable源码解析(基于JDK1.6.0_45)
为了更了解Hashtable的原理,下面对Hashtable源码代码作出分析。 在阅读源码时,建议参考后面的说明来建立对Hashtable的整体认识,这样更容易理解Hashtable。
package java.util;
import java.io.*;
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable {
// Hashtable保存key-value的数组。
// Hashtable是采用拉链法实现的,每一个Entry本质上是一个单向链表
private transient Entry[] table;
// Hashtable中元素的实际数量
private transient int count;
// 阈值,用于判断是否需要调整Hashtable的容量(threshold = 容量*加载因子)
private int threshold;
// 加载因子
private float loadFactor;
// Hashtable被改变的次数
private transient int modCount = 0;
// 序列版本号
private static final long serialVersionUID = 1421746759512286392L;
// 指定“容量大小”和“加载因子”的构造函数
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new Entry[initialCapacity];
threshold = (int)(initialCapacity * loadFactor);
}
// 指定“容量大小”的构造函数
public Hashtable(int initialCapacity) {
this(initialCapacity, 0.75f);
}
// 默认构造函数。
public Hashtable() {
// 默认构造函数,指定的容量大小是11;加载因子是0.75
this(11, 0.75f);
}
// 包含“子Map”的构造函数
public Hashtable(Map<? extends K, ? extends V> t) {
this(Math.max(2*t.size(), 11), 0.75f);
// 将“子Map”的全部元素都添加到Hashtable中
putAll(t);
}
public synchronized int size() {
return count;
}
public synchronized boolean isEmpty() {
return count == 0;
}
// 返回“所有key”的枚举对象
public synchronized Enumeration<K> keys() {
return this.<K>getEnumeration(KEYS);
}
// 返回“所有value”的枚举对象
public synchronized Enumeration<V> elements() {
return this.<V>getEnumeration(VALUES);
}
// 判断Hashtable是否包含“值(value)”
public synchronized boolean contains(Object value) {
// Hashtable中“键值对”的value不能是null,
// 若是null的话,抛出异常!
if (value == null) {
throw new NullPointerException();
}
// 从后向前遍历table数组中的元素(Entry)
// 对于每个Entry(单向链表),逐个遍历,判断节点的值是否等于value
Entry tab[] = table;
for (int i = tab.length ; i-- > 0 ;) {
for (Entry<K,V> e = tab[i] ; e != null ; e = e.next) {
if (e.value.equals(value)) {
return true;
}
}
}
return false;
}
public boolean containsValue(Object value) {
return contains(value);
}
// 判断Hashtable是否包含key
public synchronized boolean containsKey(Object key) {
Entry tab[] = table;
int hash = key.hashCode();
// 计算索引值,
// % tab.length 的目的是防止数据越界
int index = (hash & 0x7FFFFFFF) % tab.length;
// 找到“key对应的Entry(链表)”,然后在链表中找出“哈希值”和“键值”与key都相等的元素
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return true;
}
}
return false;
}
// 返回key对应的value,没有的话返回null
public synchronized V get(Object key) {
Entry tab[] = table;
int hash = key.hashCode();
// 计算索引值,
int index = (hash & 0x7FFFFFFF) % tab.length;
// 找到“key对应的Entry(链表)”,然后在链表中找出“哈希值”和“键值”与key都相等的元素
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return e.value;
}
}
return null;
}
// 调整Hashtable的长度,将长度变成原来的(2倍+1)
// (01) 将“旧的Entry数组”赋值给一个临时变量。
// (02) 创建一个“新的Entry数组”,并赋值给“旧的Entry数组”
// (03) 将“Hashtable”中的全部元素依次添加到“新的Entry数组”中
protected void rehash() {
int oldCapacity = table.length;
Entry[] oldMap = table;
int newCapacity = oldCapacity * 2 + 1;
Entry[] newMap = new Entry[newCapacity];
modCount++;
threshold = (int)(newCapacity * loadFactor);
table = newMap;
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = newMap[index];
newMap[index] = e;
}
}
}
// 将“key-value”添加到Hashtable中
public synchronized V put(K key, V value) {
// Hashtable中不能插入value为null的元素!!!
