一、运行 Pinpoint 系统
运行 Pinpoint 系统最简单的办法是使用 Docker。
# 运行 Pinpoint
$ git clone https://github.com/dawidmalina/docker-pinpoint
$ cd docker-pinpoint
$ docker-compose up -d
二、编译环境搭建
编译 Pinpoint 1.5.2 的源代码需要 JDK 6、JDK 7+ 以及 Maven 3.2.x+ 的支持,符合以上要求的最新版本的编译工具列表如下:
| 要求 |
最新版本 |
备注 |
| JDK 6 |
JDK 6u45 |
已经停止更新 |
| JDK 7+ |
JDK 8u112 |
|
| Maven 3.2.x+ |
Maven 3.2.9 |
之所以使用 Maven 3.2.x,猜想是因为只有 Maven 3.2.x 才支持 JDK 6 |
并且还要设置两个环境变量:
JAVA_6_HOME 和
JAVA_7_HOME 分别指向对应的 JDK 安装目录,然后运行以下命令完成编译:
# 编译 Pinpoint
$ git clone https://github.com/naver/pinpoint
$ cd pinpoint
$ mvn install -Dmaven.test.skip=true
使用 Docker 来运行编译会更加容易,这免去了环境配置的需要。首先将 Pinpoint 的源代码下载到本地目录,例如
/projects/pinpoint,然后运行命令:
# 使用 Docker 编译 Pinpoint
$ docker run -v /projects/pinpoint:/pinpoint:rw -v </path/to/.m2>:/root/.m2:rw tangrui/pinpoint-development
其中的两个
-v 参数是用来映射目录的。第一个
-v 参数是将本地的
/projects/pinpoint 目录映射到容器的
/pinpoint 目录;而第二个
-v 参数是将本地的 Maven 存储库映射到容器的
/root/.m2 目录,这样做的目的是让本地存储库与 Docker 中的存储库共享内容,避免每次编译的时候都要从网络上下载大量依赖包,提升运行效率。
三、技术概述
3.1、架构组成
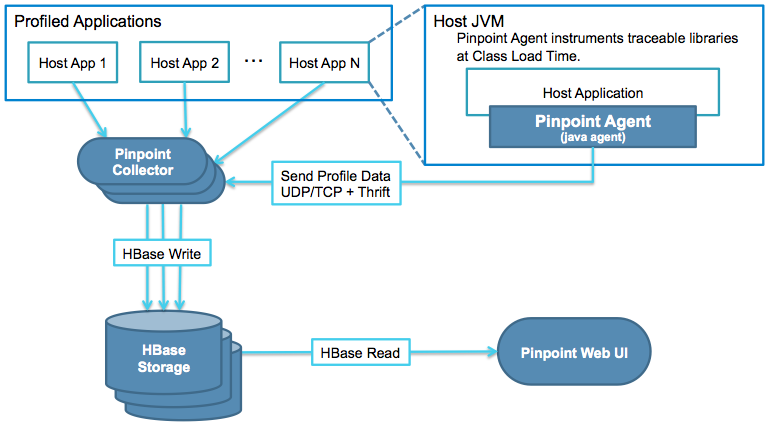
Pinpoint 主要由 3 个组件外加 Hbase 数据库构成,三个组件分别为:Agent、Collector 和 Web UI。
3.2、系统特色
- 分布式交易追踪,追踪分布式系统中穿梭的消息
- 自动侦测应用程序拓扑,以帮助指明应用程序的配置
- 横向扩展以支持大规模的服务器组
- 提供代码级别的可见性,以方便识别故障点和瓶颈
- 使用字节码注入技术,无需修改代码就可以添加新功能
3.3、分布式追踪系统如何工作
无论 Pinpoint 还是 Zipkin,都是基于 Google Dapper 的论文实现的。其核心思想就是在服务各节点彼此调用的时候,记录并传递一个应用级别的标记,这个标记可以用来关联各个服务节点之间的关系。比如两个节点之间使用 HTTP 作为请求协议的话,那么这些标记就会被加入到 HTTP 头中。因此如何传递这些标记是与节点之间使用的通讯协议有关的,有些协议就很容易加入这样的内容,但有些协议就相对困难甚至不可能,因此这一点就直接决定了实现分布式追踪系统的难度。
3.4、Pinpoint 的数据结构
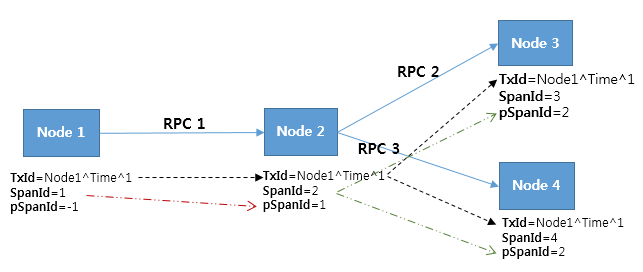
Pinpoint 消息的数据结构主要包含三种类型 Span,Trace 和 TraceId。
