Java并发指南9:AQS共享模式与并发工具类的实现
本文首发于我的个人博客: https://h2pl.github.io/
欢迎阅览我的CSDN专栏:Java并发指南
https://blog.csdn.net/column/details/21961.html相关代码会放在我的的Github: https://github.com/h2pl/
一行一行源码分析清楚 AbstractQueuedSynchronizer (三)
转自: https://javadoop.com/post/AbstractQueuedSynchronizer-3
这篇文章是 AQS 系列的最后一篇,第一篇,我们通过 ReentrantLock 公平锁分析了 AQS 的核心,第二篇的重点是把 Condition 说明白,同时也说清楚了对于线程中断的使用。
这篇,我们的关注点是 AQS 最后的部分,共享模式的使用。有前两篇文章的铺垫,剩下的源码分析将会简单很多。
本文先用 CountDownLatch 将共享模式说清楚,然后顺着把其他 AQS 相关的类 CyclicBarrier、Semaphore 的源码一起过一下。
老规矩:不放过任何一行代码,没有任何糊弄,没有任何瞎说。
- AQS的共享模式
- CountDownLatch
- 使用例子
- 源码分析
- CyclicBarrier
- Semaphore
- Exchanger
- 总结
在讲CountDownLatch之前,先让我们了解一下什么是AQS中的共享模式和共享锁。
深入浅出AQS之共享锁模式
深入浅出AQS之共享锁模式
原文地址: http://www.jianshu.com/p/1161…
搞清楚AQS独占锁的实现原理之后,再看共享锁的实现原理就会轻松很多。两种锁模式之间很多通用的地方本文只会简单说明一下,就不在赘述了,具体细节可以参考我的上篇文章。
执行过程概述
获取锁的过程:
- 当线程调用acquireShared()申请获取锁资源时,如果成功,则进入临界区。
- 当获取锁失败时,则创建一个共享类型的节点并进入一个FIFO等待队列,然后被挂起等待唤醒。
- 当队列中的等待线程被唤醒以后就重新尝试获取锁资源,如果成功则 唤醒后面还在等待的共享节点并把该唤醒事件传递下去,即会依次唤醒在该节点后面的所有共享节点 ,然后进入临界区,否则继续挂起等待。
释放锁过程:
- 当线程调用releaseShared()进行锁资源释放时,如果释放成功,则唤醒队列中等待的节点,如果有的话。
源码深入分析
基于上面所说的共享锁执行流程,我们接下来看下源码实现逻辑:
首先来看下获取锁的方法acquireShared(),如下
public final void acquireShared(int arg) {
//尝试获取共享锁,返回值小于0表示获取失败
if (tryAcquireShared(arg) < 0)
//执行获取锁失败以后的方法
doAcquireShared(arg);
}
这里tryAcquireShared()方法是留给用户去实现具体的获取锁逻辑的。关于该方法的实现有两点需要特别说明:
一、该方法必须自己检查当前上下文是否支持获取共享锁,如果支持再进行获取。
二、该方法返回值是个重点。其一、由上面的源码片段可以看出返回值小于0表示获取锁失败,需要进入等待队列。其二、如果返回值等于0表示当前线程获取共享锁成功,但它后续的线程是无法继续获取的,也就是不需要把它后面等待的节点唤醒。最后、如果返回值大于0,表示当前线程获取共享锁成功且它后续等待的节点也有可能继续获取共享锁成功,也就是说此时需要把后续节点唤醒让它们去尝试获取共享锁。
有了上面的约定,我们再来看下doAcquireShared方法的实现:
//参数不多说,就是传给acquireShared()的参数
private void doAcquireShared(int arg) {
//添加等待节点的方法跟独占锁一样,唯一区别就是节点类型变为了共享型,不再赘述
final Node node = addWaiter(Node.SHARED);
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
//表示前面的节点已经获取到锁,自己会尝试获取锁
if (p == head) {
int r = tryAcquireShared(arg);
//注意上面说的, 等于0表示不用唤醒后继节点,大于0需要
if (r >= 0) {
//这里是重点,获取到锁以后的唤醒操作,后面详细说
setHeadAndPropagate(node, r);
p.next = null;
//如果是因为中断醒来则设置中断标记位
if (interrupted)
selfInterrupt();
failed = false;
return;
}
}
//挂起逻辑跟独占锁一样,不再赘述
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
//获取失败的取消逻辑跟独占锁一样,不再赘述
if (failed)
cancelAcquire(node);
}
}
独占锁模式获取成功以后设置头结点然后返回中断状态,结束流程。而共享锁模式获取成功以后,调用了setHeadAndPropagate方法,从方法名就可以看出除了设置新的头结点以外还有一个传递动作,一起看下代码:
//两个入参,一个是当前成功获取共享锁的节点,一个就是tryAcquireShared方法的返回值,注意上面说的,它可能大于0也可能等于0
private void setHeadAndPropagate(Node node, int propagate) {
Node h = head; //记录当前头节点
//设置新的头节点,即把当前获取到锁的节点设置为头节点
//注:这里是获取到锁之后的操作,不需要并发控制
setHead(node);
//这里意思有两种情况是需要执行唤醒操作
//1.propagate > 0 表示调用方指明了后继节点需要被唤醒
//2.头节点后面的节点需要被唤醒(waitStatus<0),不论是老的头结点还是新的头结点
if (propagate > 0 || h == null || h.waitStatus < 0 ||
(h = head) == null || h.waitStatus < 0) {
Node s = node.next;
//如果当前节点的后继节点是共享类型获取没有后继节点,则进行唤醒
//这里可以理解为除非明确指明不需要唤醒(后继等待节点是独占类型),否则都要唤醒
if (s == null || s.isShared())
//后面详细说
doReleaseShared();
}
}
private void setHead(Node node) {
head = node;
node.thread = null;
node.prev = null;
}
最终的唤醒操作也很复杂,专门拿出来分析一下:
注:这个唤醒操作在releaseShare()方法里也会调用。
private void doReleaseShared() {
for (;;) {
//唤醒操作由头结点开始,注意这里的头节点已经是上面新设置的头结点了
//其实就是唤醒上面新获取到共享锁的节点的后继节点
Node h = head;
if (h != null && h != tail) {
int ws = h.waitStatus;
//表示后继节点需要被唤醒
if (ws == Node.SIGNAL) {
//这里需要控制并发,因为入口有setHeadAndPropagate跟release两个,避免两次unpark
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))
continue;
//执行唤醒操作
unparkSuccessor(h);
}
//如果后继节点暂时不需要唤醒,则把当前节点状态设置为PROPAGATE确保以后可以传递下去
else if (ws == 0 &&
!compareAndSetWaitStatus(h, 0, Node.PROPAGATE))
continue;
}
//如果头结点没有发生变化,表示设置完成,退出循环
//如果头结点发生变化,比如说其他线程获取到了锁,为了使自己的唤醒动作可以传递,必须进行重试
if (h == head)
break;
}
}
接下来看下释放共享锁的过程:
public final boolean releaseShared(int arg) {
//尝试释放共享锁
if (tryReleaseShared(arg)) {
//唤醒过程,详情见上面分析
doReleaseShared();
return true;
}
return false;
}
注:上面的setHeadAndPropagate()方法表示等待队列中的线程成功获取到共享锁,这时候它需要唤醒它后面的共享节点(如果有),但是当通过releaseShared()方法去释放一个共享锁的时候,接下来等待独占锁跟共享锁的线程都可以被唤醒进行尝试获取。
总结
跟独占锁相比,共享锁的主要特征在于当一个在等待队列中的共享节点成功获取到锁以后(它获取到的是共享锁),既然是共享,那它必须要依次唤醒后面所有可以跟它一起共享当前锁资源的节点,毫无疑问,这些节点必须也是在等待共享锁(这是大前提,如果等待的是独占锁,那前面已经有一个共享节点获取锁了,它肯定是获取不到的)。当共享锁被释放的时候,可以用读写锁为例进行思考,当一个读锁被释放,此时不论是读锁还是写锁都是可以竞争资源的。
并发工具类源码详解
CountDownLatch
CountDownLatch 这个类是比较典型的 AQS 的共享模式的使用,这是一个高频使用的类。latch 的中文意思是门栓、栅栏,具体怎么解释我就不废话了,大家随意,看两个例子就知道在哪里用、怎么用了。
使用例子
我们看下 Doug Lea 在 java doc 中给出的例子,这个例子非常实用,我们经常会写这个代码。
假设我们有 N ( N > 0 ) 个任务,那么我们会用 N 来初始化一个 CountDownLatch,然后将这个 latch 的引用传递到各个线程中,在每个线程完成了任务后,调用 latch.countDown() 代表完成了一个任务。
调用 latch.await() 的方法的线程会阻塞,直到所有的任务完成。
class Driver2 { // ...
