从并发编程到分布式系统-如何处理海量数据(上)
面试互联网公司不得不说的高并发!
在这里想写写自己在学习并发处理的学习思路,也会聊聊自己遇到的那些坑,以此为记,希望鞭策自己不断学习、永不放弃!
具体笔者认为大体可分为分两部分:
第一部分:Java多线程编程。
第二部分:高并发的解决思路。
第三部分:分布式架构中redis、zookeeper分布式锁的应用。
本文着重讲解第一块。
1、Java内存模型与线程。
并发编程主要讨论以下几点:多个线程操作相同资源,保证线程安全,合理使用资源。
通常我们可以将物理计算机中出现的并发问题类比到JVM中的并发。
物理计算机处理器、高速缓存、主内存间交互关系如图:
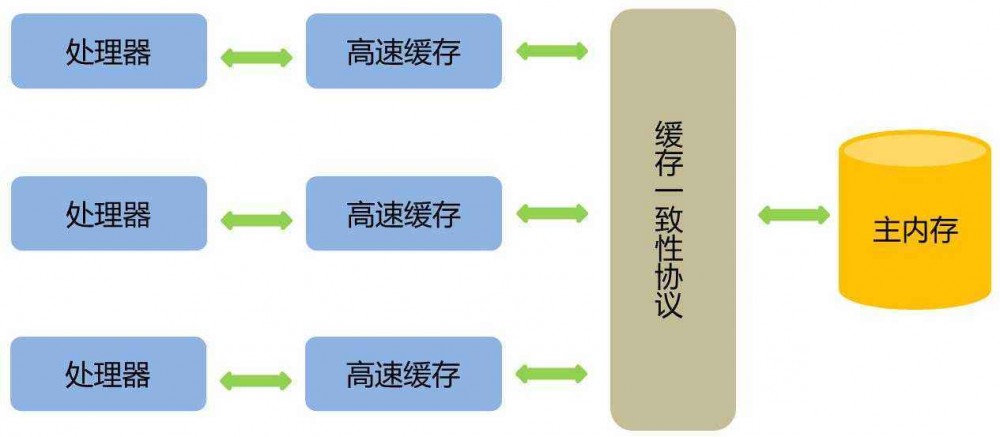
处理器和内存的运行速度存在几个数量级别的差距,因此为解决此矛盾引入了告诉缓存这一概念。当多个处理器的运行任务都涉及到同一块主内存区域时,将可能导致各自缓存数据的不一致问题,为解决一致性问题,需要各个处理器访问缓存时都遵循一些协议,在读写时要根据协议来进行操作。(MSI、MESI、MOSI、Synapse、Firefly及Dragon Protocol等)
处理器为提高性能,会对输入代码乱序执行(Out-Of-Order Execution) 优化。
类比Java内存模型,线程、主内存、工作内存交互关系如图:

JMM定义程序中各个变量访问规则,即在虚拟机中将内存取出和存储的底层细节。
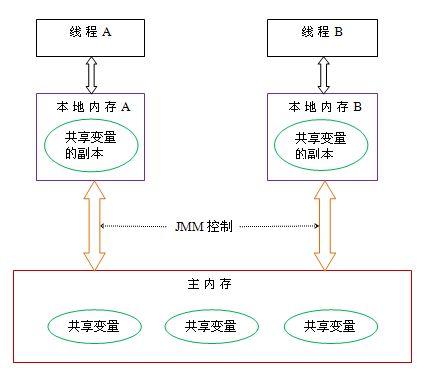
线程A如果要跟线程B要通信的话,必须经历以下两个步骤: 1)线程A把本地内存A中更新过的共享变量的值刷新到主内存中。 2)线程B去主内存中读取A更新过的共享变量的值。
线程的工作内存中保存了该线程使用到变量的主内存副本拷贝(也可理解为此线程的私有拷贝),线程对变量的操作(读取、赋值等)都在工作内存中进行,而不能直接读写主内存中变量。不同线程之间的通信业需要通过主内存来完成。 主内存对应Java堆中对象实例数据部分,而工作内存则对应虚拟机栈中部分区域。
在此还有一个需要提及的点!