Span 是最基本的调用追踪单元,当远程调用到达的时候,Span 指代处理该调用的作业,并且携带追踪数据。为了实现代码级别的可见性,Span 下面还包含一层 SpanEvent 的数据结构。每个 Span 都包含一个 SpanId。
Trace 是一组相互关联的 Span 集合,同一个 Trace 下的 Span 共享一个 TransactionId,而且会按照 SpanId 和 ParentSpanId 排列成一棵有层级关系的树形结构。
TraceId 是 TransactionId、SpanId 和 ParentSpanId 的组合。TransactionId (TxId) 是一个交易下的横跨整个分布式系统收发消息的 ID,其必须在整个服务器组中是全局唯一的。也就是说 TransactionId 识别了整个调用链;SpanId (SpanId) 是处理远程调用作业的 ID,当一个调用到达一个节点的时候随即产生;ParentSpanId (pSpanId) 顾名思义,就是产生当前 Span 的调用方 Span 的 ID。如果一个节点是交易的最初发起方,其 ParentSpanId 是 -1,以标志其是整个交易的根 Span。下图能够比较直观的说明这些 ID 结构之间的关系。
3.5、如何使用 Java Agent
Pinpoint 的优势在于其使用 Java Agent 向节点应用注入字节码,而不是直接修改源代码。因此部署一个节点就变得非常容易,只需要在程序启动的时候加入如下一些启动参数:
# 使用 Java Agent
-javaagent:$AGENT_PATH/pinpoint-bootstrap-$VERSION.jar
-Dpinpoint.agentId=<Agent's UniqueId>
-Dpinpoint.applicationName=<The name indicating a same service (AgentId collection)>
3.6、代码注入是如何工作的
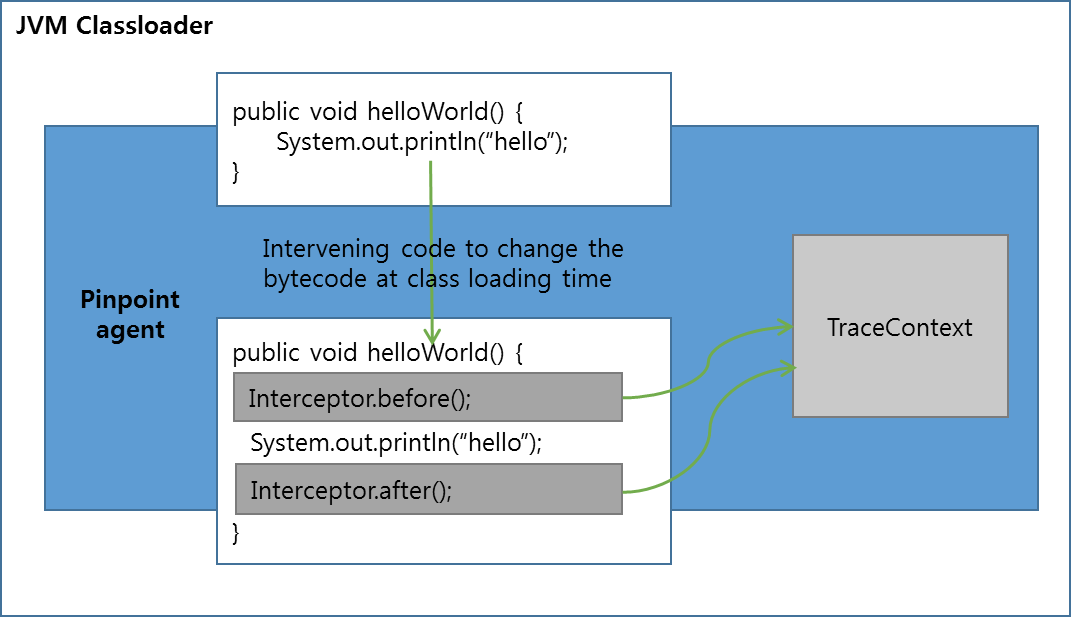
Pinpoint 对代码注入的封装非常类似 AOP,当一个类被加载的时候会通过 Interceptor 向指定的方法前后注入 before 和 after 逻辑,在这些逻辑中可以获取系统运行的状态,并通过 TraceContext 创建 Trace 消息,并发送给 Pinpoint 服务器。但与 AOP 不同的是,Pinpoint 在封装接口的时候考虑到了更多与目标代码的交互能力,因此用 Pinpoint 提供的 API 来编写注入逻辑会比 AOP 看起来更加容易和专业。(这些内容后面会有更详细说明)
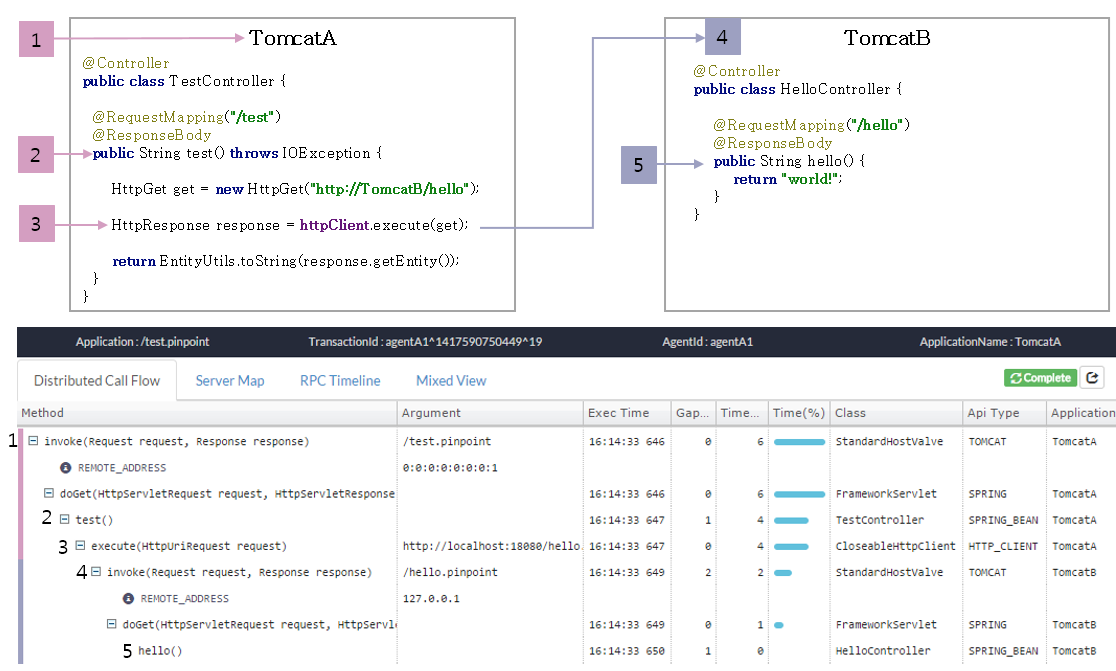
3.7、Pinpoint 的应用实例
下图展现了两个 Tomcat 服务器应用了 Pinpoint 之后,所收集到的追踪数据。
四、Agent 插件开发
开发 Pinpoint Agent 插件只需要关注两个接口:TraceMetadataProvider 和 ProfilerPlugin,实现类通过 Java 的服务发现机制进行加载。
4.1、ServiceLoader 配置
Pinpoint 的插件是以 jar 包的形式部署的,为了使得 Pinpoint Agent 能够定位到 TraceMetadataProvider 和 ProfilerPlugin 两个接口的实现,需要在
META-INF/services 目录下创建两个文件:
META-INF/services/com.navercorp.pinpoint.common.trace.TraceMetadataProvider
META-INF/services/com.navercorp.pinpoint.bootstrap.plugin.ProfilerPlugin