void main() throws InterruptedException {
CountDownLatch doneSignal = new CountDownLatch(N);
Executor e = Executors.newFixedThreadPool(8);
// 创建 N 个任务,提交给线程池来执行
for (int i = 0; i < N; ++i) // create and start threads
e.execute(new WorkerRunnable(doneSignal, i));
// 等待所有的任务完成,这个方法才会返回
doneSignal.await(); // wait for all to finish
}
}
class WorkerRunnable implements Runnable {
private final CountDownLatch doneSignal;
private final int i;
WorkerRunnable(CountDownLatch doneSignal, int i) {
this.doneSignal = doneSignal;
this.i = i;
}
public void run() {
try {
doWork(i);
// 这个线程的任务完成了,调用 countDown 方法
doneSignal.countDown();
} catch (InterruptedException ex) {
} // return;
}
void doWork() { ...}
}
所以说 CountDownLatch 非常实用,我们常常会将一个比较大的任务进行拆分,然后开启多个线程来执行,等所有线程都执行完了以后,再往下执行其他操作。这里例子中,只有 main 线程调用了 await 方法。
我们再来看另一个例子,这个例子很典型,用了两个 CountDownLatch:
class Driver { // ...
void main() throws InterruptedException {
CountDownLatch startSignal = new CountDownLatch(1);
CountDownLatch doneSignal = new CountDownLatch(N);
for (int i = 0; i < N; ++i) // create and start threads
new Thread(new Worker(startSignal, doneSignal)).start();
// 这边插入一些代码,确保上面的每个线程先启动起来,才执行下面的代码。
doSomethingElse(); // don't let run yet
// 因为这里 N == 1,所以,只要调用一次,那么所有的 await 方法都可以通过
startSignal.countDown(); // let all threads proceed
doSomethingElse();
// 等待所有任务结束
doneSignal.await(); // wait for all to finish
}
}
class Worker implements Runnable {
private final CountDownLatch startSignal;
private final CountDownLatch doneSignal;
Worker(CountDownLatch startSignal, CountDownLatch doneSignal) {
this.startSignal = startSignal;
this.doneSignal = doneSignal;
}
public void run() {
try {
// 为了让所有线程同时开始任务,我们让所有线程先阻塞在这里
// 等大家都准备好了,再打开这个门栓
startSignal.await();
doWork();
doneSignal.countDown();
} catch (InterruptedException ex) {
} // return;
}
void doWork() { ...}
}
这个例子中,doneSignal 同第一个例子的使用,我们说说这里的 startSignal。N 个新开启的线程都调用了startSignal.await() 进行阻塞等待,它们阻塞在栅栏上,只有当条件满足的时候(startSignal.countDown()),它们才能同时通过这个栅栏。
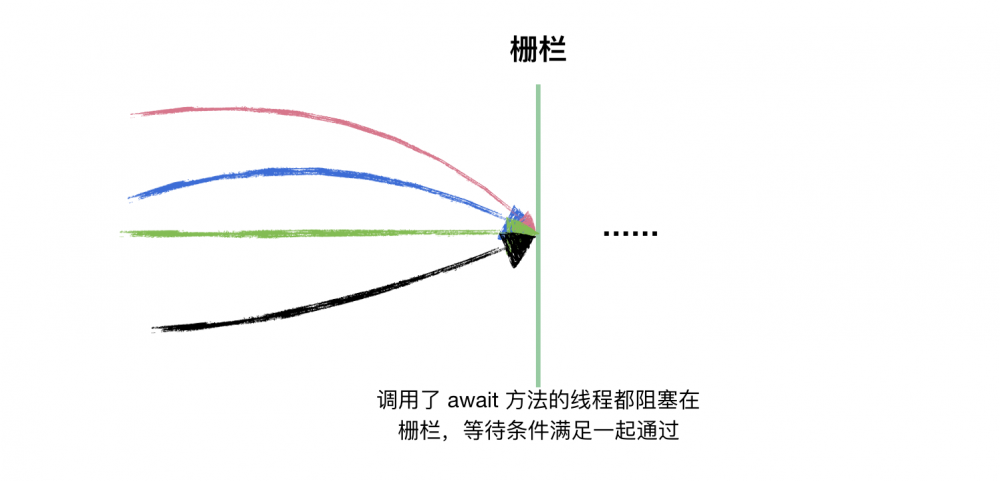
如果始终只有一个线程调用 await 方法等待任务完成,那么 CountDownLatch 就会简单很多,所以之后的源码分析读者一定要在脑海中构建出这么一个场景:有 m 个线程是做任务的,有 n 个线程在某个栅栏上等待这 m 个线程做完任务,直到所有 m 个任务完成后,n 个线程同时通过栅栏。
源码分析
Talk is cheap, show me the code.
构造方法,需要传入一个不小于 0 的整数:
public CountDownLatch(int count) {
if (count < 0) throw new IllegalArgumentException("count < 0");
this.sync = new Sync(count);
}
// 老套路了,内部封装一个 Sync 类继承自 AQS
private static final class Sync extends AbstractQueuedSynchronizer {
Sync(int count) {
// 这样就 state == count 了
setState(count);
}
...
}
代码都是套路,先分析套路:AQS 里面的 state 是一个整数值,这边用一个 int count 参数其实初始化就是设置了这个值,所有调用了 await 方法的等待线程会挂起,然后有其他一些线程会做 state = state - 1 操作,当 state 减到 0 的同时,那个线程会负责唤醒调用了 await 方法的所有线程。都是套路啊,只是 Doug Lea 的套路很深,代码很巧妙,不然我们也没有要分析源码的必要。
对于 CountDownLatch,我们仅仅需要关心两个方法,一个是 countDown() 方法,另一个是 await() 方法。countDown() 方法每次调用都会将 state 减 1,直到 state 的值为 0;而 await 是一个阻塞方法,当 state 减为 0 的时候,await 方法才会返回。await 可以被多个线程调用,读者这个时候脑子里要有个图:所有调用了 await 方法的线程阻塞在 AQS 的阻塞队列中,等待条件满足(state == 0),将线程从队列中一个个唤醒过来。
我们用以下程序来分析源码,t1 和 t2 负责调用 countDown() 方法,t3 和 t4 调用 await 方法阻塞:
public class CountDownLatchDemo {
public static void main(String[] args) {
CountDownLatch latch = new CountDownLatch(2);
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(5000);
} catch (InterruptedException ignore) {
}
// 休息 5 秒后(模拟线程工作了 5 秒),调用 countDown()
latch.countDown();
}
}, "t1");
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(10000);
} catch (InterruptedException ignore) {
}
// 休息 10 秒后(模拟线程工作了 10 秒),调用 countDown()
latch.countDown();
}
}, "t2");
t1.start();
t2.start();
Thread t3 = new Thread(new Runnable() {
@Override
public void run() {
try {
// 阻塞,等待 state 减为 0
latch.await();
System.out.println("线程 t3 从 await 中返回了");
} catch (InterruptedException e) {
System.out.println("线程 t3 await 被中断");
Thread.currentThread().interrupt();
}
}
}, "t3");
Thread t4 = new Thread(new Runnable() {
@Override
public void run() {
try {
// 阻塞,等待 state 减为 0
latch.await();
System.out.println("线程 t4 从 await 中返回了");
} catch (InterruptedException e) {
System.out.println("线程 t4 await 被中断");
Thread.currentThread().interrupt();
}
}
}, "t4");
t3.start();
t4.start();
}
}
上述程序,大概在过了 10 秒左右的时候,会输出:
线程 t3 从 await 中返回了 线程 t4 从 await 中返回了 // 这两条输出,顺序不是绝对的 // 后面的分析,我们假设 t3 先进入阻塞队列
接下来,我们按照流程一步一步走:先 await 等待,然后被唤醒,await 方法返回。
首先,我们来看 await() 方法,它代表线程阻塞,等待 state 的值减为 0。
public void await() throws InterruptedException {
sync.acquireSharedInterruptibly(1);
}
public final void acquireSharedInterruptibly(int arg)
throws InterruptedException {
// 这也是老套路了,我在第二篇的中断那一节说过了
if (Thread.interrupted())
throw new InterruptedException();
// t3 和 t4 调用 await 的时候,state 都大于 0。
// 也就是说,这个 if 返回 true,然后往里看
if (tryAcquireShared(arg) < 0)
doAcquireSharedInterruptibly(arg);
}
// 只有当 state == 0 的时候,这个方法才会返回 1
