Java并发指南14:Java并发容器ConcurrentSkipListMap与CopyOnWriteArrayList
本文首发于我的个人博客: https://h2pl.github.io/
欢迎阅览我的CSDN专栏:Java并发指南
https://blog.csdn.net/column/details/21961.html相关代码会放在我的的Github: https://github.com/h2pl/
原文出处 http://cmsblogs.com/ 『chenssy』
到目前为止,我们在Java世界里看到了两种实现key-value的数据结构:Hash、TreeMap,这两种数据结构各自都有着优缺点。
- Hash表:插入、查找最快,为O(1);如使用链表实现则可实现无锁;数据有序化需要显式的排序操作。
- 红黑树:插入、查找为O(logn),但常数项较小;无锁实现的复杂性很高,一般需要加锁;数据天然有序。
然而,这次介绍第三种实现key-value的数据结构:SkipList。SkipList有着不低于红黑树的效率,但是其原理和实现的复杂度要比红黑树简单多了。
SkipList
什么是SkipList?Skip List ,称之为跳表,它是一种可以替代平衡树的数据结构,其数据元素默认按照key值升序,天然有序。Skip list让已排序的数据分布在多层链表中,以0-1随机数决定一个数据的向上攀升与否,通过“空间来换取时间”的一个算法,在每个节点中增加了向前的指针,在插入、删除、查找时可以忽略一些不可能涉及到的结点,从而提高了效率。
我们先看一个简单的链表,如下:

如果我们需要查询9、21、30,则需要比较次数为3 + 6 + 8 = 17 次,那么有没有优化方案呢?有!我们将该链表中的某些元素提炼出来作为一个比较“索引”,如下:
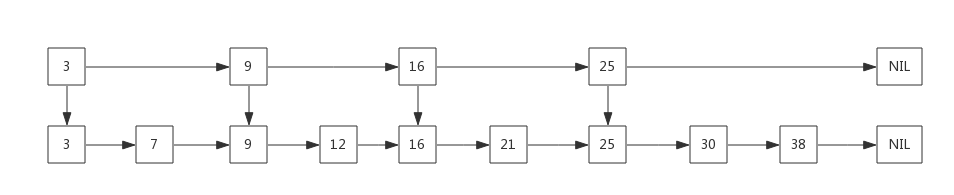
我们先与这些索引进行比较来决定下一个元素是往右还是下走,由于存在“索引”的缘故,导致在检索的时候会大大减少比较的次数。当然元素不是很多,很难体现出优势,当元素足够多的时候,这种索引结构就会大显身手。
SkipList的特性
SkipList具备如下特性:
- 由很多层结构组成,level是通过一定的概率随机产生的
- 每一层都是一个有序的链表,默认是升序,也可以根据创建映射时所提供的Comparator进行排序,具体取决于使用的构造方法
- 最底层(Level 1)的链表包含所有元素
- 如果一个元素出现在Level i 的链表中,则它在Level i 之下的链表也都会出现
- 每个节点包含两个指针,一个指向同一链表中的下一个元素,一个指向下面一层的元素
我们将上图再做一些扩展就可以变成一个典型的SkipList结构了
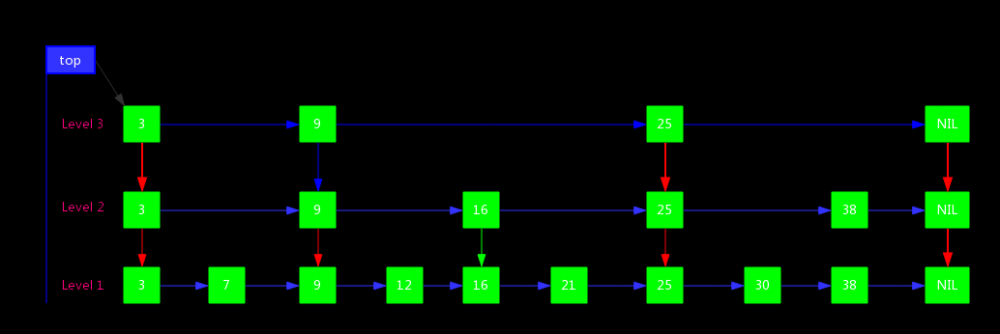
SkipList的查找
SkipListd的查找算法较为简单,对于上面我们我们要查找元素21,其过程如下:
- 比较3,大于,往后找(9),
- 比9大,继续往后找(25),但是比25小,则从9的下一层开始找(16)
- 16的后面节点依然为25,则继续从16的下一层找
- 找到21
如图
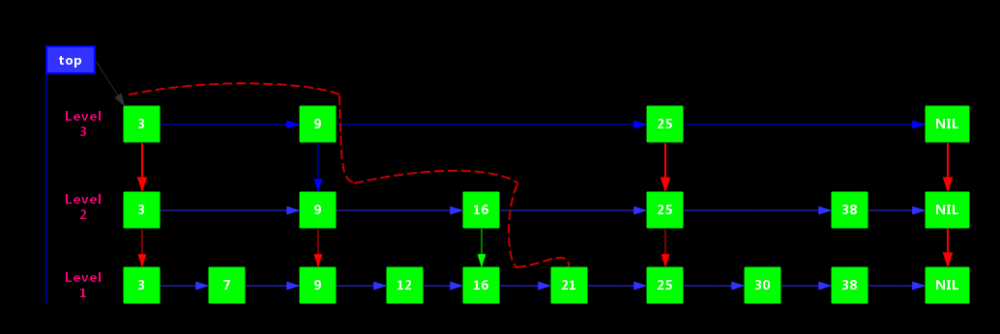
红色虚线代表路径。
SkipList的插入
SkipList的插入操作主要包括:
- 查找合适的位置。这里需要明确一点就是在确认新节点要占据的层次K时,采用丢硬币的方式,完全随机。如果占据的层次K大于链表的层次,则重新申请新的层,否则插入指定层次
- 申请新的节点
- 调整指针
假定我们要插入的元素为23,经过查找可以确认她是位于25后,9、16、21前。当然需要考虑申请的层次K。
如果层次K > 3
需要申请新层次(Level 4)
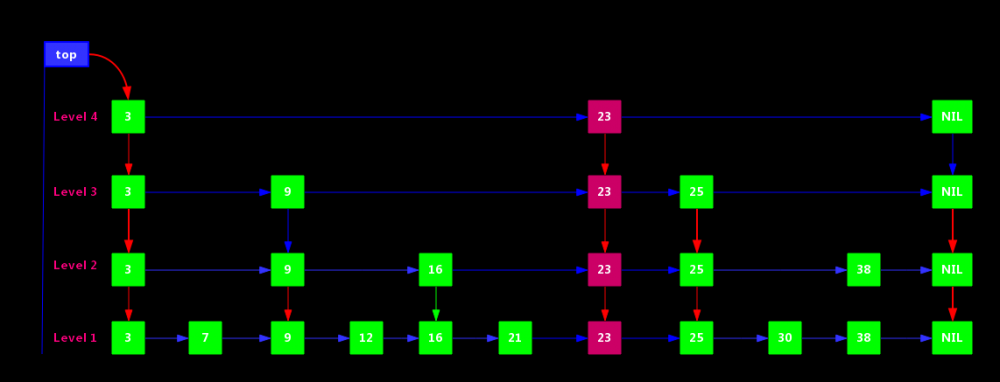
如果层次 K = 2
直接在Level 2 层插入即可
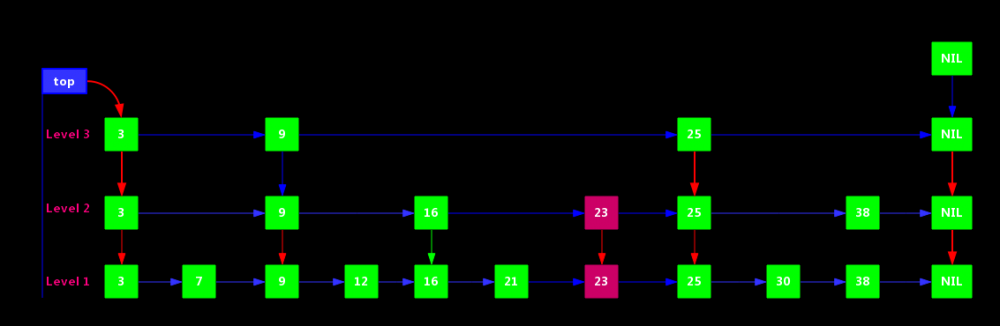
这里会涉及到以个算法:通过丢硬币决定层次K,该算法我们通过后面ConcurrentSkipListMap源码来分析。还有一个需要注意的地方就是,在K层插入元素后,需要确保所有小于K层的层次都应该出现新节点。
SkipList的删除
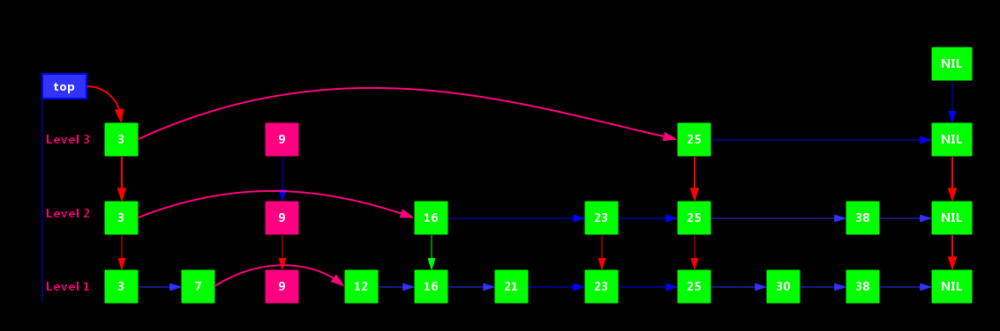
删除节点和插入节点思路基本一致:找到节点,删除节点,调整指针。
比如删除节点9,如下:
ConcurrentSkipListMap
通过上面我们知道SkipList采用空间换时间的算法,其插入和查找的效率O(logn),其效率不低于红黑树,但是其原理和实现的复杂度要比红黑树简单多了。一般来说会操作链表List,就会对SkipList毫无压力。