指令重排序
执行程序时,为提高性能,编译器和处理器常常会对指令做出重排序。分三种:
1)编译器优化的重排序。
2)指令并行重排序。
3)内存系统重排序。
JMM的编译器会禁止特定类型的编译器重排序,对于处理器重排序(后两者),则要求Java编译器在生成指令序列时,插入特定类型的内存屏障指令,通过内存屏障指令来禁止特定类型的处理器重排序。
内存之间的交互操作
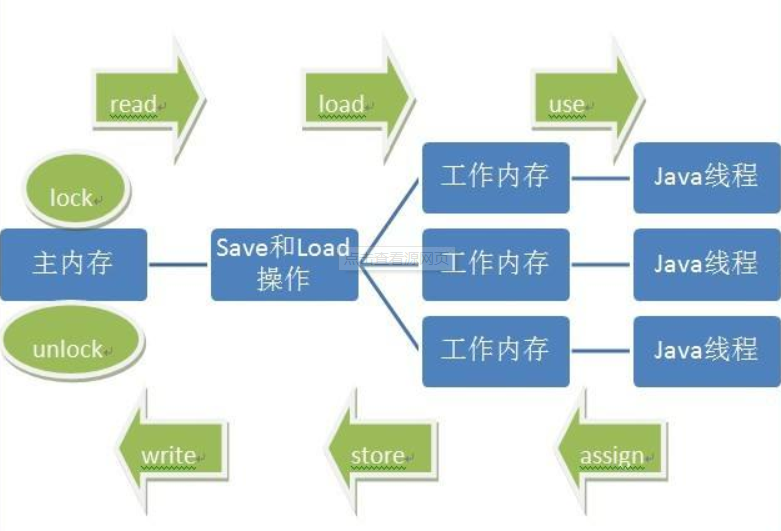
JMM中定义了8种操作来来描述工作内存与主内存之间的实现细节。
- lock(锁定):作用于主内存的变量,它把一个变量标识为一条线程独占状态。
- unlock(解锁):作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。
- read(读取):作用于主内存的变量,它把一个变量从主内存传输到线程工作内存中,以便后边的load操作。
- load(载入):作用于主内存的变量,它把read操作从主内存中得到的变量值放到工作内存副本中。
- use(使用):作用于工作内存的变量,它把工作内存中一个变量的值传递给执行引擎,每当虚拟机遇到一个需要使用到变量的值的字节码指令时将会执行这个操作。
- assign(赋值):作用于工作内存的变量,它把从执行引擎接收到的值赋给工作内存,每当虚拟机遇到一个给变量赋值的字节码指令时执行此操作。
- store(存储):作用于工作内存的变量,它把工作内存的变量的值传送到主内存中,以便以后的write操作使用。
- write(写入):作用于主内存的变量,它把store操纵从工作内存中得到的变量值放入到主内存的变量中。
JMM规定了执行上述八种操作时必须满足的规则(与happens-before原则是等效的,即先行发生原则):
- 不允许read和load、store和write操作之一单独出现
- 不允许一个线程丢弃它的最近assign的操作,即变量在工作内存中改变了之后必须同步到主内存中。
- 不允许一个线程无原因地(没有发生过任何assign操作)把数据从工作内存同步回主内存中。
- 一个新的变量只能在主内存中诞生,不允许在工作内存中直接使用一个未被初始化(load或assign)的变量。即就是对一个变量实施use和store操作之前,必须先执行过了assign和load操作。
- 一个变量在同一时刻只允许一条线程对其进行lock操作,lock和unlock必须成对出现。
- 如果对一个变量执行lock操作,将会清空工作内存中此变量的值,在执行引擎使用这个变量前需要重新执行load或assign操作初始化变量的值。
- 如果一个变量事先没有被lock操作锁定,则不允许对它执行unlock操作;也不允许去unlock一个被其他线程锁定的变量。
- 对一个变量执行unlock操作之前,必须先把此变量同步到主内存中(执行store和write操作)。
补充:JVM-攻城掠地
2、测试工具
PostMan、Apache Bench、JMeter、LoadRunner
3、线程安全性
原子性:提供了互斥访问,同一时刻只能由一个线程来对它进行操作。
可见性:一个线程对主内存的修改可以及时被其他线程观察到。
有序性:一个线程观察其它线程中指令执行顺序,由于指令重排序的存在,该观察的结果一般为杂乱无章的。 (happens-before原则) Java程序的天然有序性可以总结为:如果本线程内观察,所有的操作都是有序的;如果在一个线程观察另一个线程,所有的操作都是无须的。前者指的是线程内的串行语义,后者指的是指令重排序和工作内存和主内存同步延迟现象。
原子性-Atomic包
- AtomicXXX:CAS、Unsafe.compareAndSwapInt
通过CAS来保证原子性,即Compare And Swap 比较交换:
CAS利用处理器提供的CMPXCHG指令实现,自旋CAS实现的基本思路就是循环进行CAS直到成功为止。 比较内存的值与预期的值,若相同则修改预期的值。
CAS虽然可以进行高效的进行源自操作,但是CAS仍在存在三大问题。
- ABA问题。 在Java1.5开始,JDK的Atomic包里提供了一个类AtomicStampedReference来解决ABA问题。 大部分情况下ABA问题并不影响程序并发的正确性,如果需要解决ABA问题,改用传统的互斥同步可能会比原子类更加高效。
- 循环时间长开销大,
- 以及只能保证一个共享变量进行的原子操作。
测试:
public class AtomicExample1 {