这两个文件中的每一行都写明对应实现类的全名称即可。
TraceMetadataProvider 提供了对 ServiceType 和 AnnotationKey 的管理。
4.2.1、ServiceType
每个 Span 和 SpanEvent 都包含一个 ServiceType,用来标明他们属于哪一个库 (例如 Jetty、MySQL JDBC Client 或者 Apache HTTP Client 等),以及追踪此类型服务的 Span 和 SpanEvent 该如何被处理。ServiceType 的数据结构如下:
| 属性 |
描述 |
| name |
ServiceType 的名称,必须唯一 |
| code |
ServiceType 的编码,短整形,必须唯一 |
| desc |
描述 |
| properties |
附加属性 |
Pinpoint 为了尽量压缩 Agent 到 Collector 数据包的大小,ServiceType 被设计成不是以序列化字符串的形式发送的,而是以整形数字发送的 (code 字段),这就需要建立一个映射关系,将 code 转换成对应的 ServiceType 实例,这个映射机制就是由 TraceMetadataProvider 负责的。
ServiceType 的 code 必须全局唯一,为了避免冲突,Pinpoint 官方对这个映射表进行了严格的管理,如果所开发的插件想要声明新的映射关系,需要通知 Pinpoint 团队,以便对此映射表进行更新和发布。与私有 IP 地址段一样,Pinpoint 团队也保留了一段私有区域可供开发内部服务的时候使用。具体的 ID 范围参照表如下:
ServiceType Code 全部范围
| 类型 |
范围 |
| Internal Use |
0 ~ 999 |
| Server |
1000 ~ 1999 |
| DB Client |
2000 ~ 2999 |
| Cache Client |
8000 ~ 8999 |
| RPC Client |
9000 ~ 9999 |
| Others |
5000 ~ 7999 |
ServiceType Code 私有区域范围
| 类型 |
范围 |
| Server |
1900 ~ 1999 |
| DB Client |
2900 ~ 2999 |
| Cache Client |
8900 ~ 8999 |
| RPC Client |
9900 ~ 9999 |
| Others |
7500 ~ 7999 |
4.2.2、AnnotationKey
Annotation 是包含在 Span 和 SpanEvent 中的更详尽的数据,以键值对的形式存在,键就是 AnnotationKey,值可以是字符串或字节数组。Pinpoint 内置了很多的 AnnotationKey,如果不够用的话也可以通过 TraceMetadataProvider 来自定义。AnnotationKey 的数据结构如下:
| 属性 |
描述 |
| name |
AnnotationKey 的名称 |
| code |
AnnotationKey 的编码,整形,必须唯一 |
| properties |
附加属性 |
同 ServiceType 的 code 字段一样,AnnotationKey 的 code 字段也是全局唯一的,Pinpoint 团队给出的私有区域范围是 900 到 999。
TraceMetadataProvider 接口只有一个 setup 方法,此方法接收一个 TraceMetadataSetupContext 类型的参数,该类型有三个方法:
| 方法 |
描述 |
| addServiceType(ServiceType) |
注册 ServiceType |