ConcurrentSkipListMap其内部采用SkipLis数据结构实现。为了实现SkipList,ConcurrentSkipListMap提供了三个内部类来构建这样的链表结构:Node、Index、HeadIndex。其中Node表示最底层的单链表有序节点、Index表示为基于Node的索引层,HeadIndex用来维护索引层次。到这里我们可以这样说ConcurrentSkipListMap是通过HeadIndex维护索引层次,通过Index从最上层开始往下层查找,一步一步缩小查询范围,最后到达最底层Node时,就只需要比较很小一部分数据了。在JDK中的关系如下图:
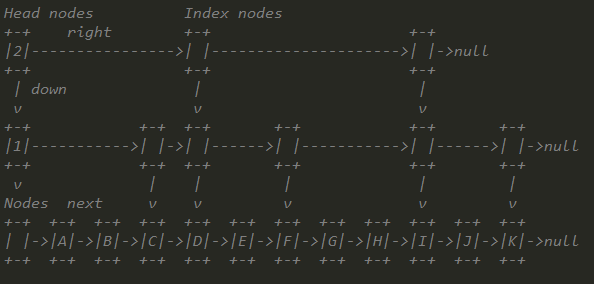
Node
static final class Node
<k v="">
{ final K key; volatile Object value; volatile ConcurrentSkipListMap.Node
<k v="">
next; /** 省略些许代码 */ }
</k>
</k>
Node的结构和一般的单链表毫无区别,key-value和一个指向下一个节点的next。
Index
static class Index
<k v="">
{ final ConcurrentSkipListMap.Node
<k v="">
node; final ConcurrentSkipListMap.Index
<k v="">
down; volatile ConcurrentSkipListMap.Index
<k v="">
right; /** 省略些许代码 */ }
</k>
</k>
</k>
</k>
Index提供了一个基于Node节点的索引Node,一个指向下一个Index的right,一个指向下层的down节点。
HeadIndex
static final class HeadIndex
<k v="">
extends Index
<k v="">
{ final int level; //索引层,从1开始,Node单链表层为0 HeadIndex(Node
<k v="">
node, Index
<k v="">
down, Index
<k v="">
right, int level) { super(node, down, right); this.level = level; } }
</k>
</k>
</k>
</k>
</k>
HeadIndex内部就一个level来定义层级。
ConcurrentSkipListMap提供了四个构造函数,每个构造函数都会调用initialize()方法进行初始化工作。
final void initialize() { keySet = null; entrySet = null; values = null; descendingMap = null; randomSeed = seedGenerator.nextInt() | 0x0100; // ensure nonzero head = new ConcurrentSkipListMap.HeadIndex
<k v="">
(new ConcurrentSkipListMap.Node
<k v="">
(null, BASE_HEADER, null), null, null, 1); }
</k>
</k>
注意,initialize()方法不仅仅只在构造函数中被调用,如clone,clear、readObject时都会调用该方法进行初始化步骤。这里需要注意randomSeed的初始化。
private transient int randomSeed; randomSeed = seedGenerator.nextInt() | 0x0100; // ensure nonzero
randomSeed一个简单的随机数生成器(在后面介绍)。
put操作
CoucurrentSkipListMap提供了put()方法用于将指定值与此映射中的指定键关联。源码如下:
public V put(K key, V value) { if (value == null) throw new NullPointerException(); return doPut(key, value, false); }
首先判断value如果为null,则抛出NullPointerException,否则调用doPut方法,其实如果各位看过JDK的源码的话,应该对这样的操作很熟悉了,JDK源码里面很多方法都是先做一些必要性的验证后,然后通过调用do**()方法进行真正的操作。
doPut()方法内容较多,我们分步分析。
private V doPut(K key, V value, boolean onlyIfAbsent) { Node
<k v="">
z; // added node if (key == null) throw new NullPointerException(); // 比较器 Comparator<? super K> cmp = comparator; outer: for (;;) { for (Node