// 请求总数
public static int clientTotal = 5000;
// 同时并发执行的线程数
public static int threadTotal = 200;
public static AtomicInteger count = new AtomicInteger(0);
public static void main(String[] args) throws Exception {
ExecutorService executorService = Executors.newCachedThreadPool();
final Semaphore semaphore = new Semaphore(threadTotal);
final CountDownLatch countDownLatch = new CountDownLatch(clientTotal);
for (int i = 0; i < clientTotal ; i++) {
executorService.execute(() -> {
try {
semaphore.acquire();
add();
semaphore.release();
} catch (Exception e) {
log.error("exception", e);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
log.info("count:{}", count.get());
}
private static void add() {
count.incrementAndGet();
// count.getAndIncrement();
}
}
AtomicInteger
源码实现
public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
//当前的指为var2,底层穿过来的值var5 如果当前的值与底层传过来的值一样的话,则将其更新问var5+var4
AtomicLong与LongAdder
- Java内存模型要求lock、unlock、read、load、assign、use、store、write这8个操作都是具有原子性,但是对于64位的数据类型(long、double),允许虚拟机将没有被volatile修饰的64位数据的读写操作划分为两次32位的操作来进行,即允许虚拟机实现选择可以不保证64位数据类型的load、store、read和write这四个原子操作,但是可以视为原子性操作。
- LongAdder实现热点数据的分离,更快,如果有并发更新可能会出现误差。
- AtomicLong CAS中如果并发量大,则会不断进行循环调用,效率会比较低。
底层用数组实现,其结果为数组的求和累加。
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
if ((as = cells) != null || !casBase(b = base, b + x)) {
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x)))
longAccumulate(x, null, uncontended);
}
}
/**
* Equivalent to {@code add(1)}.
*/
public void increment() {
add(1L);
}
AtomicBoolean
- 希望某件事情只执行一次。
public final boolean compareAndSet(boolean expect, boolean update) {
int e = expect ? 1 : 0;
int u = update ? 1 : 0;
return unsafe.compareAndSwapInt(this, valueOffset, e, u);
}
AtomicReference
public final V getAndSet(V newValue) {
return (V)unsafe.getAndSetObject(this, valueOffset, newValue);
}
public final Object getAndSetObject(Object var1, long var2, Object var4) {
Object var5;
do {
var5 = this.getObjectVolatile(var1, var2);