if (value == null) {
throw new NullPointerException();
}
// 若“Hashtable中已存在键为key的键值对”,
// 则用“新的value”替换“旧的value”
Entry tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
V old = e.value;
e.value = value;
return old;
}
}
// 若“Hashtable中不存在键为key的键值对”,
// (01) 将“修改统计数”+1
modCount++;
// (02) 若“Hashtable实际容量” > “阈值”(阈值=总的容量 * 加载因子)
// 则调整Hashtable的大小
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
index = (hash & 0x7FFFFFFF) % tab.length;
}
// (03) 将“Hashtable中index”位置的Entry(链表)保存到e中
Entry<K,V> e = tab[index];
// (04) 创建“新的Entry节点”,并将“新的Entry”插入“Hashtable的index位置”,并设置e为“新的Entry”的下一个元素(即“新Entry”为链表表头)。
tab[index] = new Entry<K,V>(hash, key, value, e);
// (05) 将“Hashtable的实际容量”+1
count++;
return null;
}
// 删除Hashtable中键为key的元素
public synchronized V remove(Object key) {
Entry tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
// 找到“key对应的Entry(链表)”
// 然后在链表中找出要删除的节点,并删除该节点。
for (Entry<K,V> e = tab[index], prev = null ; e != null ; prev = e, e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
modCount++;
if (prev != null) {
prev.next = e.next;
} else {
tab[index] = e.next;
}
count--;
V oldValue = e.value;
e.value = null;
return oldValue;
}
}
return null;
}
// 将“Map(t)”的中全部元素逐一添加到Hashtable中
public synchronized void putAll(Map<? extends K, ? extends V> t) {
for (Map.Entry<? extends K, ? extends V> e : t.entrySet())
put(e.getKey(), e.getValue());
}
// 清空Hashtable
// 将Hashtable的table数组的值全部设为null
public synchronized void clear() {
Entry tab[] = table;
modCount++;
for (int index = tab.length; --index >= 0; )
tab[index] = null;
count = 0;
}
// 克隆一个Hashtable,并以Object的形式返回。
public synchronized Object clone() {
try {
Hashtable<K,V> t = (Hashtable<K,V>) super.clone();
t.table = new Entry[table.length];
for (int i = table.length ; i-- > 0 ; ) {
t.table[i] = (table[i] != null)
? (Entry<K,V>) table[i].clone() : null;
}
t.keySet = null;
t.entrySet = null;
t.values = null;
t.modCount = 0;
return t;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError();
}
}
public synchronized String toString() {
int max = size() - 1;
if (max == -1)
return "{}";
StringBuilder sb = new StringBuilder();
Iterator<Map.Entry<K,V>> it = entrySet().iterator();
sb.append('{');
for (int i = 0; ; i++) {
Map.Entry<K,V> e = it.next();
K key = e.getKey();
V value = e.getValue();
sb.append(key == this ? "(this Map)" : key.toString());
sb.append('=');
sb.append(value == this ? "(this Map)" : value.toString());
if (i == max)
return sb.append('}').toString();
sb.append(", ");
}
}
// 获取Hashtable的枚举类对象
// 若Hashtable的实际大小为0,则返回“空枚举类”对象;
// 否则,返回正常的Enumerator的对象。(Enumerator实现了迭代器和枚举两个接口)
private <T> Enumeration<T> getEnumeration(int type) {
if (count == 0) {
return (Enumeration<T>)emptyEnumerator;
} else {
return new Enumerator<T>(type, false);
}
}
// 获取Hashtable的迭代器
// 若Hashtable的实际大小为0,则返回“空迭代器”对象;
// 否则,返回正常的Enumerator的对象。(Enumerator实现了迭代器和枚举两个接口)
private <T> Iterator<T> getIterator(int type) {
if (count == 0) {
return (Iterator<T>) emptyIterator;
} else {
return new Enumerator<T>(type, true);
}
}
// Hashtable的“key的集合”。它是一个Set,意味着没有重复元素
private transient volatile Set<K> keySet = null;
// Hashtable的“key-value的集合”。它是一个Set,意味着没有重复元素
private transient volatile Set<Map.Entry<K,V>> entrySet = null;
// Hashtable的“key-value的集合”。它是一个Collection,意味着可以有重复元素
private transient volatile Collection<V> values = null;
// 返回一个被synchronizedSet封装后的KeySet对象
// synchronizedSet封装的目的是对KeySet的所有方法都添加synchronized,实现多线程同步
public Set<K> keySet() {
if (keySet == null)
keySet = Collections.synchronizedSet(new KeySet(), this);
return keySet;
}
// Hashtable的Key的Set集合。
// KeySet继承于AbstractSet,所以,KeySet中的元素没有重复的。
private class KeySet extends AbstractSet<K> {
public Iterator<K> iterator() {
return getIterator(KEYS);
}
public int size() {
return count;
}
public boolean contains(Object o) {
return containsKey(o);
}
public boolean remove(Object o) {
return Hashtable.this.remove(o) != null;
}
public void clear() {
Hashtable.this.clear();
}
}
// 返回一个被synchronizedSet封装后的EntrySet对象
// synchronizedSet封装的目的是对EntrySet的所有方法都添加synchronized,实现多线程同步
public Set<Map.Entry<K,V>> entrySet() {
if (entrySet==null)
entrySet = Collections.synchronizedSet(new EntrySet(), this);
return entrySet;
}
// Hashtable的Entry的Set集合。
// EntrySet继承于AbstractSet,所以,EntrySet中的元素没有重复的。
private class EntrySet extends AbstractSet<Map.Entry<K,V>> {
public Iterator<Map.Entry<K,V>> iterator() {
return getIterator(ENTRIES);
}
public boolean add(Map.Entry<K,V> o) {
return super.add(o);
}
// 查找EntrySet中是否包含Object(0)
// 首先,在table中找到o对应的Entry(Entry是一个单向链表)
// 然后,查找Entry链表中是否存在Object
public boolean contains(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry entry = (Map.Entry)o;
Object key = entry.getKey();