protected int tryAcquireShared(int acquires) {
return (getState() == 0) ? 1 : -1;
}
从方法名我们就可以看出,这个方法是获取共享锁,并且此方法是可中断的(中断的时候抛出 InterruptedException 退出这个方法)。
private void doAcquireSharedInterruptibly(int arg)
throws InterruptedException {
// 1/. 入队
final Node node = addWaiter(Node.SHARED);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head) {
// 同上,只要 state 不等于 0,那么这个方法返回 -1
int r = tryAcquireShared(arg);
if (r >= 0) {
setHeadAndPropagate(node, r);
p.next = null; // help GC
failed = false;
return;
}
}
// 2
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
我们来仔细分析这个方法,线程 t3 经过第 1 步 addWaiter 入队以后,我们应该可以得到这个:
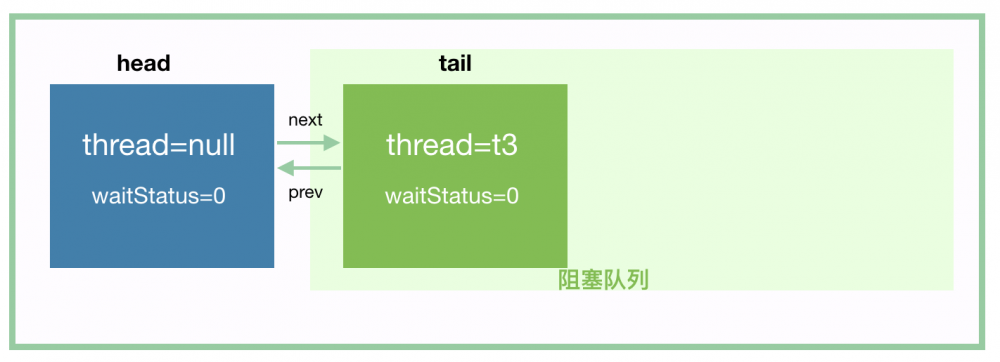
由于 tryAcquireShared 这个方法会返回 -1,所以 if (r >= 0) 这个分支不会进去。到 shouldParkAfterFailedAcquire 的时候,t3 将 head 的 waitStatus 值设置为 -1,如下:
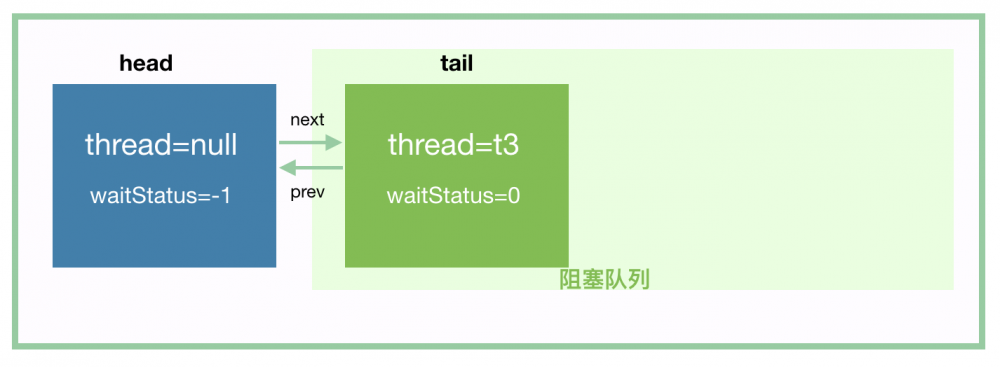
然后进入到 parkAndCheckInterrupt 的时候,t3 挂起。
我们再分析 t4 入队,t4 会将前驱节点 t3 所在节点的 waitStatus 设置为 -1,t4 入队后,应该是这样的:
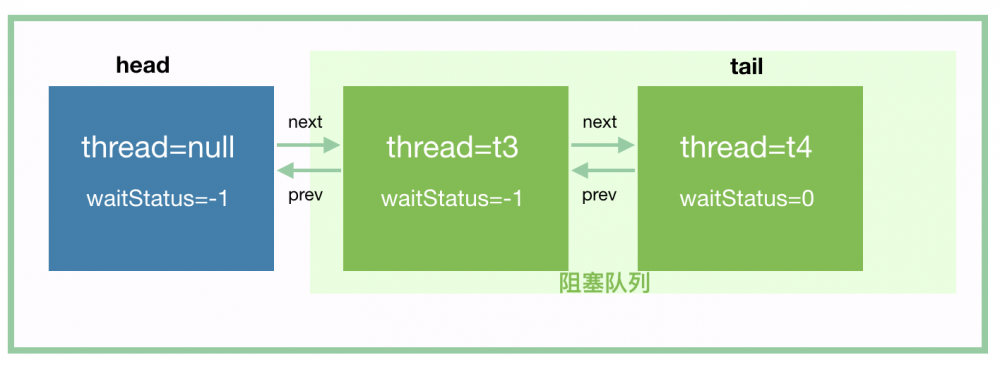
然后,t4 也挂起。接下来,t3 和 t4 就等待唤醒了。
接下来,我们来看唤醒的流程,我们假设用 10 初始化 CountDownLatch。
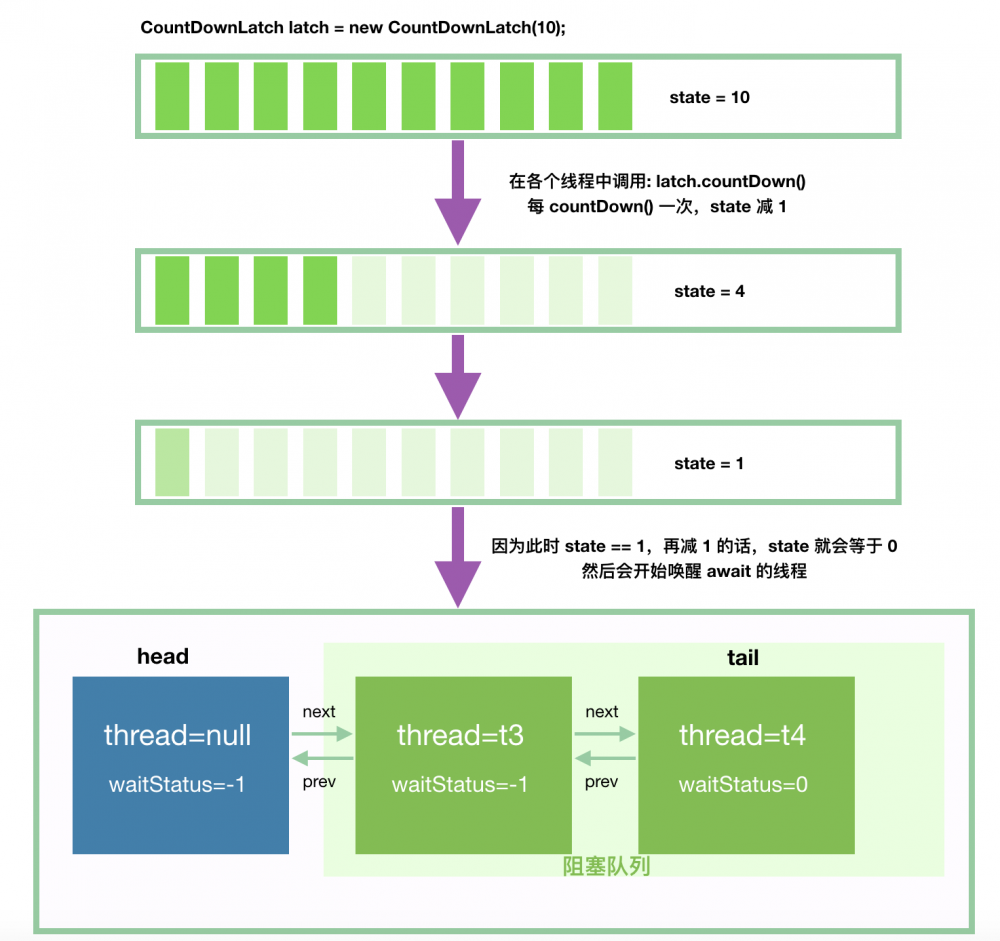
当然,我们的例子中,其实没有 10 个线程,只有 2 个线程 t1 和 t2,只是为了让图好看些罢了。
我们再一步步看具体的流程。首先,我们看 countDown() 方法:
public void countDown() {
sync.releaseShared(1);
}
public final boolean releaseShared(int arg) {
// 只有当 state 减为 0 的时候,tryReleaseShared 才返回 true
// 否则只是简单的 state = state - 1 那么 countDown 方法就结束了
if (tryReleaseShared(arg)) {
// 唤醒 await 的线程
doReleaseShared();
return true;
}
return false;
}
// 这个方法很简单,用自旋的方法实现 state 减 1
protected boolean tryReleaseShared(int releases) {
for (;;) {
int c = getState();
if (c == 0)
return false;
int nextc = c-1;
if (compareAndSetState(c, nextc))
return nextc == 0;
}
}
countDown 方法就是每次调用都将 state 值减 1,如果 state 减到 0 了,那么就调用下面的方法进行唤醒阻塞队列中的线程:
// 调用这个方法的时候,state == 0
// 这个方法先不要看所有的代码,按照思路往下到我写注释的地方,其他的之后还会仔细分析
private void doReleaseShared() {
for (;;) {
Node h = head;
if (h != null && h != tail) {
int ws = h.waitStatus;
// t3 入队的时候,已经将头节点的 waitStatus 设置为 Node.SIGNAL(-1) 了
if (ws == Node.SIGNAL) {
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))
continue; // loop to recheck cases
// 就是这里,唤醒 head 的后继节点,也就是阻塞队列中的第一个节点
// 在这里,也就是唤醒 t3
unparkSuccessor(h);
}
else if (ws == 0 &&
!compareAndSetWaitStatus(h, 0, Node.PROPAGATE)) // todo
continue; // loop on failed CAS
}
if (h == head) // loop if head changed
break;
}
}
一旦 t3 被唤醒后,我们继续回到 await 的这段代码,parkAndCheckInterrupt 返回,我们先不考虑中断的情况:
private void doAcquireSharedInterruptibly(int arg)
throws InterruptedException {
final Node node = addWaiter(Node.SHARED);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head) {
int r = tryAcquireShared(arg);
if (r >= 0) {
setHeadAndPropagate(node, r); // 2/. 这里是下一步
p.next = null; // help GC
failed = false;
return;
}
}
if (shouldParkAfterFailedAcquire(p, node) &&
// 1/. 唤醒后这个方法返回
parkAndCheckInterrupt())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
接下来,t3 会进到 setHeadAndPropagate(node, r) 这个方法,先把 head 给占了,然后唤醒队列中其他的线程:
private void setHeadAndPropagate(Node node, int propagate) {
Node h = head; // Record old head for check below
setHead(node);
// 下面说的是,唤醒当前 node 之后的节点,即 t3 已经醒了,马上唤醒 t4
// 类似的,如果 t4 后面还有 t5,那么 t4 醒了以后,马上将 t5 给唤醒了
if (propagate > 0 || h == null || h.waitStatus < 0 ||
(h = head) == null || h.waitStatus < 0) {
Node s = node.next;
if (s == null || s.isShared())
// 又是这个方法,只是现在的 head 已经不是原来的空节点了,是 t3 的节点了
doReleaseShared();
}
}
又回到这个方法了,那么接下来,我们好好分析 doReleaseShared 这个方法,我们根据流程,头节点 head 此时是 t3 节点了:
// 调用这个方法的时候,state == 0
private void doReleaseShared() {
for (;;) {
Node h = head;
// 1/. h == null: 说明阻塞队列为空
// 2/. h == tail: 说明头结点可能是刚刚初始化的头节点,
// 或者是普通线程节点,但是此节点既然是头节点了,那么代表已经被唤醒了,阻塞队列没有其他节点了
// 所以这两种情况不需要进行唤醒后继节点
if (h != null && h != tail) {
int ws = h.waitStatus;
// t4 将头节点(此时是 t3)的 waitStatus 设置为 Node.SIGNAL(-1) 了
if (ws == Node.SIGNAL) {
// 这里 CAS 失败的场景请看下面的解读
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))
continue; // loop to recheck cases
// 就是这里,唤醒 head 的后继节点,也就是阻塞队列中的第一个节点
// 在这里,也就是唤醒 t4
unparkSuccessor(h);
}
else if (ws == 0 &&
// 这个 CAS 失败的场景是:执行到这里的时候,刚好有一个节点入队,入队会将这个 ws 设置为 -1
!compareAndSetWaitStatus(h, 0, Node.PROPAGATE))
continue; // loop on failed CAS
}
// 如果到这里的时候,前面唤醒的线程已经占领了 head,那么再循环
// 否则,就是 head 没变,那么退出循环,
// 退出循环是不是意味着阻塞队列中的其他节点就不唤醒了?当然不是,唤醒的线程之后还是会调用这个方法的
if (h == head) // loop if head changed
break;
}
}
我们分析下最后一个 if 语句,然后才能解释第一个 CAS 为什么可能会失败:
- h == head:说明头节点还没有被刚刚用 unparkSuccessor 唤醒的线程(这里可以理解为 t4)占有,此时 break 退出循环。
- h != head:头节点被刚刚唤醒的线程(这里可以理解为 t4)占有,那么这里重新进入下一轮循环,唤醒下一个节点(这里是 t4 )。我们知道,等到 t4 被唤醒后,其实是会主动唤醒 t5、t6、t7…,那为什么这里要进行下一个循环来唤醒 t5 呢?我觉得是出于吞吐量的考虑。
满足上面的 2 的场景,那么我们就能知道为什么上面的 CAS 操作 compareAndSetWaitStatus(h, Node.SIGNAL, 0) 会失败了?
因为当前进行 for 循环的线程到这里的时候,可能刚刚唤醒的线程 t4 也刚刚好到这里了,那么就有可能 CAS 失败了。
