Java并发指南3:并发三大问题与volatile关键字,CAS操作
01 final class SetCheck {
02 private int a = 0;
03 private long b = 0;
04
05 void set() {
06 a = 1;
07 b = -1;
08 }
09
10 boolean check() {
11 return ((b == 0) ||
12 (b == -1 && a == 1));
13 }
14 }
如果是在一个串行执行的语言中,执行SetCheck类中的check方法永远不会返回false,即使编译器,运行时和计算机硬件并没有按照你所期望的逻辑来处理这段程序,该方法依然不会返回false。在程序执行过程中,下面这些你所不能预料的行为都是可能发生的:
- 编译器可能会进行指令重排序,所以b变量的赋值操作可能先于a变量。如果是一个内联方法,编译器可能更甚一步将该方法的指令与其他语句进行重排序。
- 处理器可能会对语句所对应的机器指令进行重排序之后再执行,甚至并发地去执行。
- 内存系统(由高速缓存控制单元组成)可能会对变量所对应的内存单元的写操作指令进行重排序。重排之后的写操作可能会对其他的计算/内存操作造成覆盖。
- 编译器,处理器以及内存系统可能会让两条语句的机器指令交错。比如在32位机器上,b变量的高位字节先被写入,然后是a变量,紧接着才会是b变量的低位字节。
- 编译器,处理器以及内存系统可能会导致代表两个变量的内存单元在(如果有的话)连续的check调用(如果有的话)之后的某个时刻才更新,而以这种方式保存相应的值(如在CPU寄存器中)仍会得到预期的结果(check永远不会返回false)。
在串行执行的语言中,只要程序执行遵循类似串行的语义,如上几种行为就不会有任何的影响。在一段简单的代码块中,串行执行程序不会依赖于代码的内部执行细节,因此如上的几种行为可以随意控制代码。这样就为编译器和计算机硬件提供了基本的灵活性。基于此,在过去的数十年内很多技术(CPU的流水线操作,多级缓存,读写平衡,寄存器分配等等)应运而生,为计算机处理速度的大幅提升奠定了基础。这些操作的类似串行执行的特性可以让开发人员无须知道其内部发生了什么。对于开发人员来说,如果不创建自己的线程,那么这些行为也不会对其产生任何的影响。
然而这些情况在并发编程中就完全不一样了,上面的代码在并发过程中,当一个线程调用check方法的时候完全有可能另一个线程正在执行set方法,这种情况下check方法就会将上面提到的优化操作过程暴露出来。如果上述任意一个操作发生,那么check方法就有可能返回false。例如,check方法读取long类型的变量b的时候可能得到的既不是0也不是-1.而是一个被写入一半的值。另一种情况,set方法中的语句的乱序执行有可能导致check方法读取变量b的值的时候是-1,然而读取变量a时却依然是0。
换句话说,不仅是并发执行会导致问题,而且在一些优化操作(比如指令重排序)进行之后也会导致代码执行结果和源代码中的逻辑有所出入。由于编译器和运行时技术的日趋成熟以及多处理器的逐渐普及,这种现象就变得越来越普遍。对于那些一直从事串行编程背景的开发人员(其实,基本上所有的程序员)来说,这可能会导致令人诧异的结果,而这些结果可能从没在串行编程中出现过。这可能就是那些微妙难解的并发编程错误的根本源头吧。
在绝大部分的情况下,有一个很简单易行的方法来避免那些在复杂的并发程序中因代码执行优化导致的问题: 使用同步 。例如,如果SetCheck类中所有的方法都被声明为synchronized,那么你就可以确保那么内部处理细节都不会影响代码预期的结果了。
但是在有些情况下你却不能或者不想去使用同步,抑或着你需要推断别人未使用同步的代码。在这些情况下你只能依赖Java内存模型所阐述的结果语义所提供的最小保证。Java内存模型允许上面提到的所有操作,但是限制了它们在执行语义上潜在的结果,此外还提出了一些技术让程序员可以用来控制这些语义的某些方面。
Java内存模型是Java语言规范的一部分,主要在JLS的第17章节介绍。这里,我们只是讨论一些基本的动机,属性以及模型的程序一致性。这里对JLS第一版中所缺少的部分进行了澄清。
我们假设Java内存模型可以被看作在1.2.4中描述的那种标准的SMP机器的理想化模型。
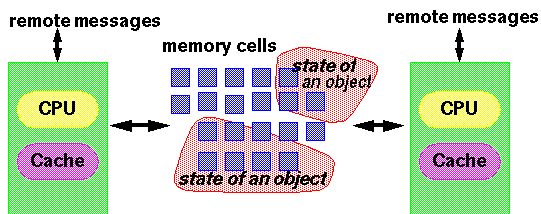
(1.2.4)
在这个模型中, 每一个线程都可以被看作为运行在不同的CPU上,然而即使是在多处理器上,这种情况也是很罕见的 。但是实际上,通过模型所具备的某些特性,这种CPU和线程单一映射能够通过一些合理的方法去实现。例如,因为CPU的寄存器不能被另一个CPU直接访问,这种模型必须考虑到某个线程无法得知被另一个线程操作变量的值的情况。这种情况不仅仅存在于多处理器环境上,在单核CPU环境里,因为编译器和处理器的不可预测的行为也可能导致同样的情况。