Entry[] tab = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry e = tab[index]; e != null; e = e.next)
if (e.hash==hash && e.equals(entry))
return true;
return false;
}
// 删除元素Object(0)
// 首先,在table中找到o对应的Entry(Entry是一个单向链表)
// 然后,删除链表中的元素Object
public boolean remove(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<K,V> entry = (Map.Entry<K,V>) o;
K key = entry.getKey();
Entry[] tab = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index], prev = null; e != null;
prev = e, e = e.next) {
if (e.hash==hash && e.equals(entry)) {
modCount++;
if (prev != null)
prev.next = e.next;
else
tab[index] = e.next;
count--;
e.value = null;
return true;
}
}
return false;
}
public int size() {
return count;
}
public void clear() {
Hashtable.this.clear();
}
}
// 返回一个被synchronizedCollection封装后的ValueCollection对象
// synchronizedCollection封装的目的是对ValueCollection的所有方法都添加synchronized,实现多线程同步
public Collection<V> values() {
if (values==null)
values = Collections.synchronizedCollection(new ValueCollection(),
this);
return values;
}
// Hashtable的value的Collection集合。
// ValueCollection继承于AbstractCollection,所以,ValueCollection中的元素可以重复的。
private class ValueCollection extends AbstractCollection<V> {
public Iterator<V> iterator() {
return getIterator(VALUES);
}
public int size() {
return count;
}
public boolean contains(Object o) {
return containsValue(o);
}
public void clear() {
Hashtable.this.clear();
}
}
// 重新equals()函数
// 若两个Hashtable的所有key-value键值对都相等,则判断它们两个相等
public synchronized boolean equals(Object o) {
if (o == this)
return true;
if (!(o instanceof Map))
return false;
Map<K,V> t = (Map<K,V>) o;
if (t.size() != size())
return false;
try {
// 通过迭代器依次取出当前Hashtable的key-value键值对
// 并判断该键值对,存在于Hashtable(o)中。
// 若不存在,则立即返回false;否则,遍历完“当前Hashtable”并返回true。
Iterator<Map.Entry<K,V>> i = entrySet().iterator();
while (i.hasNext()) {
Map.Entry<K,V> e = i.next();
K key = e.getKey();
V value = e.getValue();
if (value == null) {
if (!(t.get(key)==null && t.containsKey(key)))
return false;
} else {
if (!value.equals(t.get(key)))
return false;
}
}
} catch (ClassCastException unused) {
return false;
} catch (NullPointerException unused) {
return false;
}
return true;
}
// 计算Hashtable的哈希值
// 若 Hashtable的实际大小为0 或者 加载因子<0,则返回0。
// 否则,返回“Hashtable中的每个Entry的key和value的异或值 的总和”。
public synchronized int hashCode() {
int h = 0;
if (count == 0 || loadFactor < 0)
return h; // Returns zero
loadFactor = -loadFactor; // Mark hashCode computation in progress
Entry[] tab = table;
for (int i = 0; i < tab.length; i++)
for (Entry e = tab[i]; e != null; e = e.next)
h += e.key.hashCode() ^ e.value.hashCode();
loadFactor = -loadFactor; // Mark hashCode computation complete
return h;
}
// java.io.Serializable的写入函数
// 将Hashtable的“总的容量,实际容量,所有的Entry”都写入到输出流中
private synchronized void writeObject(java.io.ObjectOutputStream s)
throws IOException
{
// Write out the length, threshold, loadfactor
s.defaultWriteObject();
// Write out length, count of elements and then the key/value objects
s.writeInt(table.length);
s.writeInt(count);
for (int index = table.length-1; index >= 0; index--) {
Entry entry = table[index];
while (entry != null) {
s.writeObject(entry.key);
s.writeObject(entry.value);
entry = entry.next;
}
}
}
// java.io.Serializable的读取函数:根据写入方式读出
// 将Hashtable的“总的容量,实际容量,所有的Entry”依次读出
private void readObject(java.io.ObjectInputStream s)
throws IOException, ClassNotFoundException
{
// Read in the length, threshold, and loadfactor
s.defaultReadObject();
// Read the original length of the array and number of elements
int origlength = s.readInt();
int elements = s.readInt();
// Compute new size with a bit of room 5% to grow but
// no larger than the original size. Make the length
// odd if it's large enough, this helps distribute the entries.
// Guard against the length ending up zero, that's not valid.
int length = (int)(elements * loadFactor) + (elements / 20) + 3;
if (length > elements && (length & 1) == 0)
length--;
if (origlength > 0 && length > origlength)
length = origlength;
Entry[] table = new Entry[length];
count = 0;
// Read the number of elements and then all the key/value objects
for (; elements > 0; elements--) {
K key = (K)s.readObject();
V value = (V)s.readObject();
// synch could be eliminated for performance
reconstitutionPut(table, key, value);
}
this.table = table;
}
private void reconstitutionPut(Entry[] tab, K key, V value)
throws StreamCorruptedException
{
if (value == null) {
throw new java.io.StreamCorruptedException();
}
// Makes sure the key is not already in the hashtable.
// This should not happen in deserialized version.
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
throw new java.io.StreamCorruptedException();
}
}
// Creates the new entry.