} while(!this.compareAndSwapObject(var1, var2, var5, var4));
return var5;
}
AtomicIntegerFieldUpdater
- 以原子性更新类中某一个属性,这属性需要用volatile进行修饰。
public class AtomicExample5 {
private static AtomicIntegerFieldUpdater<AtomicExample5> updater =
AtomicIntegerFieldUpdater.newUpdater(AtomicExample5.class, "count");
@Getter
public volatile int count = 100;
public static void main(String[] args) {
AtomicExample5 example5 = new AtomicExample5();
if (updater.compareAndSet(example5, 100, 120)) {
log.info("update success 1, {}", example5.getCount());
}
if (updater.compareAndSet(example5, 100, 120)) {
log.info("update success 2, {}", example5.getCount());
} else {
log.info("update failed, {}", example5.getCount());
}
}
}
AtomicStampedReference
- 作用是首先检查当前引用是否等于预期引用,并且检查当前标志是否等于预期标志,如果全部相等,则以原子的方式将该引用和该标志的值设置为给定的更新值。
public boolean compareAndSet(V expectedReference,
V newReference,
int expectedStamp,
int newStamp) {
Pair<V> current = pair;
return
expectedReference == current.reference &&
expectedStamp == current.stamp &&
((newReference == current.reference &&
newStamp == current.stamp) ||
casPair(current, Pair.of(newReference, newStamp)));
}
AtomicLongArray 维护数组
原子性-锁及对比
- synchronized:依赖JVM,不可中断锁,适合竞争不激烈,可读性号。
- Lock:依赖特殊的CPU指令,代码实现,ReentrantLock。可中断锁,多样化同步,竞争激烈的时候能维持常态。
- Atomic:竞争激烈的时候能维持常态,比Lock性能更好,只能同步一个值。
线程安全-可见性
导致共享变量在线程间不可见的原因
1)线程交叉执行。
2)重排序结合线程交叉执行。
3)共享变量更新后的值没有在工作内存与主内存及时更新。
JMM关于synchronizd的两条规定:
- 线程解锁前,必须把共享变量的最新值刷新到主内存。
- 线程加锁时,将清空工作内存中共享变量的值,从而使用共享变量时需要从主内存中读取最新的值。
volatile-可见性 通过加入内存屏障和禁止重排序优化实现。
- 对volatile变量写操作时,会在写操作后加入一条store屏障指令,将本地内存共享变量的值刷新到主内存。
- 对volatile变量读操作时,会在读操作前加入一条load屏障指令,从主内存中读取共享变量。
必须符合以下场景才可使用:
- 运算结果并不依赖变量当前值,或者能够确保只有单一线程修改变量的值。
- 变量不需要与其他状态变量共同参与不变约束。
原因:volatile变量在各个线程工作内存中不存在一致性问题,但是Java里面的运算并非原子性操作,导致volatile变量运算在并发下一样是不安全的。(可以通过反编译来验证)
private static void add() {
count++;
// 1、count 取出当前内存中的值
// 2、+1
// 3、count 写回主存
//即:两个线程同时执行+1写回主存就出现问题。
}
volatile通常用来作为状态标记量