Java内存模型没有具体讲述前面讨论的执行策略是由编译器,CPU,缓存控制器还是其它机制促成的。甚至没有用开发人员所熟悉的类,对象及方法来讨论。取而代之,Java内存模型中仅仅定义了线程和内存之间那种抽象的关系。众所周知,每个线程都拥有自己的工作存储单元(缓存和寄存器的抽象)来存储线程当前使用的变量的值。Java内存模型仅仅保证了代码指令与变量操作的有序性,大多数规则都只是指出什么时候变量值应该在内存和线程工作内存之间传输。这些规则主要是为了解决如下三个相互牵连的问题:
- 原子性 :哪些指令必须是不可分割的。在Java内存模型中,这些规则需声明仅适用于-—实例变量和静态变量,也包括数组元素,但不包括方法中的局部变量-—的内存单元的简单读写操作。
- 可见性 :在哪些情况下,一个线程执行的结果对另一个线程是可见的。这里需要关心的结果有,写入的字段以及读取这个字段所看到的值。
- 有序性 :在什么情况下,某个线程的操作结果对其它线程来看是无序的。最主要的乱序执行问题主要表现在读写操作和赋值语句的相互执行顺序上。
原子性
当正确的使用了同步,上面属性都会具有一个简单的特性:一个同步方法或者代码块中所做的修改对于使用了同一个锁的同步方法或代码块都具有原子性和可见性。同步方法或代码块之间的执行过程都会和代码指定的执行顺序保持一致。即使代码块内部指令也许是乱序执行的,也不会对使用了同步的其它线程造成任何影响。
当没有使用同步或者使用的不一致的时候,情况就会变得复杂。Java内存模型所提供的保障要比大多数开发人员所期望的弱,也远不及目前业界所实现的任意一款Java虚拟机。这样,开发人员就必须负起额外的义务去保证对象的一致性关系:对象间若有能被多个线程看到的某种恒定关系,所有依赖这种关系的线程就必须一直维持这种关系,而不仅仅由执行状态修改的线程来维持。
除了long型字段和double型字段外,java内存模型确保访问任意类型字段所对应的内存单元都是原子的。这包括引用其它对象的引用类型的字段。此外,volatile long 和volatile double也具有原子性 。(虽然java内存模型不保证non-volatile long 和 non-volatile double的原子性,当然它们在某些场合也具有原子性。)(译注:non-volatile long在64位JVM,OS,CPU下具有原子性)
当在一个表达式中使用一个non-long或者non-double型字段时,原子性可以确保你将获得这个字段的初始值或者某个线程对这个字段写入之后的值;但不会是两个或更多线程在同一时间对这个字段写入之后产生混乱的结果值(即原子性可以确保,获取到的结果值所对应的所有bit位,全部都是由单个线程写入的)。但是,如下面(译注:指可见性章节)将要看到的,原子性不能确保你获得的是任意线程写入之后的最新值。 因此,原子性保证通常对并发程序设计的影响很小。
可见性
只有在下列情况时,一个线程对字段的修改才能确保对另一个线程可见:
一个写线程释放一个锁之后,另一个读线程随后获取了同一个锁。本质上,线程释放锁时会将强制刷新工作内存中的脏数据到主内存中,获取一个锁将强制线程装载(或重新装载)字段的值。锁提供对一个同步方法或块的互斥性执行,线程执行获取锁和释放锁时,所有对字段的访问的内存效果都是已定义的。
注意同步的双重含义:锁提供高级同步协议,同时在线程执行同步方法或块时,内存系统(有时通过内存屏障指令)保证值的一致性。这说明,与顺序程序设计相比较,并发程序设计与分布式程序设计更加类似。同步的第二个特性可以视为一种机制:一个线程在运行已同步方法时,它将发送和/或接收其他线程在同步方法中对变量所做的修改。从这一点来说,使用锁和发送消息仅仅是语法不同而已。
如果把一个字段声明为volatile型,线程对这个字段写入后,在执行后续的内存访问之前,线程必须刷新这个字段且让这个字段对其他线程可见(即该字段立即刷新)。每次对volatile字段的读访问,都要重新装载字段的值。
一个线程首次访问一个对象的字段,它将读到这个字段的初始值或被某个线程写入后的值。
此外,把还未构造完成的对象的引用暴露给某个线程,这是一个错误的做法 (see ?.1.2)。在构造函数内部开始一个新线程也是危险的,特别是这个类可能被子类化时。Thread.start有如下的内存效果:调用start方法的线程释放了锁,随后开始执行的新线程获取了这个锁。如果在子类构造函数执行之前,可运行的超类调用了new Thread(this).start(),当run方法执行时,对象很可能还没有完全初始化。同样,如果你创建且开始一个新线程T,这个线程使用了在执行start之后才创建的一个对象X。你不能确信X的字段值将能对线程T可见。除非你把所有用到X的引用的方法都同步。如果可行的话,你可以在开始T线程之前创建X。
线程终止时,所有写过的变量值都要刷新到主内存中。比如,一个线程使用Thread.join来终止另一个线程,那么第一个线程肯定能看到第二个线程对变量值得修改。