| addServiceType(ServiceType, AnnotationKeyMatcher) |
注册 ServiceType,并将匹配 AnnotationKeyMatcher 的 AnnotationKey 作为此 ServiceType 的典型注解,这些典型注解会显示在瀑布视图的 Argument 列中 |
| addAnnotationKey(AnnotationKey) |
注册 AnnotationKey,这里注册的 AnnotationKey 会被标记为 VIEW_IN_RECORD_SET,显示在瀑布视图中是以单独一行显示的,且前面有一个蓝色的 i 图标 |
详细使用方法可以参考官方提供的样例文件
SampleTraceMetadataProvider。
4.3、ProfilerPlugin
ProfilerPlugin 通过字节码注入的方式拦截目标代码以实现跟踪数据的收集。
4.3.1、插件的工作原理
- Pinpoint Agent 随 JVM 一起启动
- Agent 加载所有
plugin 目录下的插件
- Agent 调用每个已经加载的插件的 ProfilerPlugin.setup(ProfilerPluginSetupContext) 方法
- 在 setup 方法中,插件定义那些需要被转换的类,并注册 TransformerCallback
- 目标应用启动
- 当类被加载的时候,Pinpoint Agent 会寻找注册到该类的 TransformerCallback
- 如果 TransformerCallback 被注册,Agent 就调用它的 doInTransform 方法
- TransformerCallback 修改目标类的字节码 (例如添加拦截器、添加字段等)
- 修改后的代码返回到 JVM,类型加载的时候就使用修改后的字节码
- 应用程序继续
- 当调用到被修改的方法的时候,拦截器的 before 和 after 方法被调用
- 拦截器记录追踪数据
Pinpoint 插件的工作原理看似跟 AOP 非常相似,但还是有一些区别和自身特色的:
- 因为 Pinpoint 需要处理的注入场景比较单一,因此他提供的注入 API 相对简单;而 AOP 为了要处理各种可能的切面情况,Pointcut 被设计得非常复杂。
- Pinpoint 插件拦截是通过拦截器的 before 和 after 方法实现的,很像 around 切面,如果不想执行其中某个方法,可以通过 @IgnoreMethod 注解来忽略。
- Pinpoint 的拦截器可以任意拦截方法,因此被拦截的方法之间可能会有调用关系,这会导致追踪数据被重复收集,因此 Pinpoint 提供了 Scope 和 ExecutionPolicy 功能。在一个 Scope 内,可以定义拦截器的执行策略:是每次都执行 (ExecutionPolicy.ALWAYS),还是在没有更外层的拦截器存在的时候执行 (ExecutionPolicy.BOUNDARY),或者必须在有外层拦截器存在的时候执行 (ExecutionPolicy.INTERNAL)。具体请参考这个样例。
- 在一个 Scope 内的拦截器彼此还可以传递数据。同一个 Scope 内的拦截器共享一个 InterceptorScopeInvocation 对象,可以使用该对象来交换数据,请参考样例。
- 除了拦截方法以外,Pinpoint 还可以向目标类中注入字段以及 getter 和 setter 方法,可以使用它们来保存一些上下文的数据。
通过上述内容可以了解,如果要编写一个 Pinpoint 的插件,除了要对目标代码的调用逻辑有较深入的理解,还必须得设计好上下文数据如何存储、如何传递,以及如何通过 Scope 避免信息被重复收集等问题。这些问题在 AOP 的场景下也会存在,只是 Pinpoint 提供了更加一致和便捷的解决方案,而基于 AOP 的实现就要自己去考虑这些问题了。