Entry<K,V> e = tab[index];
tab[index] = new Entry<K,V>(hash, key, value, e);
count++;
}
// Hashtable的Entry节点,它本质上是一个单向链表。
// 也因此,我们才能推断出Hashtable是由拉链法实现的散列表
private static class Entry<K,V> implements Map.Entry<K,V> {
// 哈希值
int hash;
K key;
V value;
// 指向的下一个Entry,即链表的下一个节点
Entry<K,V> next;
// 构造函数
protected Entry(int hash, K key, V value, Entry<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
protected Object clone() {
return new Entry<K,V>(hash, key, value,
(next==null ? null : (Entry<K,V>) next.clone()));
}
public K getKey() {
return key;
}
public V getValue() {
return value;
}
// 设置value。若value是null,则抛出异常。
public V setValue(V value) {
if (value == null)
throw new NullPointerException();
V oldValue = this.value;
this.value = value;
return oldValue;
}
// 覆盖equals()方法,判断两个Entry是否相等。
// 若两个Entry的key和value都相等,则认为它们相等。
public boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
return (key==null ? e.getKey()==null : key.equals(e.getKey())) &&
(value==null ? e.getValue()==null : value.equals(e.getValue()));
}
public int hashCode() {
return hash ^ (value==null ? 0 : value.hashCode());
}
public String toString() {
return key.toString()+"="+value.toString();
}
}
private static final int KEYS = 0;
private static final int VALUES = 1;
private static final int ENTRIES = 2;
// Enumerator的作用是提供了“通过elements()遍历Hashtable的接口” 和 “通过entrySet()遍历Hashtable的接口”。因为,它同时实现了 “Enumerator接口”和“Iterator接口”。
private class Enumerator<T> implements Enumeration<T>, Iterator<T> {
// 指向Hashtable的table
Entry[] table = Hashtable.this.table;
// Hashtable的总的大小
int index = table.length;
Entry<K,V> entry = null;
Entry<K,V> lastReturned = null;
int type;
// Enumerator是 “迭代器(Iterator)” 还是 “枚举类(Enumeration)”的标志
// iterator为true,表示它是迭代器;否则,是枚举类。
boolean iterator;
// 在将Enumerator当作迭代器使用时会用到,用来实现fail-fast机制。
protected int expectedModCount = modCount;
Enumerator(int type, boolean iterator) {
this.type = type;
this.iterator = iterator;
}
// 从遍历table的数组的末尾向前查找,直到找到不为null的Entry。
public boolean hasMoreElements() {
Entry<K,V> e = entry;
int i = index;
Entry[] t = table;
/* Use locals for faster loop iteration */
while (e == null && i > 0) {
e = t[--i];
}
entry = e;
index = i;
return e != null;
}
// 获取下一个元素
// 注意:从hasMoreElements() 和nextElement() 可以看出“Hashtable的elements()遍历方式”
// 首先,从后向前的遍历table数组。table数组的每个节点都是一个单向链表(Entry)。
// 然后,依次向后遍历单向链表Entry。
public T nextElement() {
Entry<K,V> et = entry;
int i = index;
Entry[] t = table;
/* Use locals for faster loop iteration */
while (et == null && i > 0) {
et = t[--i];
}
entry = et;
index = i;
if (et != null) {
Entry<K,V> e = lastReturned = entry;
entry = e.next;
return type == KEYS ? (T)e.key : (type == VALUES ? (T)e.value : (T)e);
}
throw new NoSuchElementException("Hashtable Enumerator");
}
// 迭代器Iterator的判断是否存在下一个元素
// 实际上,它是调用的hasMoreElements()
public boolean hasNext() {
return hasMoreElements();
}
// 迭代器获取下一个元素
// 实际上,它是调用的nextElement()
public T next() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
return nextElement();
}
// 迭代器的remove()接口。
// 首先,它在table数组中找出要删除元素所在的Entry,
// 然后,删除单向链表Entry中的元素。
public void remove() {
if (!iterator)
throw new UnsupportedOperationException();
if (lastReturned == null)
throw new IllegalStateException("Hashtable Enumerator");
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
synchronized(Hashtable.this) {
Entry[] tab = Hashtable.this.table;
int index = (lastReturned.hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index], prev = null; e != null;
prev = e, e = e.next) {
if (e == lastReturned) {
modCount++;
expectedModCount++;
if (prev == null)
tab[index] = e.next;
else
prev.next = e.next;
count--;
lastReturned = null;
return;
}
}
throw new ConcurrentModificationException();
}
}
}
private static Enumeration emptyEnumerator = new EmptyEnumerator();
private static Iterator emptyIterator = new EmptyIterator();
// 空枚举类
// 当Hashtable的实际大小为0;此时,又要通过Enumeration遍历Hashtable时,返回的是“空枚举类”的对象。
private static class EmptyEnumerator implements Enumeration<Object> {
EmptyEnumerator() {
}
// 空枚举类的hasMoreElements() 始终返回false
public boolean hasMoreElements() {
return false;
}
// 空枚举类的nextElement() 抛出异常
public Object nextElement() {
throw new NoSuchElementException("Hashtable Enumerator");
}
}
// 空迭代器
// 当Hashtable的实际大小为0;此时,又要通过迭代器遍历Hashtable时,返回的是“空迭代器”的对象。
private static class EmptyIterator implements Iterator<Object> {
EmptyIterator() {
}
public boolean hasNext() {
return false;
}
public Object next() {
throw new NoSuchElementException("Hashtable Iterator");