注意,在同一个线程的不同方法之间传递对象的引用,永远也不会出现内存可见性问题。
内存模型确保上述操作最终会发生,一个线程对一个特定字段的特定更新,最终将会对其他线程可见,但这个“最终”可能是很长一段时间。线程之间没有同步时,很难保证对字段的值能在多线程之间保持一致(指写线程对字段的写入立即能对读线程可见)。特别是,如果字段不是volatile或没有通过同步来访问这个字段,在一个循环中等待其他线程对这个字段的写入,这种情况总是错误的(see ?.2.6)。
在缺乏同步的情况下,模型还允许不一致的可见性。比如,得到一个对象的一个字段的最新值,同时得到这个对象的其他字段的过期的值。同样,可能读到一个引用变量的最新值,但读取到这个引用变量引用的对象的字段的过期值。
不管怎样,线程之间的可见性并不总是失效(指线程即使没有使用同步,仍然有可能读取到字段的最新值),内存模型仅仅是允许这种失效发生而已。因此,即使多个线程之间没有使用同步,也不保证一定会发生内存可见性问题(指线程读取到过期的值),java内存模型仅仅是允许内存可见性问题发生而已。在很多当前的JVM实现和java执行平台中,甚至是在那些使用多处理器的JVM和平台中,也很少出现内存可见性问题。共享同一个CPU的多个线程使用公共的缓存,缺少强大的编译器优化,以及存在强缓存一致性的硬件,这些都会使线程更新后的值能够立即在多线程之间传递。这使得测试基于内存可见性的错误是不切实际的,因为这样的错误极难发生。或者这种错误仅仅在某个你没有使用过的平台上发生,或仅在未来的某个平台上发生。这些类似的解释对于多线程之间的内存可见性问题来说非常普遍。没有同步的并发程序会出现很多问题,包括内存一致性问题。
有序性
有序性规则表现在以下两种场景: 线程内和线程间
- 从某个线程的角度看方法的执行,指令会按照一种叫“串行”(as-if-serial)的方式执行,此种方式已经应用于顺序编程语言。
- 这个线程“观察”到其他线程并发地执行非同步的代码时,任何代码都有可能交叉执行。唯一起作用的约束是:对于同步方法,同步块以及volatile字段的操作仍维持相对有序。
再次提醒,这些仅是最小特性的规则。具体到任何一个程序或平台上,可能存在更严格的有序性规则。所以你不能依赖它们,因为即使你的代码遵循了这些更严格的规则,仍可能在不同特性的JVM上运行失败,而且测试非常困难。
需要注意的是,线程内部的观察视角被JLS _ [1] _中其他的语义的讨论所采用。例如,算术表达式的计算在线程内看来是从左到右地执行操作(JLS 15.6章节),而这种执行效果是没有必要被其他线程观察到的。
仅当某一时刻只有一个线程操作变量时,线程内的执行表现为串行。出现上述情景,可能是因为使用了同步,互斥体 _[2] _ 或者纯属巧合。当多线程同时运行在非同步的代码里进行公用字段的读写时,会形成一种执行模式。在这种模式下,代码会任意交叉执行,原子性和可见性会失效,以及产生竞态条件。这时线程执行不再表现为串行。
尽管JLS列出了一些特定的合法和非法的重排序,如果碰到所列范围之外的问题,会降低以下这条实践保证 :运行结果反映了几乎所有的重排序产生的代码交叉执行的情况。所以,没必要去探究这些代码的有序性。
volatile关键字详解:在JMM中volatile的内存语义是锁
volatile的特性
当我们声明共享变量为volatile后,对这个变量的读/写将会很特别。理解volatile特性的一个好方法是:把对volatile变量的单个读/写,看成是使用同一个监视器锁对这些单个读/写操作做了同步。下面我们通过具体的示例来说明,请看下面的示例代码:
class VolatileFeaturesExample {
volatile long vl = 0L; //使用volatile声明64位的long型变量
public void set(long l) {
vl = l; //单个volatile变量的写
}
public void getAndIncrement () {
vl++; //复合(多个)volatile变量的读/写
}
public long get() {
return vl; //单个volatile变量的读
}
}
假设有多个线程分别调用上面程序的三个方法,这个程序在语意上和下面程序等价:
class VolatileFeaturesExample {
long vl = 0L; // 64位的long型普通变量
public synchronized void set(long l) { //对单个的普通 变量的写用同一个监视器同步
vl = l;
}
public void getAndIncrement () { //普通方法调用
long temp = get(); //调用已同步的读方法
temp += 1L; //普通写操作
set(temp); //调用已同步的写方法
}
public synchronized long get() {