volatile boolean inited = false;
//线程1:
context = loadContext();
inited = true;
//线程2;
while (!inited){
sleep();
}
doSomethingWithConfig(context);
4、安全发布对象
发布对象:使一个对象能够被当前范围之外代码所使用。
对象逸出:一种错误的发布。当一个对象还没有构造完成,就能被其它线程所见。
安全发布对象
- 在静态初始化函数中初始化一个对象的引用。
- 将对象的引用保存到volatile类型域或者AtomicReference对象中。
- 对象引用保存到某个正确构造对象final类型域中。
- 将对象的引用保存到一个由锁保护的域中。
public class SingletonExample4 {
// 私有构造函数
private SingletonExample4() {
}
// 1、memory = allocate() 分配对象的内存空间
// 2、ctorInstance() 初始化对象
// 3、instance = memory 设置instance指向刚分配的内存
// JVM和cpu优化,发生了指令重排
// 1、memory = allocate() 分配对象的内存空间
// 3、instance = memory 设置instance指向刚分配的内存
// 2、ctorInstance() 初始化对象
// 单例对象
private volatile static SingletonExample4 instance = null;
// 静态的工厂方法
public static SingletonExample4 getInstance() {
if (instance == null) { // 双重检测机制 // B
synchronized (SingletonExample4.class) { // 同步锁
if (instance == null) {
instance = new SingletonExample4(); // A - 3
}
}
}
return instance;
}
}
通过枚举实现单例模式
/**
* 枚举模式:最安全
*/
@ThreadSafe
@Recommend
public class SingletonExample7 {
// 私有构造函数
private SingletonExample7() {
}
public static SingletonExample7 getInstance() {
return Singleton.INSTANCE.getInstance();
}
private enum Singleton {
INSTANCE;
private SingletonExample7 singleton;
// JVM保证这个方法绝对只调用一次
Singleton() {
singleton = new SingletonExample7();
}
public SingletonExample7 getInstance() {
return singleton;
}
}
}
5、线程安全策略
1) 不可变对象
满足条件:
- 对象创建以后其状态就不能修改。
- 对象对所有域都是final类型。
- 对象是正确创建的。(对象在创建期间,this没有逸出)
- Collections.unmodifiableXXX:Collection、List、Set、Map……
- Guava:ImmutableXXX:Collection、List、Set、Map……
2) 线程封闭
- Ad-hoc线程封闭:程序控制实现,最糟糕,忽略。
- 堆栈封闭:局部变量,无并发问题。
- ThreadLocal线程封闭:特别好的封闭方法。(实现权限管理)
3) 线程不安全写法
- StringBuilder -> StringBuffer
- SimpleDateFormat -> JodaTime(推荐)
- ArrayList、HashSet、HashMap等Collections
- 先检查再执行:if(condition(a)){handle(a);} ->非原子操作
4) 同步容器
- ArrayList -->Vector,Stack
- HashMap -->HashTable (key、value不能为null)
- Collections.synchronizedXXX(List、Set、Map) 注意:同步容器在某些场合并不一定可以做到线程安全。