}
public void remove() {
throw new IllegalStateException("Hashtable Iterator");
}
}
}
说明:在详细介绍Hashtable的代码之前,我们需要了解:和Hashmap一样,Hashtable也是一个散列表,它也是通过“拉链法”解决哈希冲突的。
第3.1部分 Hashtable的“拉链法”相关内容
3.1.1 Hashtable数据存储数组
private transient Entry[] table;
Hashtable中的key-value都是 存储在table数组中的。
3.1.2 数据节点Entry的数据结构
private static class Entry<K,V> implements Map.Entry<K,V> {
// 哈希值
int hash;
K key;
V value;
// 指向的下一个Entry,即链表的下一个节点
Entry<K,V> next;
// 构造函数
protected Entry(int hash, K key, V value, Entry<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
protected Object clone() {
return new Entry<K,V>(hash, key, value,
(next==null ? null : (Entry<K,V>) next.clone()));
}
public K getKey() {
return key;
}
public V getValue() {
return value;
}
// 设置value。若value是null,则抛出异常。
public V setValue(V value) {
if (value == null)
throw new NullPointerException();
V oldValue = this.value;
this.value = value;
return oldValue;
}
// 覆盖equals()方法,判断两个Entry是否相等。
// 若两个Entry的key和value都相等,则认为它们相等。
public boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
return (key==null ? e.getKey()==null : key.equals(e.getKey())) &&
(value==null ? e.getValue()==null : value.equals(e.getValue()));
}
public int hashCode() {
return hash ^ (value==null ? 0 : value.hashCode());
}
public String toString() {
return key.toString()+"="+value.toString();
}
}
从中,我们可以看出 Entry 实际上就是一个单向链表。这也是为什么我们说Hashtable是通过拉链法解决哈希冲突的。 Entry 实现了Map.Entry 接口,即实现getKey(), getValue(), setValue(V value), equals(Object o), hashCode()这些函数。这些都是基本的读取/修改key、value值的函数。
第3.2部分 Hashtable的构造函数
Hashtable共包括4个构造函数
// 默认构造函数。
public Hashtable() {
// 默认构造函数,指定的容量大小是11;加载因子是0.75
this(11, 0.75f);
}
// 指定“容量大小”的构造函数
public Hashtable(int initialCapacity) {
this(initialCapacity, 0.75f);
}
// 指定“容量大小”和“加载因子”的构造函数
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new Entry[initialCapacity];
threshold = (int)(initialCapacity * loadFactor);
}
// 包含“子Map”的构造函数
public Hashtable(Map<? extends K, ? extends V> t) {
this(Math.max(2*t.size(), 11), 0.75f);
// 将“子Map”的全部元素都添加到Hashtable中
putAll(t);
}
第3.3部分 Hashtable的主要对外接口
3.3.1 clear()
clear() 的作用是 清空Hashtable 。它是将Hashtable的table数组的值全部设为null
public synchronized void clear() {
Entry tab[] = table;
modCount++;
for (int index = tab.length; --index >= 0; )
tab[index] = null;
count = 0;
}
3.3.2 contains() 和 containsValue()
contains() 和 containsValue() 的作用都是 判断Hashtable是否包含“值(value)”
public boolean containsValue(Object value) {
return contains(value);
}
public synchronized boolean contains(Object value) {
// Hashtable中“键值对”的value不能是null,
// 若是null的话,抛出异常!
if (value == null) {
throw new NullPointerException();
}
// 从后向前遍历table数组中的元素(Entry)
// 对于每个Entry(单向链表),逐个遍历,判断节点的值是否等于value
Entry tab[] = table;
for (int i = tab.length ; i-- > 0 ;) {
for (Entry<K,V> e = tab[i] ; e != null ; e = e.next) {
if (e.value.equals(value)) {
return true;
}
}
}
return false;
}
3.3.3 containsKey()
containsKey() 的作用 是判断Hashtable是否包含key
public synchronized boolean containsKey(Object key) {
Entry tab[] = table;
int hash = key.hashCode();
// 计算索引值,
// % tab.length 的目的是防止数据越界
int index = (hash & 0x7FFFFFFF) % tab.length;
// 找到“key对应的Entry(链表)”,然后在链表中找出“哈希值”和“键值”与key都相等的元素
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return true;
}
}
return false;
}
3.3.4 elements()
elements() 的作用是 返回“所有value”的枚举对象
public synchronized Enumeration<V> elements() {
return this.<V>getEnumeration(VALUES);
}
// 获取Hashtable的枚举类对象
private <T> Enumeration<T> getEnumeration(int type) {
if (count == 0) {
return (Enumeration<T>)emptyEnumerator;
} else {
return new Enumerator<T>(type, false);
}
}
从中,我们可以看出: (01) 若Hashtable的实际大小为0,则返回“空枚举类”对象emptyEnumerator; (02) 否则,返回正常的Enumerator的对象 。(Enumerator实现了迭代器和枚举两个接口)
我们先看看emptyEnumerator对象是如何实现的
private static Enumeration emptyEnumerator = new EmptyEnumerator();
// 空枚举类
// 当Hashtable的实际大小为0;此时,又要通过Enumeration遍历Hashtable时,返回的是“空枚举类”的对象。
private static class EmptyEnumerator implements Enumeration<Object> {
EmptyEnumerator() {
}
// 空枚举类的hasMoreElements() 始终返回false
public boolean hasMoreElements() {
return false;
}
// 空枚举类的nextElement() 抛出异常
public Object nextElement() {
throw new NoSuchElementException("Hashtable Enumerator");
}
}
我们在来看看Enumeration类
Enumerator的作用是 提供了“通过elements()遍历Hashtable的接口” 和 “通过entrySet()遍历Hashtable的接口 ”。因为,它同时实现了 “Enumerator接口”和“Iterator接口”。
private class Enumerator<T> implements Enumeration<T>, Iterator<T> {
// 指向Hashtable的table
Entry[] table = Hashtable.this.table;
// Hashtable的总的大小
int index = table.length;