4.3.2、方法拦截
如前文所述,Pinpoint 插件需要实现 ProfilerPlugin 接口,该接口只有一个 setup(ProfilerPluginSetupContext) 方法。为了更容易的操作 Pinpoint 的代码注入 API,还需要实现一个 TransformTemplateAware 的接口,该接口会注入 TransformTemplate 类。
public class SamplePlugin implements ProfilerPlugin, TransformTemplateAware {
private TransformTemplate transformTemplate;
@Override
public void setup(ProfilerPluginSetupContext context) {
}
@Override
public void setTransformTemplate(TransformTemplate transformTemplate) {
this.transformTemplate = transformTemplate;
}
}
ProfilerPluginSetupContext 有两个方法:getConfig() 和 addApplicationTypeDetector(ApplicationTypeDetector…)。第一个方法用来获取 ProfilerConfig 对象,该对象保存了所有插件的配置信息,而第二个方法用来添加 ApplicationTypeDetector。ApplicationTypeDetector 是用来自动检测节点所运行服务的类型的。例如在 pinpoint-tomcat-plugin 项目中,有 TomcatDetector 类,这个类的作用是通过如下逻辑检测来确定当前服务是否为 Tomcat 的:
- 检查 main class 是不是 org.apache.catalina.startup.Bootstrap
- 检查是否有系统变量 catalina.home
- 检查是否存在某个指定的类 (对于检测 Tomcat 而言,这个特定的类型也是 org.apache.catalina.startup.Bootstrap)
如果以上三个条件都满足,就把当前节点的 ServiceType 设置为 Tomcat。
TransformTemplate 只有一个方法 transform(String, TransformCallback),第一个参数是需要被转换的类的全名称,而第二个参数就是 4.3.1 章节中提到的 TransformCallback 接口,这个接口也只有一个方法叫 doInTransform,所有的注入逻辑都在这里完成。
public byte[] doInTransform(Instrumentor instrumentor,
ClassLoader classLoader,
String className,
Class<?>; classBeingRedefined,
ProtectionDomain protectionDomain,
byte[] classfileBuffer) throws InstrumentException {
// 1. Get InstrumentClass of the target class
InstrumentClass target = instrumentor.getInstrumentClass(classLoader, className, classfileBuffer);
// 2. Get InstrumentMethod of the target method.