ArrayList -> CopyOnWriteArrayList
- 拷贝数组过大,容易造成young GC FUll GC
- 不适用于实时读的场景,适合读取多写少的场景。
- 实现读写分离,满足最终一致性,使用的时候另外开辟空间。
- 读取未加锁,写加锁。
public void add(int index, E element) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
if (index > len || index < 0)
throw new IndexOutOfBoundsException("Index: "+index+
", Size: "+len);
Object[] newElements;
int numMoved = len - index;
if (numMoved == 0)
newElements = Arrays.copyOf(elements, len + 1);
else {
newElements = new Object[len + 1];
System.arraycopy(elements, 0, newElements, 0, index);
System.arraycopy(elements, index, newElements, index + 1,
numMoved);
}
newElements[index] = element;
setArray(newElements);
} finally {
lock.unlock();
}
}
public E get(int index) {
return get(getArray(), index);
}
HashSet、TreeSet --> CopyOnWriteArraySet、ConcurrentSkipListSet
ConcurrentSkipListSet对批量操作不能保证原子性。
参考: JDK1.8源码分析之ConcurrentSkipListSet(八)
HashMap、TreeMap --> ConcurrentHashMap、ConcurrentSkipListMap
ConcurrentHashMap效率相对比ConcurrentSkipListMap高,ConcurrentSkipListMap有些其不具有的特性:
- ConcurrentSkipListMap 的key有序
- 支持更高的并发
参考:
Java多线程(四)之ConcurrentSkipListMap深入分析
探索 ConcurrentHashMap 高并发性的实现机制
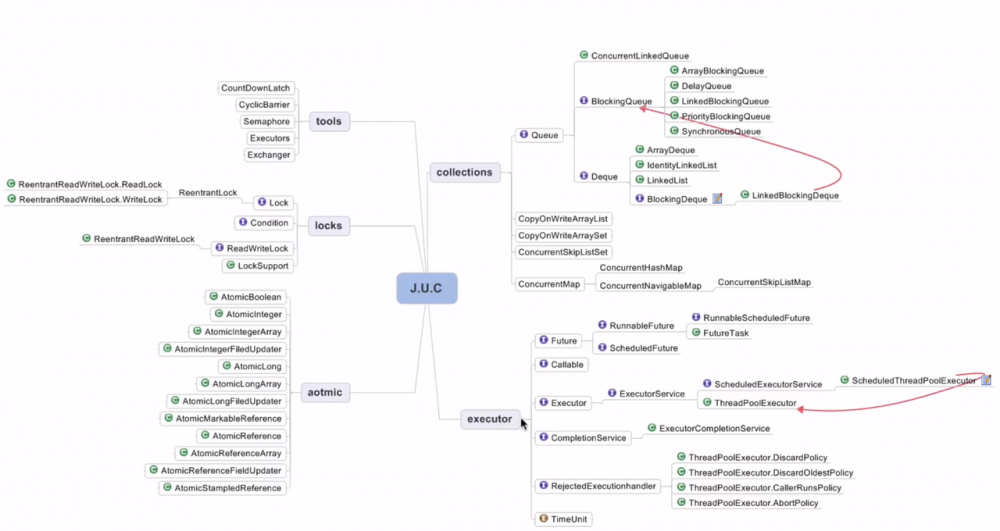
6、J.U.C之AQSAbstractQueuedSynchronizer-AQS
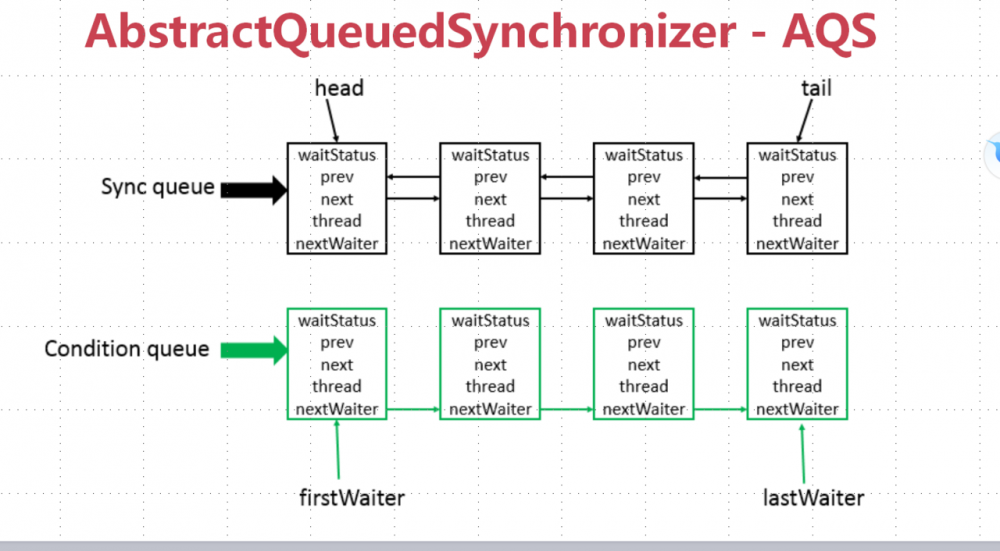
- 使用Node实现FIFO队列,可以用于构建锁或者其它同步装置的基础框架。
- 利用了一个int类型表示状态。
- 使用方法是继承。
- 子类通过继承并通过实现它的方法管理其状态{acquire和release}的方法操纵状态。
- 可以同步实现排它锁和共享锁模式(独占、共享)
AQS同步组件 1)等待多线程完成的CountDownLatch(JDK1.5)
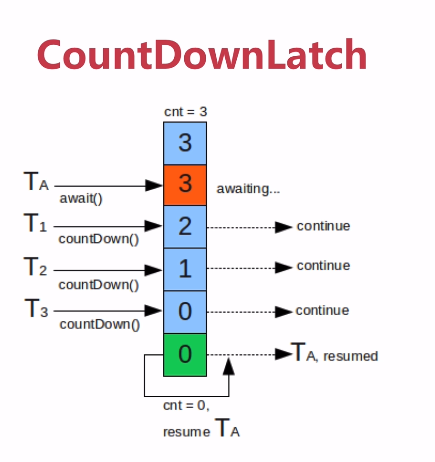
允许一个或多个线程等待其他线程完成操作。
其构造函数接收一个int类型的参数作为计数器,调用countDown方法的时候,计数器的值会减1,CountDownLatch的await方法会阻塞当前线程,直到N变为零。
应用:并行计算,解析Excel中多个sheet的数据。
2)控制并发线程数的 Semaphore 用来控制同时访问特定资源线程的数量。 应用:流量控制,特别是公共资源有限的场景,如数据库连接。
//可用的许可的数量 Semaphore(int permits) //获取一个许可 aquire() //使用完成后归还许可 release() //尝试获取许可证 tryAcquire()
3)同步屏障 CyclicBarrier
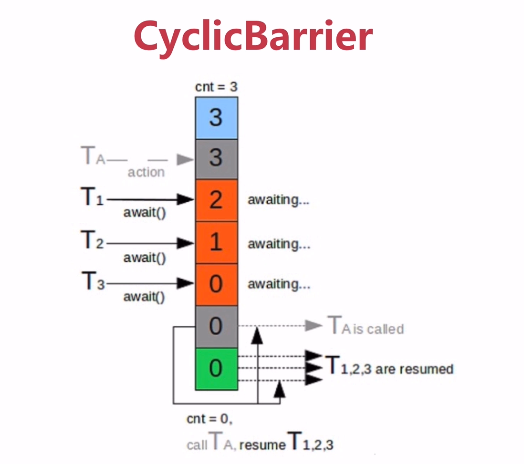
让一组线程达到一个屏障(同步点)时被阻塞,直到最后一个线程到达屏障时,才会开门,所有被屏障拦截的线程才会继续执行。 应用:多线程计算数据,最后合并计算结果的场景。