Entry<K,V> entry = null;
Entry<K,V> lastReturned = null;
int type;
// Enumerator是 “迭代器(Iterator)” 还是 “枚举类(Enumeration)”的标志
// iterator为true,表示它是迭代器;否则,是枚举类。
boolean iterator;
// 在将Enumerator当作迭代器使用时会用到,用来实现fail-fast机制。
protected int expectedModCount = modCount;
Enumerator(int type, boolean iterator) {
this.type = type;
this.iterator = iterator;
}
// 从遍历table的数组的末尾向前查找,直到找到不为null的Entry。
public boolean hasMoreElements() {
Entry<K,V> e = entry;
int i = index;
Entry[] t = table;
/* Use locals for faster loop iteration */
while (e == null && i > 0) {
e = t[--i];
}
entry = e;
index = i;
return e != null;
}
// 获取下一个元素
// 注意:从hasMoreElements() 和nextElement() 可以看出“Hashtable的elements()遍历方式”
// 首先,从后向前的遍历table数组。table数组的每个节点都是一个单向链表(Entry)。
// 然后,依次向后遍历单向链表Entry。
public T nextElement() {
Entry<K,V> et = entry;
int i = index;
Entry[] t = table;
/* Use locals for faster loop iteration */
while (et == null && i > 0) {
et = t[--i];
}
entry = et;
index = i;
if (et != null) {
Entry<K,V> e = lastReturned = entry;
entry = e.next;
return type == KEYS ? (T)e.key : (type == VALUES ? (T)e.value : (T)e);
}
throw new NoSuchElementException("Hashtable Enumerator");
}
// 迭代器Iterator的判断是否存在下一个元素
// 实际上,它是调用的hasMoreElements()
public boolean hasNext() {
return hasMoreElements();
}
// 迭代器获取下一个元素
// 实际上,它是调用的nextElement()
public T next() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
return nextElement();
}
// 迭代器的remove()接口。
// 首先,它在table数组中找出要删除元素所在的Entry,
// 然后,删除单向链表Entry中的元素。
public void remove() {
if (!iterator)
throw new UnsupportedOperationException();
if (lastReturned == null)
throw new IllegalStateException("Hashtable Enumerator");
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
synchronized(Hashtable.this) {
Entry[] tab = Hashtable.this.table;
int index = (lastReturned.hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index], prev = null; e != null;
prev = e, e = e.next) {
if (e == lastReturned) {
modCount++;
expectedModCount++;
if (prev == null)
tab[index] = e.next;
else
prev.next = e.next;
count--;
lastReturned = null;
return;
}
}
throw new ConcurrentModificationException();
}
}
}
entrySet(), keySet(), keys(), values()的实现方法和elements()差不多,而且源码中已经明确的给出了注释。这里就不再做过多说明了。
3.3.5 get()
get() 的作用就是 获取key对应的value,没有的话返回null
public synchronized V get(Object key) {
Entry tab[] = table;
int hash = key.hashCode();
// 计算索引值,
int index = (hash & 0x7FFFFFFF) % tab.length;
// 找到“key对应的Entry(链表)”,然后在链表中找出“哈希值”和“键值”与key都相等的元素
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return e.value;
}
}
return null;
}
3.3.6 put()
put() 的作用是 对外提供接口,让Hashtable对象可以通过put()将“key-value”添加到Hashtable中。
public synchronized V put(K key, V value) {
// Hashtable中不能插入value为null的元素!!!
if (value == null) {
throw new NullPointerException();
}
// 若“Hashtable中已存在键为key的键值对”,
// 则用“新的value”替换“旧的value”
Entry tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
V old = e.value;
e.value = value;
return old;
}
}
// 若“Hashtable中不存在键为key的键值对”,
// (01) 将“修改统计数”+1
modCount++;
// (02) 若“Hashtable实际容量” > “阈值”(阈值=总的容量 * 加载因子)
// 则调整Hashtable的大小
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
index = (hash & 0x7FFFFFFF) % tab.length;
}
// (03) 将“Hashtable中index”位置的Entry(链表)保存到e中
Entry<K,V> e = tab[index];
// (04) 创建“新的Entry节点”,并将“新的Entry”插入“Hashtable的index位置”,并设置e为“新的Entry”的下一个元素(即“新Entry”为链表表头)。
tab[index] = new Entry<K,V>(hash, key, value, e);
// (05) 将“Hashtable的实际容量”+1
count++;
return null;
}
3.3.7 putAll()
putAll() 的作用是将“Map(t)”的中全部元素逐一添加到Hashtable中
public synchronized void putAll(Map<? extends K, ? extends V> t) {
for (Map.Entry<? extends K, ? extends V> e : t.entrySet())
put(e.getKey(), e.getValue());
}
3.3.8 remove()
remove() 的作用就是 删除Hashtable中键为key的元素
public synchronized V remove(Object key) {
Entry tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
// 找到“key对应的Entry(链表)”
// 然后在链表中找出要删除的节点,并删除该节点。
for (Entry<K,V> e = tab[index], prev = null ; e != null ; prev = e, e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
modCount++;
if (prev != null) {
prev.next = e.next;
} else {
tab[index] = e.next;
}
count--;
V oldValue = e.value;
e.value = null;
return oldValue;
}
}
return null;
}
第3.4部分 Hashtable实现的Cloneable接口
Hashtable实现了Cloneable接口,即实现了clone()方法。 clone()方法的作用很简单,就是克隆一个Hashtable对象并返回。
// 克隆一个Hashtable,并以Object的形式返回。
public synchronized Object clone() {
try {
Hashtable<K,V> t = (Hashtable<K,V>) super.clone();
t.table = new Entry[table.length];
for (int i = table.length ; i-- > 0 ; ) {
t.table[i] = (table[i] != null)