for 循环第一轮的时候会唤醒 t4,t4 醒后会将自己设置为头节点,如果在 t4 设置头节点后,for 循环才跑到 if (h == head),那么此时会返回 false,for 循环会进入下一轮。t4 唤醒后也会进入到这个方法里面,那么 for 循环第二轮和 t4 就有可能在这个 CAS 相遇,那么就只会有一个成功了。
CyclicBarrier
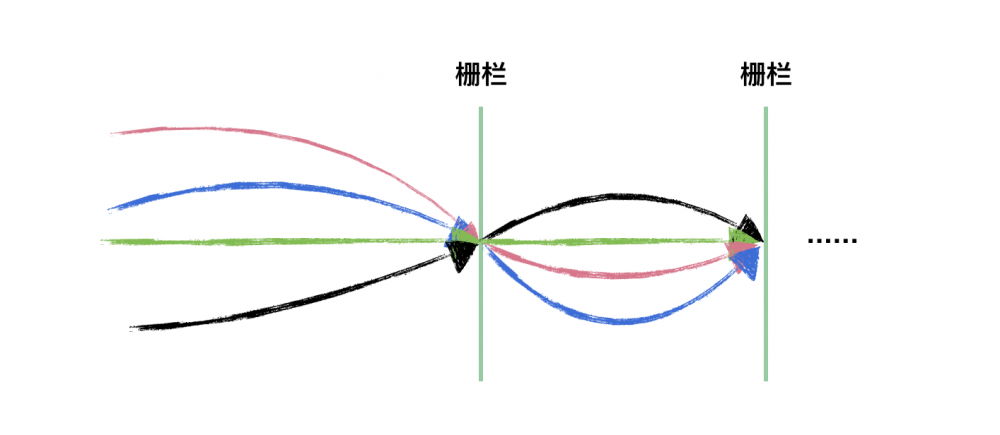
字面意思是“可重复使用的栅栏”,CyclicBarrier 相比 CountDownLatch 来说,要简单很多,其源码没有什么高深的地方,它是 ReentrantLock 和 Condition 的组合使用。看如下示意图,CyclicBarrier 和 CountDownLatch 是不是很像,只是 CyclicBarrier 可以有不止一个栅栏,因为它的栅栏(Barrier)可以重复使用(Cyclic)。
首先,CyclicBarrier 的源码实现和 CountDownLatch 大相径庭,CountDownLatch 基于 AQS 的共享模式的使用,而 CyclicBarrier 基于 Condition 来实现。
因为 CyclicBarrier 的源码相对来说简单许多,读者只要熟悉了前面关于 Condition 的分析,那么这里的源码是毫无压力的,就是几个特殊概念罢了。
废话结束,先上基本属性和构造方法,往下拉一点点,和图一起看:
public class CyclicBarrier {
// 我们说了,CyclicBarrier 是可以重复使用的,我们把每次从开始使用到穿过栅栏当做"一代"
private static class Generation {
boolean broken = false;
}
/** The lock for guarding barrier entry */
private final ReentrantLock lock = new ReentrantLock();
// CyclicBarrier 是基于 Condition 的
// Condition 是“条件”的意思,CyclicBarrier 的等待线程通过 barrier 的“条件”是大家都到了栅栏上
private final Condition trip = lock.newCondition();
// 参与的线程数
private final int parties;
// 如果设置了这个,代表越过栅栏之前,要执行相应的操作
private final Runnable barrierCommand;
// 当前所处的“代”
private Generation generation = new Generation();
// 还没有到栅栏的线程数,这个值初始为 parties,然后递减
// 还没有到栅栏的线程数 = parties - 已经到栅栏的数量
private int count;
public CyclicBarrier(int parties, Runnable barrierAction) {
if (parties <= 0) throw new IllegalArgumentException();
this.parties = parties;
this.count = parties;
this.barrierCommand = barrierAction;
}
public CyclicBarrier(int parties) {
this(parties, null);
}
我用一图来描绘下 CyclicBarrier 里面的一些概念:
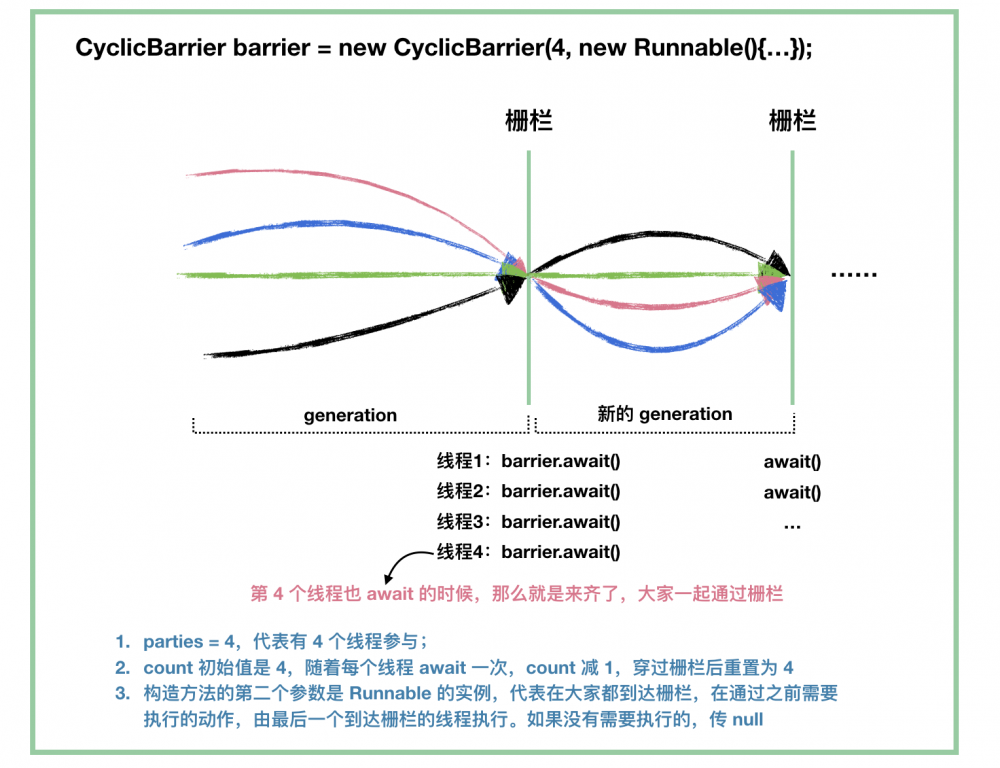
看图我们也知道了,CyclicBarrier 的源码最重要的就是 await() 方法了。
首先,先看怎么开启新的一代:
// 开启新的一代,当最后一个线程到达栅栏上的时候,调用这个方法来唤醒其他线程,同时初始化“下一代”
private void nextGeneration() {
// 首先,需要唤醒所有的在栅栏上等待的线程
trip.signalAll();
// 更新 count 的值
count = parties;
// 重新生成“新一代”
generation = new Generation();
}
看看怎么打破一个栅栏:
private void breakBarrier() {
// 设置状态 broken 为 true
generation.broken = true;
// 重置 count 为初始值 parties
count = parties;
// 唤醒所有已经在等待的线程
trip.signalAll();
}
这两个方法之后用得到,现在开始分析最重要的等待通过栅栏方法 await 方法:
// 不带超时机制
public int await() throws InterruptedException, BrokenBarrierException {
try {
return dowait(false, 0L);
} catch (TimeoutException toe) {
throw new Error(toe); // cannot happen
}
}
// 带超时机制,如果超时抛出 TimeoutException 异常
public int await(long timeout, TimeUnit unit)
throws InterruptedException,
BrokenBarrierException,
TimeoutException {
return dowait(true, unit.toNanos(timeout));
}
继续往里看:
private int dowait(boolean timed, long nanos)
throws InterruptedException, BrokenBarrierException,
TimeoutException {
final ReentrantLock lock = this.lock;
// 先要获取到锁,然后在 finally 中要记得释放锁
// 如果记得 Condition 部分的话,我们知道 condition 的 await 会释放锁,signal 的时候需要重新获取锁
lock.lock();
try {
final Generation g = generation;
// 检查栅栏是否被打破,如果被打破,抛出 BrokenBarrierException 异常
if (g.broken)
throw new BrokenBarrierException();
// 检查中断状态,如果中断了,抛出 InterruptedException 异常
if (Thread.interrupted()) {
breakBarrier();
throw new InterruptedException();
}
// index 是这个 await 方法的返回值
// 注意到这里,这个是从 count 递减后得到的值
int index = --count;
// 如果等于 0,说明所有的线程都到栅栏上了,准备通过
if (index == 0) { // tripped
boolean ranAction = false;
try {
// 如果在初始化的时候,指定了通过栅栏前需要执行的操作,在这里会得到执行
final Runnable command = barrierCommand;
if (command != null)
command.run();
// 如果 ranAction 为 true,说明执行 command.run() 的时候,没有发生异常退出的情况
ranAction = true;
// 唤醒等待的线程,然后开启新的一代
nextGeneration();
return 0;
} finally {
if (!ranAction)
// 进到这里,说明执行指定操作的时候,发生了异常,那么需要打破栅栏
// 之前我们说了,打破栅栏意味着唤醒所有等待的线程,设置 broken 为 true,重置 count 为 parties
breakBarrier();
}
}
// loop until tripped, broken, interrupted, or timed out
// 如果是最后一个线程调用 await,那么上面就返回了
// 下面的操作是给那些不是最后一个到达栅栏的线程执行的
for (;;) {
try {
// 如果带有超时机制,调用带超时的 Condition 的 await 方法等待,直到最后一个线程调用 await
if (!timed)
trip.await();
else if (nanos > 0L)
nanos = trip.awaitNanos(nanos);
} catch (InterruptedException ie) {
// 如果到这里,说明等待的线程在 await(是 Condition 的 await)的时候被中断
if (g == generation && ! g.broken) {
// 打破栅栏
breakBarrier();
// 打破栅栏后,重新抛出这个 InterruptedException 异常给外层调用的方法
throw ie;
} else {
// 到这里,说明 g != generation, 说明新的一代已经产生,即最后一个线程 await 执行完成,
// 那么此时没有必要再抛出 InterruptedException 异常,记录下来这个中断信息即可
// 或者是栅栏已经被打破了,那么也不应该抛出 InterruptedException 异常,
// 而是之后抛出 BrokenBarrierException 异常
Thread.currentThread().interrupt();
}
}
// 唤醒后,检查栅栏是否是“破的”
if (g.broken)
throw new BrokenBarrierException();
// 这个 for 循环除了异常,就是要从这里退出了
// 我们要清楚,最后一个线程在执行完指定任务(如果有的话),会调用 nextGeneration 来开启一个新的代
// 然后释放掉锁,其他线程从 Condition 的 await 方法中得到锁并返回,然后到这里的时候,其实就会满足 g != generation 的
// 那什么时候不满足呢?barrierCommand 执行过程中抛出了异常,那么会执行打破栅栏操作,
// 设置 broken 为true,然后唤醒这些线程。这些线程会从上面的 if (g.broken) 这个分支抛 BrokenBarrierException 异常返回
// 当然,还有最后一种可能,那就是 await 超时,此种情况不会从上面的 if 分支异常返回,也不会从这里返回,会执行后面的代码
if (g != generation)
return index;
// 如果醒来发现超时了,打破栅栏,抛出异常
if (timed && nanos <= 0L) {