<k v="">
b = findPredecessor(key, cmp), n = b.next; ; ) { /** 省略代码 */
</k>
</k>
doPut()方法有三个参数,除了key,value外还有一个boolean类型的onlyIfAbsent,该参数作用与如果存在当前key时,该做何动作。当onlyIfAbsent为false时,替换value,为true时,则返回该value。用代码解释为:
if (!map.containsKey(key)) return map.put(key, value); else return map.get(key);
首先判断key是否为null,如果为null,则抛出NullPointerException,从这里我们可以确认ConcurrentSkipList是不支持key或者value为null的。然后调用findPredecessor()方法,传入key来确认位置。findPredecessor()方法其实就是确认key要插入的位置。
private Node
<k v="">
findPredecessor(Object key, Comparator<? super K> cmp) { if (key == null) throw new NullPointerException(); // don't postpone errors for (;;) { // 从head节点开始,head是level最高级别的headIndex for (Index
<k v="">
q = head, r = q.right, d;;) { // r != null,表示该节点右边还有节点,需要比较 if (r != null) { Node
<k v="">
n = r.node; K k = n.key; // value == null,表示该节点已经被删除了 // 通过unlink()方法过滤掉该节点 if (n.value == null) { //删掉r节点 if (!q.unlink(r)) break; // restart r = q.right; // reread r continue; } // value != null,节点存在 // 如果key 大于r节点的key 则往前进一步 if (cpr(cmp, key, k) > 0) { q = r; r = r.right; continue; } } // 到达最右边,如果dowm == null,表示指针已经达到最下层了,直接返回该节点 if ((d = q.down) == null) return q.node; q = d; r = d.right; } } }
</k>
</k>
</k>
findPredecessor()方法意思非常明确:寻找前辈。从最高层的headIndex开始向右一步一步比较,直到right为null或者右边节点的Node的key大于当前key为止,然后再向下寻找,依次重复该过程,直到down为null为止,即找到了前辈,看返回的结果注意是Node,不是Item,所以插入的位置应该是最底层的Node链表。
在这个过程中ConcurrentSkipListMap赋予了该方法一个其他的功能,就是通过判断节点的value是否为null,如果为null,表示该节点已经被删除了,通过调用unlink()方法删除该节点。
final boolean unlink(Index
<k v="">
succ) { return node.value != null && casRight(succ, succ.right); }
</k>
删除节点过程非常简单,更改下right指针即可。
通过findPredecessor()找到前辈节点后,做什么呢?看下面:
for (Node
<k v="">
b = findPredecessor(key, cmp), n = b.next;;) { // 前辈节点的next != null if (n != null) { Object v; int c; Node
<k v="">