//对单个的普通变量的读用同一个监视器同步
return vl;
}
}
如上面示例程序所示,对一个volatile变量的单个读/写操作,与对一个普通变量的读/写操作使用同一个监视器锁来同步,它们之间的执行效果相同。
监视器锁的happens-before规则保证释放监视器和获取监视器的两个线程之间的内存可见性,这意味着对一个volatile变量的读,总是能看到(任意线程)对这个volatile变量最后的写入。
简而言之,volatile变量自身具有下列特性:监视器锁的语义决定了临界区代码的执行具有原子性。这意味着即使是64位的long型和double型变量,只要它是volatile变量,对该变量的读写就将具有原子性。如果是多个volatile操作或类似于volatile++这种复合操作,这些操作整体上不具有原子性。
- 可见性。对一个volatile变量的读,总是能看到(任意线程)对这个volatile变量最后的写入。
- 原子性:对任意单个volatile变量的读/写具有原子性,但类似于volatile++这种复合操作不具有原子性。
volatile写-读建立的happens before关系
上面讲的是volatile变量自身的特性,对程序员来说,volatile对线程的内存可见性的影响比volatile自身的特性更为重要,也更需要我们去关注。
从JSR-133开始,volatile变量的写-读可以实现线程之间的通信。
从内存语义的角度来说,volatile与监视器锁有相同的效果:volatile写和监视器的释放有相同的内存语义;volatile读与监视器的获取有相同的内存语义。
请看下面使用volatile变量的示例代码:
class VolatileExample {
int a = 0;
volatile boolean flag = false;
public void writer() {
a = 1; //1
flag = true; //2
}
public void reader() {
if (flag) { //3
int i = a; //4
……
}
}
}
假设线程A执行writer()方法之后,线程B执行reader()方法。根据happens before规则,这个过程建立的happens before 关系可以分为两类:
- 根据程序次序规则,1 happens before 2; 3 happens before 4。
- 根据volatile规则,2 happens before 3。
- 根据happens before 的传递性规则,1 happens before 4。
上述happens before 关系的图形化表现形式如下:

在上图中,每一个箭头链接的两个节点,代表了一个happens before 关系。黑色箭头表示程序顺序规则;橙色箭头表示volatile规则;蓝色箭头表示组合这些规则后提供的happens before保证。
这里A线程写一个volatile变量后,B线程读同一个volatile变量。A线程在写volatile变量之前所有可见的共享变量,在B线程读同一个volatile变量后,将立即变得对B线程可见。
volatile写-读的内存语义
volatile写的内存语义如下:
- 当写一个volatile变量时,JMM会把该线程对应的本地内存中的共享变量刷新到主内存。
以上面示例程序VolatileExample为例,假设线程A首先执行writer()方法,随后线程B执行reader()方法,初始时两个线程的本地内存中的flag和a都是初始状态。下图是线程A执行volatile写后,共享变量的状态示意图:

如上图所示,线程A在写flag变量后,本地内存A中被线程A更新过的两个共享变量的值被刷新到主内存中。此时,本地内存A和主内存中的共享变量的值是一致的。
volatile读的内存语义如下:
- 当读一个volatile变量时,JMM会把该线程对应的本地内存置为无效。线程接下来将从主内存中读取共享变量。
下面是线程B读同一个volatile变量后,共享变量的状态示意图:

如上图所示,在读flag变量后,本地内存B已经被置为无效。此时,线程B必须从主内存中读取共享变量。线程B的读取操作将导致本地内存B与主内存中的共享变量的值也变成一致的了。
如果我们把volatile写和volatile读这两个步骤综合起来看的话,在读线程B读一个volatile变量后,写线程A在写这个volatile变量之前所有可见的共享变量的值都将立即变得对读线程B可见。
下面对volatile写和volatile读的内存语义做个总结:
- 线程A写一个volatile变量,实质上是线程A向接下来将要读这个volatile变量的某个线程发出了(其对共享变量所在修改的)消息。
- 线程B读一个volatile变量,实质上是线程B接收了之前某个线程发出的(在写这个volatile变量之前对共享变量所做修改的)消息。