breakBarrier();
throw new TimeoutException();
}
}
} finally {
lock.unlock();
}
}
好了,我想我应该讲清楚了吧,我好像几乎没有漏掉任何一行代码吧?
下面开始收尾工作。
首先,我们看看怎么得到有多少个线程到了栅栏上,处于等待状态:
public int getNumberWaiting() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
return parties - count;
} finally {
lock.unlock();
}
}
判断一个栅栏是否被打破了,这个很简单,直接看 broken 的值即可:
public boolean isBroken() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
return generation.broken;
} finally {
lock.unlock();
}
}
前面我们在说 await 的时候也几乎说清楚了,什么时候栅栏会被打破,总结如下:
- 中断,我们说了,如果某个等待的线程发生了中断,那么会打破栅栏,同时抛出 InterruptedException 异常;
- 超时,打破栅栏,同时抛出 TimeoutException 异常;
- 指定执行的操作抛出了异常,这个我们前面也说过。
最后,我们来看看怎么重置一个栅栏:
public void reset() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
breakBarrier(); // break the current generation
nextGeneration(); // start a new generation
} finally {
lock.unlock();
}
}
我们设想一下,如果初始化时,指定了线程 parties = 4,前面有 3 个线程调用了 await 等待,在第 4 个线程调用 await 之前,我们调用 reset 方法,那么会发生什么?
首先,打破栅栏,那意味着所有等待的线程(3个等待的线程)会唤醒,await 方法会通过抛出 BrokenBarrierException 异常返回。然后开启新的一代,重置了 count 和 generation,相当于一切归零了。
怎么样,CyclicBarrier 源码很简单吧。
Semaphore
有了 CountDownLatch 的基础后,分析 Semaphore 会简单很多。Semaphore 是什么呢?它类似一个资源池(读者可以类比线程池),每个线程需要调用 acquire() 方法获取资源,然后才能执行,执行完后,需要 release 资源,让给其他的线程用。
大概大家也可以猜到,Semaphore 其实也是 AQS 中共享锁的使用,因为每个线程共享一个池嘛。
套路解读:创建 Semaphore 实例的时候,需要一个参数 permits,这个基本上可以确定是设置给 AQS 的 state 的,然后每个线程调用 acquire 的时候,执行 state = state - 1,release 的时候执行 state = state + 1,当然,acquire 的时候,如果 state = 0,说明没有资源了,需要等待其他线程 release。
构造方法:
public Semaphore(int permits) {
sync = new NonfairSync(permits);
}
public Semaphore(int permits, boolean fair) {
sync = fair ? new FairSync(permits) : new NonfairSync(permits);
}
这里和 ReentrantLock 类似,用了公平策略和非公平策略。
看 acquire 方法:
public void acquire() throws InterruptedException {
sync.acquireSharedInterruptibly(1);
}
public void acquireUninterruptibly() {
sync.acquireShared(1);
}
public void acquire(int permits) throws InterruptedException {
if (permits < 0) throw new IllegalArgumentException();
sync.acquireSharedInterruptibly(permits);
}
public void acquireUninterruptibly(int permits) {
if (permits < 0) throw new IllegalArgumentException();
sync.acquireShared(permits);
}
这几个方法也是老套路了,大家基本都懂了吧,这边多了两个可以传参的 acquire 方法,不过大家也都懂的吧,如果我们需要一次获取超过一个的资源,会用得着这个的。
我们接下来看不抛出 InterruptedException 异常的 acquireUninterruptibly() 方法吧:
public void acquireUninterruptibly() {
sync.acquireShared(1);
}
public final void acquireShared(int arg) {
if (tryAcquireShared(arg) < 0)
doAcquireShared(arg);
}
前面说了,Semaphore 分公平策略和非公平策略,我们对比一下两个 tryAcquireShared 方法:
// 公平策略:
protected int tryAcquireShared(int acquires) {
for (;;) {
// 区别就在于是不是会先判断是否有线程在排队,然后才进行 CAS 减操作
if (hasQueuedPredecessors())
return -1;
int available = getState();
int remaining = available - acquires;
if (remaining < 0 ||
compareAndSetState(available, remaining))
return remaining;
}
}
// 非公平策略:
protected int tryAcquireShared(int acquires) {
return nonfairTryAcquireShared(acquires);
}
final int nonfairTryAcquireShared(int acquires) {
for (;;) {
int available = getState();
int remaining = available - acquires;
if (remaining < 0 ||
compareAndSetState(available, remaining))
return remaining;
}
}
也是老套路了,所以从源码分析角度的话,我们其实不太需要关心是不是公平策略还是非公平策略,它们的区别往往就那么一两行。
我们再回到 acquireShared 方法,
public final void acquireShared(int arg) {
if (tryAcquireShared(arg) < 0)
doAcquireShared(arg);
}
由于 tryAcquireShared(arg) 返回小于 0 的时候,说明 state 已经小于 0 了(没资源了),此时 acquire 不能立马拿到资源,需要进入到阻塞队列等待,虽然贴了很多代码,不在乎多这点了:
private void doAcquireShared(int arg) {
final Node node = addWaiter(Node.SHARED);
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head) {
int r = tryAcquireShared(arg);
if (r >= 0) {
setHeadAndPropagate(node, r);
p.next = null; // help GC
if (interrupted)
selfInterrupt();
failed = false;
return;
}
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
这个方法我就不介绍了,线程挂起后等待有资源被 release 出来。接下来,我们就要看 release 的方法了:
// 任务介绍,释放一个资源
public void release() {
sync.releaseShared(1);
}
public final boolean releaseShared(int arg) {
if (tryReleaseShared(arg)) {
doReleaseShared();
return true;
}
return false;
}
protected final boolean tryReleaseShared(int releases) {
for (;;) {
int current = getState();
int next = current + releases;
// 溢出,当然,我们一般也不会用这么大的数
if (next < current) // overflow
throw new Error("Maximum permit count exceeded");
if (compareAndSetState(current, next))
return true;
}
}
tryReleaseShared 方法总是会返回 true,然后是 doReleaseShared,这个也是我们熟悉的方法了,我就贴下代码,不分析了,这个方法用于唤醒所有的等待线程:
private void doReleaseShared() {
for (;;) {
Node h = head;
if (h != null && h != tail) {
int ws = h.waitStatus;
if (ws == Node.SIGNAL) {
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))
continue; // loop to recheck cases
unparkSuccessor(h);
}
else if (ws == 0 &&
!compareAndSetWaitStatus(h, 0, Node.PROPAGATE))
continue; // loop on failed CAS