InstrumentMethod targetMethod = target.getDeclaredMethod("targetMethod", "java.lang.String");
// 3. Add interceptor. The first argument is FQN of the interceptor class,
// followed by arguments for the interceptor's constructor.
targetMethod.addInterceptor("com.navercorp.pinpoint.bootstrap.interceptor.BasicMethodInterceptor", va(SamplePluginConstants.MY_SERVICE_TYPE));
// 4. Return resulting byte code.
return target.toBytecode();
}
- 注入过程是从获取 InstrumentClass 类开始的。
- 如果想要拦截一个方法,或者是添加字段以及 getter、setter 方法,就可以调用 InstrumentClass 对应的 API 来实现,这里是获取了一个签名为 targetMethod(String) 的方法,返回的对象是 InstrumentMethod 类型。
- 调用 InstrumentMethod 的 addInterceptor 方法注入拦截器,所有跟踪信息的收集行为都是在拦截器中实现的,这里添加的拦截器是 com.navercorp.pinpoint.bootstrap.interceptor.BasicMethodInterceptor,这是 Pinpoint 框架默认提供的一个基本拦截器,里面收集了一些 targetMethod 的调用信息。后面的 va 是一个静态方法 (代表可变参数列表),va 中给出的参数会传递到 BasicMethodInterceptor 的构造方法中。
- 调用 InstrumentClass.toBytecode() 方法即可返回注入后的字节码,剩下的事情就转交给 Pinpoint Agent 自己来完成了。
BasicMethodInterceptor 类仅提供了对方法调用信息的简单收集,只收集方法的名称、参数、返回值以及是否产生异常等等。在某些复杂的场景下,我们会需要收集更多的信息,如当前登录用户、线程池、数据库查询语句以及任何跟中间件功能有关的信息,这就需要我们定义自己的 Interceptor 类。
以上内容请参考该
样例。
Interceptor 是一个标记接口,真正有意义的是 AroundInterceptor 接口,该接口定义了如下两个方法:
public interface AroundInterceptor extends Interceptor {
void before(Object target, Object[] args);
void after(Object target, Object[] args, Object result, Throwable throwable);
}
为了应对被拦截方法的不同个数的参数列表,AroundInterceptor 还有若干子接口:AroundInterceptor0, AroundInterceptor1,…,AroundInterceptor5,分别对应没有参数,一个参数,到 5 个参数的方法。实现 Interceptor 接口的时候要提供一个如下的构造方法:
public RecordArgsAndReturnValueInterceptor(TraceContext traceContext,
MethodDescriptor descriptor) {
this.traceContext = traceContext;
this.descriptor = descriptor;
}
TraceContext 和 MethodDescriptor 会被 Pinpoint Agent 在运行时注入进来,当然也可以添加额外的参数,这些额外的参数,需要在 addInterceptor 的时候指定,就像上文中关于 va 的描述那样。
有了 TraceContext 对象,就可以开始收集信息了。调用 traceContext.getCurrentTraceObject() 方法可以获取当前的 Trace,再调用 trace.traceBlockBegin() 开始记录一个新的 Trace 块 (这里我理解应该就是 Span 了)。在 traceBlockBegin 以后,可以调用 currentSpanEventRecorder 方法获取 SpanEventRecorder 对象,这个对象提供了诸如 recordServiceType、recordApi、recordException 和 recordAttribute 等方法,可以分别记录方法的有关信息。但是 SpanEventRecorder 并没有提供 recordReturnValue 这样的方法,只能通过 recordAttribute 来记录。所有自己扩展的信息也是通过 recordAttribute 来记录的。最后所有信息记录完成就调用 traceBlockEnd() 方法关闭区块。
以上内容请参考该
样例。
五、总结
其实 Pinpint 的插件开发 API 还提供了非常丰富的能力,如拦截异步方法、调用链跟踪、拦截器之间共享数据等等,但原理都是基于上述这些内容,只是调用了更加复杂的 API 而已。具体代码可以参考官方提供的
样例项目,里面有非常详尽的代码及注释,相信理解了上面这些内容,再看这个代码就不会有任何困难了。
















![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