- 线程A写一个volatile变量,随后线程B读这个volatile变量,这个过程实质上是线程A通过主内存向线程B发送消息。
volatile内存语义的实现
下面,让我们来看看JMM如何实现volatile写/读的内存语义。
前文我们提到过重排序分为编译器重排序和处理器重排序。为了实现volatile内存语义,JMM会分别限制这两种类型的重排序类型。下面是JMM针对编译器制定的volatile重排序规则表:
| 是否能重排序 | 第二个操作 | ||
|---|---|---|---|
| 第一个操作 | 普通读/写 | volatile读 | volatile写 |
| 普通读/写 | NO | ||
| volatile读 | NO | NO | NO |
| volatile写 | NO | NO |
举例来说,第三行最后一个单元格的意思是:在程序顺序中,当第一个操作为普通变量的读或写时,如果第二个操作为volatile写,则编译器不能重排序这两个操作。
从上表我们可以看出:
- 当第二个操作是volatile写时,不管第一个操作是什么,都不能重排序。这个规则确保volatile写之前的操作不会被编译器重排序到volatile写之后。
- 当第一个操作是volatile读时,不管第二个操作是什么,都不能重排序。这个规则确保volatile读之后的操作不会被编译器重排序到volatile读之前。
- 当第一个操作是volatile写,第二个操作是volatile读时,不能重排序。
为了实现volatile的内存语义,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。对于编译器来说,发现一个最优布置来最小化插入屏障的总数几乎不可能,为此,JMM采取保守策略。下面是基于保守策略的JMM内存屏障插入策略:
- 在每个volatile写操作的前面插入一个StoreStore屏障。
- 在每个volatile写操作的后面插入一个StoreLoad屏障。
- 在每个volatile读操作的后面插入一个LoadLoad屏障。
- 在每个volatile读操作的后面插入一个LoadStore屏障。
上述内存屏障插入策略非常保守,但它可以保证在任意处理器平台,任意的程序中都能得到正确的volatile内存语义。
下面是保守策略下,volatile写插入内存屏障后生成的指令序列示意图:

上图中的StoreStore屏障可以保证在volatile写之前,其前面的所有普通写操作已经对任意处理器可见了。这是因为StoreStore屏障将保障上面所有的普通写在volatile写之前刷新到主内存。
这里比较有意思的是volatile写后面的StoreLoad屏障。这个屏障的作用是避免volatile写与后面可能有的volatile读/写操作重排序。因为编译器常常无法准确判断在一个volatile写的后面,是否需要插入一个StoreLoad屏障(比如,一个volatile写之后方法立即return)。为了保证能正确实现volatile的内存语义,JMM在这里采取了保守策略:在每个volatile写的后面或在每个volatile读的前面插入一个StoreLoad屏障。从整体执行效率的角度考虑,JMM选择了在每个volatile写的后面插入一个StoreLoad屏障。因为volatile写-读内存语义的常见使用模式是:一个写线程写volatile变量,多个读线程读同一个volatile变量。当读线程的数量大大超过写线程时,选择在volatile写之后插入StoreLoad屏障将带来可观的执行效率的提升。从这里我们可以看到JMM在实现上的一个特点:首先确保正确性,然后再去追求执行效率。
下面是在保守策略下,volatile读插入内存屏障后生成的指令序列示意图:

上图中的LoadLoad屏障用来禁止处理器把上面的volatile读与下面的普通读重排序。LoadStore屏障用来禁止处理器把上面的volatile读与下面的普通写重排序。
上述volatile写和volatile读的内存屏障插入策略非常保守。在实际执行时,只要不改变volatile写-读的内存语义,编译器可以根据具体情况省略不必要的屏障。下面我们通过具体的示例代码来说明:
class VolatileBarrierExample {
int a;
volatile int v1 = 1;
volatile int v2 = 2;
void readAndWrite() {
int i = v1; //第一个volatile读
int j = v2; // 第二个volatile读
a = i + j; //普通写
v1 = i + 1; // 第一个volatile写
v2 = j * 2; //第二个 volatile写
}
… //其他方法
}
针对readAndWrite()方法,编译器在生成字节码时可以做如下的优化:

注意,最后的StoreLoad屏障不能省略。因为第二个volatile写之后,方法立即return。此时编译器可能无法准确断定后面是否会有volatile读或写,为了安全起见,编译器常常会在这里插入一个StoreLoad屏障。
上面的优化是针对任意处理器平台,由于不同的处理器有不同“松紧度”的处理器内存模型,内存屏障的插入还可以根据具体的处理器内存模型继续优化。以x86处理器为例,上图中除最后的StoreLoad屏障外,其它的屏障都会被省略。
前面保守策略下的volatile读和写,在 x86处理器平台可以优化成:

前文提到过,x86处理器仅会对写-读操作做重排序。X86不会对读-读,读-写和写-写操作做重排序,因此在x86处理器中会省略掉这三种操作类型对应的内存屏障。在x86中,JMM仅需在volatile写后面插入一个StoreLoad屏障即可正确实现volatile写-读的内存语义。这意味着在x86处理器中,volatile写的开销比volatile读的开销会大很多(因为执行StoreLoad屏障开销会比较大)。
JSR-133为什么要增强volatile的内存语义
在JSR-133之前的旧Java内存模型中,虽然不允许volatile变量之间重排序,但旧的Java内存模型允许volatile变量与普通变量之间重排序。在旧的内存模型中,VolatileExample示例程序可能被重排序成下列时序来执行:

在旧的内存模型中,当1和2之间没有数据依赖关系时,1和2之间就可能被重排序(3和4类似)。其结果就是:读线程B执行4时,不一定能看到写线程A在执行1时对共享变量的修改。
因此在旧的内存模型中 ,volatile的写-读没有监视器的释放-获所具有的内存语义。为了提供一种比监视器锁更轻量级的线程之间通信的机制,JSR-133专家组决定增强volatile的内存语义:严格限制编译器和处理器对volatile变量与普通变量的重排序,确保volatile的写-读和监视器的释放-获取一样,具有相同的内存语义。从编译器重排序规则和处理器内存屏障插入策略来看,只要volatile变量与普通变量之间的重排序可能会破坏volatile的内存语意,这种重排序就会被编译器重排序规则和处理器内存屏障插入策略禁止。
由于volatile仅仅保证对单个volatile变量的读/写具有原子性,而监视器锁的互斥执行的特性可以确保对整个临界区代码的执行具有原子性。在功能上,监视器锁比volatile更强大;在可伸缩性和执行性能上,volatile更有优势。如果读者想在程序中用volatile代替监视器锁,请一定谨慎。
CAS操作详解
本文属于作者原创,原文发表于InfoQ: http://www.infoq.com/cn/articles/atomic-operation
引言
原子(atom)本意是“不能被进一步分割的最小粒子”,而原子操作(atomic operation)意为”不可被中断的一个或一系列操作” 。在多处理器上实现原子操作就变得有点复杂。本文让我们一起来聊一聊在Inter处理器和Java里是如何实现原子操作的。
术语定义
| 术语名称 | 英文 | 解释 |
|---|---|---|
| 缓存行 | Cache line | 缓存的最小操作单位 |
| 比较并交换 | Compare and Swap | CAS操作需要输入两个数值,一个旧值(期望操作前的值)和一个新值,在操作期间先 比较 下在旧值有没有发生变化,如果没有发生变化,才 交换 成新值,发生了变化则不交换。 |
| CPU流水线 | CPU pipeline | CPU流水线的工作方式就象工业生产上的装配流水线,在CPU中由5~6个不同功能的电路单元组成一条指令处理流水线,然后将一条X86指令分成5~6步后再由这些电路单元分别执行,这样就能实现在一个CPU时钟周期完成一条指令,因此提高CPU的运算速度。 |
| 内存顺序冲突 | Memory order violation | 内存顺序冲突一般是由假共享引起,假共享是指多个CPU同时修改同一个缓存行的不同部分而引起其中一个CPU的操作无效,当出现这个内存顺序冲突时,CPU必须清空流水线。 |
处理器如何实现原子操作
32位IA-32处理器使用 基于对缓存加锁或总线加锁 的方式来实现多处理器之间的原子操作。
处理器自动保证基本内存操作的原子性
首先处理器会自动保证基本的内存操作的原子性。处理器保证从系统内存当中读取或者写入一个字节是原子的,意思是当一个处理器读取一个字节时,其他处理器不能访问这个字节的内存地址。奔腾6和最新的处理器能自动保证单处理器对同一个缓存行里进行16/32/64位的操作是原子的,但是复杂的内存操作处理器不能自动保证其原子性,比如跨总线宽度,跨多个缓存行,跨页表的访问。但是处理器提供总线锁定和缓存锁定两个机制来保证复杂内存操作的原子性。
使用总线锁保证原子性