CyclicBarrier和CountDownLatch的区别
- CountDownLatch计数器只能使用一次,CyclicBarrier可以调用reset()方法重置。所以CyclicBarrier可以支持更加复杂的场景,如发生错误后重置计数器,并让线程重新执行。
//屏障拦截的线程数量 CyclicBarrier(int permits) //已经到达屏障 await() //CyclicBarrier阻塞线程的数量 getNumberWaiting()
4)重入锁 ReentrantLock (排他锁:同时允许单个线程访问。) 支持重进入的锁,表示该锁能够支持一个线程对资源的重复加锁。(即实现重进入:任意线程获取到锁之后能够再次获取该锁而不会被锁阻塞。)
- 该锁支持获取锁时的公平和非公平性选择
public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
}
公平锁就是等待时间最长的线程最优先获取锁,也就是说获取锁的是顺序的(FIFO)。而非公平则允许插队。 非公平因为不保障顺序,则效率相对较高,而公平锁则可以减少饥饿发生的概率。
- 提供了一个Condition类,可以分组唤醒需要唤醒的线程。
- 提供能够中断等待锁的线程机制,lock.lockInterruptibly()
ReentrantReadWriteLock (读写锁,实现悲观读取,同时允许多个线程访问)
在写线程访问时,所有的读线程和其他写线程均被堵塞。其维护了一对锁,通过分离读锁、写锁,使得并发性比排他锁有很大提升。
适用于读多写少的环境,能够提供比排他锁更好的并发与吞吐量。
不足:ReentrantReadWriteLock是读写锁,在多线程环境下,大多数情况是读的情况远远大于写的操作,因此可能导致写的饥饿问题。
StampedLock
是ReentrantReadWriteLock 的增强版,是为了解决ReentrantReadWriteLock的一些不足。 StampedLock读锁并不会阻塞写锁,设计思路也比较简单,就是在读的时候发现有写操作,再去读多一次。。 StampedLock有两种锁,一种是悲观锁,另外一种是乐观锁。如果线程拿到乐观锁就读和写不互斥,如果拿到悲观锁就读和写互斥。
参考: Java8对读写锁的改进:StampedLock
5)Condition
参考: Java线程(九):Condition-线程通信更高效的方式
6)FutureTask
参考: Java并发编程:Callable、Future和FutureTask
7)Fork/Join
参考: Fork/Join 模式高级特性
8)BlocklingQueue
- ArrayBlockingQueue
- DelayQueue
- LinkedBlockingQueue
- PriorityBlockingQueue
- SynchronousQueue
参考:Java中的阻塞队列
7、线程池
参考: Java 四种线程池的用法分析
越写越多,受不了了,已经凌晨4点,参考项以后再补,先休息!
参考资料:
《深入理解Java虚拟机》
《Java并发编程艺术》
《Java多线程编程核心技术》
慕课:Java并发编程与高并发解决方案正文到此结束
- 本文标签: 分布式锁 数据库 重排序 src Full GC redis ORM rsync loadrunner 高并发 ip value HashTable 安全 总结 线程池 缓存 多线程 Collection 测试 解析 排他锁 swap 并发编程 client 字节码 数据 Service update JMeter 分布式 db key HashMap cat final 凌晨 CountDownLatch API IO 协议 App 一致性 tar Java内存模型 build JVM UI 处理器 java 时间 id node Excel 线程通信 互联网 锁 http 原子类 管理 executor 编译 CTO 模型 参数 example ArrayList map Atom rmi 代码 希望 tab Collections java线程 线程 volatile ask synchronized NSA cache apache 空间 分布式系统 https list ConcurrentHashMap zookeeper 同步 queue 内存模型 MQ 源码 实例
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