? (Entry<K,V>) table[i].clone() : null;
}
t.keySet = null;
t.entrySet = null;
t.values = null;
t.modCount = 0;
return t;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError();
}
}
第3.5部分 Hashtable实现的Serializable接口
Hashtable实现java.io.Serializable,分别实现了串行读取、写入功能。
串行写入函数就是将 Hashtable的“总的容量,实际容量,所有的Entry”都写入到输出流中 串行读取函数: 根据写入方式读出将Hashtable的“总的容量,实际容量,所有的Entry”依次读出
private synchronized void writeObject(java.io.ObjectOutputStream s)
throws IOException
{
// Write out the length, threshold, loadfactor
s.defaultWriteObject();
// Write out length, count of elements and then the key/value objects
s.writeInt(table.length);
s.writeInt(count);
for (int index = table.length-1; index >= 0; index--) {
Entry entry = table[index];
while (entry != null) {
s.writeObject(entry.key);
s.writeObject(entry.value);
entry = entry.next;
}
}
}
private void readObject(java.io.ObjectInputStream s)
throws IOException, ClassNotFoundException
{
// Read in the length, threshold, and loadfactor
s.defaultReadObject();
// Read the original length of the array and number of elements
int origlength = s.readInt();
int elements = s.readInt();
// Compute new size with a bit of room 5% to grow but
// no larger than the original size. Make the length
// odd if it's large enough, this helps distribute the entries.
// Guard against the length ending up zero, that's not valid.
int length = (int)(elements * loadFactor) + (elements / 20) + 3;
if (length > elements && (length & 1) == 0)
length--;
if (origlength > 0 && length > origlength)
length = origlength;
Entry[] table = new Entry[length];
count = 0;
// Read the number of elements and then all the key/value objects
for (; elements > 0; elements--) {
K key = (K)s.readObject();
V value = (V)s.readObject();
// synch could be eliminated for performance
reconstitutionPut(table, key, value);
}
this.table = table;
}
第4部分 Hashtable遍历方式
4.1 遍历Hashtable的键值对
第一步: 根据entrySet()获取Hashtable的“键值对”的Set集合。 第二步: 通过Iterator迭代器遍历“第一步”得到的集合 。
// 假设table是Hashtable对象
// table中的key是String类型,value是Integer类型
Integer integ = null;
Iterator iter = table.entrySet().iterator();
while(iter.hasNext()) {
Map.Entry entry = (Map.Entry)iter.next();
// 获取key
key = (String)entry.getKey();
// 获取value
integ = (Integer)entry.getValue();
}
4.2 通过Iterator遍历Hashtable的键
第一步: 根据keySet()获取Hashtable的“键”的Set集合。 第二步: 通过Iterator迭代器遍历“第一步”得到的集合。
// 假设table是Hashtable对象
// table中的key是String类型,value是Integer类型
String key = null;
Integer integ = null;
Iterator iter = table.keySet().iterator();
while (iter.hasNext()) {
// 获取key
key = (String)iter.next();
// 根据key,获取value
integ = (Integer)table.get(key);
}
4.3 通过Iterator遍历Hashtable的值
第一步: 根据value()获取Hashtable的“值”的集合。 第二步: 通过Iterator迭代器遍历“第一步”得到的集合。
// 假设table是Hashtable对象
// table中的key是String类型,value是Integer类型
Integer value = null;
Collection c = table.values();
Iterator iter= c.iterator();
while (iter.hasNext()) {
value = (Integer)iter.next();
}
4.4 通过Enumeration遍历Hashtable的键
第一步: 根据keys()获取Hashtable的集合。 第二步: 通过Enumeration遍历“第一步”得到的集合。
Enumeration enu = table.keys();
while(enu.hasMoreElements()) {
System.out.println(enu.nextElement());
}
4.5 通过Enumeration遍历Hashtable的值
第一步: 根据elements()获取Hashtable的集合。 第二步: 通过Enumeration遍历“第一步”得到的集合。
Enumeration enu = table.elements();
while(enu.hasMoreElements()) {
System.out.println(enu.nextElement());
}
遍历测试程序如下:
import java.util.*;
/*
* @desc 遍历Hashtable的测试程序。
* (01) 通过entrySet()去遍历key、value,参考实现函数:
* iteratorHashtableByEntryset()
* (02) 通过keySet()去遍历key,参考实现函数:
* iteratorHashtableByKeyset()
* (03) 通过values()去遍历value,参考实现函数:
* iteratorHashtableJustValues()
* (04) 通过Enumeration去遍历key,参考实现函数:
* enumHashtableKey()
* (05) 通过Enumeration去遍历value,参考实现函数:
* enumHashtableValue()
*
* @author skywang
*/
public class HashtableIteratorTest {
public static void main(String[] args) {
int val = 0;
String key = null;
Integer value = null;
Random r = new Random();
Hashtable table = new Hashtable();
for (int i=0; i<12; i++) {
// 随机获取一个[0,100)之间的数字
val = r.nextInt(100);
key = String.valueOf(val);
value = r.nextInt(5);
// 添加到Hashtable中
table.put(key, value);
System.out.println(" key:"+key+" value:"+value);
}
// 通过entrySet()遍历Hashtable的key-value
iteratorHashtableByEntryset(table) ;
// 通过keySet()遍历Hashtable的key-value
iteratorHashtableByKeyset(table) ;
// 单单遍历Hashtable的value
iteratorHashtableJustValues(table);
// 遍历Hashtable的Enumeration的key
enumHashtableKey(table);
// 遍历Hashtable的Enumeration的value
//enumHashtableValue(table);
}
/*
* 通过Enumeration遍历Hashtable的key
* 效率高!