第一个机制是通过总线锁保证原子性。如果多个处理器同时对共享变量进行读改写(i++就是经典的读改写操作)操作,那么共享变量就会被多个处理器同时进行操作,这样读改写操作就不是原子的,操作完之后共享变量的值会和期望的不一致,举个例子:如果i=1,我们进行两次i++操作,我们期望的结果是3,但是有可能结果是2。如下图
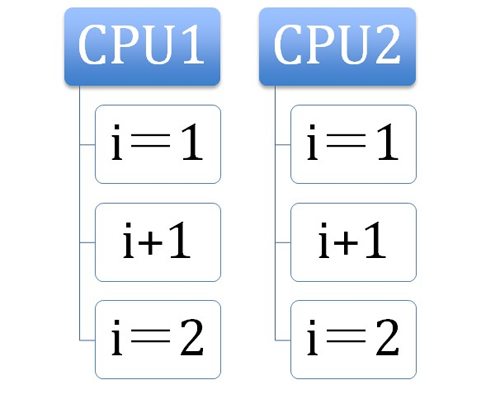
(例1)
原因是有可能多个处理器同时从各自的缓存中读取变量i,分别进行加一操作,然后分别写入系统内存当中。那么想要保证读改写共享变量的操作是原子的,就必须保证CPU1读改写共享变量的时候,CPU2不能操作缓存了该共享变量内存地址的缓存。
处理器使用总线锁就是来解决这个问题的。所谓总线锁就是使用处理器提供的一个LOCK#信号,当一个处理器在总线上输出此信号时,其他处理器的请求将被阻塞住,那么该处理器可以独占使用共享内存。
使用缓存锁保证原子性
第二个机制是通过缓存锁定保证原子性。在同一时刻我们只需保证对某个内存地址的操作是原子性即可,但总线锁定把CPU和内存之间通信锁住了,这使得锁定期间,其他处理器不能操作其他内存地址的数据,所以总线锁定的开销比较大,最近的处理器在某些场合下使用缓存锁定代替总线锁定来进行优化。
频繁使用的内存会缓存在处理器的L1,L2和L3高速缓存里,那么原子操作就可以直接在处理器内部缓存中进行,并不需要声明总线锁,在奔腾6和最近的处理器中可以使用“缓存锁定”的方式来实现复杂的原子性。所谓“缓存锁定”就是如果缓存在处理器缓存行中内存区域在LOCK操作期间被锁定,当它执行锁操作回写内存时,处理器不在总线上声言LOCK#信号,而是修改内部的内存地址,并允许它的缓存一致性机制来保证操作的原子性,因为缓存一致性机制会阻止同时修改被两个以上处理器缓存的内存区域数据,当其他处理器回写已被锁定的缓存行的数据时会起缓存行无效,在例1中,当CPU1修改缓存行中的i时使用缓存锁定,那么CPU2就不能同时缓存了i的缓存行。
但是有两种情况下处理器不会使用缓存锁定。第一种情况是:当操作的数据不能被缓存在处理器内部,或操作的数据跨多个缓存行(cache line),则处理器会调用总线锁定。第二种情况是:有些处理器不支持缓存锁定。对于Inter486和奔腾处理器,就算锁定的内存区域在处理器的缓存行中也会调用总线锁定。
以上两个机制我们可以通过Inter处理器提供了很多LOCK前缀的指令来实现。比如位测试和修改指令BTS,BTR,BTC,交换指令XADD,CMPXCHG和其他一些操作数和逻辑指令,比如ADD(加),OR(或)等,被这些指令操作的内存区域就会加锁,导致其他处理器不能同时访问它。
JAVA如何实现原子操作
在java中可以通过 锁 和 循环CAS 的方式来实现原子操作。
使用循环CAS实现原子操作
JVM中的CAS操作正是利用了上一节中提到的处理器提供的CMPXCHG指令实现的。自旋CAS实现的基本思路就是循环进行CAS操作直到成功为止,以下代码实现了一个基于CAS线程安全的计数器方法safeCount和一个非线程安全的计数器count。
001 private AtomicInteger atomicI = newAtomicInteger(0);
002
003 private int i = 0;
004
005 public static void main(String[] args) {
006
007 final Counter cas = new Counter();
008
009 List<Thread> ts = new ArrayList<Thread>(600);
010
011 long start = System.currentTimeMillis();
012
013 for (int j = 0; j < 100; j++) {
014
015 Thread t = new Thread(new Runnable() {
016
017 @Override
018
019 public void run() {
020
021 for (int i = 0; i < 10000; i++) {
022
023 cas.count();
024
025 cas.safeCount();
026
027 }
028
029 }
030
031 });
032
033 ts.add(t);
034
035 }
036
037 for (Thread t : ts) {
038
039 t.start();
040
041 }
042
043 // 等待所有线程执行完成
044
045 for (Thread t : ts) {
046
047 try {
048
049 t.join();
050
051 } catch (InterruptedException e) {
052
053 e.printStackTrace();
054
055 }
056
057 }
058
059 System.out.println(cas.i);