f = n.next; // 不一致读,主要原因是并发,有节点捷足先登 if (n != b.next) // inconsistent read break; // n.value == null,该节点已经被删除了 if ((v = n.value) == null) { // n is deleted n.helpDelete(b, f); break; } // 前辈节点b已经被删除 if (b.value == null || v == n) // b is deleted break; // 节点大于,往前移 if ((c = cpr(cmp, key, n.key)) > 0) { b = n; n = f; continue; } // c == 0 表示,找到一个key相等的节点,根据onlyIfAbsent参数来做判断 // onlyIfAbsent ==false,则通过casValue,替换value // onlyIfAbsent == true,返回该value if (c == 0) { if (onlyIfAbsent || n.casValue(v, value)) { @SuppressWarnings("unchecked") V vv = (V)v; return vv; } break; // restart if lost race to replace value } // else c < 0; fall through } // 将key-value包装成一个node,插入 z = new Node
<k v="">
(key, value, n); if (!b.casNext(n, z)) break; // restart if lost race to append to b break outer; }
</k>
</k>
</k>
找到合适的位置后,就是在该位置插入节点咯。插入节点的过程比较简单,就是将key-value包装成一个Node,然后通过casNext()方法加入到链表当中。当然是插入之前需要进行一系列的校验工作。
在最下层插入节点后,下一步工作是什么?新建索引。前面博主提过,在插入节点的时候,会根据采用抛硬币的方式来决定新节点所插入的层次,由于存在并发的可能,ConcurrentSkipListMap采用ThreadLocalRandom来生成随机数。如下:
int rnd = ThreadLocalRandom.nextSecondarySeed();
抛硬币决定层次的思想很简单,就是通过抛硬币如果硬币为正面则层次level + 1 ,否则停止,如下:
// 抛硬币决定层次 while (((rnd >>>= 1) & 1) != 0) ++level;
在阐述SkipList插入节点的时候说明了,决定的层次level会分为两种情况进行处理,一是如果层次level大于最大的层次话则需要新增一层,否则就在相应层次以及小于该level的层次进行节点新增处理。
level <= headIndex.level
// 如果决定的层次level比最高层次head.level小,直接生成最高层次的index // 由于需要确认每一层次的down,所以需要从最下层依次往上生成 if (level <= (max="h.level))" {="" for="" (int="" i="1;" <="level;" ++i)="" idx="new" concurrentskiplistmap.index
<k v="">
(z, idx, null); }
</k>
从底层开始,小于level的每一层都初始化一个index,每次的node都指向新加入的node,down指向下一层的item,右侧next全部为null。整个处理过程非常简单:为小于level的每一层初始化一个index,然后加入到原来的index链条中去。
level > headIndex.level
// leve > head.level 则新增一层 else { // try to grow by one level // 新增一层 level = max + 1; // 初始化 level个item节点 @SuppressWarnings("unchecked") ConcurrentSkipListMap.Index
<k v="">
[] idxs = (ConcurrentSkipListMap.Index
<k v="">
[])new ConcurrentSkipListMap.Index<?,?>[level+1]; for (int i = 1; i <= level;="" ++i)="" idxs[i]="idx" =="" new="" concurrentskiplistmap.index
<k v="">
(z, idx, null); // for (;;) { h = head; int oldLevel = h.level; // 层次扩大了,需要重新开始(有新线程节点加入) if (level <= oldlevel)="" lost="" race="" to="" add="" level="" break;="" 新的头结点headindex="" concurrentskiplistmap.headindex
<k v="">
newh = h; ConcurrentSkipListMap.Node
<k v="">
oldbase = h.node; // 生成新的HeadIndex节点,该HeadIndex指向新增层次 for (int j = oldLevel+1; j <= level;="" ++j)="" newh="new" concurrentskiplistmap.headindex