}
if (h == head) // loop if head changed
break;
}
}
Semphore 的源码确实很简单,基本上都是分析过的老代码的组合使用了。
Exchanger
此篇博客所有源码均来自JDK 1.8
前面三篇博客分别介绍了CyclicBarrier、CountDownLatch、Semaphore,现在介绍并发工具类中的最后一个Exchange。Exchange是最简单的也是最复杂的,简单在于API非常简单,就一个构造方法和两个exchange()方法,最复杂在于它的实现是最复杂的(反正我是看晕了的)。
在API是这么介绍的:可以在对中对元素进行配对和交换的线程的同步点。每个线程将条目上的某个方法呈现给 exchange 方法,与伙伴线程进行匹配,并且在返回时接收其伙伴的对象。Exchanger 可能被视为 SynchronousQueue 的双向形式。Exchanger 可能在应用程序(比如遗传算法和管道设计)中很有用。
Exchanger,它允许在并发任务之间交换数据。具体来说,Exchanger类允许在两个线程之间定义同步点。当两个线程都到达同步点时,他们交换数据结构,因此第一个线程的数据结构进入到第二个线程中,第二个线程的数据结构进入到第一个线程中。
功能简介:
- Exchanger是一种线程间安全交换数据的机制。可以和之前分析过的SynchronousQueue对比一下:线程A通过SynchronousQueue将数据a交给线程B;线程A通过Exchanger和线程B交换数据,线程A把数据a交给线程B,同时线程B把数据b交给线程A。可见,SynchronousQueue是交给一个数据,Exchanger是交换两个数据。
应用示例
Exchange实现较为复杂,我们先看其怎么使用,然后再来分析其源码。现在我们用Exchange来模拟生产-消费者问题:
public class ExchangerTest {
static class Producer implements Runnable{
//生产者、消费者交换的数据结构
private List<String> buffer;
//步生产者和消费者的交换对象
private Exchanger<List<String>> exchanger;
Producer(List<String> buffer,Exchanger<List<String>> exchanger){
this.buffer = buffer;
this.exchanger = exchanger;
}
@Override
public void run() {
for(int i = 1 ; i < 5 ; i++){
System.out.println("生产者第" + i + "次提供");
for(int j = 1 ; j <= 3 ; j++){
System.out.println("生产者装入" + i + "--" + j);
buffer.add("buffer:" + i + "--" + j);
}
System.out.println("生产者装满,等待与消费者交换...");
try {
exchanger.exchange(buffer);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
static class Consumer implements Runnable {
private List<String> buffer;
private final Exchanger<List<String>> exchanger;
public Consumer(List<String> buffer, Exchanger<List<String>> exchanger) {
this.buffer = buffer;
this.exchanger = exchanger;
}
@Override
public void run() {
for (int i = 1; i < 5; i++) {
//调用exchange()与消费者进行数据交换
try {
buffer = exchanger.exchange(buffer);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("消费者第" + i + "次提取");
for (int j = 1; j <= 3 ; j++) {
System.out.println("消费者 : " + buffer.get(0));
buffer.remove(0);
}
}
}
}
public static void main(String[] args){
List<String> buffer1 = new ArrayList<String>();
List<String> buffer2 = new ArrayList<String>();
Exchanger<List<String>> exchanger = new Exchanger<List<String>>();
Thread producerThread = new Thread(new Producer(buffer1,exchanger));
Thread consumerThread = new Thread(new Consumer(buffer2,exchanger));
producerThread.start();
consumerThread.start();
}
}
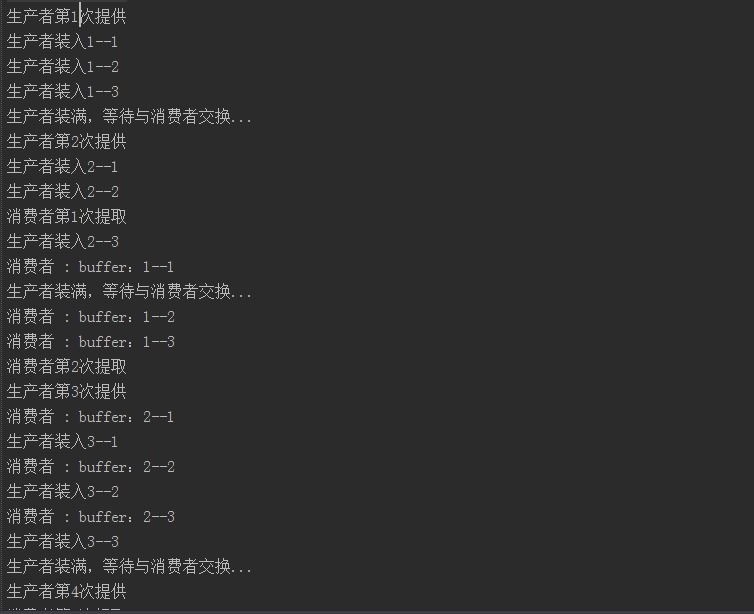
运行结果:
[
]( http://cmsblogs.qiniudn.com/wp-content/uploads/2017/05/2017022100011.jpg )
首先生产者Producer、消费者Consumer首先都创建一个缓冲列表,通过Exchanger来同步交换数据。消费中通过调用Exchanger与生产者进行同步来获取数据,而生产者则通过for循环向缓存队列存储数据并使用exchanger对象消费者同步。到消费者从exchanger哪里得到数据后,他的缓冲列表中有3个数据,而生产者得到的则是一个空的列表。上面的例子充分展示了消费者-生产者是如何利用Exchanger来完成数据交换的。
在Exchanger中,如果一个线程已经到达了exchanger节点时,对于它的伙伴节点的情况有三种:
- 如果它的伙伴节点在该线程到达之前已经调用了exchanger方法,则它会唤醒它的伙伴然后进行数据交换,得到各自数据返回。
- 如果它的伙伴节点还没有到达交换点,则该线程将会被挂起,等待它的伙伴节点到达被唤醒,完成数据交换。
- 如果当前线程被中断了则抛出异常,或者等待超时了,则抛出超时异常。
核心交换算法实现
换句话说Exchanger提供的是一个交换服务,允许原子性的交换两个(多个)对象,但同时只有一对才会成功。先看一个简单的实例模型。
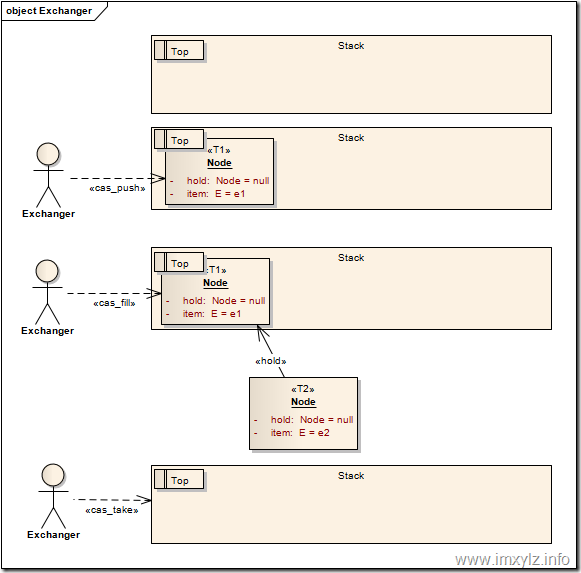
在上面的模型中,我们假定一个空的栈(Stack),栈顶(Top)当然是没有元素的。同时我们假定一个数据结构Node,包含一个要交换的元素E和一个要填充的“洞”Node。这时线程T1携带节点node1进入栈(cas_push),当然这是CAS操作,这样栈顶就不为空了。线程T2携带节点node2进入栈,发现栈里面已经有元素了node1,同时发现node1的hold(Node)为空,于是将自己(node2)填充到node1的hold中(cas_fill)。然后将元素node1从栈中弹出(cas_take)。这样线程T1就得到了node1.hold.item也就是node2的元素e2,线程T2就得到了node1.item也就是e1,从而达到了交换的目的。
算法描述就是下图展示的内容。
JDK 5就是采用类似的思想实现的Exchanger。JDK 6以后为了支持多线程多对象同时Exchanger了就进行了改造(为了支持更好的并发),采用ConcurrentHashMap的思想,将Stack分割成很多的片段(或者说插槽Slot),线程Id(Thread.getId())hash相同的落在同一个Slot上,这样在默认32个Slot上就有很好的吞吐量。当然会根据机器CPU内核的数量有一定的优化,有兴趣的可以去了解下Exchanger的源码。
实现分析
Exchanger算法的核心是通过一个可交换数据的slot,以及一个可以带有数据item的参与者。源码中的描述如下:
for (;;) { if (slot is empty) { // offer place item in a Node; if (can CAS slot from empty to node) { wait for release; return matching item in node; } } else if (can CAS slot from node to empty) { // release get the item in node; set matching item in node; release waiting thread; } // else retry on CAS failure }
Exchanger中定义了如下几个重要的成员变量:
private final Participant participant; private volatile Node[] arena; private volatile Node slot;
participant的作用是为每个线程保留唯一的一个Node节点。
slot为单个槽,arena为数组槽。他们都是Node类型。在这里可能会感觉到疑惑,slot作为Exchanger交换数据的场景,应该只需要一个就可以了啊?为何还多了一个Participant 和数组类型的arena呢?一个slot交换场所原则上来说应该是可以的,但实际情况却不是如此,多个参与者使用同一个交换场所时,会存在严重伸缩性问题。既然单个交换场所存在问题,那么我们就安排多个,也就是数组arena。通过数组arena来安排不同的线程使用不同的slot来降低竞争问题,并且可以保证最终一定会成对交换数据。但是Exchanger不是一来就会生成arena数组来降低竞争,只有当产生竞争是才会生成arena数组。那么怎么将Node与当前线程绑定呢?Participant ,Participant 的作用就是为每个线程保留唯一的一个Node节点,它继承ThreadLocal,同时在Node节点中记录在arena中的下标index。
Node定义如下:
@sun.misc.Contended static final class Node { int index; // Arena index int bound; // Last recorded value of Exchanger.bound int collides; // Number of CAS failures at current bound int hash; // Pseudo-random for spins Object item; // This thread's current item volatile Object match; // Item provided by releasing thread volatile Thread parked; // Set to this thread when parked, else null }
- index:arena的下标;
- bound:上一次记录的Exchanger.bound;
- collides:在当前bound下CAS失败的次数;
- hash:伪随机数,用于自旋;
- item:这个线程的当前项,也就是需要交换的数据;
- match:做releasing操作的线程传递的项;
- parked:挂起时设置线程值,其他情况下为null;
在Node定义中有两个变量值得思考:bound以及collides。前面提到了数组area是为了避免竞争而产生的,如果系统不存在竞争问题,那么完全没有必要开辟一个高效的arena来徒增系统的复杂性。首先通过单个slot的exchanger来交换数据,当探测到竞争时将安排不同的位置的slot来保存线程Node,并且可以确保没有slot会在同一个缓存行上。如何来判断会有竞争呢?CAS替换slot失败,如果失败,则通过记录冲突次数来扩展arena的尺寸,我们在记录冲突的过程中会跟踪“bound”的值,以及会重新计算冲突次数在bound的值被改变时。这里阐述可能有点儿模糊,不着急,我们先有这个概念,后面在arenaExchange中再次做详细阐述。
我们直接看exchange()方法
exchange(V x)
exchange(V x):等待另一个线程到达此交换点(除非当前线程被中断),然后将给定的对象传送给该线程,并接收该线程的对象。方法定义如下:
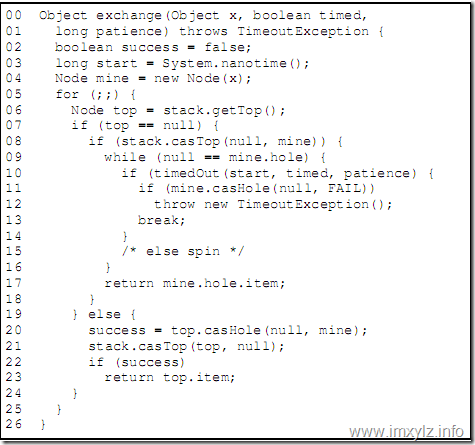
public V exchange(V x) throws InterruptedException { Object v; Object item = (x == null) ? NULL_ITEM : x; // translate null args if ((arena != null || (v = slotExchange(item, false, 0L)) == null) && ((Thread.interrupted() || // disambiguates null return (v = arenaExchange(item, false, 0L)) == null))) throw new InterruptedException(); return (v == NULL_ITEM) ? null : (V)v; }
这个方法比较好理解:arena为数组槽,如果为null,则执行slotExchange()方法,否则判断线程是否中断,如果中断值抛出InterruptedException异常,没有中断则执行arenaExchange()方法。整套逻辑就是:如果slotExchange(Object item, boolean timed, long ns)方法执行失败了就执行arenaExchange(Object item, boolean timed, long ns)方法,最后返回结果V。
NULL_ITEM 为一个空节点,其实就是一个Object对象而已,slotExchange()为单个slot交换。
slotExchange(Object item, boolean timed, long ns)
private final Object slotExchange(Object item, boolean timed, long ns) { // 获取当前线程的节点 p Node p = participant.get(); // 当前线程 Thread t = Thread.currentThread(); // 线程中断,直接返回 if (t.isInterrupted()) return null; // 自旋 for (Node q;;) { //slot != null if ((q = slot) != null) { //尝试CAS替换 if (U.compareAndSwapObject(this, SLOT, q, null)) { Object v = q.item; // 当前线程的项,也就是交换的数据 q.match = item; // 做releasing操作的线程传递的项 Thread w = q.parked; // 挂起时设置线程值 // 挂起线程不为null,线程挂起 if (w != null) U.unpark(w); return v; } //如果失败了,则创建arena //bound 则是上次Exchanger.bound if (NCPU > 1 && bound == 0 && U.compareAndSwapInt(this, BOUND, 0, SEQ)) arena = new Node[(FULL + 2) << ASHIFT]; } //如果arena != null,直接返回,进入arenaExchange逻辑处理 else if (arena != null) return null; else { p.item = item; if (U.compareAndSwapObject(this, SLOT, null, p)) break; p.item = null; } } /*
* 等待 release
* 进入spin+block模式
*/ int h = p.hash; long end = timed ? System.nanoTime() + ns : 0L; int spins = (NCPU > 1) ? SPINS : 1; Object v; while ((v = p.match) == null) { if (spins > 0) { h ^= h << 1; h ^= h >>> 3; h ^= h << 10; if (h == 0) h = SPINS | (int)t.getId(); else if (h < 0 && (--spins & ((SPINS >>> 1) - 1)) == 0) Thread.yield(); } else if (slot != p) spins = SPINS; else if (!t.isInterrupted() && arena == null && (!timed || (ns = end - System.nanoTime()) > 0L)) { U.putObject(t, BLOCKER, this); p.parked = t; if (slot == p) U.park(false, ns); p.parked = null; U.putObject(t, BLOCKER, null); } else if (U.compareAndSwapObject(this, SLOT, p, null)) { v = timed && ns <= 0l="" &&="" !t.isinterrupted()="" ?="" timed_out="" :="" null;="" break;="" }="" u.putorderedobject(p,="" match,="" null);="" p.item="null;" p.hash="h;" return="" v;="" }<="" pre="">
程序首先通过participant获取当前线程节点Node。检测是否中断,如果中断return null,等待后续抛出InterruptedException异常。
如果slot不为null,则进行slot消除,成功直接返回数据V,否则失败,则创建arena消除数组。
如果slot为null,但arena不为null,则返回null,进入arenaExchange逻辑。
如果slot为null,且arena也为null,则尝试占领该slot,失败重试,成功则跳出循环进入spin+block(自旋+阻塞)模式。
在自旋+阻塞模式中,首先取得结束时间和自旋次数。如果match(做releasing操作的线程传递的项)为null,其首先尝试spins+随机次自旋(改自旋使用当前节点中的hash,并改变之)和退让。当自旋数为0后,假如slot发生了改变(slot != p)则重置自旋数并重试。否则假如:当前未中断&arena为null&(当前不是限时版本或者限时版本+当前时间未结束):阻塞或者限时阻塞。假如:当前中断或者arena不为null或者当前为限时版本+时间已经结束:不限时版本:置v为null;限时版本:如果时间结束以及未中断则TIMED_OUT;否则给出null(原因是探测到arena非空或者当前线程中断)。
match不为空时跳出循环。
整个slotExchange清晰明了。
arenaExchange(Object item, boolean timed, long ns)
private final Object arenaExchange(Object item, boolean timed, long ns) { Node[] a = arena; Node p = participant.get(); for (int i = p.index;;) { // access slot at i int b, m, c; long j; // j is raw array offset Node q = (Node)U.getObjectVolatile(a, j = (i << ASHIFT) + ABASE); if (q != null && U.compareAndSwapObject(a, j, q, null)) { Object v = q.item; // release q.match = item; Thread w = q.parked; if (w != null) U.unpark(w); return v; } else if (i <= (m="(b" =="" bound)="" &="" mmask)="" &&="" q="=" null)="" {="" p.item="item;" offer="" if="" (u.compareandswapobject(a,="" j,="" null,="" p))="" long="" end="(timed" m="=" 0)="" ?="" system.nanotime()="" +="" ns="" :="" 0l;="" thread="" t="Thread.currentThread();" wait="" for="" (int="" h="p.hash," spins="SPINS;;)" object="" v="p.match;" (v="" !