060
061 System.out.println(cas.atomicI.get());
062
063 System.out.println(System.currentTimeMillis() - start);
064
065 }
066
067 /**
068
069 * 使用CAS实现线程安全计数器
070
071 */
072
073 private void safeCount() {
074
075 for (;;) {
076
077 int i = atomicI.get();
078
079 boolean suc = atomicI.compareAndSet(i, ++i);
080
081 if (suc) {
082
083 break;
084
085 }
086
087 }
088
089 }
090
091 /**
092
093 * 非线程安全计数器
094
095 */
096
097 private void count() {
098
099 i++;
100
101 }
102
103 }
从Java1.5开始JDK的并发包里提供了一些类来支持原子操作,如 AtomicBoolean (用原子方式更新的 boolean 值), AtomicInteger (用原子方式更新的 int 值), AtomicLong (用原子方式更新的 long 值),这些原子包装类还提供了有用的工具方法,比如以原子的方式将当前值自增1和自减1。
在Java并发包中有一些并发框架也使用了自旋CAS的方式来实现原子操作,比如LinkedTransferQueue类的Xfer方法。CAS虽然很高效的解决原子操作,但是CAS仍然存在三大问题。ABA问题,循环时间长开销大和只能保证一个共享变量的原子操作。
- ABA问题 。因为CAS需要在操作值的时候检查下值有没有发生变化,如果没有发生变化则更新,但是如果一个值原来是A,变成了B,又变成了A,那么使用CAS进行检查时会发现它的值没有发生变化,但是实际上却变化了。ABA问题的解决思路就是使用版本号。在变量前面追加上版本号,每次变量更新的时候把版本号加一,那么A-B-A 就会变成1A-2B-3A。
从Java1.5开始JDK的atomic包里提供了一个类AtomicStampedReference来解决ABA问题。这个类的compareAndSet方法作用是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
1 public boolean compareAndSet( 2 V expectedReference,//预期引用 3 4 V newReference,//更新后的引用 5 6 int expectedStamp, //预期标志 7 8 int newStamp //更新后的标志 9 )
- 循环时间长开销大 。自旋CAS如果长时间不成功,会给CPU带来非常大的执行开销。如果JVM能支持处理器提供的pause指令那么效率会有一定的提升,pause指令有两个作用,第一它可以延迟流水线执行指令(de-pipeline),使CPU不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零。第二它可以避免在退出循环的时候因内存顺序冲突(memory order violation)而引起CPU流水线被清空(CPU pipeline flush),从而提高CPU的执行效率。
- 只能保证一个共享变量的原子操作 。当对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子操作,但是对多个共享变量操作时,循环CAS就无法保证操作的原子性,这个时候就可以用锁,或者有一个取巧的办法,就是把多个共享变量合并成一个共享变量来操作。比如有两个共享变量i=2,j=a,合并一下ij=2a,然后用CAS来操作ij。从Java1.5开始JDK提供了 AtomicReference类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行CAS操作。
正文到此结束
- 本文标签: IO JVM git 安全 时间 并发编程 src cache ArrayList ip cat 代码 Java内存模型 example 处理器 本质 tab 线程 GitHub 开发 同步 Atom 一致性 测试 swap 内存模型 REST 总结 Features 模型 协议 tar 多线程 list final queue 分布式 缓存 编译 IDE 实例 锁 ACE id synchronized java js 数据 程序员 volatile http 十年 字节码 https UI App 重排序
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