<k v="">
(oldbase, newh, idxs[j], j); // HeadIndex CAS替换 if (casHead(h, newh)) { h = newh; idx = idxs[level = oldLevel]; break; } }
</k>
</k>
</k>
</k>
</k>
</k>
当抛硬币决定的level大于最大层次level时,需要新增一层进行处理。处理逻辑如下:
- 初始化一个对应的index数组,大小为level + 1,然后为每个单位都创建一个index,个中参数为:Node为新增的Z,down为下一层index,right为null
- 通过for循环来进行扩容操作。从最高层进行处理,新增一个HeadIndex,个中参数:节点Node,down都为最高层的Node和HeadIndex,right为刚刚创建的对应层次的index,level为相对应的层次level。最后通过CAS把当前的head与新加入层的head进行替换。
通过上面步骤我们发现,尽管已经找到了前辈节点,也将node插入了,也确定确定了层次并生成了相应的Index,但是并没有将这些Index插入到相应的层次当中,所以下面的代码就是将index插入到相对应的层当中。
// 从插入的层次level开始 splice: for (int insertionLevel = level;;) { int j = h.level; // 从headIndex开始 for (ConcurrentSkipListMap.Index
<k v="">
q = h, r = q.right, t = idx;;) { if (q == null || t == null) break splice; // r != null;这里是找到相应层次的插入节点位置,注意这里只横向找 if (r != null) { ConcurrentSkipListMap.Node
<k v="">
n = r.node; int c = cpr(cmp, key, n.key); // n.value == null ,解除关系,r右移 if (n.value == null) { if (!q.unlink(r)) break; r = q.right; continue; } // key > n.key 右移 if (c > 0) { q = r; r = r.right; continue; } } // 上面找到节点要插入的位置,这里就插入 // 当前层是最顶层 if (j == insertionLevel) { // 建立联系 if (!q.link(r, t)) break; // restart if (t.node.value == null) { findNode(key); break splice; } // 标志的插入层 -- ,如果== 0 ,表示已经到底了,插入完毕,退出循环 if (--insertionLevel == 0) break splice; } // 上面节点已经插入完毕了,插入下一个节点 if (--j >= insertionLevel && j < level) t = t.down; q = q.down; r = q.right; } }
</k>
</k>
这段代码分为两部分看,一部分是找到相应层次的该节点插入的位置,第二部分在该位置插入,然后下移。
至此,ConcurrentSkipListMap的put操作到此就结束了。代码量有点儿多,这里总结下:
- 首先通过findPredecessor()方法找到前辈节点Node
- 根据返回的前辈节点以及key-value,新建Node节点,同时通过CAS设置next
- 设置节点Node,再设置索引节点。采取抛硬币方式决定层次,如果所决定的层次大于现存的最大层次,则新增一层,然后新建一个Item链表。
- 最后,将新建的Item链表插入到SkipList结构中。
get操作
相比于put操作 ,get操作会简单很多,其过程其实就只相当于put操作的第一步:
private V doGet(Object key) { if (key == null) throw new NullPointerException(); Comparator<? super K> cmp = comparator; outer: for (;;) { for (ConcurrentSkipListMap.Node
<k v="">
b = findPredecessor(key, cmp), n = b.next;;) { Object v; int c; if (n == null) break outer; ConcurrentSkipListMap.Node
<k v="">