="null)" u.putorderedobject(p,="" match,="" null);="" clear="" next="" use="" p.hash="h;" return="" v;="" }="" else="" (spins=""> 0) { h ^= h << 1; h ^= h >>> 3; h ^= h << 10; // xorshift if (h == 0) // initialize hash h = SPINS | (int)t.getId(); else if (h < 0 && // approx 50% true (--spins & ((SPINS >>> 1) - 1)) == 0) Thread.yield(); // two yields per wait } else if (U.getObjectVolatile(a, j) != p) spins = SPINS; // releaser hasn't set match yet else if (!t.isInterrupted() && m == 0 && (!timed || (ns = end - System.nanoTime()) > 0L)) { U.putObject(t, BLOCKER, this); // emulate LockSupport p.parked = t; // minimize window if (U.getObjectVolatile(a, j) == p) U.park(false, ns); p.parked = null; U.putObject(t, BLOCKER, null); } else if (U.getObjectVolatile(a, j) == p && U.compareAndSwapObject(a, j, p, null)) { if (m != 0) // try to shrink U.compareAndSwapInt(this, BOUND, b, b + SEQ - 1); p.item = null; p.hash = h; i = p.index >>>= 1; // descend if (Thread.interrupted()) return null; if (timed && m == 0 && ns <= 0l)="" return="" timed_out;="" break;="" expired;="" restart="" }="" else="" p.item="null;" clear="" offer="" {="" if="" (p.bound="" !="b)" stale;="" reset="" p.bound="b;" p.collides="0;" i="(i" ||="" m="=" 0)="" ?="" :="" -="" 1;="" ((c="p.collides)" <="" full="" !u.compareandswapint(this,="" bound,="" b,="" b="" +="" seq="" 1))="" =="0)" cyclically="" traverse="" grow="" p.index="i;" }<="" pre="">
首先通过participant取得当前节点Node,然后根据当前节点Node的index去取arena中相对应的节点node。前面提到过arena可以确保不同的slot在arena中是不会相冲突的,那么是怎么保证的呢?我们先看arena的创建:
arena = new Node[(FULL + 2) << ASHIFT];
这个arena到底有多大呢?我们先看FULL 和ASHIFT的定义:
static final int FULL = (NCPU >= (MMASK << 1)) ? MMASK : NCPU >>> 1; private static final int ASHIFT = 7; private static final int NCPU = Runtime.getRuntime().availableProcessors(); private static final int MMASK = 0xff; // 255
假如我的机器NCPU = 8 ,则得到的是768大小的arena数组。然后通过以下代码取得在arena中的节点:
Node q = (Node)U.getObjectVolatile(a, j = (i << ASHIFT) + ABASE);
他仍然是通过右移ASHIFT位来取得Node的,ABASE定义如下:
Class<?> ak = Node[].class; ABASE = U.arrayBaseOffset(ak) + (1 << ASHIFT);
U.arrayBaseOffset获取对象头长度,数组元素的大小可以通过unsafe.arrayIndexScale(T[].class) 方法获取到。这也就是说要访问类型为T的第N个元素的话,你的偏移量offset应该是arrayOffset+N*arrayScale。也就是说BASE = arrayOffset+ 128 。其次我们再看Node节点的定义
@sun.misc.Contended static final class Node{ .... }
在Java 8 中我们是可以利用sun.misc.Contended来规避伪共享的。所以说通过 << ASHIFT方式加上sun.misc.Contended,所以使得任意两个可用Node不会再同一个缓存行中。
关于伪共享请参考如下博文:
伪共享(False Sharing)
Java8中用sun.misc.Contended避免伪共享(false sharing) )
我们再次回到arenaExchange()。取得arena中的node节点后,如果定位的节点q 不为空,且CAS操作成功,则交换数据,返回交换的数据,唤醒等待的线程。
如果q等于null且下标在bound & MMASK范围之内,则尝试占领该位置,如果成功,则采用自旋 + 阻塞的方式进行等待交换数据。
如果下标不在bound & MMASK范围之内获取由于q不为null但是竞争失败的时候:消除p。加入bound 不等于当前节点的bond(b != p.bound),则更新p.bound = b,collides = 0 ,i = m或者m - 1。如果冲突的次数不到m 获取m 已经为最大值或者修改当前bound的值失败,则通过增加一次collides以及循环递减下标i的值;否则更新当前bound的值成功:我们令i为m+1即为此时最大的下标。最后更新当前index的值。
Exchanger使用、原理都比较好理解,但是这个源码看起来真心有点儿复杂,是真心难看懂,但是这种交换的思路Doug Lea在后续博文中还会提到,例如SynchronousQueue、LinkedTransferQueue。
最后用一个在网上看到的段子结束此篇博客( http://brokendreams.iteye.com/blog/2253956 ),博主对其做了一点点修改,以便更加符合在1.8环境下的Exchanger:
其实就是”我”和”你”(可能有多个”我”,多个”你”)在一个叫Slot的地方做交易(一手交钱,一手交货),过程分以下步骤:
- 我先到一个叫做Slot的交易场所交易,发现你已经到了,那我就尝试喊你交易,如果你回应了我,决定和我交易那么进入第2步;如果别人抢先一步把你喊走了,那我就进入第5步。
- 我拿出钱交给你,你可能会接收我的钱,然后把货给我,交易结束;也可能嫌我掏钱太慢(超时)或者接个电话(中断),TM的不卖了,走了,那我只能再找别人买货了(从头开始)。
- 我到交易地点的时候,你不在,那我先尝试把这个交易点给占了(一屁股做凳子上…),如果我成功抢占了单间(交易点),那就坐这儿等着你拿货来交易,进入第4步;如果被别人抢座了,那我只能在找别的地方儿了,进入第5步。
- 你拿着货来了,喊我交易,然后完成交易;也可能我等了好长时间你都没来,我不等了,继续找别人交易去,走的时候我看了一眼,一共没多少人,弄了这么多单间(交易地点Slot),太TM浪费了,我喊来交易地点管理员:一共也没几个人,搞这么多单间儿干毛,给哥撤一个!。然后再找别人买货(从头开始);或者我老大给我打了个电话,不让我买货了(中断)。
- 我跑去喊管理员,尼玛,就一个坑交易个毛啊,然后管理在一个更加开阔的地方开辟了好多个单间,然后我就挨个来看每个单间是否有人。如果有人我就问他是否可以交易,如果回应了我,那我就进入第2步。如果我没有人,那我就占着这个单间等其他人来交易,进入第4步。
6.如果我尝试了几次都没有成功,我就会认为,是不是我TM选的这个单间风水不好?不行,得换个地儿继续(从头开始);如果我尝试了多次发现还没有成功,怒了,把管理员喊来:给哥再开一个单间(Slot),加一个凳子,这么多人就这么几个破凳子够谁用!
总结
CountdownLatch基于AQS的共享锁实现,线程运行完内部调用cas操作修改state - 1,当state为0时阻塞的线程被一起唤醒。
collidebarrier基于lock和condition实现,线程运行到屏障时cas操作修改state - 1,并阻塞在condition上,state= 0 时conditon.signal阻塞的线程。
Semaphore基于AQS共享实现。同上。
exchanger内部保持一个栈(后来改为slot或slot数组),一个线程进入时cas把数据放到栈中,并阻塞,另一个线程进来发现有东西,cas获取并清空,同时把数据放到伙伴线程的一个结构中,唤醒伙伴线程,运行完毕。
写到这里,终于把 AbstractQueuedSynchronizer 基本上说完了,对于 Java 并发,Doug Lea 真的是神一样的存在。日后我们还会接触到很多 Doug Lea 的代码,希望我们大家都可以朝着大神的方向不断打磨自己的技术,少一些高大上的架构,多一些实实在在的优秀代码吧。
正文到此结束
- 本文标签: 代码 list 同步 producer HashMap ssh tar 数据 value consumer 线程池 模型 java UI GitHub 实例 总结 文章 id rmi https map SDN DOM final ACE 希望 缓存 git 安全 多线程 HTML 锁 博客 IO CountDownLatch ip cat API App volatile http executor 构造方法 node 压力 管理 注释 参数 ask Action ArrayList 源码 线程 NSA 时间 REST src queue ConcurrentHashMap rsync swap IDE
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