*/
private static void enumHashtableKey(Hashtable table) {
if (table == null)
return ;
System.out.println("/nenumeration Hashtable");
Enumeration enu = table.keys();
while(enu.hasMoreElements()) {
System.out.println(enu.nextElement());
}
}
/*
* 通过Enumeration遍历Hashtable的value
* 效率高!
*/
private static void enumHashtableValue(Hashtable table) {
if (table == null)
return ;
System.out.println("/nenumeration Hashtable");
Enumeration enu = table.elements();
while(enu.hasMoreElements()) {
System.out.println(enu.nextElement());
}
}
/*
* 通过entry set遍历Hashtable
* 效率高!
*/
private static void iteratorHashtableByEntryset(Hashtable table) {
if (table == null)
return ;
System.out.println("/niterator Hashtable By entryset");
String key = null;
Integer integ = null;
Iterator iter = table.entrySet().iterator();
while(iter.hasNext()) {
Map.Entry entry = (Map.Entry)iter.next();
key = (String)entry.getKey();
integ = (Integer)entry.getValue();
System.out.println(key+" -- "+integ.intValue());
}
}
/*
* 通过keyset来遍历Hashtable
* 效率低!
*/
private static void iteratorHashtableByKeyset(Hashtable table) {
if (table == null)
return ;
System.out.println("/niterator Hashtable By keyset");
String key = null;
Integer integ = null;
Iterator iter = table.keySet().iterator();
while (iter.hasNext()) {
key = (String)iter.next();
integ = (Integer)table.get(key);
System.out.println(key+" -- "+integ.intValue());
}
}
/*
* 遍历Hashtable的values
*/
private static void iteratorHashtableJustValues(Hashtable table) {
if (table == null)
return ;
Collection c = table.values();
Iterator iter= c.iterator();
while (iter.hasNext()) {
System.out.println(iter.next());
}
}
}
第5部分 Hashtable示例
下面通过一个实例来学习如何使用Hashtable。
import java.util.*;
/*
* @desc Hashtable的测试程序。
*
* @author skywang
*/
public class HashtableTest {
public static void main(String[] args) {
testHashtableAPIs();
}
private static void testHashtableAPIs() {
// 初始化随机种子
Random r = new Random();
// 新建Hashtable
Hashtable table = new Hashtable();
// 添加操作
table.put("one", r.nextInt(10));
table.put("two", r.nextInt(10));
table.put("three", r.nextInt(10));
// 打印出table
System.out.println("table:"+table );
// 通过Iterator遍历key-value
Iterator iter = table.entrySet().iterator();
while(iter.hasNext()) {
Map.Entry entry = (Map.Entry)iter.next();
System.out.println("next : "+ entry.getKey() +" - "+entry.getValue());
}
// Hashtable的键值对个数
System.out.println("size:"+table.size());
// containsKey(Object key) :是否包含键key
System.out.println("contains key two : "+table.containsKey("two"));
System.out.println("contains key five : "+table.containsKey("five"));
// containsValue(Object value) :是否包含值value
System.out.println("contains value 0 : "+table.containsValue(new Integer(0)));
// remove(Object key) : 删除键key对应的键值对
table.remove("three");
System.out.println("table:"+table );
// clear() : 清空Hashtable
table.clear();
// isEmpty() : Hashtable是否为空
System.out.println((table.isEmpty()?"table is empty":"table is not empty") );
}
}
(某一次)运行结果:
table:{two=5, one=0, three=6}
next : two - 5
next : one - 0
next : three - 6
size:3
contains key two : true
contains key five : false
contains value 0 : true
table:{two=5, one=0}
table is empty
出处:http://www.cnblogs.com/skywang12345/p/3310887.html
文章有不当之处,欢迎指正,你也可以关注我的微信公众号: 好好学java ,获取优质学习资源。
正文到此结束
- 本文标签: 源码 安全 注释 DOM final ACE 本质 测试 cat 时间 遍历 volatile 删除 id synchronized java 线程 代码 解析 参数 http Collection 构造方法 tar 多线程 HTML list 统计 IO equals API App value src 深入解析 索引 https 数据 CTO key dist ORM HashTable mina UI CEO Collections build 微信公众号 HashMap tab map 空间 实例 同步 文章 线程同步
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