f = n.next; if (n != b.next) // inconsistent read break; if ((v = n.value) == null) { // n is deleted n.helpDelete(b, f); break; } if (b.value == null || v == n) // b is deleted break; if ((c = cpr(cmp, key, n.key)) == 0) { @SuppressWarnings("unchecked") V vv = (V)v; return vv; } if (c < 0) break outer; b = n; n = f; } } return null; }
</k>
</k>
与put操作第一步相似,首先调用findPredecessor()方法找到前辈节点,然后顺着right一直往右找即可,同时在这个过程中同样承担了一个删除value为null的节点的职责。
remove操作
remove操作为删除指定key节点,如下:
public V remove(Object key) { return doRemove(key, null); }
直接调用doRemove()方法,这里remove有两个参数,一个是key,另外一个是value,所以doRemove方法即提供remove key,也提供同时满足key-value。
final V doRemove(Object key, Object value) { if (key == null) throw new NullPointerException(); Comparator<? super K> cmp = comparator; outer: for (;;) { for (ConcurrentSkipListMap.Node
<k v="">
b = findPredecessor(key, cmp), n = b.next;;) { Object v; int c; if (n == null) break outer; ConcurrentSkipListMap.Node
<k v="">
f = n.next; // 不一致读,重新开始 if (n != b.next) // inconsistent read break; // n节点已删除 if ((v = n.value) == null) { // n is deleted n.helpDelete(b, f); break; } // b节点已删除 if (b.value == null || v == n) // b is deleted break; if ((c = cpr(cmp, key, n.key)) < 0) break outer; // 右移 if (c > 0) { b = n; n = f; continue; } /*
* 找到节点
*/ // value != null 表示需要同时校验key-value值 if (value != null && !value.equals(v)) break outer; // CAS替换value if (!n.casValue(v, null)) break; if (!n.appendMarker(f) || !b.casNext(n, f)) findNode(key); // retry via findNode else { // 清理节点 findPredecessor(key, cmp); // clean index // head.right == null表示该层已经没有节点,删掉该层 if (head.right == null) tryReduceLevel(); } @SuppressWarnings("unchecked") V vv = (V)v; return vv; } } return null; }
</k>
</k>
调用findPredecessor()方法找到前辈节点,然后通过右移,然后比较,找到后利用CAS把value替换为null,然后判断该节点是不是这层唯一的index,如果是的话,调用tryReduceLevel()方法把这层干掉,完成删除。
其实从这里可以看出,remove方法仅仅是把Node的value设置null,并没有真正删除该节点Node,其实从上面的put操作、get操作我们可以看出,他们在寻找节点的时候都会判断节点的value是否为null,如果为null,则调用unLink()方法取消关联关系,如下:
if (n.value == null) { if (!q.unlink(r)) break; // restart r = q.right; // reread r continue; }
size操作
ConcurrentSkipListMap的size()操作和ConcurrentHashMap不同,它并没有维护一个全局变量来统计元素的个数,所以每次调用该方法的时候都需要去遍历。
public int size() { long count = 0; for (Node
<k v="">
n = findFirst(); n != null; n = n.next) { if (n.getValidValue() != null) ++count; } return (count >= Integer.MAX_VALUE) ? Integer.MAX_VALUE : (int) count; }
</k>
调用findFirst()方法找到第一个Node,然后利用node的next去统计。最后返回统计数据,最多能返回Integer.MAX_VALUE。注意这里在线程并发下是安全的。
ConcurrentSkipListMap过程其实不复杂,相比于ConcurrentHashMap而言,是简单的不能再简单了。对跳表SkipList熟悉的话,ConcurrentSkipListMap 应该是盘中餐了。
Java并发编程:并发容器之CopyOnWriteArrayList(转载)
原文链接:
http://ifeve.com/java-copy-on-write/
Copy-On-Write简称COW,是一种用于程序设计中的优化策略。其基本思路是,从一开始大家都在共享同一个内容,当某个人想要修改这个内容的时候,才会真正把内容Copy出去形成一个新的内容然后再改,这是一种延时懒惰策略。从JDK1.5开始Java并发包里提供了两个使用CopyOnWrite机制实现的并发容器,它们是CopyOnWriteArrayList和CopyOnWriteArraySet。CopyOnWrite容器非常有用,可以在非常多的并发场景中使用到。
什么是CopyOnWrite容器
CopyOnWrite容器即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。
CopyOnWriteArrayList的实现原理
在使用CopyOnWriteArrayList之前,我们先阅读其源码了解下它是如何实现的。以下代码是向CopyOnWriteArrayList中add方法的实现(向CopyOnWriteArrayList里添加元素),可以发现在添加的时候是需要加锁的,否则多线程写的时候会Copy出N个副本出来。
| 1234567891011121314151617181920 | /**` Appends the specified element to the end of this list. * @param e element to be appended to this list @return true (as specified by {@link Collection#add}) public` `boolean` `add(E e) { final this .lock; lock.lock(); try Object[] elements = getArray(); int Object[] newElements = Arrays.copyOf(elements, len + 1 ); newElements[len] = e; setArray(newElements); return ; } finally` `{ lock.unlock(); } }` |
|---|
读的时候不需要加锁,如果读的时候有多个线程正在向CopyOnWriteArrayList添加数据,读还是会读到旧的数据,因为写的时候不会锁住旧的CopyOnWriteArrayList。
| 123 | public E get(` int return` `get(getArray(), index); }` |
|---|
JDK中并没有提供CopyOnWriteMap,我们可以参考CopyOnWriteArrayList来实现一个,基本代码如下:
| 123456789101112131415161718192021222324252627282930313233 | import java.util.Collection;` import import` `java.util.Set; public implements` `Map<K, V>, Cloneable { private public` `CopyOnWriteMap() { internalMap = new` `HashMap<K, V>(); } public` `V put(K key, V value) { synchronized this ) { Map<K, V> newMap = new V val = newMap.put(key, value); internalMap = newMap; return` `val; } } public return` `internalMap.get(key); } public` `void` `putAll(Map<? extends extends` `V> newData) { synchronized this ) { Map<K, V> newMap = new newMap.putAll(newData); internalMap = newMap; } } |
|---|
实现很简单,只要了解了CopyOnWrite机制,我们可以实现各种CopyOnWrite容器,并且在不同的应用场景中使用。
CopyOnWrite的应用场景
CopyOnWrite并发容器用于读多写少的并发场景。比如白名单,黑名单,商品类目的访问和更新场景,假如我们有一个搜索网站,用户在这个网站的搜索框中,输入关键字搜索内容,但是某些关键字不允许被搜索。这些不能被搜索的关键字会被放在一个黑名单当中,黑名单每天晚上更新一次。当用户搜索时,会检查当前关键字在不在黑名单当中,如果在,则提示不能搜索。实现代码如下:
| 1234567891011121314151617181920212223242526272829303132333435 | package com.ifeve.book;` import import` `com.ifeve.book.forkjoin.CopyOnWriteMap; / * 黑名单服务 * */ public` `class` `BlackListServiceImpl { private new` `CopyOnWriteMap<String, Boolean>( 1000 ); public return` `blackListMap.get(id) == null false` `: true ; } public` `static` `void` `addBlackList(String id) { blackListMap.put(id, Boolean.TRUE); } / * 批量添加黑名单 */ public blackListMap.putAll(ids); } |
|---|
代码很简单,但是使用CopyOnWriteMap需要注意两件事情:
1. 减少扩容开销。根据实际需要,初始化CopyOnWriteMap的大小,避免写时CopyOnWriteMap扩容的开销。
2. 使用批量添加。因为每次添加,容器每次都会进行复制,所以减少添加次数,可以减少容器的复制次数。如使用上面代码里的addBlackList方法。
CopyOnWrite的缺点
CopyOnWrite容器有很多优点,但是同时也存在两个问题,即内存占用问题和数据一致性问题。所以在开发的时候需要注意一下。
内存占用问题。因为CopyOnWrite的写时复制机制,所以在进行写操作的时候,内存里会同时驻扎两个对象的内存,旧的对象和新写入的对象(注意:在复制的时候只是复制容器里的引用,只是在写的时候会创建新对象添加到新容器里,而旧容器的对象还在使用,所以有两份对象内存)。如果这些对象占用的内存比较大,比如说200M左右,那么再写入100M数据进去,内存就会占用300M,那么这个时候很有可能造成频繁的Yong GC和Full GC。之前我们系统中使用了一个服务由于每晚使用CopyOnWrite机制更新大对象,造成了每晚15秒的Full GC,应用响应时间也随之变长。
针对内存占用问题,可以通过压缩容器中的元素的方法来减少大对象的内存消耗,比如,如果元素全是10进制的数字,可以考虑把它压缩成36进制或64进制。或者不使用CopyOnWrite容器,而使用其他的并发容器,如 ConcurrentHashMap 。
数据一致性问题。CopyOnWrite容器只能保证数据的最终一致性,不能保证数据的实时一致性。所以如果你希望写入的的数据,马上能读到,请不要使用CopyOnWrite容器。
下面这篇文章验证了CopyOnWriteArrayList和同步容器的性能:
http://blog.csdn.net/wind5shy/article/details/5396887
下面这篇文章简单描述了CopyOnWriteArrayList的使用:
http://blog.csdn.net/imzoer/article/details/9751591
正文到此结束
- 本文标签: 并发编程 node 压力 删除 代码 一致性 list synchronized 总结 https UI Service HTML ArrayList 开发 tab http 线程 GitHub id value 构造方法 final git map 文章 App 索引 缩小 源码 统计 find SDN 希望 key yong GC 锁 ip 安全 ACE 空间 ConcurrentHashMap 参数 java src tar 多线程 Collection DOM Full GC volatile db 网站 博客 时间 HashMap REST 同步 数据 IO 遍历 equals
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

